一.论文概述
- 一般因动态场景造成的非均匀模糊是图像去模糊中一个具有挑战性的问题,这类模糊由相机抖动、场景深度以及多个对象运动造成。
- 消除这类复杂运动模糊,传统的基于简单假设的方法不在适用
- 在本文中,作者提出了一种多尺度卷积神经网络,以端到端的方式恢复由多种原因造成的模糊图像,作者还提出了多尺度损失函数来模拟传统的由"粗糙到精细"的方法。
- 此外,作者还提出了一个新的大规模数据集(仅由模糊和清晰图像对组成),通过该数据集对新提出的模型进行训练,通过实验表明,作者的方法不仅在质量上而且在数量上都使得动态场景去模糊取得最新的性能。
二.论文提出的背景
- 在估计清晰图像前,得到模糊核是很有必要的。但是核估计通常涉及如下几点问题:
1.假设简单的核卷积并不能解决复杂的模糊问题。
2.核估计过程对噪声和饱和度较敏感,除非是精心设计的模糊模型。
3.估计的模糊核不正确会导致清晰图像存在伪影。
4.为动态场景中的每个像素寻找空间变化的核需要大量的计算和内存。
基于以上核估计出现的问题,作者在新数据集的生成和去模糊的过程中采用了无核(“kernel-free”,后面就简称无核)的方法。在对清晰图像进行估计时,不假设模糊源(我认为就是模糊核),仅在模糊和清晰的图像对上训练模型。因此,作者提出的方法在去模糊时不会产生与核相关的问题。
三.论文中提出的网络模型
大多数采用由"粗糙到精细"方法的网络使用单个输入和输出。在作者提出的模型中,由更粗糙的尺度特征辅助更精细的尺度图像去模糊,而为了在保留精细级别信息的同时更充分地利用粗糙和中级特征信息,作者的网络的输入和输出都采用了高斯金字塔形式。
3.1 网络的Building Block
