1.1,首先导入包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
import calendar # 日历
import warnings
warnings.filterwarnings('ignore')
1.2,导入数据集及处理数据集
data = pd.read_csv('train.csv')
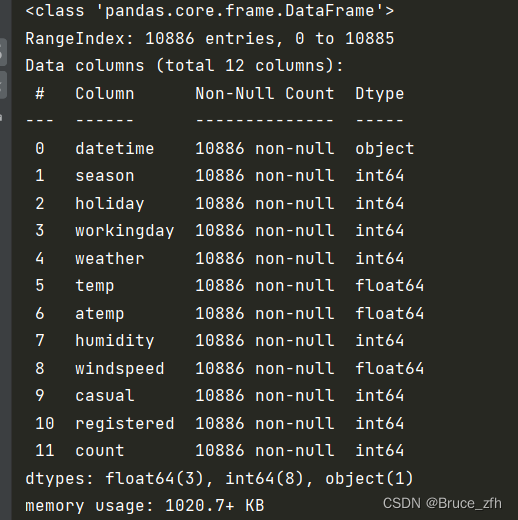
data.info()
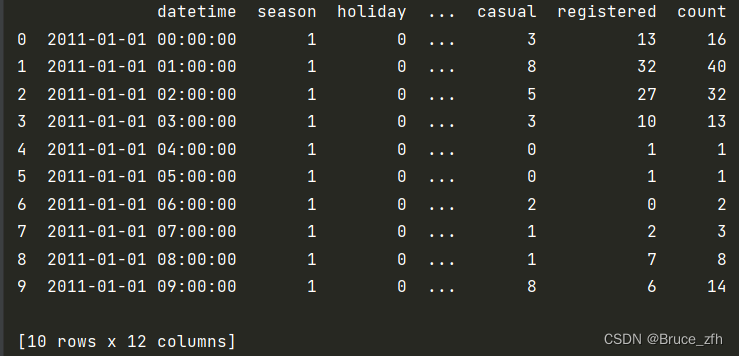
print(data.head(10))
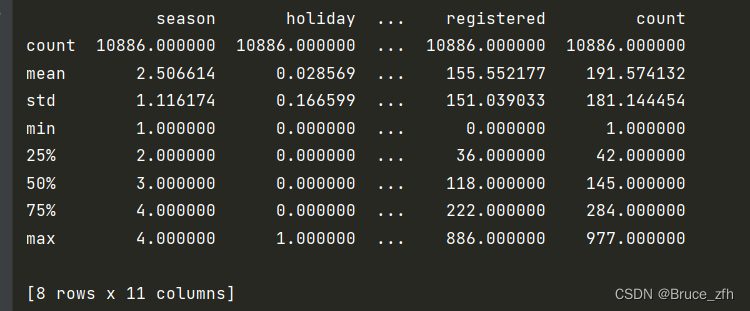
print(data.describe())
经典的数据集查看三连,可以得出一下
分别获取月份,天,小时的信息
#获取月份信息
def get_month(md): #2011-01-01 00:00:00
#返回时间的datetime对象
#month_obj = datetime.datetime.strptime(md,'%Y-%m-%d %H:%M:%S')
month_obj = datetime.datetime.fromisoformat(md)
#返回datetime中对应的月份信息
return month_obj.month
#获取天的信息
def get_day(md): #2011-01-01 00:00:00
#返回时间的datetime对象
day_obj = datetime.datetime.fromisoformat(md)
#返回datetime中对应的月份信息
return day_obj.day
#获取小时信息
def get_hour(md):
#返回时间的datetime对象
hour_onj = datetime.datetime.formisoformat(md)
#返回datetime中对应的月份信息
return hour)obj.hour
python时间处理datetime模块的datetime对象提供的fromisoformat方法将符合isoformat时间格式的字符串转为datetime对象,比如“2022-06-02”和“2022-06-02 07:39:00”,这种方式比较简便,因此传统代码注释供参考
将月份,天,小时添加到data中
date['month'] = date['datetime'].map(get_month)
date['day'] = date['datetime'].map(get_day)
date['hour'] = date['datetime'].map(get_hour)
调用刚刚创建的三个函数
# 获取月份名字
def creat_month_name(n):
# 返回datetime中对应的月份信息
month_value = datetime.datetime.fromisoformat(n).month
return calendar.month_name[month_value]
# 获取天的名字
def creat_day_name(n):
# 返回datetime中对应的月份信息
day_value = datetime.datetime.fromisoformat(n).weekday()
return calendar.month_name[day_value]
# 添加月份和星期名字到字段中
data['month_name'] = data['datetime'].map(creat_month_name)
data['day_name'] = data['datetime'].map(creat_day_name)
设置时间段函数,并添加时间段字段
def creat_hour_type(n):
if 0 <= n <=6:
return 1
elif 7 <= n <= 10:
return 2
elif 11 <= n <=15:
return 3
elif 16 <= n <= 20:
return 4
else:
return 5
#添加时间段字段
data['hour_tyoe'] = data['hour'].map(creat_hour_type)
data.info()
如图将一天二十四个小时划分为五个时间段字段
下面就开始简单的绘图了
sns.pointplot(data=data,x='hour',y='count')
plt.show()
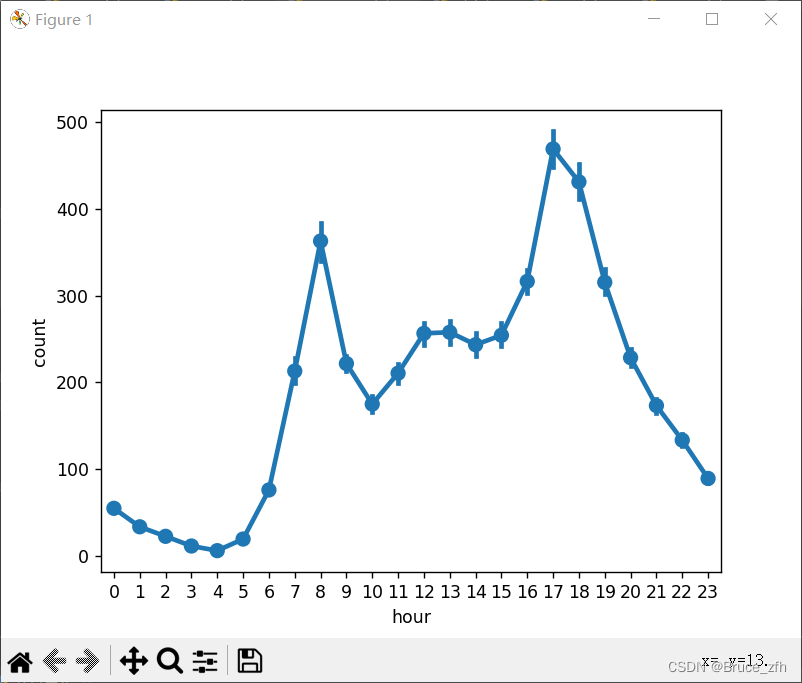
可以简单的看到随着一天中二十四个小时的变化骑行人数随之变化
sns.pointplot(data=data,x='hour_type',y='count')
plt.show()
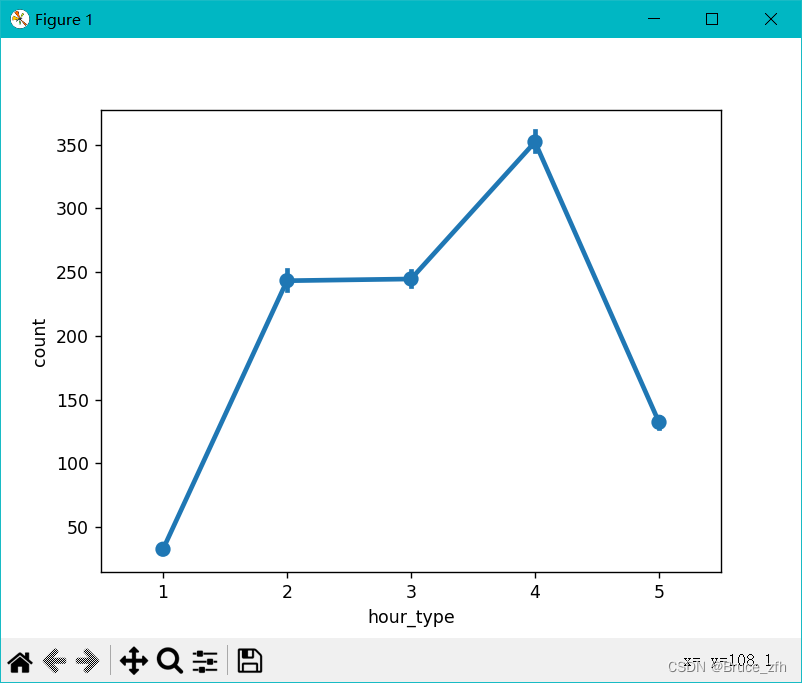
可以从字段中简要看出五个时间段中骑行人数在一天中的大致变化
sns.pointplot(data=data, x='month', y='count')
plt.show()
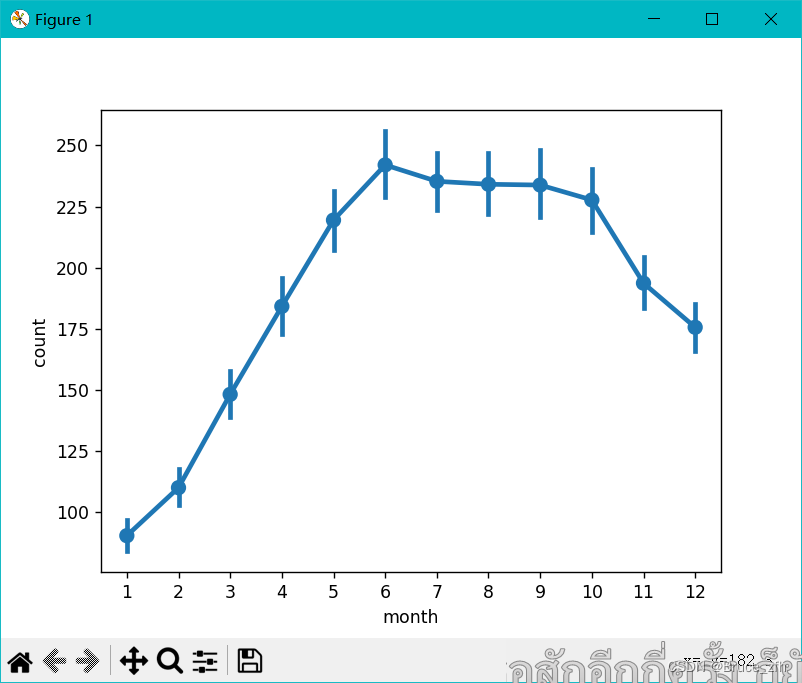
如图,这是一年十二个月骑行人数大致的变化趋势
上面三张图都为线性图,现在为大家上两张箱型图进一步了解数据集
sns.boxplot(
data=data,
y='count',
)
plt.show()
sns.boxplot(
data=data,
x='season',
y='count',
)
plt.show()
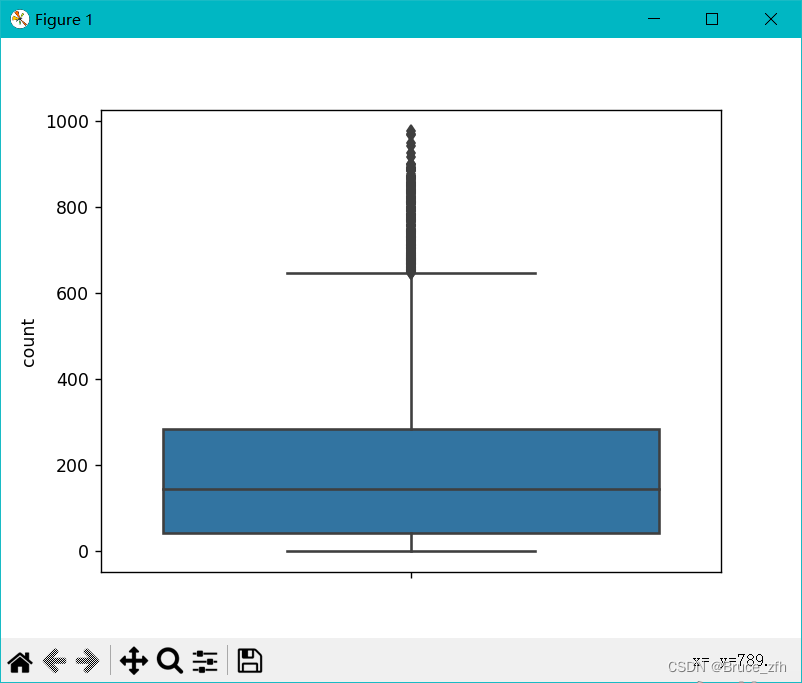
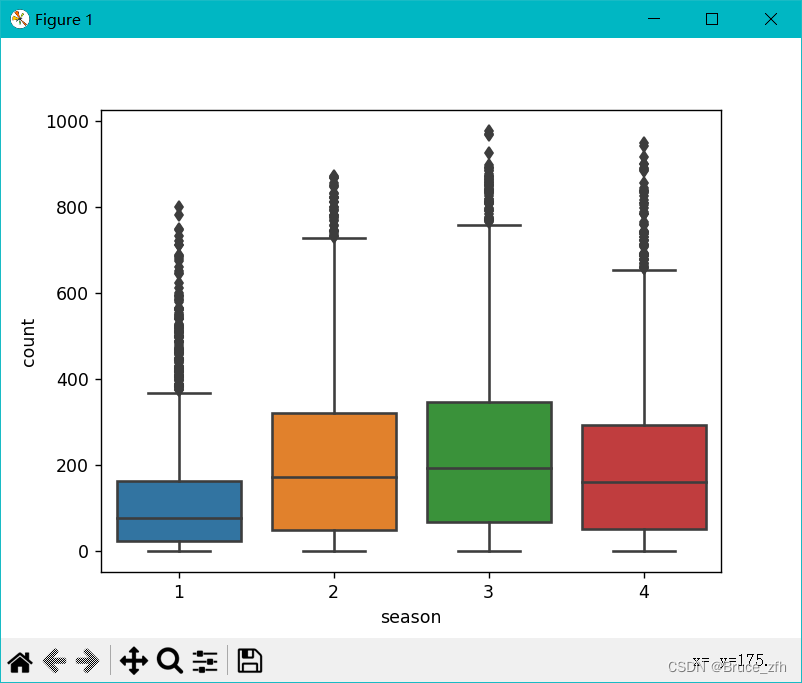
以上简单了解一下数据集后咱们进入下一步
对数据集进行处理
# iloc ----> 需要使用字段索引或行索引,对数据切分获取,iloc[:,9]
# loc ----> 需要使用字段名或行名对数据进行切分获取 ,loc[:,['count']]
介绍一下两种划分数据集的方法后,咱们进行截取骑行量数据
dd_count = data.loc[:, ['count']]
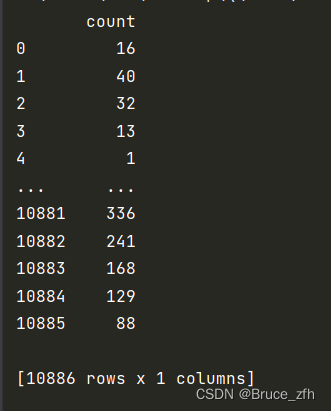
# 骑行量的均值
dd_count_mean = np.mean(dd_count)
# 骑行量的标准差
dd_count_std = np.std(dd_count)
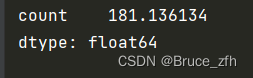
获取这些数据后咱们再通过上面两种箱型图可以看出来有很多的异常值,这里也可以说成噪声,首先说一下噪声的判断条件: 数据点 - 均值 > 3 * 标准差
通过距离值与三倍的标准差相比,大的就是异常值,否则就是正常,直接上代码
dd_count = dd_count - dd_count_mean
noie_opt = dd_count > 3 * dd_count_std
noie_opt_valu = noie_opt.values.flatten()

之后咱们获取一下非噪声数据
~ 对当前数据取反
dd_data_good = data.loc[~noie_opt_valu, :]

非噪声数据取出后咱们画一张热力图看一下
heat_map_list = ['count', 'weather', 'temp', 'atemp', 'windspeed', 'casual', 'registered']
# 取出上面列表中的字段数据
dd_data_keep = dd_data_good.loc[:, heat_map_list]
# 计算皮尔逊相关系数
dd_data_keep_corr = dd_data_keep.corr()
sns.heatmap(
data=dd_data_keep_corr,
annot=True
)
plt.show()
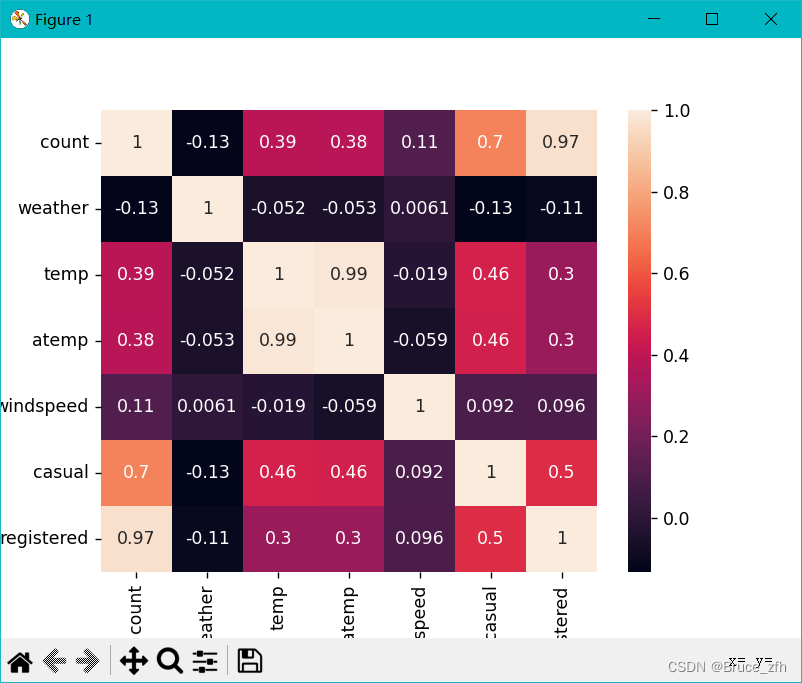
简要了解后进入正题
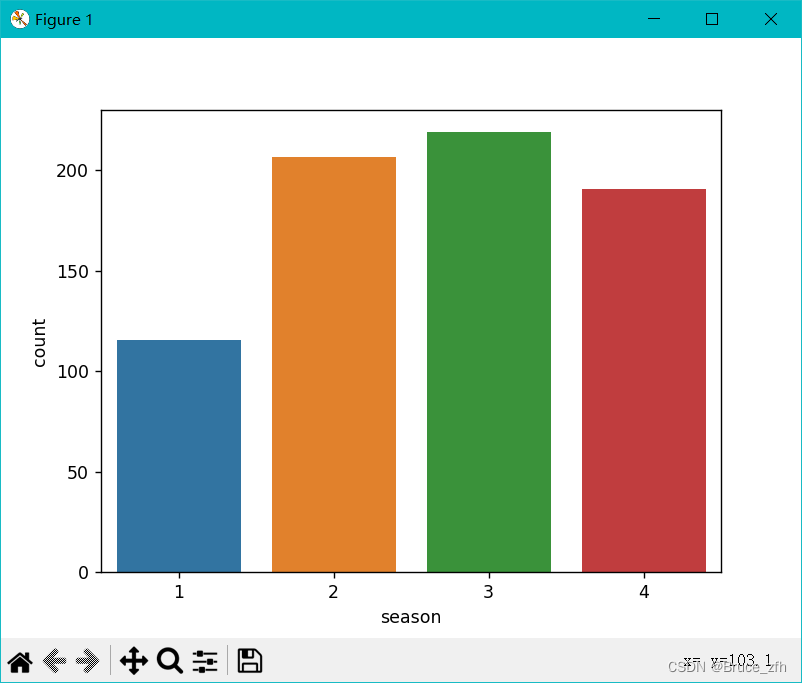
咱们先分析一下不同季节对骑行量的影响
按照‘season’字段进行分组,并得到分组后字段的平均值
season_gd = dd_data_good.groupby(by=['season']).mean()
holiday workingday weather ... day hour hour_type
season ...
1 0.026473 0.680089 1.425056 ... 9.960477 11.633482 2.736018
2 0.017817 0.688196 1.427246 ... 9.990349 11.426503 2.692279
3 0.036036 0.667417 1.368619 ... 9.981231 11.383634 2.682432
4 0.035569 0.671360 1.461282 ... 10.000741 11.473138 2.702112
# 重置索引
season_gd_good = season_gd.reset_index()
season holiday workingday ... day hour hour_type
0 1 0.026473 0.680089 ... 9.960477 11.633482 2.736018
1 2 0.017817 0.688196 ... 9.990349 11.426503 2.692279
2 3 0.036036 0.667417 ... 9.981231 11.383634 2.682432
3 4 0.035569 0.671360 ... 10.000741 11.473138 2.702112
#上条形图
sns.barplot(
data=season_gd_good,
x='season',
y='count'
)
plt.show()
# # 按照'season','hour'字段进行分组统计
season_gd = dd_data_good.groupby(by=['season', 'hour']).mean().reset_index()
sns.barplot(
data=season_gd,
x='hour',
y='count',
hue='season'
)
plt.show()
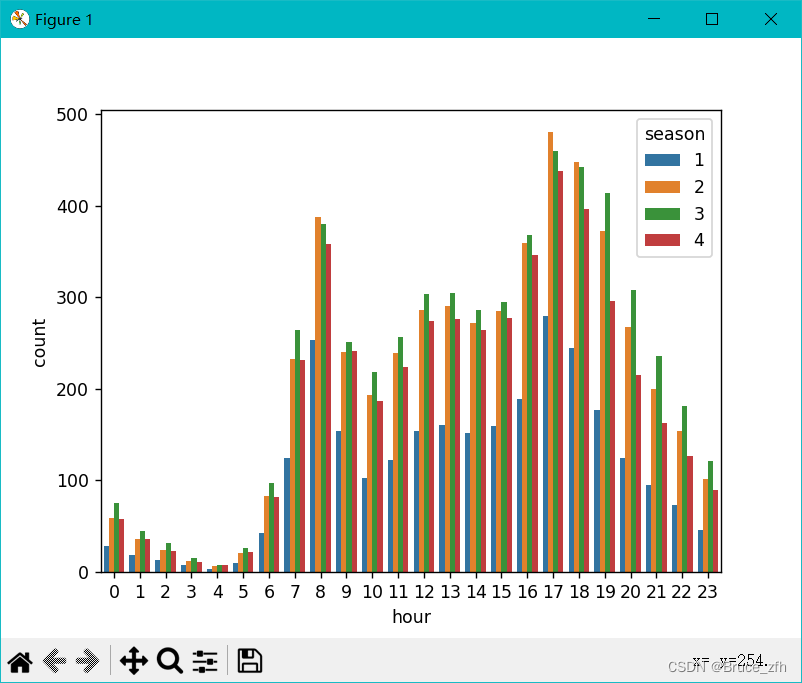
上完图后咱们进一步处理数据
删除冗余字段 datetime month hour
dd_data_good.drop('datetime', inplace=True, axis=1)
dd_data_good.drop('month', inplace=True, axis=1)
dd_data_good.drop('hour', inplace=True, axis=1)
穿插一点小知识点
离散型:人为定义的数据,都是自然数 ,可数的 obj/int -----> 独热
连续型:在某一个区间之内【35,37。2】 float64 -----> 标准化/归一化
#独热处理离散型数据
dd_data_good = pd.get_dummies(data=dd_data_good, columns=['season', 'month_name', 'day_name', 'hour_type', 'weather'])
#进行特征缩放,导入标准化包
from sklearn.preprocessing import StandardScaler
fs_list = ['temp', 'atemp', 'windspeed', 'humidity', 'casual', 'registered']
for i in fs_list:
dd_data_good[i] = StandardScaler().fit_transform(dd_data_good[[i]])
# dd_data_good[i]---> 取出的是一维数据【1,2,3。。。】
# 标准化----> 二维数据,dd_data_good[[i]]
#导入岭回归包,
from sklearn.linear_model import Ridge
#导入train_test_split 包进行纯随机采样 , 导入GridSearchCV 进行网格搜索交叉验证,寻找最优参数
from sklearn.model_selection import train_test_split, GridSearchCV
# 准备特征和标签矩阵 标签 -----> count 要预测什么,要分析什么数据
y = dd_data_good.pop('count') # pop 将指定数据取出,原始数据集中就没有了,作为返回值给变量
x = dd_data_good
# dataframe 数据类型转化为矩阵类型,矩阵类型的数据更适合机器学习
x_arr = np.array(x)
y_arr = np.array(y)
# 切分训练集测试集
x_train,x_test,y_train,y_test = train_test_split(x_arr,y_arr,test_size=0.2)
# 调用线性回归
robj = Ridge()
# 网格搜索交叉验证 -----> 确定参数
gmodel = GridSearchCV(robj,param_grid={'alpha':[1.0,0.3,0.5,0.002,0.2]},cv=5)
# 训练找最优惨
gmodel.fit(x_train,y_train)
# 打印最优惨
print(gmodel.best_params_)
# 将最优参数传入模型训练
robj = Ridge(alpha=gmodel.best_params_['alpha'])
robj.fit(x_train,y_train)
# 预测
y_pre= robj.predict(x_test)

# 评分
print(robj.score(x_train,y_train))

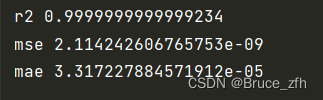
获取r2,mse,mae值
# 模型评估 r2,mse,mae
from sklearn.metrics import r2_score,mean_squared_error,mean_absolute_error
print('r2',r2_score(y_test,y_pre))
print('mse',mean_squared_error(y_test,y_pre))
print('mae',mean_absolute_error(y_test,y_pre))
以上就是共享单车项目的总流程欢迎大家在评论区探讨,生活不易,随手留个