论文:Dense Teacher: Dense Pseudo-Labels for Semi-supervised Object Detection
代码:https://github.com/Megvii-BaseDetection/DenseTeacher
出处:ECCV2022 | 旷视
一、背景
目前在半监督目标检测任务中表现较好的方法是:
- 对输入图像进行弱数据增强并输入 teacher 模型,得到预测的伪边界框
- 对输入图像经过强数据增强后输入 student 模型,student 模型学习的真值是伪边界框。
但这种直接从半监督分类任务中迁移过来的方法对目标检测可能不是非常合适,如图 1 所示。
使用生成的伪边界框当做 student 模型的真值来监督模型训练需要几个额外的步骤,从而引入很多超参数,如果参数选择不到位,则会影响半监督检测模型的效果,如:
本文的贡献点:提出了 Dense Teacher,也提出了伪标签的统一形式——Dense Pseudo-Label(DPL)
- DPL 表示完整的标签,是网络的密集输出,没有经过后处理,能够使得教师模型和学生模型之间进行更有效的知识传递
- 对每个训练 iter,随机选择一定数量的标签数据和无标签数据作为训练样本
- Teacher model 是 Student model 经过 EMA 后得到的,Teacher model 用于生成 DPL
- Student model 是学习标签数据的 label 和无标签数据的伪真值
二、方法
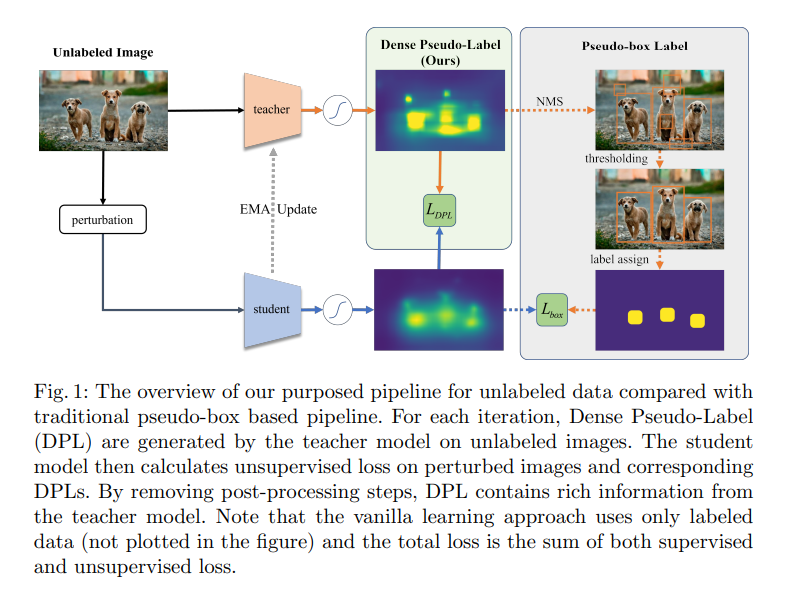
Dense Teacher 的整个过程如图 1 所示:
2.1 框架结构
Dense Teacher 的框架结构如图 1 所示,在每个 iter:
- 对 labeled data 和 unlabeled data 进行随机采样,得到一个 data batch
- teacher model:通过 student 的 EMA 得到,用于接收弱数据增强后的数据作为输入,并输出预测的结果作为伪标签
- student model:使用有标签的数据进行有监督学习,并得到有监督的 loss
L
s
L_s
Ls,使用有伪标签的数据进行无监督训练,得到无监督 loss
L
u
L_u
Lu
- 只有 student model 需要计算 loss,teacher 模型不需要计算 loss,故整体的 loss 为
L
=
L
s
+
w
u
L
u
L=L_s+w_uL_u