- 除了多尺度框架,作者将稍微修改的残差结构作为模型的Building block。这里采用残差结构除了老生常谈的使用残差结构可以实现更深层次的架构,解决网络退化问题外,还有一个重要的不常见的原因,作者给出的解释是:由于模糊和清晰的图像对在像素值上是相似的,因此让参数仅学习差异是有效的。
如下图所示,为作者使用的修改后的残差结构与原始残差结构对比:
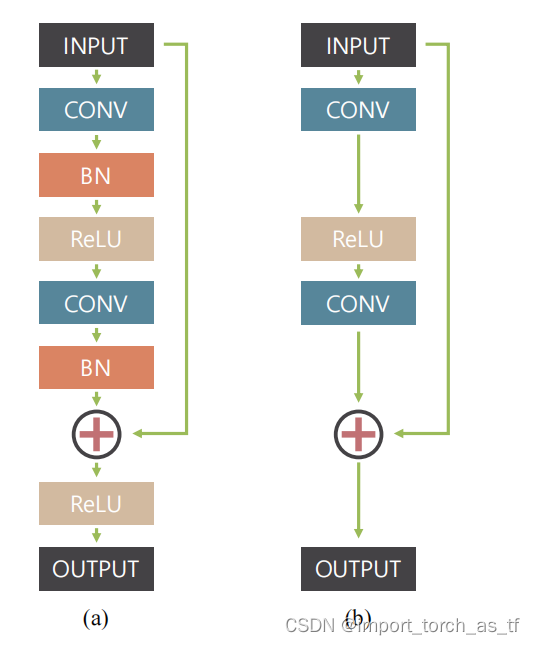
注释:
1.(a)为原始残差结构,(b)为修改后的残差结构,本文中的ResBlock。
2.修改的残差结构中,删除了BN层,因为作者使用的批处理为2的小批量训练。
3.删除了输出之前的ReLU激活函数,增加了训练时的收敛速度。
3.2 网络的整体框架
如下图所示,为网络的整体框架:
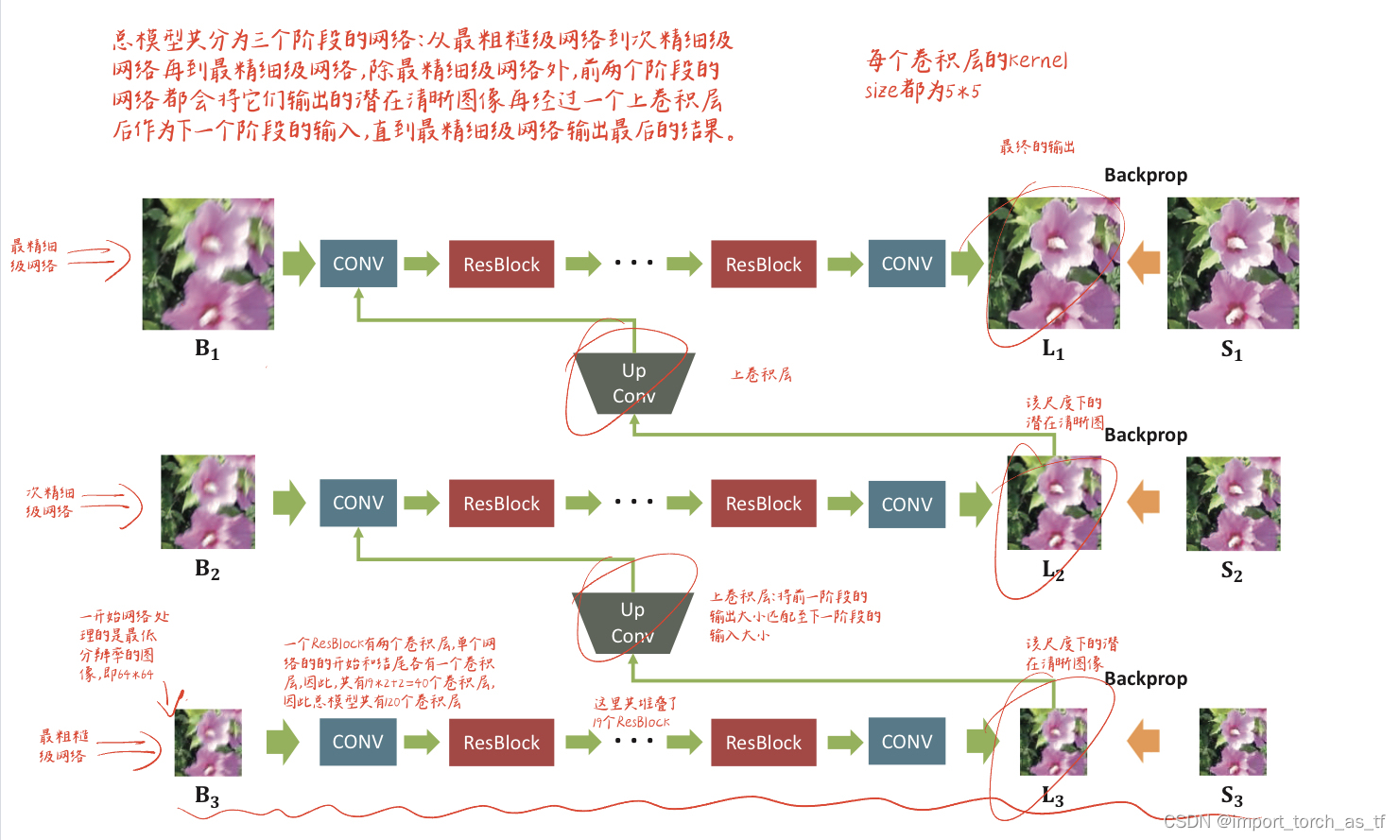
注释:
- 原文中有一词"the coarsest level network",翻译过来就是最粗糙级网络。我理解为作者将总模型划分为了三个单个模型,分别处理不同分辨率的图像,处理最粗糙图像的模型就是这里所谓的最粗糙级网络。
- 在原文中也说了共划分三个分辨率分别是64 * 64,128 * 128以及256 * 256
- 从下往上看,网络最开始输入的是最粗糙的图像,这里的单个模型也就是最粗糙级网络。第一个卷积层将分辨率为64*64的输入图像转换为64个特征图(即卷积核个数为64),然后堆叠19个ResBlock,最后通过卷积层将特征图转换为输入的维数,并产生最粗糙的潜在清晰图像。
