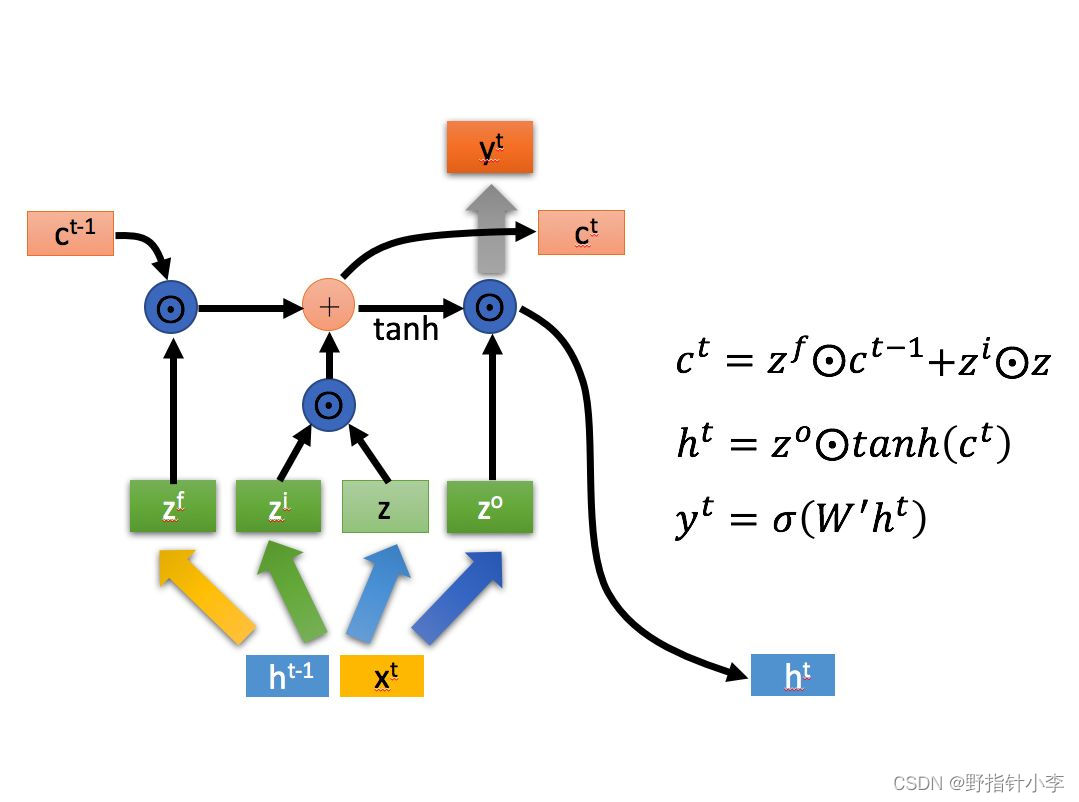
坦白的说,其实我也不懂 LSTM,但是我这里还是尽我最大的可能解释这个模型。这里我就盗个图 [1](懒得自己画了,而且感觉好像他也是盗的李宏毅老师课件的图)。 简单来说,LSTM 在每个时刻的输入都是由该时刻输入的序列信息
X
t
X^t
Xt 与上一时刻的隐藏状态
h
t
−
1
h^{t-1}
ht−1 通过四种不同的非线性变化映射而成,分别为:
遗忘门控信号:遗忘门控信号
z
f
z^f
zf 的计算公式如下:
z
f
=
s
i
g
m
o
i
d
(
W
f
[
X
t
;
h
t
−
1
]
)
,
z^f = {\rm sigmoid}(W^f\left[ X^t; h^{t-1} \right]),
zf=sigmoid(Wf[Xt;ht−1]), 其中,
[
X
t
;
h
t
−
1
]
[X^t;h^{t-1}]
[Xt;ht−1] 是将
X
t
X^t
Xt 与
h
t
−
1
h^{t-1}
ht−1 拼接起来;
W
f
W^f
Wf 是权重;
S
i
g
m
o
i
d
(
⋅
)
{\rm Sigmoid}(\cdot)
Sigmoid(⋅) 是 Sigmoid 激活函数,用于将数据映射到 (0, 1) 的区间范围内。
记忆门控信号:记忆门控信号
z
i
z^i
zi 的计算公式如下:
z
i
=
s
i
g
m
o
i
d
(
W
i
[
X
t
;
h
t
−
1
]
)
.