L=Ls+wuLu,
w
u
w_u
wu 是无监督 loss 的权重
2.2 伪标签的缺陷
下文主要会探索伪标签在 COCO 和 CrowdHuman 上的效果,因为 NMS 阈值在密集场景会更凸显问题。
也是由于现存方法有如下 3 个问题,作者提出了一种新的无后处理的密集标签指导的无监督学习
1、阈值选择的问题
在半监督目标检测任务中,teacher 模型的输出会作为伪标签供 student 模型学习
所以,如何使用阈值来过滤分类得分低的预测框是很关键的一步
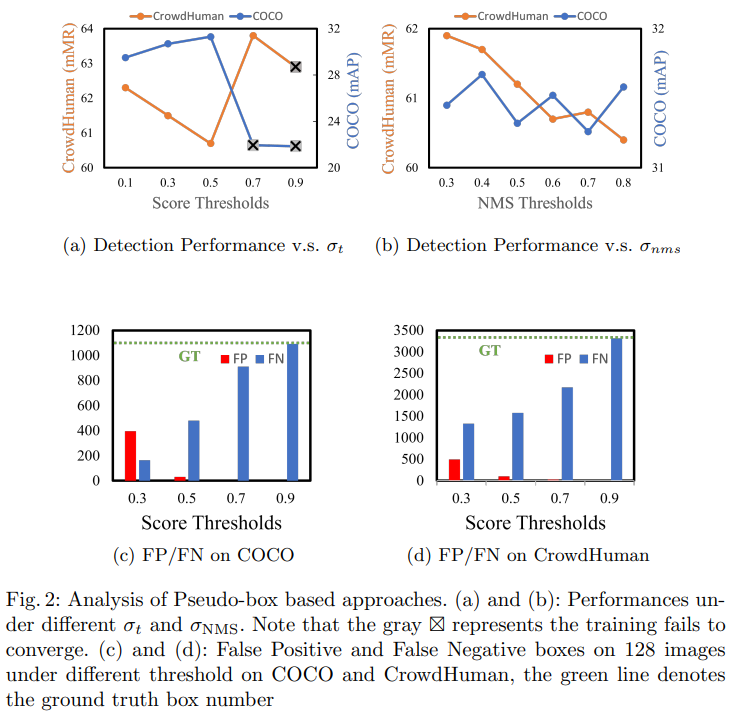
如图 2 所示,作者给出了 Unbiased Teacher 在不同阈值下的训练结果:
- 随着阈值的变化,两个数据集的检测性能波动很大
- 当阈值较高时(如 0.7 和 0.9),训练过程可能会无法收敛,这可能是由于教师模型的预测中存在大量的 FN,如图 2c 和 2d 所示。这也说明使用阈值操作会消除很多高质量的预测,导致 student 模型学习效果变差
- 当阈值较低时(如 0.3),由于 FP 较多,性能表现也会下降,如图 2c 和 2d
- 综上,很难选择一个合适的阈值来保证保留下来的伪边界框的质量
2、NMS 的问题
NMS 使用阈值来控制预测框的去留
通过实验发现,NMS 的阈值对 SSOD 的效果也有很大的影响
如图 2b,展示了 NMS 的阈值和 Unbiased Teacher 效果的关系:
- 不同的 NMS 阈值会导致检测效果的波动,尤其是在 CrowdHuman 这种密集场景的数据下尤为明显
- 不同数据集的最优 NMS 阈值是不同的,COCO 为 0.7,CrowdHuman 为 0.8,所以 NMS 阈值的选择也需要一定的调试才能选择到最优的阈值
- 使用了 NMS 后,会进一步增加伪边界框的不可靠性
3、正负样本分配中的不一致问题
我们已知目标检测中的正负样本分配是非常重要的,但在半监督目标检测中可能会有问题,因为伪标签的定位可能不是很准确,这就会导致标签的正负样本分配和真实的标签不一致。
如图 3 所示,虽然预测的伪框和真实的框可能满足 IoU>0.5:
- 3b 中的绿框是真实标注的 gt,假设 gt 中心的 3x3 区域的 anchor point 被分为正样本(绿色实心圆)
- 3c 中的预测的伪框的 3x3 中心区域的 anchor point 是三个实心红圆和六个实心绿圆,这样就会导致将一些错误的 anchor point 误分为正样本
- 这种与真值不一致的问题会导致模型性能降低。