- 产生的最粗糙的潜在清晰图像的信息会被传递到更精细级的网络作为输入,当然该信息要经过上卷积层的处理以匹配下一个更精细级的网络的输入大小。
- 为什么要采用上卷积层处理,(改变大小的方法还有上采样法和图像resize等)作者也给了一定的解释:由于清晰和模糊的图像块共享低频信息,学习上卷积层的合适特征有助于消除冗余。而通过实验也确实证明了使用上卷积层的性能确实比上采样更好。
- 单个模型总共有40个卷积层,所以总模型具有120个卷积层(我在上图中已经给了推导),各单个模型的结构基本相同,除第一个模型(最粗糙级网络)外,其他模型的第一个卷积层都采用串联的方式将前一阶段获得的清晰特征作为输入。
3.3 损失函数
在优化网络参数的过程中,作者将两个损失的组合在一起进行训练,分别是多尺度内容损失和对抗性损失。
3.3.1 多尺度内容损失
多尺度内容损失定义如下:

3.3.2 对抗性损失
对抗性损失定义如下:

注释:
- D表示鉴别器,G表示生成器,也就是作者提出的多尺度去模糊网络。其中,生成器的结构如下图所示:
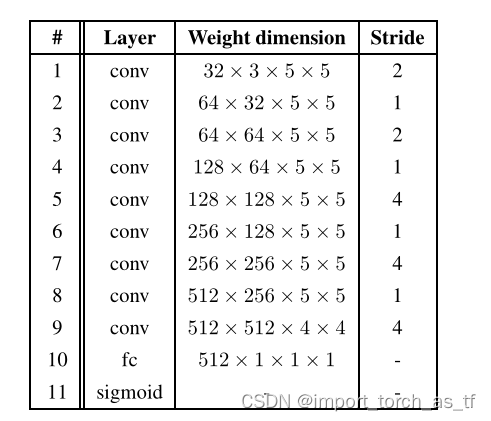
鉴别器的结构示意图,每一个卷积层的激活函数都是LeakyReLU激活函数
- 当训练时,生成器模块尝试去最小化对抗性损失,而鉴别器模块尝试去最大化对抗性损失。
最后,通过组合多尺度内容损失和对抗性损失,联合训练生成网络和鉴别网络。因此,最终的损失定义如下:
L
total
=
L
cont
+
λ
×
L
a
d
v
\mathcal{L}_{\text {total }}=\mathcal{L}_{\text {cont }}+\lambda \times \mathcal{L}_{a d v}