z^i={\rm sigmoid}(W^i\left[ X^t; h^{t-1} \right]).
zi=sigmoid(Wi[Xt;ht−1]).
输出门控信号:输出门控信号
z
o
z^o
zo 的计算公式如下:
z
o
=
s
i
g
m
o
i
d
(
W
o
[
X
t
;
h
t
−
1
]
)
.
z^o = {\rm sigmoid}(W^o\left[ X^t; h^{t-1} \right]).
zo=sigmoid(Wo[Xt;ht−1]).
当前时刻的信息:当前时刻的信息
z
z
z 的计算公式如下:
z
=
t
a
n
h
(
W
[
X
t
;
h
t
−
1
]
)
,
z = {\rm tanh}(W\left[ X^t; h^{t-1} \right]),
z=tanh(W[Xt;ht−1]), 其中,
t
a
n
h
(
⋅
)
{\rm tanh}(\cdot)
tanh(⋅) 是将数据放缩到 (-1, 1) 的区间内。
通过以上的公式,我们可以发现,
z
f
,
z
i
,
z
o
z^f, z^i, z^o
zf,zi,zo 都是 (0, 1) 区间的值,而
z
z
z 是 (-1, 1) 区间的值。
接着就是 LSTM 的内部计算公式,即图上所示的那几个,分别为:
当前时刻的细胞状态
c
t
c^t
ct 的计算公式如下:
c
t
=
z
f
⊙
c
t
−
1
+
z
i
⊙
z
,
c^t = z^f \odot c^{t-1} + z^i \odot z,
ct=zf⊙ct−1+zi⊙z, 其中,
⊙
\odot
⊙ 是哈达玛积,即矩阵元素对位相乘,但是需要注意的是,哈达玛积数学上不可解释,但是跑出来效果好。
当前时刻的隐藏状态
h
t
h^t
ht 的计算公式如下:
h
t
=
z
o
⊙
t
a
n
h
(
c
t
)
.
h^t = z^o \odot {\rm tanh} (c^t).
ht=zo⊙tanh(ct).
当前时刻的输出
y
t
y^t
yt 的计算公式如下:
y
t
=
σ
(
W
′
h
t
)
.
y^t = \sigma (W'h^t).
yt=σ(W′ht).
公式列举完后,这里说一下我对这些公式的理解(不一定是对的哈)。
首先是
c
t
c^t
ct 的计算。我们看到
c
t
c^t
ct 的计算分为了两部分。一部分是
z
f
⊙
c
t
−
1
z^f \odot c^{t-1}
zf⊙ct−1,这一部分是 LSTM 的遗忘过程,由于刚刚提到,
z
f
z^f
zf 是 (0, 1) 区间范围内的值,同时,sigmoid 函数是一个无限趋近于 0 或者 1 的函数,也就是说,
c
t
−
1
c^{t-1}
ct−1无论怎样,都会有些数据被遗弃,始终不会完全保留下来,这也就模拟了一个遗忘的过程。同理,对于记忆部分