2.3 Dense Peseudo-Label
1、DPL 的具体过程如下:
- 期望的密集伪标签是由训练的模型预测的 post-sigmoid logits 得到的,如图 1 绿色框所示
- 经过对比后可以明确的发现,DPL 比其他的伪标签具有更详细的信息

2、DPL 的分类损失:QFL
- 由于 DPL 的表示是连续值(0~1),标准的 Focal loss 只能处理离散值,所以使用 QFL 在密集的伪标签和学生模型的预测结果间进行学习
QFL 公式如下,
p
i
s
p_i^s
pis 表示学生网络对第 i 个 anchor 的预测结果,
y
i
y_i
yi 表示 DPL,
γ
\gamma
γ 是抑制因子:
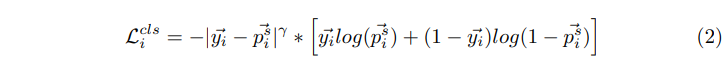
3、使用特征丰富程度评分来划分学习区域,提高模型对有效区域的利用率
-
虽然 DPL 包含丰富的信息,但由于没有阈值的过滤,保留了很多低得分的预测结果,而这些结果包含很多背景区域,包含的有用信息很少。
-
在下面也会证明,如果学生网络学习这些背景区域的特征,就会影响 SSOD 算法的性能
-
因此,作者提出基于【教师特征的丰富程度评分,Feature Richness Score,FRS】来讲整幅图像划分为学习区域和抑制区域。
如何使用 FRS 来划分像素呢:
- 选择 top-k% 得分的像素作为学习区域
- 其他区域抑制为 0
基于 FRS 划分后的 DPL 如下,
p
i
,
c
t
p_{i,c}^t
pi,ct 为教师网络在第 c 个类别的第 i 个样本的得分预测,C 是总类别数:
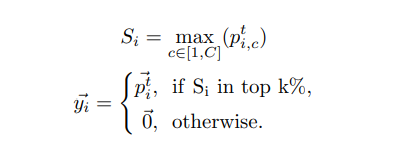
经过上面的设计,有如下的好处:
- 通过修改学习区域,可以通过选择额外的样本来实现难负例挖掘,如图 4 所示
- 通过选择学习区域,可以很容易的实现对回归分支的无监督学习,作者使用 IoU loss 来监督无标签数据的回归
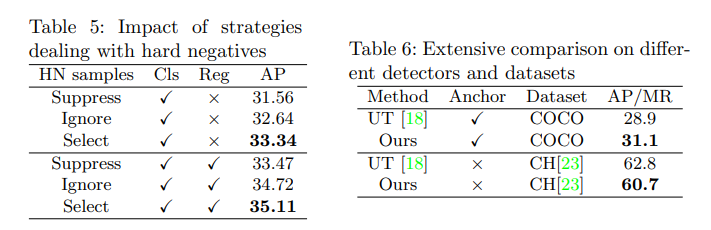
难负例样本挖掘带来的提升:
在 Dense Teacher 网络中,分别探索了“抑制”、“忽略”、“选择” 三种不同策略对难负例区域的影响,结果如表 5 所示。
- 抑制难负例为 0:分类和回归分支的性能都有下降
- 忽略难负例:在计算损失时忽略难负例,结果表明这种方式比抑制难负例得到的效果更好,但仍比“选择”难负例用于训练效果要差一些
- 这表明如何处理难负例对模型性能有影响