Ltotal =Lcont +λ×Ladv
其中权重常数 λ = 1 × 10−4。
四.实验部分
作者在不同数据集上进行了实验,以证明提出模型的性能
4.1 GOPRO 数据集
- 测试数据由1111个模糊和清晰图像对组成,大约占据整个数据集的1/3。
- 作者将自己提出的模型与当时最新的技术进行了定量和定性的比较。
- 正如在本文第二部分所说的一样,由于作者提出的是无核的方法,因此,作者的结果没有那些核估计相关的问题,而其他方法可能会由于运动边缘或非线性形状的模糊区域导致去模糊效果不好,等等。
- 下表对比显示了作者提出的模型和当时最新方法的比较:
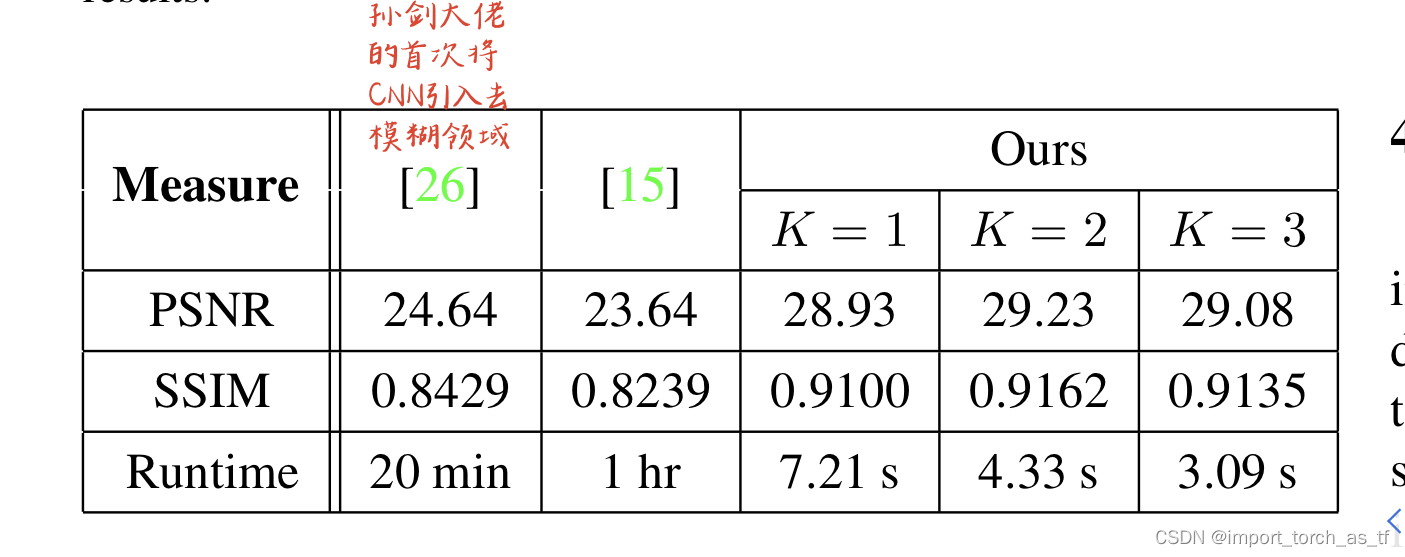
其中k表示尺度等级
4.2 Kohler 数据集
- Kohler 数据集由4个清晰潜像和12个不同的模糊图像组成。
- 下表对比显示了作者提出的模型和当时最新方法的比较:
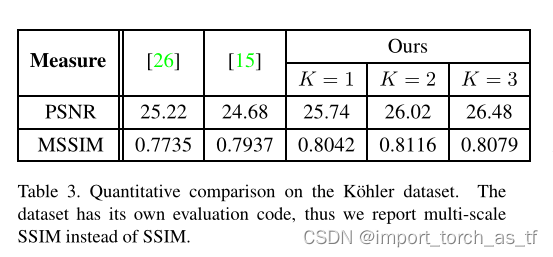
当K = 3时,作者的模型在PSNR方面的结果最好,而当K = 2时,模型的MSSIM结果最好。
4.3 Lai等人的数据集
- 在该数据集下,作者直接给出了模型的定性比较结果,如下图所示:

通过上下图的对比,可以看出作者提出的模型去模糊效果更加好。
五.总结
- 作者通过无核的方法,来避免那些核估计相关的问题。
- 所提出的模型遵循从粗糙到精细的方法,并在多尺度空间中训练。
- 提出了一个新的数据集:GOPRO 数据集,实现了有效的监督学习和严格的评估。