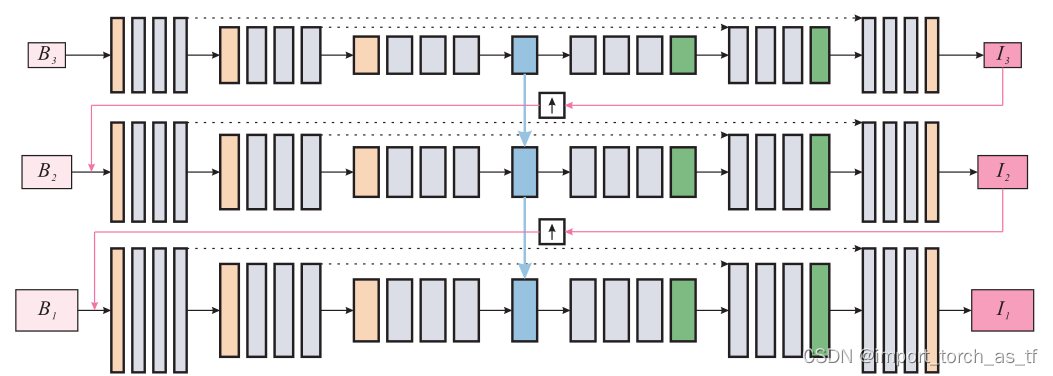
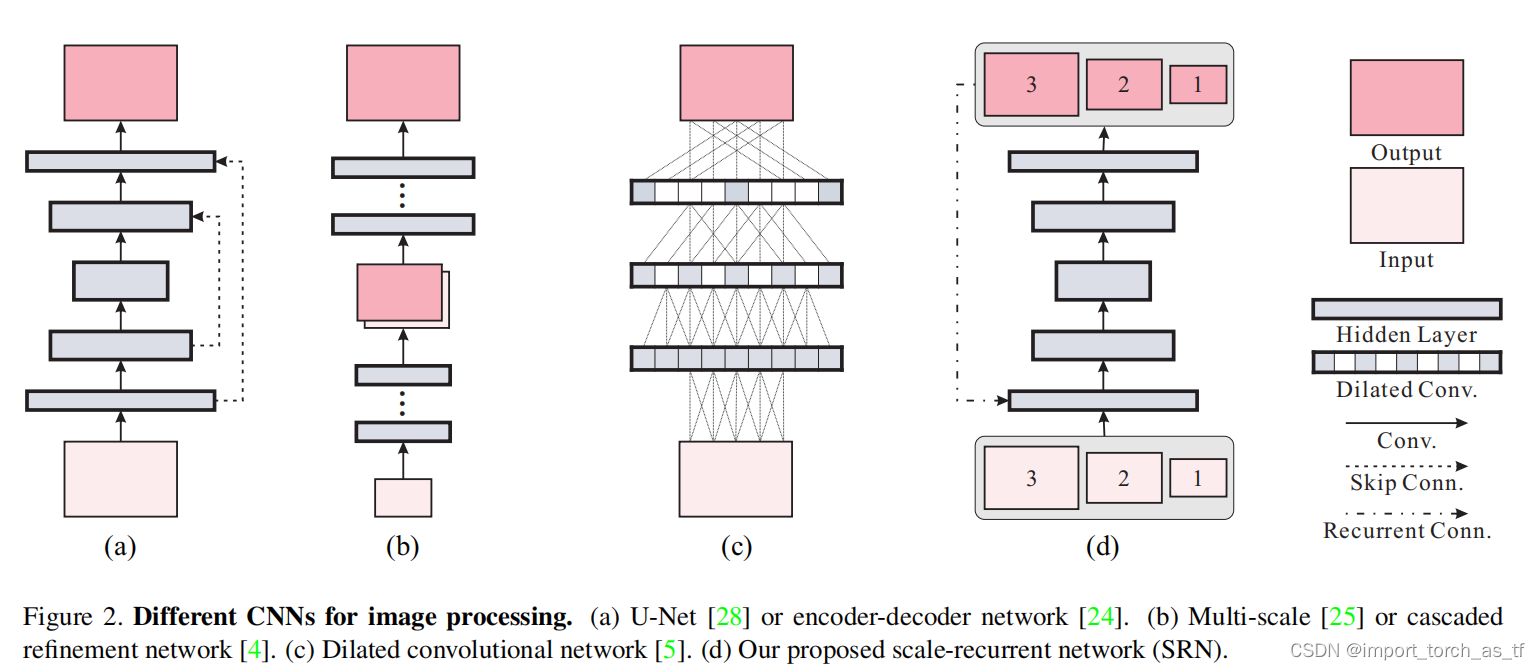
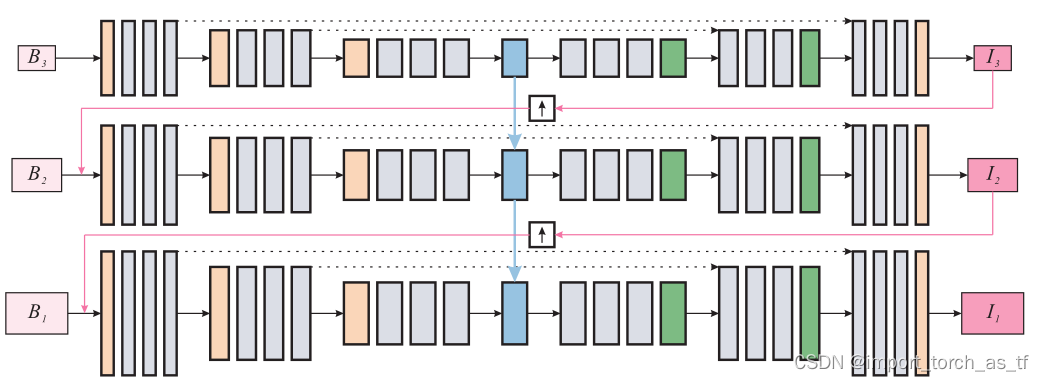
本论文中,作者研究了图像去模糊中的”coarse-to-fine”方案并提出了一个尺度循环网络——SRN-DeblurNet,用于图像去模糊任务。
该网络具有更简单的网络结构,更少的参数数量并且更容易训练。
图像去模糊的定义:给定一张因运动或失焦而模糊(由相机摇晃、目标快速移动或对焦不准而造成)的图像,去模糊的目标是恢复具有必要边缘结构和细节的清晰的latent image(后面称为“潜像”) 。
首先图像去模糊本身是个ill-posed problem。(当一个问题的解不能同时满足以下三个条件时,称该问题为ill-posed problem:1. 解必须存在;2. 解必须唯一; 3. 解能根据初始条件连续变化,不会发生跳变,即解必须稳定)所以传统方法中做去模糊之前首先要做出一些假设,包括假设模糊是均匀的、模糊是仅由相机运动产生的、模糊是局部线性的等等,但是这些假设在很大程度上影响潜像的质量,因为真实的模糊是非均匀的,真实的模糊是非线性的,真实模糊也不一定仅由相机运动产生。
除了传统的方法,基于学习的方法也被提出用于去模糊。早期的方法利用外部数据学习的参数替换传统框架中的一些模块或步骤。最近的研究开始使用端到端的可训练网络来去除图像和视频中的模糊,在这其中,Seungjun Nah使用多尺度卷积神经网络取得了最先进的结果。( 基于学习方法实际上是以Seungjun Nah那篇论文的出现为分水岭,大体分为了基于深度学习的核估计方法(以learning to learn deblur和孙剑大佬的首次把CNN引入到Deblur中的那篇为代表),再一个就是以Seungjun Nah这篇为代表的基于学习的kernel free方法。 )
Seungjun Nah使用的卷积神经网络框架仍然采用”coarse-to-fine”方案(该方案从模糊图像的一个非常粗糙的尺度开始,逐渐以更高的分辨率恢复潜在图像,直到达到全分辨率为止)并且该框架遵循了传统方法中的多尺度机制。
本文的标题《Scale-recurrent Network for Deep Image Deblurring》中的Scale实际上指的就是多尺度的网络结构,从这里其实大概可以看出这篇论文也是沿用了coarse-to-fine的方案,而recurrent应该是指这篇论文中用了RNN(循环神经网络),而之前图像去模糊领域基于学习的方法通常使用的是CNN。
