k-均值(k-means)及Matlab实现
注:1.仅适合于数值属性的数据。
2.对正态分布(高斯分布)数据聚类效果最佳。。
1. 算法思想
k-means算法,也称k-均值算法,它把N个对象划分成k个簇,用簇中对象的均值表示每个簇的中心点(质心),通过迭代使每个簇内的对象不再发生变化为止,此时的平方误差准则函数达到最优,即簇内对象相似度高,簇间相似度低。其具体过程描述如下:
(1.)首先,随机选择k个对象,代表要分成的k个簇的初始均值或中心。
(2.)计算其余对象与各个均值的欧式距离,找到距离最短的对象,将其分配到距离中心最近的簇中。
(3.)计算每个簇中所有对象的平均值(均值),作为每个簇的新的中心。
(4.)再次计算所有对象与新的k个中心的欧式距离,根据**"距离中心最近原则”** ,重新划分所有对象到各个簇中。
(5.)重复(3.)(4.)步骤,直至所有簇中心不变为止。(即本轮生成的簇与上一轮生形成的簇相同)。聚类结束。
2. k-均值算法划分聚类的三个关键点
(1.)数据对象的划分
-
距离度量的选择
计算数据对象之间的距离时,要选择合适的相似性度量,较著名的距离度量是欧几里得距离和曼哈顿距离,常用的是欧氏距离,公式如下:
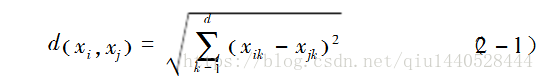
这里xi,xj表示两个d维数据对象,即对象有d个属性,xi=(xi1,xi2,…,xid),xj=(xj1,xj2,…,xjd)。d(xi,xj)表示对象xi和xj之间的距离,距离越小,二者越相似。
根据欧几里得距离,计算出每一个数据对象与各个簇中心的距离。
-
选择最小距离
即如果d(p,mi)=min{d(p,m1),d(p,m2),…,d(p,mk)}
那么,p∈ci;P表示给定的数据对象;m1,m2,…,mk分别表示簇c1,c2,…,ck的初始均值或中心。
(2.)准则函数的选择
k-均值算法采用平方误差准则函数来评估聚类的性能,即聚类结束后,对所有聚类簇用该公式评估。公式如下:
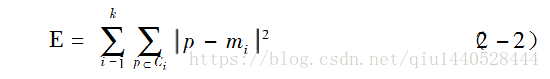
对于每个簇中的每个对象,求对象到其簇中心距离的平方,然后求和。
其中,E表示数据库中所有对象的平方误差和,P表示给定的数据对象,mi表示簇ci的均值。
(3.)簇中心的计算
用每个簇内所有对象的均值作为簇中心,公式如下:

