Hello大家好,今天带大家来看Nips2020的最新文章《GAN Memory with No Forgetting》。关于Nips2020所有关于终生学习的文章可见传送门
总览
本文是杜克大学(Duke University)ECE的一篇关于终身学习(Lifelong learning or continual learning)的问题的文章,关于这个问题我会再开一篇文章介绍。本文提出了一种没有遗忘的GAN模型并对其进行了压缩,文中对于模型各个参数进行了全面的分析,值得一看。
论文、附录和代码都是开源的,目前在我提交issue后已经上传了模型压缩的算法,但是没有提供最终的模型。
启发
本文主要是在GAN的框架下研究终身学习的问题,众所周知GAN是由一个
G
G
G(generator)和
D
D
D(discriminator)组成。本文主要是借鉴了风格迁移(Style-transfer)的技巧,并对提出的模型做了全面的分析。
- 隐变量的FiLM:
FiLM(Feature-wise Linear Modulation)是风格迁移中基础且常用的一种模型。它对神经网络的隐变量做简单的线性变化,在许多领域展现出了强大的迁移能力。
给定网络某一层输出的一个
d
d
d维的特征向量
h
∈
R
d
\boldsymbol{h} \in \mathbb{R}^{d}
h∈Rd做如下变换:
h
^
=
γ
⊙
h
+
β
,
\hat{\boldsymbol{h}}=\boldsymbol{\gamma} \odot \boldsymbol{h}+\boldsymbol{\beta},
h^=γ⊙h+β,
那么其中的
h
^
\hat{\boldsymbol{h}}
h^就是下一层网络的输入,其中
⊙
\odot
⊙表示元素两两之间点乘,缩放
γ
∈
R
d
\boldsymbol{\gamma}\in \mathbb{R}^{d}
γ∈Rd和位移
β
∈
R
d
\boldsymbol{\beta} \in \mathbb{R}^{d}
β∈Rd可以受到其他信息的约束。 - 卷积层的AdaFM:
AdaFM(adaptive filter modulation)是通过对于卷积核的变换来达到风格迁移的效果。给定一个卷积核
W
∈
R
C
out
×
C
in
×
K
1
×
K
2
\mathbf{W} \in \mathbb{R}^{{C_{\text {out}}} \times C_{\text {in}} \times K_{1} \times K_{2}}
W∈RCout×Cin×K1×K2,其中
C
in
C_{\text {in}}
Cin和
C
out
C_{\text {out}}
Cout分别代表输入和输出的channel数量,那么AdaFM的变换就是
W
^
=
Γ
⊙
W
+
B
\hat{\mathbf{W}}=\mathbf{\Gamma} \odot \mathbf{W}+\mathbf{B}
W^=Γ⊙W+B
那么其中的
h
^
\hat{\boldsymbol{h}}
h^就是下一层网络的输入,其中
⊙
\odot
⊙表示元素两两之间点乘,缩放
Γ
∈
R
C
out
×
C
in
\mathbf{\Gamma}\in \mathbb{R}^{C_{\text {out}}\times C_{\text {in}} }
Γ∈RCout×Cin和位移
β
∈
R
C
out
×
C
in
\boldsymbol{\beta} \in \mathbb{R}^{C_{\text {out}}\times C_{\text {in}}}
β∈RCout×Cin。
提出的方法
假设GAN会遇到一系列的问题
{
D
1
,
D
2
,
⋯
}
\left\{\mathcal{D}_{1}, \mathcal{D}_{2}, \cdots\right\}
{D1,D2,⋯},当,他们采用了分别对FC层和卷积层采用了modified FiLM (mFiLM)和modified AdaFM (mAdaFM)
- 全链接层(FCs)
给定一个全链接层
h
source
=
W
z
+
b
\boldsymbol{h}^{\text {source }}=\mathbf{W} \boldsymbol{z}+\boldsymbol{b}
hsource =Wz+b,其中权重为
W
∈
R
d
o
u
t
×
d
i
n
\mathbf{W}\in \mathbb{R}^{d_{out}\times d_{in}}
W∈Rdout×din,偏差
b
∈
R
d
o
u
t
\boldsymbol{b}\in \mathbb{R}^{d_{out}}
b∈Rdout和输入
z
∈
R
d
i
n
\boldsymbol{z}\in\mathbb{R}^{d_{in}}
z∈Rdin
W
^
=
γ
⊙
W
−
μ
σ
+
β
,
b
^
=
b
+
b
F
C
\hat{\mathbf{W}}=\gamma \odot \frac{\mathbf{W}-\boldsymbol{\mu}}{\boldsymbol{\sigma}}+\boldsymbol{\beta}, \quad \hat{\boldsymbol{b}}=\boldsymbol{b}+\boldsymbol{b}_{\mathrm{FC}}
W^=γ⊙σW−μ+β,b^=b+bFC
其中
μ
\boldsymbol{\mu}
μ和
σ
\boldsymbol{\sigma}
σ中的
μ
i
\boldsymbol{\mu}_i
μi和
σ
i
\boldsymbol{\sigma}_i
σi表示
W
i
,
:
\mathbf{W}_{i,:}
Wi,:的均值和方差。
- 卷积层(Conv layers)
给定一个卷积层
H
source
=
W
∗
H
′
+
b
\mathbf{H}^{\text {source }}=\mathbf{W} * \mathbf{H}^{\prime}+\boldsymbol{b}
Hsource =W∗H′+b,对于卷积核做如下变换:
W
^
=
Γ
⊙
W
−
M
S
+
B
,
b
^
=
b
+
b
C
o
n
v
\hat{\mathbf{W}}=\mathbf{\Gamma} \odot \frac{\mathbf{W}-\mathbf{M}}{\mathbf{S}}+\mathbf{B}, \quad \hat{\boldsymbol{b}}=\boldsymbol{b}+\boldsymbol{b}_{\mathrm{Conv}}
W^=Γ⊙SW−M+B,b^=b+bConv
这样使得对于每个问题来说下图的红色部分都是可学习的参数,而绿色部分是被冻结的参数。