在本论文中,作者探索了一种更有效的多尺度图像去模糊网络——SRN。SRN将从输入图像中取不同尺度下采样的模糊图像序列作为输入并产生一系列相应的清晰图像,全分辨率下最清晰的图像为最终的输出图像。SRN引入了两个创新: Scale-recurrent Structure和Encoder-decoder ResBlock Network。
在完善的多尺度方法中,每个尺度的求解器(solver)和相应参数通常是相同的。
因为在每个尺度上变化的参数可能引入不稳定性或导致无限解空间等其他问题。
同时每张输入图像可能具有不同的分辨率和移动尺度(我理解为移动尺度造成的不同程度的模糊),若在每个尺度中都进行参数调整,可能会造成过拟合(过度适应某种分辨率和移动尺度,造成泛化能力不好)。
作者在如上问题的基础上提出了Scale-recurrent Structure,主要的两点idea为:共享权重和RNN循环模块。
下面,我们来详细看一下这一结构是怎样工作的:
原文中是这样写的:作者采用了在”coarse-to-fine”方案中跨多个尺度的循环结构。在每个尺度下生成一个清晰的潜像,作为去模糊任务的子问题,该子问题将一张模糊图像和初始去模糊的结果(来自早先尺度的下采样)作为输入,并推测在这一尺度下, 这张清晰的图像为 :
I
i
,
h
i
=
N
e
t
S
R
(
B
i
,
I
i
+
1
↑
,
h
i
+
1
↑
;
θ
S
R
)
\mathbf{I}^i, \mathbf{h}^i=\mathbf{N e t}_{S R}\left(\mathbf{B}^i, \mathbf{I}^{i+1 \uparrow}, \mathbf{h}^{i+1 \uparrow} ; \theta_{S R}\right)
I i , h i = Net SR ( B i , I i + 1 ↑ , h i + 1 ↑ ; θ SR ) 这个公式非常重要,并且这两张图要一起看
首先,本文的信息流(暂且这么说)是由大到小的(简直反人类了属于是),这也是为什么原文说i=1时是the finest scale,因为都输出了,能不是最好的吗?也就是说信息流是:
B3—>SRN—>I3
I3经过上采样+ B2—>SRN—>I2
I2经过上采样+ B1—>SRN—>I1
