过拟合问题(Overfitting)
当我们对一个问题建立线性回归模型或逻辑回归模型时,不恰当的选择特征会导致过拟合问题。过拟合问题是指当我们选择了很多的特征值时,模型对数据集的每一个example都符合的很好,但是对新的example却预测不能,偏差较大。


解决方法
方法一:减少特征量的数量
方法二:正则化
本片博客暂不讨论方法一,着重于正则化的分析。
正则化(Regularization)
正则化的思想是保留所有特征量,而通过减小 的值解决过拟合,这样我们就可以在不舍弃任何一个有价值的量的前提下解决过拟合问题。
的值解决过拟合,这样我们就可以在不舍弃任何一个有价值的量的前提下解决过拟合问题。
线性回归正则化
线性回归正则化的具体操作方法是在代价函数后添加一项 ,其中
,其中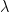 是正则化系数,这样
是正则化系数,这样
代价函数变为:
![\large J(\Theta ) = \frac{1}{2m}[\sum_{i=1}^{m}(h_\Theta (x^{(i)})-y^{(i)})^2+\lambda \sum_{j=1}^{n}\Theta _j^2]](https://private.codecogs.com/gif.latex?%5Cdpi%7B100%7D%20%5Clarge%20J%28%5CTheta%20%29%20%3D%20%5Cfrac%7B1%7D%7B2m%7D%5B%5Csum_%7Bi%3D1%7D%5E%7Bm%7D%28h_%5CTheta%20%28x%5E%7B%28i%29%7D%29-y%5E%7B%28i%29%7D%29%5E2+%5Clambda%20%5Csum_%7Bj%3D1%7D%5E%7Bn%7D%5CTheta%20_j%5E2%5D)
梯度下降算法变为:
repeat until convergence{

![\small \Theta _j := \Theta _j-\alpha *[\frac{1}{m} \sum_{i=1}^{m}((h_\Theta (x^{(i)})-y^{(i)})*x^{(i)}_j)+\frac{\lambda }{m}\Theta _j]](https://private.codecogs.com/gif.latex?%5Cdpi%7B100%7D%20%5Csmall%20%5CTheta%20_j%20%3A%3D%20%5CTheta%20_j-%5Calpha%20*%5B%5Cfrac%7B1%7D%7Bm%7D%20%5Csum_%7Bi%3D1%7D%5E%7Bm%7D%28%28h_%5CTheta%20%28x%5E%7B%28i%29%7D%29-y%5E%7B%28i%29%7D%29*x%5E%7B%28i%29%7D_j%29+%5Cfrac%7B%5Clambda%20%7D%7Bm%7D%5CTheta%20_j%5D)

}
正规方程法变为:
 ,其中E是(n+1)*(n+1)的单位矩阵。注意此时不存在不可逆的问题。
,其中E是(n+1)*(n+1)的单位矩阵。注意此时不存在不可逆的问题。
逻辑回归正则化
代价函数变为:

梯度下降算法变为:
repeat until convergence{
}
代码实现
通过使用MATLAB和Python,实现了逻辑回归的正则化处理。代码已上传至github,文件夹是machine-learning-ex2。
若对本篇博客有任何问题,欢迎指正,欢迎讨论。