实验效果

首先可以看出与Fine-tuning比较,文章提出的方法在问题迁移训练时收敛更快且收敛后的效果更好。
风格参数主要可以分为三类:缩放变量
{
γ
,
Γ
}
\{\boldsymbol{\gamma} ,\boldsymbol{\Gamma}\}
{γ,Γ},位移变量
{
β
,
B
}
\{\boldsymbol{\beta} ,\boldsymbol{\Beta}\}
{β,B}以及偏差
{
b
F
C
,
b
C
o
n
v
}
\left\{\boldsymbol{b}_{\mathrm{FC}}, \boldsymbol{b}_{\mathrm{Conv}}\right\}
{bFC,bConv},从下图中可以看出
{
γ
,
Γ
}
\{\boldsymbol{\gamma} ,\boldsymbol{\Gamma}\}
{γ,Γ}主要影响结构信息,
{
β
,
B
}
\{\boldsymbol{\beta} ,\boldsymbol{\Beta}\}
{β,B}主要学习了低频彩色信息。

从下图可以看出
{
b
F
C
,
b
C
o
n
v
}
\left\{\boldsymbol{b}_{\mathrm{FC}}, \boldsymbol{b}_{\mathrm{Conv}}\right\}
{bFC,bConv}主要影响细节的构造,例如肿瘤或组织细节。
此外下图展示了不同层(FC到B6)的风格变量对于模型输出的影响。从头开始看,FC改变了整体的亮度和对比度,B0-B3主要将人的面部变为花朵,之后B4-B6再对生成图片的细节进行更改。

在下图的(a)中展示的是做归一化是非常有用的,图(b)表示的是GAN的模型可以平滑地从生成一朵花变为生成一只猫,这个图是通过改变权重得到的:

图©是一个重现结果。
仿真实验的结果:

额外压缩
!在笔者的要求下作者已经上传了压缩模型的代码了!
笔者个人认为额外压缩是本文的一大亮点,不过在原文中许多对于额外压缩的介绍被放在Supplemental中。
原文作者分析了每次新任务增加的参数
Γ
\mathbf{\Gamma}
Γ 和
B
\mathbf{B}
B的奇异值(singular values)的情况。奇异值可以理解为特征值在一般矩阵上的推广。

他们发现几乎所有的网络的奇异值都下降的非常快,也就是说有非常多的奇异值其实接近于0,他们尝试将矩阵做奇异值分解了以后将那些小的奇异值设置为0后研究了模型的性能,发现在保持80%的power下。

因此他们提出了新的压缩算法:


可以看出每次需要额外保存的信息为
λ
t
\lambda_t
λt、
s
t
s_t
st和
U
t
U_t
Ut、
V
^
t
\hat{V}_t
V^t。那么随着学习的问题越来越多,
E
t
E_t
Et压缩后的维度也越来越小,因此模型需要保存的参数也越来越少。
下表给出了压缩的参数数量结果(原本的网络参数数量为52.2M)。可以看出压缩后的参数数量大大减少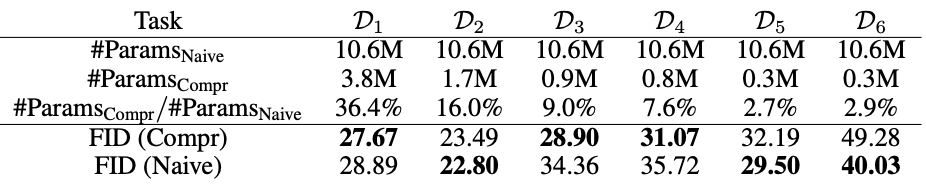
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)