z
i
⊙
z
z^i \odot z
zi⊙z,这一步也是只会保留部分
z
z
z 的信息,也就模拟了人的记忆是由些许失真的过程。同时,两者相加后,那么就代表了当前细胞状态
c
t
c^t
ct 中保留的是没有被遗忘掉的过去的信息和当前时刻被记忆下来的信息。
接着是
h
t
h^t
ht 的计算。首先是为什么要先对
c
t
c^t
ct 做一次
t
a
n
h
(
⋅
)
{\rm tanh}(\cdot)
tanh(⋅),这是因为由于
c
t
c^t
ct 的区间范围不是 (-1, 1),因为
z
i
⊙
z
z^i \odot z
zi⊙z 的区间范围是 (-1, 1),再与
z
f
⊙
c
t
−
1
z^f \odot c^{t-1}
zf⊙ct−1 相加,那么
c
t
c^t
ct 的范围就有可能超出 (-1, 1),所以先用一个 tanh 将数值给放缩到 (-1, 1) 内。接着再与
z
o
z^o
zo 做一次哈达玛积后,得到的隐藏状态就是 (-1, 1) 的数据,那么该数据放到后续模块中,就可以代表当前时刻的输入是正的还是负的,同时有多大。
最后就是
y
t
y^t
yt 的计算,实际上这就是个全连接层,将隐藏状态进行一次映射,再通过一个非线性变化的激活函数。
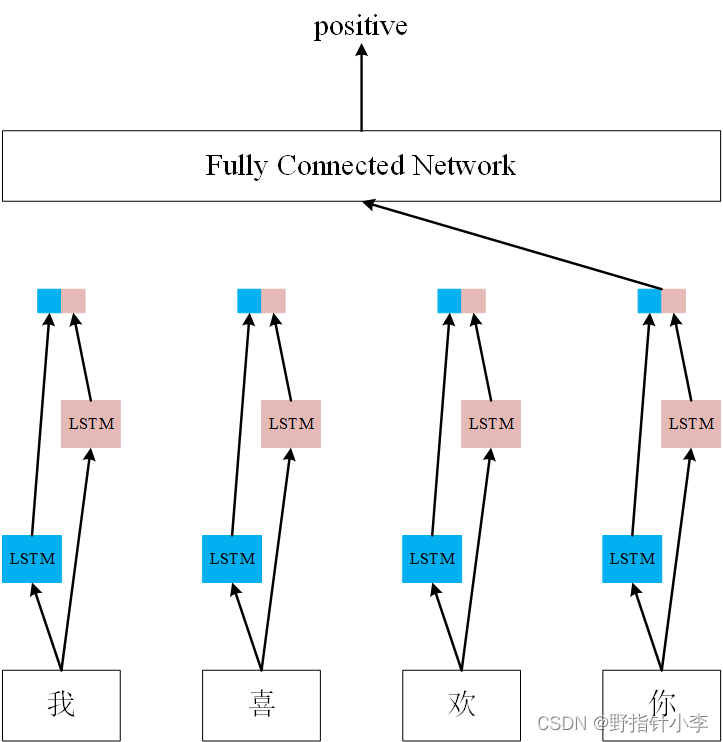
首先,这是一个序列模型,它接受一个序列的输入,并且输出这个序列的信息。对于序列中每个位置的输出,它会包含该位置的信息以及之前的信息。就是说 LSTM 能够捕获到位置
t
t
t 及其之前位置的信息。而对于 BiLSTM 的话,则能捕获到
t
t
t 的双向信息。
如果是 BiLSTM,它的每个位置的输出,是前向
L
S
T
M
→
\overrightarrow{LSTM}
LSTM 的输出
y
→
\overrightarrow{y}
y 与反向
L
S
T
M
←
\overleftarrow{LSTM}
LSTM 的输出
y
←
\overleftarrow{y}
y 拼接在一起的,
[
y
→
;
y
←
]
[\overrightarrow{y}; \overleftarrow{y}]
[y;y]。所以假设你设置 LSTM 的隐藏层维度为 128,那么单向 LSTM 的输出维度是 128,但是双向就是 256 (128*2).
这里有个小细节要注意一下,通常在论文的公式里面,我们都会看到别人写的分类器的公式如下:
y
^
=
S
o
f
t
m
a
x
(
W
h
+
b
)
\hat{y} = {\rm Softmax}(Wh+b)
y^=Softmax(Wh+b),有个 softmax 的激活函数,但是在 pytorch 中实际不需要,就比如我代码里面是写的: