q
=
x
W
q
,
k
=
x
W
k
,
v
=
x
W
v
,
z
(
m
)
=
σ
(
q
(
m
)
k
(
m
)
⊤
/
d
)
v
(
m
)
,
m
=
1
,
…
,
M
,
z
=
Concat
(
z
(
1
)
,
…
,
z
(
M
)
)
W
o
,
z
l
′
=
MHSA
(
LN
(
z
l
−
1
)
)
+
z
l
−
1
,
z
l
=
MLP
(
LN
(
z
l
′
)
)
+
z
l
′
,
\begin{aligned} q&=x W_{q}, k=x W_{k}, v=x W_{v}, \\ z^{(m)}&=\sigma\left(q^{(m)} k^{(m) \top} / \sqrt{d}\right) v^{(m)}, m=1, \ldots, M, \\ z&=\text { Concat }\left(z^{(1)}, \ldots, z^{(M)}\right) W_{o}, \\ z_{l}^{\prime} &=\operatorname{MHSA}\left(\operatorname{LN}\left(z_{l-1}\right)\right)+z_{l-1}, \\ z_{l} &=\operatorname{MLP}\left(\operatorname{LN}\left(z_{l}^{\prime}\right)\right)+z_{l}^{\prime}, \end{aligned}
qz(m)zzl′zl=xWq,k=xWk,v=xWv,=σ(q(m)k(m)⊤/d)v(m),m=1,…,M,= Concat (z(1),…,z(M))Wo,=MHSA(LN(zl−1))+zl−1,=MLP(LN(zl′))+zl′,
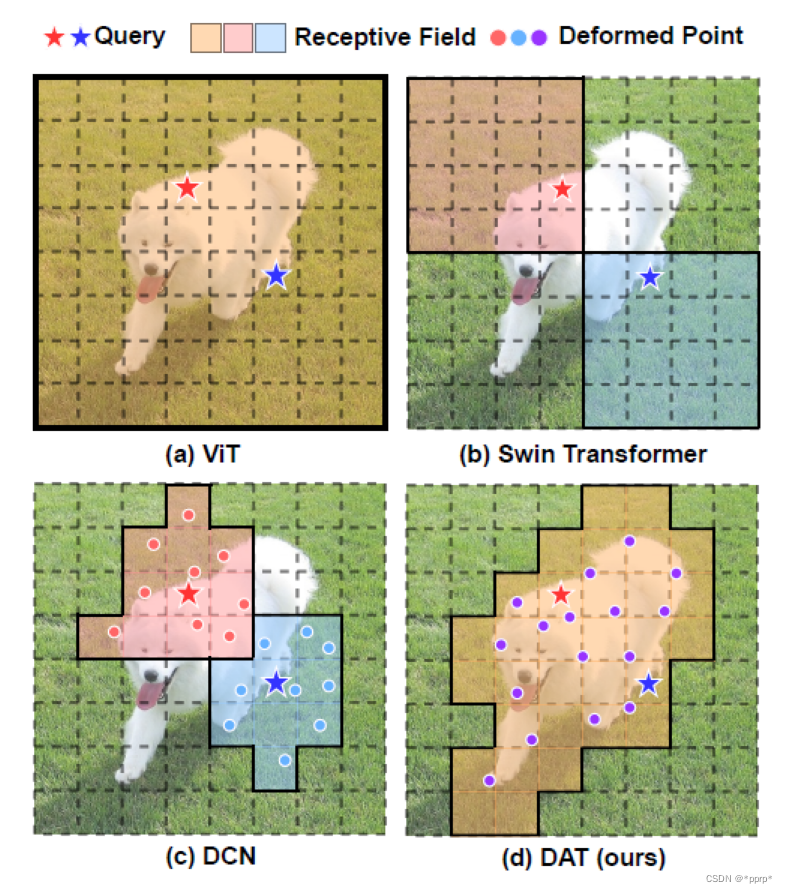
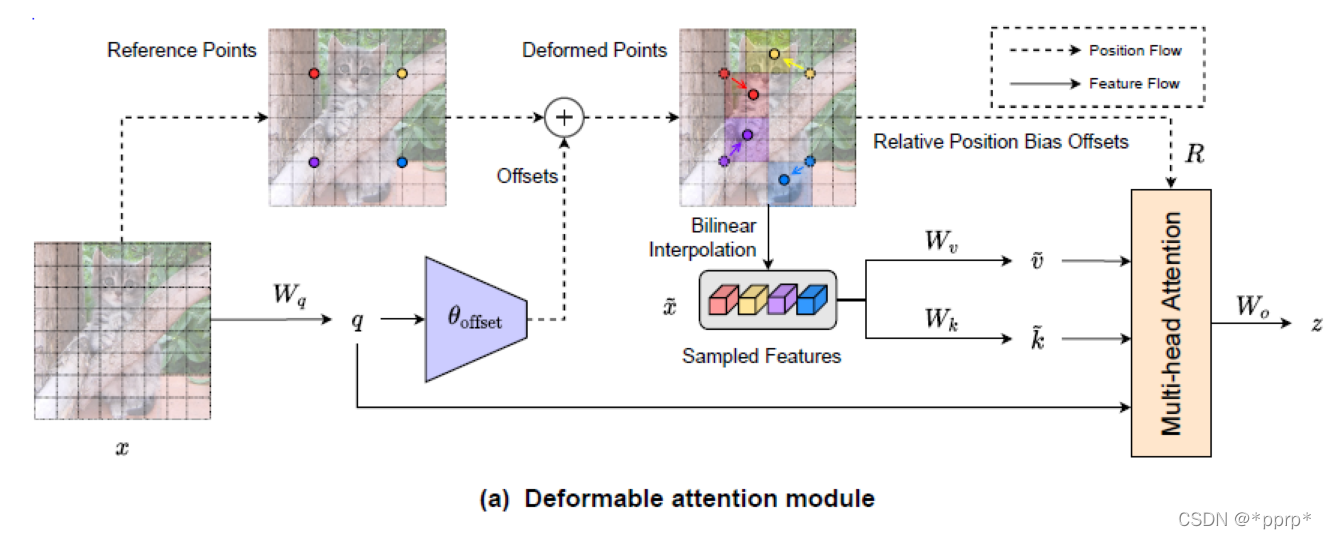
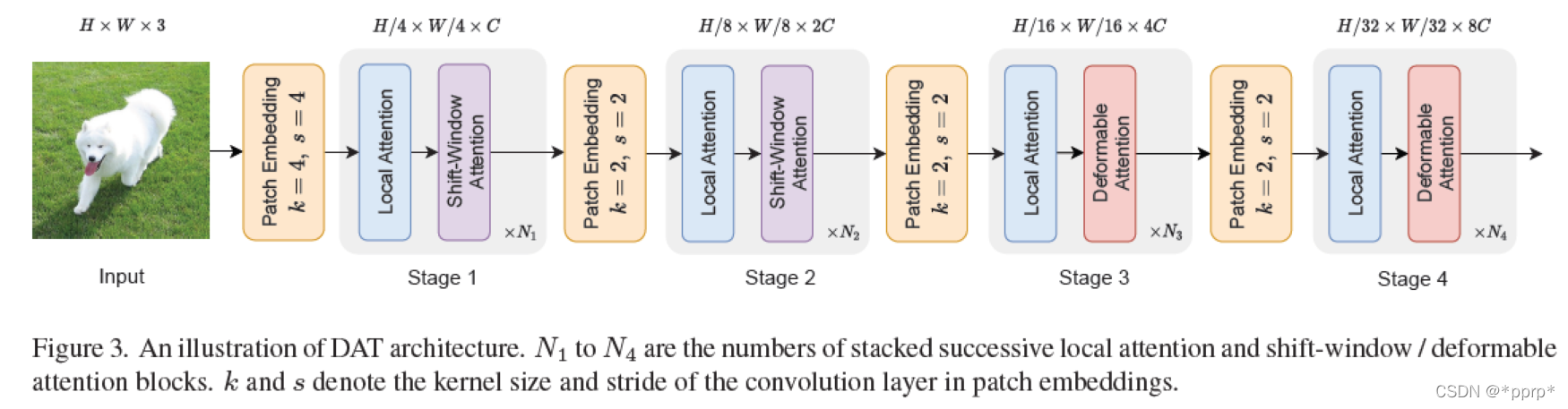
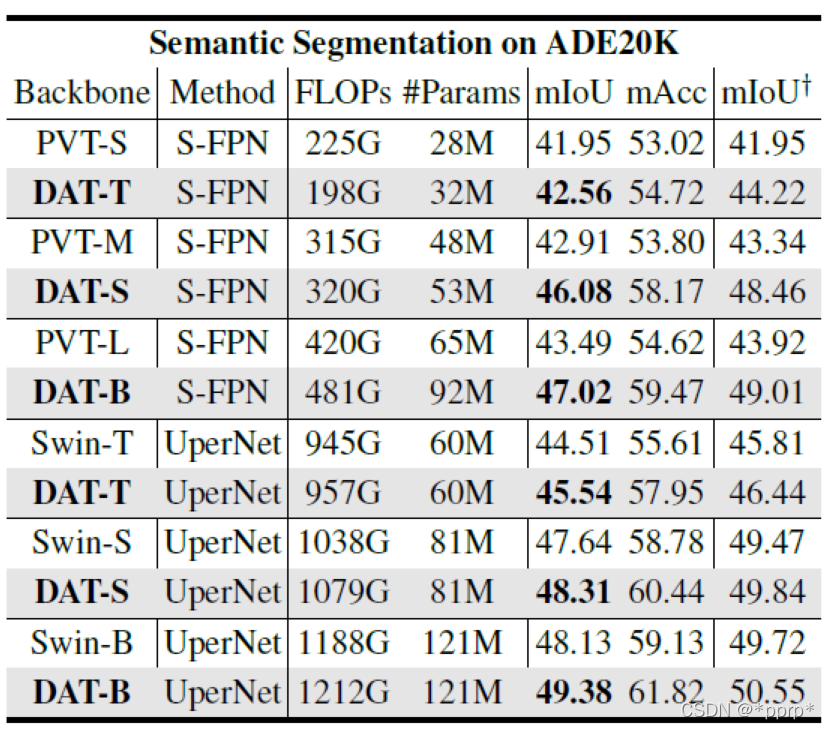
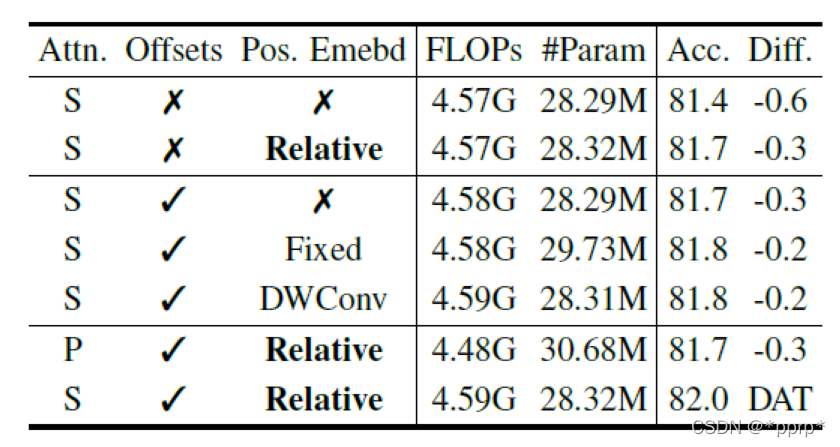
有了以上铺垫,下图就是本文最核心的模块Deformable Attention。
左边这部分使用一组均匀分布在feature map上的参照点
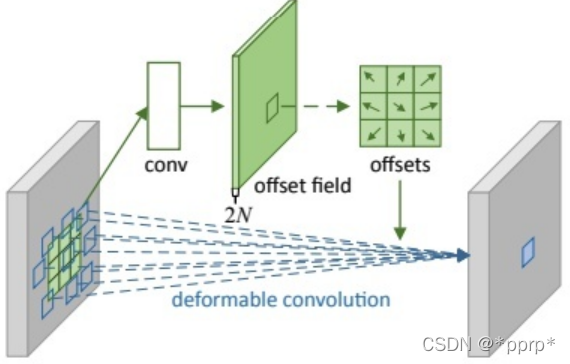
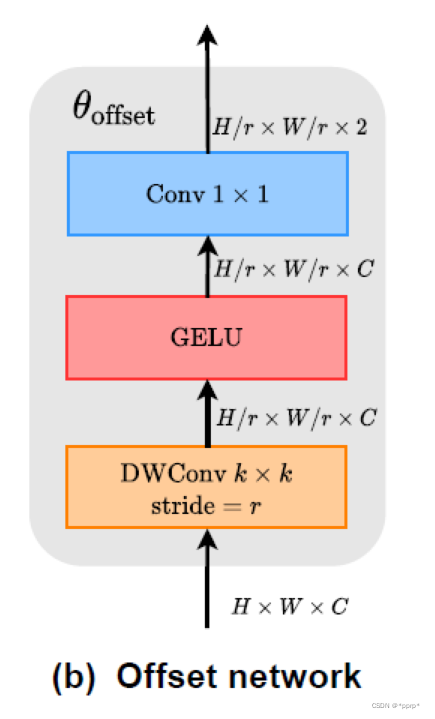
然后通过offset network学习偏置的值,将offset施加于参照点中。
在得到参照点以后使用bilinear pooling操作将很小一部分特征图抠出来,作为k和v的输入
x_sampled = F.grid_sample(
input=x.reshape(B * self.n_groups, self.n_group_channels, H, W),
grid=pos[..., (1, 0)], # y, x -> x, y
mode='bilinear', align_corners=True) # B * g, Cg, Hg, Wg
之后将得到的Q,K,V执行普通的self-attention, 并在其基础上增加relative position bias offsets。
q_off = einops.rearrange(q, 'b (g c) h w -> (b g) c h w', g=self.n_groups, c=self.n_group_channels)
offset = self.conv_offset(q_off) # B * g 2 Hg Wg
Hk, Wk = offset.size(2), offset.size(3)
n_sample = Hk * Wk
在参照点基础上使用offset
offset = einops.rearrange(offset, 'b p h w -> b h w p')
reference = self._get_ref_points(Hk, Wk, B, dtype, device)
if self.no_off:
offset = offset.fill(0.0)
if self.offset_range_factor >= 0:
pos = offset + reference
else:
pos = (offset + reference).tanh()