我们再对上面红色的原文进行翻译:作者采用了在”coarse-to-fine”方案中跨多个尺度的循环结构。在i尺度下生成尺度i的清晰潜像,当i=1时,生成的清晰潜像就是最终的结果。当i≠1时,生成的潜像会作为下一尺度的输入(当然还要经过一定的处理),和下一尺度的模糊图像一起输入到SRN网络中,重复上述的过程,直达i=1为止。
循环网络:SRN里增加了循环网络,作者在论文中说循环网络可从RNN,(长短期记忆)LSTM,GRU,ConvLSTM中选择,作者最终选择了ConvLSTM,因为效果最好。
上采样方法:上采样算子可以选择反卷积层、亚像素卷积层和图像大小调整。作者采用的是双线性插值法,因为它的充分性和简单性。
共享参数:这一点从图里是没办法看出来的,Seungjun Nah方法里三个尺度的参数都是分别独立的,而这一篇因为有RNN循环网络的存在,可以将三个尺度的参数共享,也就是三个尺度共用一套参数。
最近的工作中,编码器-解码器结构在计算机视觉任务中获得了成功。
Encoder-decoder指的是像U-net那样的对称的CNN结构,该结构在编码器中将输入数据逐步转换为具有较小空间尺寸的和更多通道的特征图,然后在解码器中再将他们转换为输入的形状。
直接将编码器-解码器结构应用到图像去模糊任务中,并不能产生最优的结果。其原因是,在图像去模糊任务中,需要更大的感受野来处理大尺度的运动造成的模糊。如果直接使用编码器-解码器结构就需要增加堆叠的层次,但是堆叠的层次过多会导致中间层的特征通道数快速增加,也会导致参数的大量增加和网络收敛慢的问题。此外,中间层的feature map的空间尺寸太小也无法保留空间信息进行重建。
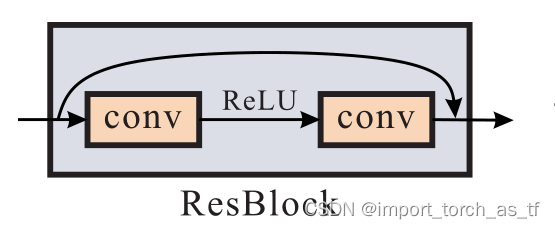
所以作者采用了一种Encoder-decoder ResBlock 网络,它能够放大卷积神经网络结构的优点,在训练中更易收敛;它还产生更大的感受野,这对于大移动尺度造成的模糊来说是至关重要的。 该网络极大的提高了训练效率,使用更少的参数,测试时间更快,并且无论是在数量上,还是在质量上都比现有方法要好。
ResBlock我认为指的是像ResNet一样采用了跳跃连接。跳跃连接可以组合不同级别(我理解为低层次的特征和高层次的特征)的信息,还有益于梯度传播并加速收敛。
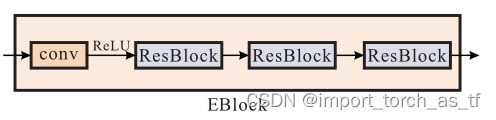
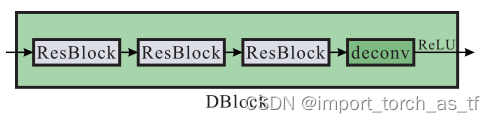