这里假设簇c1,c2,…,ck中的数据对象个数分别为n1,n2,…,nk。
3. k-均值算法实现
输入:k,簇数目
D,包含N个对象的数据集
输出:k个簇的集合
方法:
1. 从D中N个对象任意选择k个对象作为初始簇中心;
2. 根据欧氏距离,依次比较其余每个对象与各个簇中心的距离;选择距离最近的簇,依次把N个对象划分到k个簇中;
3. 完成第一次划分后,重新计算新的簇中心即均值,然后重新划分数据对象,直到新的簇中心不再发生变化。
4. k-均值算法的优缺点
优点:
- 解决聚类问题的一种经典算法,简单,快速;
- 对处理大型数据集,该算法保持可收缩性,高效性;
- 当簇接近正态分布时,效果最好;
缺点:
- 在k-means算法中k是事先给定的,这个k值难以估计,很多时候并不知道数据集应该分成多少个类别最合适;
- 当簇的均值可定义时才能使用,不适用于具有标称属性的数据,此时用k-众数方法研究;
- 初始聚类中心的任意选择对聚类结果有很大影响,一旦初始值选择不好就无法得到有效的聚类结果;
- 该算法需要不断进行样本分类调整,不断计算调整后的新的聚类中心,因此数据量大时,算法时间开销大;
- 若簇中含有异常点,将导致均值偏离严重;(即对噪声、孤立点敏感);
- 不适用于发现非凸形状的簇,或大小差别大的簇;
5. 给出两个Matlab聚类代码
代码一:静态实现
随机生成三组正态分布数据点,迭代生成K个聚类簇。具体通过计算欧式距离划分数据点并标记每个数据点到K个聚类簇中,直到K个簇中心达到稳定(收敛)为止。
clear all;
close all;
clc;
% 第一组数据
mu1=[0 0 ]; %均值(是需要生成的数据的均值)
S1=[.1 0 ;0 .1]; %协方差(需要生成的数据的自相关矩阵(相关系数矩阵))
data1=mvnrnd(mu1,S1,100); %产生高斯分布数据
%第二组数据
mu2=[1.25 1.25 ];
S2=[.1 0 ;0 .1];
data2=mvnrnd(mu2,S2,100);
% 第三组数据
mu3=[-1.25 1.25 ];
S3=[.1 0 ;0 .1];
data3=mvnrnd(mu3,S3,100);
% 显示数据
plot(data1(:,1),data1(:,2),'b+');
hold on;%不覆盖原图,要关闭则使用hold off;
plot(data2(:,1),data2(:,2),'r+');
plot(data3(:,1),data3(:,2),'g+');
grid on;%显示表格
% 三类数据合成一个不带标号的数据类
data=[data1;data2;data3];
N=3;%设置聚类数目
[m,n]=size(data);%表示矩阵data大小,m行n列
pattern=zeros(m,n+1);%生成0矩阵
center=zeros(N,n);%初始化聚类中心
pattern(:,1:n)=data(:,:);
for x=1:N
center(x,:)=data( randi(300,1),:);%第一次随机产生聚类中心
end
while 1 %循环迭代每次的聚类簇;
distence=zeros(1,N);%最小距离矩阵
num=zeros(1,N);%聚类簇数矩阵
new_center=zeros(N,n);%聚类中心矩阵
for x=1:m
for y=1:N
distence(y)=norm(data(x,:)-center(y,:));%计算到每个类的距离
end
[~, temp]=min(distence);%求最小的距离
pattern(x,n+1)=temp;%划分所有对象点到最近的聚类中心;标记为1,2,3;
end
k=0;
for y=1:N
for x=1:m
if pattern(x,n+1)==y
new_center(y,:)=new_center(y,:)+pattern(x,1:n);
num(y)=num(y)+1;
end
end
new_center(y,:)=new_center(y,:)/num(y);%求均值,即新的聚类中心;
if norm(new_center(y,:)-center(y,:))<0.1%检查集群中心是否已收敛。如果是则终止。
k=k+1;
end
end
if k==N
break;
else
center=new_center;
end
end
[m, n]=size(pattern);
%最后显示聚类后的数据
figure;
hold on;
for i=1:m
if pattern(i,n)==1
plot(pattern(i,1),pattern(i,2),'r*');
plot(center(1,1),center(1,2),'ko');%用小圆圈标记中心点;
elseif pattern(i,n)==2
plot(pattern(i,1),pattern(i,2),'g*');
plot(center(2,1),center(2,2),'ko');
elseif pattern(i,n)==3
plot(pattern(i,1),pattern(i,2),'b*');
plot(center(3,1),center(3,2),'ko');
elseif pattern(i,n)==4
plot(pattern(i,1),pattern(i,2),'y*');
plot(center(4,1),center(4,2),'ko');
else
plot(pattern(i,1),pattern(i,2),'m*');
plot(center(4,1),center(4,2),'ko');
end
end
grid on;
随着N值的自定义设置,聚类结果如下:
N=2时

