AutoModel架构的输出(通用类,不带head部分)
In many cases, the architecture you want to use can be guessed from the name or the path of the pretrained model you are supplying to the from_pretrained() method. AutoClasses are here to do this job for you so that you automatically retrieve the relevant model given the name/path to the pretrained weights/config/vocabulary. – 官方原文
– 大概意思 AutoModel是个通用类,能从输入的预训练模型名称中或预训练模型存储路径中,自动生成相应模型的architecture(架构)并自动加载checkpoint(可以理解为对应层的权重参数)
– BertModel 专用于加载BERT架构模型的基础类。
from transformers import (
AutoTokenizer,
AutoModel,
AutoConfig,
AutoModelForMaskedLM,
AutoModelForSequenceClassification,
AutoModelForTokenClassification)
# 记载预训练模型
auto_model = AutoModel.from_pretrained(model_path)
bert_model = BertModel.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 验证AutoModel和BertModel加载同一个模型输出结果
data = tokenizer(text=['我爱你'],return_tensors='pt')
auto_model(data.input_ids).last_hidden_state
bert_model(data.input_ids).last_hidden_state
'''
tensor([[[ 0.0963, 0.0306, -0.0745, ..., -0.6741, 0.0229, -0.3951],
[ 0.8193, -0.4155, 0.4848, ..., -0.7079, 0.5251, -0.2706],
[ 0.2164, 0.2476, -0.2831, ..., -0.1583, 0.1191, -1.0851],
[ 0.8606, -0.5950, 0.8120, ..., -0.4619, 0.1180, -0.4674],
[ 0.0963, 0.0306, -0.0745, ..., -0.6741, 0.0229, -0.3951]]],
grad_fn=<NativeLayerNormBackward>)
tensor([[[ 0.0963, 0.0306, -0.0745, ..., -0.6741, 0.0229, -0.3951],
[ 0.8193, -0.4155, 0.4848, ..., -0.7079, 0.5251, -0.2706],
[ 0.2164, 0.2476, -0.2831, ..., -0.1583, 0.1191, -1.0851],
[ 0.8606, -0.5950, 0.8120, ..., -0.4619, 0.1180, -0.4674],
[ 0.0963, 0.0306, -0.0745, ..., -0.6741, 0.0229, -0.3951]]],
grad_fn=<NativeLayerNormBackward>)
'''
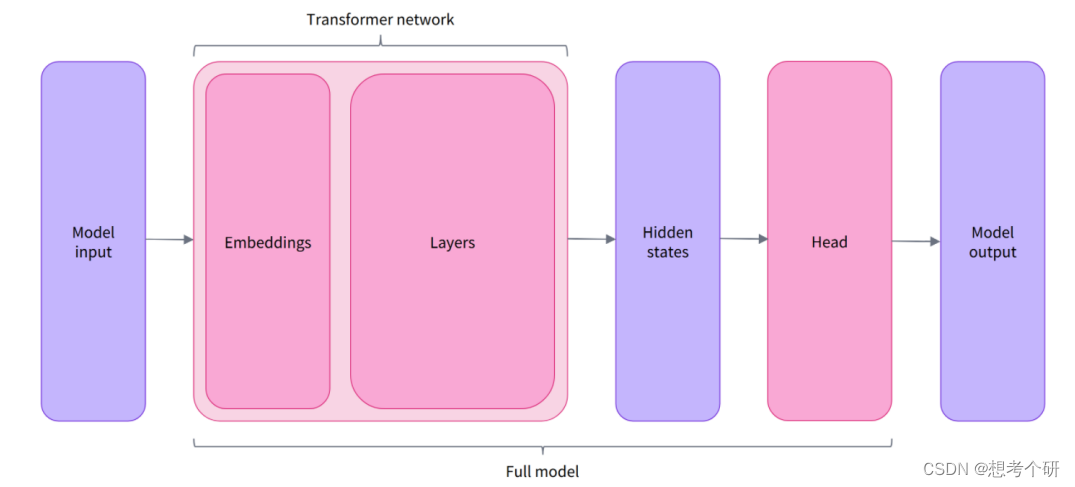
AutoModel类输出:
- 输出为BaseModelOutputWithPoolingAndCrossAttentions。
- 包含’last_hidden_state’和’pooler_output’两个元素。
- 'last_hidden_state’的形状是(batch size,sequence length,768)
data = tokenizer(text=['我爱你'],return_tensors='pt')
model = AutoModel.from_pretrained(model_path)
outputs = model(**data)
outputs.keys()
outputs.last_hidden_state.shape # 最后一层隐藏层输出
outputs.pooler_output.shape # pooler output是取[CLS]标记处对应的向量后面接个全连接再接tanh激活后的输出
'''
odict_keys(['last_hidden_state', 'pooler_output'])
torch.Size([1, 5, 768]) (batch,sequence_len,word_embedding_szie)
torch.Size([1, 768]) (batch,word_embedding_szie)
'''