回归分支带来的效果提升:

三、效果
3.1 数据和实验设置
数据使用 COCO 和 Pascal VOC:
-
COCO 的 train2017 包含 118k 标签数据,123k 无标签数据,在 val2017 上进行测试
-
Pascal VOC 的训练集使用 VOC07 train 和 VOC12 train,测试集使用 VOC07 test
-
COCO-Standard:使用 1%、2%、5%、10% 的采样率对 train2017 进行有标签数据的采样,其他数据当做无标签数据训练
-
COCO-Full:使用 train2017 有标签数据和 unlabeled2017 无标签数据的所有
-
VOC Mixture:将 VOC07 train 作为有标签数据,VOC12 train & COCO20cls 作为无标签数据
实验设置:
- 使用 FCOS 作为基准检测器,在 ImageNet 上预训练的 ResNet50 作为 backbone
- batch-size=16,基础学习率为 0.01,QFL 的参数
γ
=
2
\gamma=2
γ=2
- COCO 数据集的 loss weight
w
u
=
4
w_u=4
wu=4,其他数据集为 2
3.2 主要的结果对比
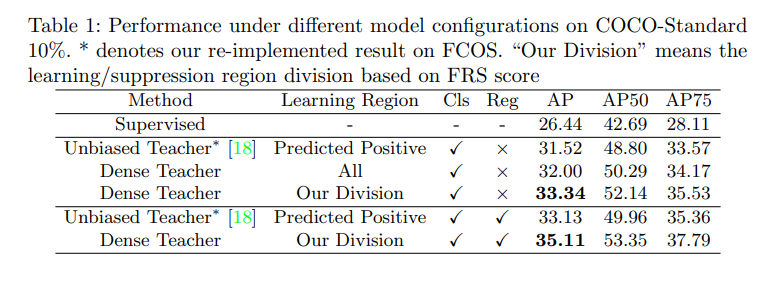
- DPL 带来了较好的提升,但如果没有区域划分策略的话,只能从 31.52% 提升到 32%,提升的很小,所以区域划分非常重要
- 区域划分测量能有效利用难负例区域来加强训练效果,使用 COCO 的 gt 对 FCOS 进行正负样本分配时,在 train2017 上只有约 0.4% 的正样本。通过指定 k=1,能够挖掘更多的难负例来知道无监督训练
- 图 4 中可以看出难负例分布在一些有意义的像素上(坐垫处、柜子上、小狗身上的其他部位等),教师模型这样的响应可以帮助学生模型提高效果
3.3 和 SOTA 的对比
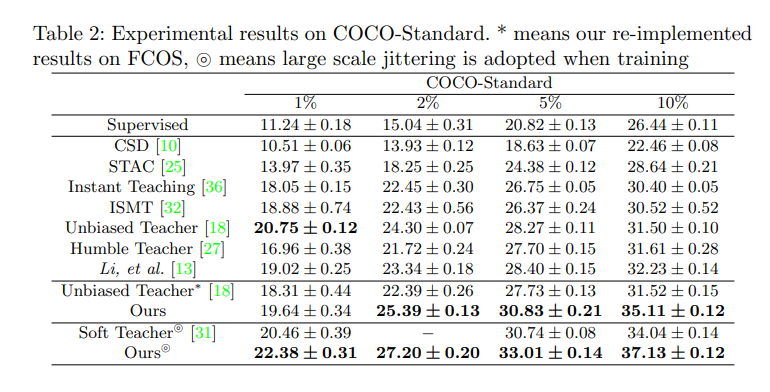
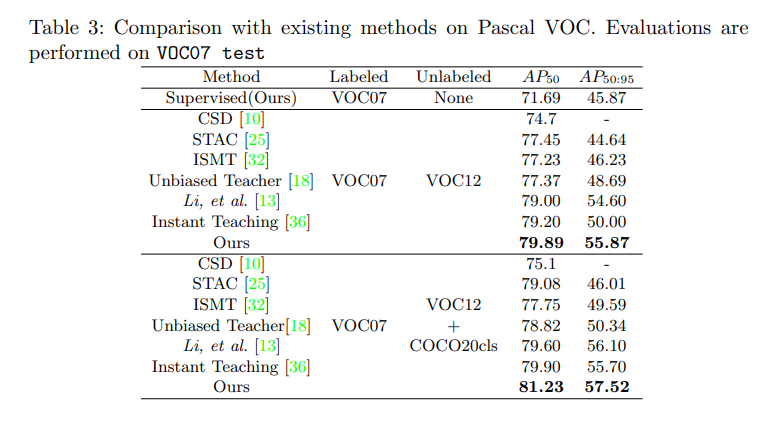
箭头的意思:baseline → result
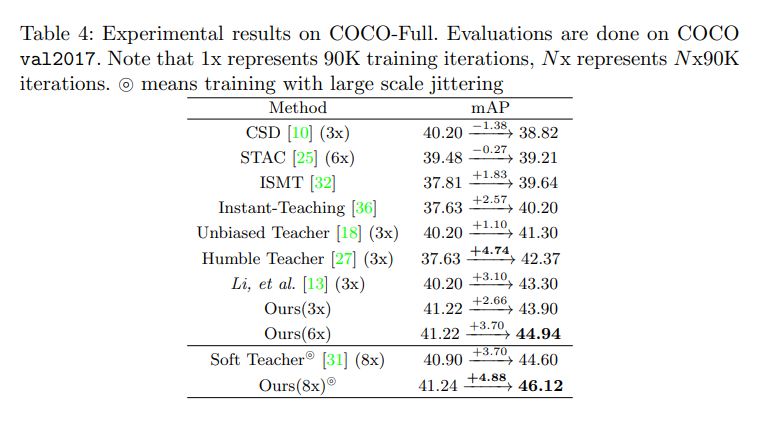
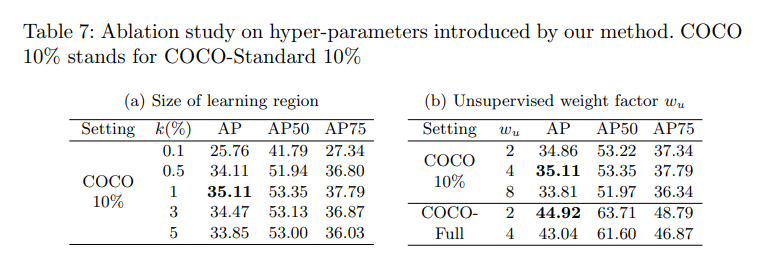
表 7 对比了选择不同的比例 k 对对性能的影响,选择 1% 时得到了最好的效果