N=3时

N=4时

代码二:动态演示聚类过程
数据存储于scaledfaithful.txt文本文件,通过自定义多个函数实现聚类。
效果如下:
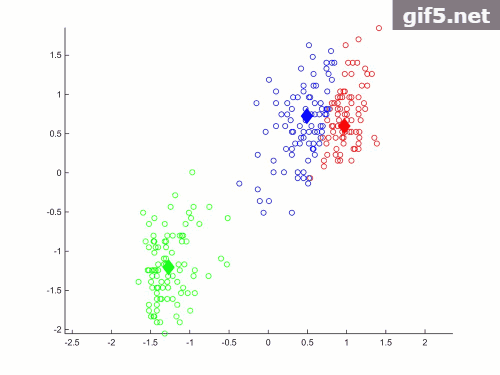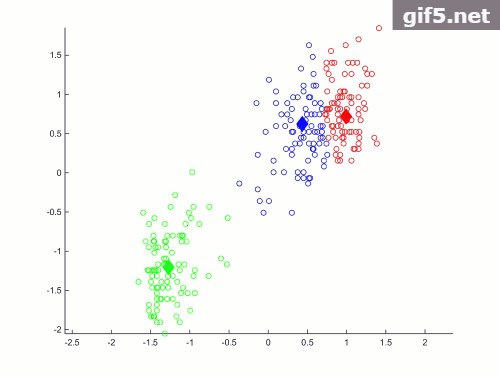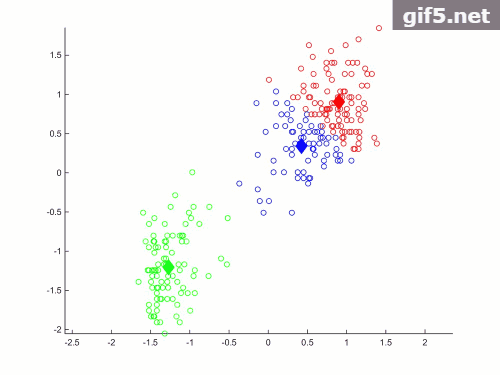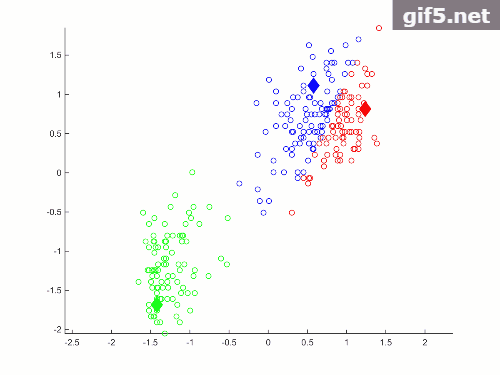
代码:
runKMeans.m文件(自定义runKMeans函数,进行聚类算法实现。)
function runKMeans(K,fileString)
%加载由fileStringfrom Bishop book指定的数据文件
%[filename,filepath]=uigetfile('*.txt','Select Input file');
X=load(fileString);%load函数加载当前文件夹中的数据;
%读入数据,X为N×D维的矩阵
N=size(X,1);
D=size(X,2);
%初始化中心点Kmus 为K×D维度的矩阵
Kmus=zeros(K,D);
%通过从数据中随机选取点来初始化集群中心
rndinds=randperm(N);
Kmus=X(rndinds(1:K),:);
%指定允许的最大迭代次数
maxiters=1000;
for iter=1:maxiters
%sqDmat将是一个n×k矩阵
%调用自定义函数calcSqDistances() 计算数据与各中心点之间的距离
sqDmat=calcSqDistances(X,Kmus);
%给定距离的平方矩阵,确定最近的簇
%R将是一个n×k的二进制值矩阵,
%是否属于第k个中心点的类,属于就是1,不属于就是0
%调用自定义函数determineRnk()根据距离决定数据属于哪一类
Rnk=determineRnk(sqDmat);
KmusOld=Kmus;
plotCurrent(X,Rnk,Kmus);
pause(1) %函数pause(1) 会在循环过程中产生动态效果
%recalcMus()根据确定好的数据的类重新计算出新的中心点,最后重复循环直到收敛。
Kmus=recalcMus(X,Rnk);
%检查集群中心是否已收敛。如果是则终止。
if sum(abs(KmusOld(:)-Kmus(:)))<1e-6
disp(iter);
break
end
end
end
计算数据与各中心点之间的距离函数:calcSqDistances

划分数据点的类别的函数:determineRnk

绘图函数:plotCurrent

主程序:KMeans_script(KMeans运行脚本)
% KMeans_script(KMeans运行脚本)
K = 4; %自定义聚类数
filename = 'scaledfaithful.txt'; %数据文本
runKMeans(K,filename)
运行结果如下:
当K=2时

当K=3时

当K=4时

总结
本文介绍了k-均值(k-means)聚类算法的思想及算法步骤和关键知识点。给出了两个Matlab的实现代码。
代码一,通过Matlab函数随机生成三组高斯分布数点,并迭代生成聚类簇。
代码二,将数据点存放于.txt文件,通过读取数据文件获取数据,并通过自定义多个函数方法并调用实现聚类。代码主要通过在迭代循环体中添加pause()函数,实现数据对象动态聚类的过程。
参考文献
https://blog.csdn.net/liu1194397014/article/details/52844997
通过本文对k-均值算法的深入学习,给出了两种流行的Matlab代码实现,具体源码可点击下方进行积分下载,没有积分的小伙伴可扫码联系本人获取。
CSDN积分下载地址:
静态实现: https://download.csdn.net/download/qiu1440528444/10486647
动态实现:https://download.csdn.net/download/qiu1440528444/10486631