多尺度信息流程图: 共有三个尺度B1、B2和B3,(i+1)尺度是(i尺度)的一半,并且这三个尺度共享参数 SRN网络架构图: SRN网络的整体框架为:一个InBlock,两个编码器模块,然后是一个ConvLSTM,两个解码器模块和一个OutBlock。InBlock产生32通道的特征映射,OutBlock将上一层的特征映射作为输入并生成输出图像。每个编码器和解码器模块内的所有卷积层的卷积核均相同。对于编码器,内核数分别为64和128;对于解码器,内核数分别为128和64。 残差结构示意图: 残差模块包含两个卷积层和一个跳跃连接,卷积层具有相同数量的卷积核。 编码器结构示意图: 编码器模块包含一个卷积层,然后是三个残差模块,其中卷积层的stride=2,将上一层输入的通道数翻倍,并将特征图下采样为原来的一半 解码器结构示意图: 解码器模块与编码器模块在结构上是对称的,它包含三个残差模块,然后是一个反卷积层,反卷积层用于将特征图的空间大小加倍,并将通道数减半。
论文中所用损失函数为:
L
=
∑
i
=
1
n
κ
i
N
i
∥
I
i
−
I
∗
i
∥
2
2
\mathcal{L}=\sum_{i=1}^n \frac{\kappa_i}{N_i}\left\|I^i-I_*^i\right\|_2^2
L = i = 1 ∑ n N i κ i ∥
∥ I i − I ∗ i ∥
∥ 2 2
其中Ii为网络的输出;Ii*为真实的图像(ground truth,目标检测领域的老名词了);ki为每个尺度下的权重,默认为1;Ni为图像中像素的个数,起到归一化的作用
这里用的是L2 损失的开平方,如同Adam是较为理想的优化器,L2 损失也是较为理想的损失函数,因为可以更容易跑出高一点的PSNR值,但是L2 loss也存在它的缺点,容易受到异常值(outliers)的影响,所以在使用的时候也要思考这个问题。
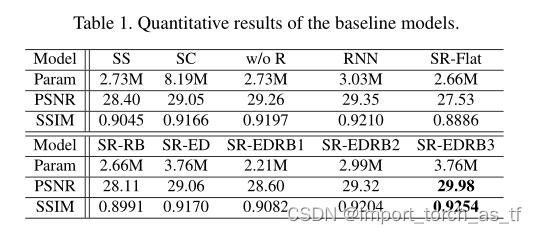
ss:单尺度模型,在原始分辨率下只取一幅单尺度图像作为输入,并将循环模块替换为一个卷积层,以保证相同数量的卷积层。
基准模型sc:该模型指的是在Seungjun Nah的那篇去模糊论文 里的尺度级联结构,它使用了独立网络的3个stage(看过我那篇博客后,这里的3个stage是很好理解的)。单个stage与ss模型相同,因此该模型的可训练参数是作者所提出方法(原文)的3倍(这里是我不理解的地方,为什么是作者所提出方法的3倍呢?不应该是ss模型的3倍吗?作者提出的方法不也是3个阶段的多尺度网络吗?) 然后,看给出的数据表,可以看出这里应该说的就是sc模型的参数是ss模型的3倍(2.73*3=8.19) 。
w/o R模型:在sc模型上加了共享权重,因此可以看到该模型的参数和ss模型的参数相同。
RNN模型:采用普通RNN,而不是ConvLSTM。
SR-EDRBx模型:是指作者提出的SRN网络,其中x表示在编码器-解码器中,ResBlock模块的数量为x个。注释:
多尺度策略是有效的:对比上图的数据可知,SS模型的性能最差(这里不包括SR-Flat模型,因为结构不同)。并且作者给了不同尺度数量的效果对比图。如下所示,尽管多尺度是有效的,但是3尺度相比于2尺度效果已经不那么明显了。
共享参数是有效的。SC模型的性能比w/o R、RNN和SR-EDRB3模型的性能要差。作者给出了可能的原因:更多的参数导致更大的模型,模型需要更长的训练时间和更大的训练数据集。在作者使用固定数据集和训练周期的约束下,模型SC可能还没有得到最佳的训练。
RNN是有效的,其中使用ConvLSTM效果最好。对比w/o R、RNN和SR-EDRB3模型可以看出,使用RNN比不使用RNN有更好的效果,而使用了ConvLSTM的SR-EDRB3模型性能最优。
SR表示scale-recurrent框架,SR-Flat表示用平坦的卷积代替编码器-解码器结构。
SR-RB表示用ResBlock替换所有的EBlocks和DBlocks;SR-ED表示采用原来的编码器-解码器结构,所有的ResBlock替换为两个卷积层。
SR-EDRBx模型:是指作者提出的SRN网络,其中x表示在编码器-解码器中,ResBlock模块的数量为x个。
注释:
SR-Flat模型效果最差,无论实在PSNR还是SSIM方面。
对比SR-EDRB1,2,3模型,可以看到选择残差模块是有效的。但是当残差模块的数量超过3个后,提升性能有限,在模型中选择3个残差模块可以在效率和性能之间取得很好的平衡。
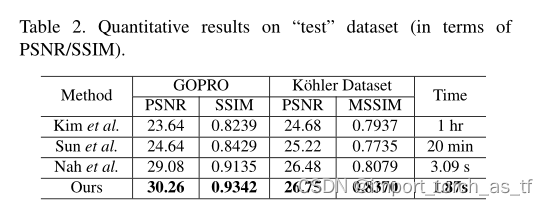
作者提出的模型处理的是相机抖动和物体运动造成的模糊,这种模糊一般是非均匀模糊,因此,作者所比较的对象都是处理这类模糊的模型,并且在两个数据集上进行了比较。从下表中可以观察到,作者提出的模型无论实在PSNR还是SSIM亦或者是时间上都取得了最好的性能。
参考https://zhuanlan.zhihu.com/p/283532126?utm_source=qq