开发环境
作者:嘟粥yyds
时间:2023年8月12日
集成开发工具:Google Colab
集成开发环境:Python 3.10.6
第三方库:torch、torchvision、cv2、xml、os、math、matplotlib、PIL、time、imutils、random、tqdm、face_recognition
概要
有没有想过像 Instagram 之类的软件如何将惊人的滤镜应用到你的脸上呢?该软件可检测到人脸上的关键点,并投影一个遮罩。
本文将讲述如何使用 PyTorch 来构建具有类似功能的软件。
1 DLIB数据集下载
本文使用的是 DLib 官方数据集,其中包含 6666 张不同尺寸的图像。此外,labels_ibug_300W_train.xml(随数据集一起提供)包含每张人脸上 68 个标记点的坐标。
下载完成后自动将压缩数据集删除,若需要保留则去掉!rm -r 'ibug_300W_large_face_landmark_dataset.tar.gz'代码。
%%capture
if not os.path.exists('ibug_300W_large_face_landmark_dataset'):
!wget http://dlib.net/files/data/ibug_300W_large_face_landmark_dataset.tar.gz
!tar -xvzf 'ibug_300W_large_face_landmark_dataset.tar.gz'
!rm -r 'ibug_300W_large_face_landmark_dataset.tar.gz'
如果Windows系统未自带wget工具,则先去下载再执行上面的代码。
wget下载地址:GNU Wget 1.21.3 for Windows
下载完成后,将下载后的wget.exe文件放到C:\Windows\System32,并配置系统环境变量,一般都会自动配置,若未自动配置则手动配置一下。
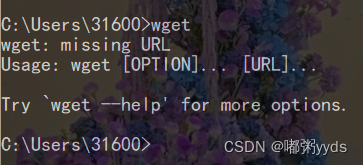
确认安装成功:
cmd命令中输入wget,出现如下对话框,表示安装成功。
2 数据集可视化
file = open('ibug_300W_large_face_landmark_dataset/helen/trainset/10405424_1.pts')
# 剔除了前三行和最后一行。在该关键点标注文件中,前三行是一些注释信息,最后一行是文件末尾的标记
points = file.readlines()[3:-1]
landmarks = []
for point in points:
# 获取点的x y坐标
x,y = point.split(' ')
landmarks.append([floor(float(x)), floor(float(y[:-1]))]) # 去除 y 坐标字符串末尾的换行符
landmarks = np.array(landmarks)
plt.figure(figsize=(6, 6))
plt.imshow(mpimg.imread('ibug_300W_large_face_landmark_dataset/helen/trainset/10405424_1.jpg'))
plt.scatter(landmarks[:,0], landmarks[:,1], s = 5, c = 'g')
plt.axis('off')
plt.show()

这是一张来自数据集的样本图像。可以发现,面部只占整个图像的很小一部分。如果我们将整个图像输入神经网络,它还将需要额外处理背景(不相关的信息),这样会使得模型难以学习。因此,我们需要裁剪图像并仅输入脸部给网络。
3 数据预处理
为了防止神经网络过拟合训练数据集,我们需要对数据集进行随机变换。我们将以下操作应用于训练和验证数据集:
- 由于面部只占整个图像的一小部分,因此裁剪图像并仅使用面部进行训练。
- 将裁剪的脸部调整为(224x224)图像的大小。
- 随机更改脸部的亮度和饱和度。
- 经过以上三个变换后,随机旋转面部。
- 将图像和标记点转换为 PyTorch 张量,并在 [-1,1] 之间对其进行归一化。
import numpy as np
from math import radians, cos, sin
import torchvision.transforms as transforms
import torchvision.transforms.functional as TF
import imutils
import torch
from PIL import Image
import random
class Transforms():
def __init__(self):
pass
def rotate(self, image, landmarks, angle):
# 随机生成一个在 -angle 到 +angle 范围内的旋转角度
angle = random.uniform(-angle, +angle)
# 基于二维平面上的旋转变换的数学特性构建旋转矩阵
transformation_matrix = torch.tensor([
[+cos(radians(angle)), -sin(radians(angle))],
[+sin(radians(angle)), +cos(radians(angle))]
])
# 对图像进行旋转:相比于 PIL 的图像旋转计算开销更小
image = imutils.rotate(np.array(image), angle)
# 将关键点坐标中心化:简化旋转变换的计算,同时确保关键点的变换和图像变换的对应关系
landmarks = landmarks - 0.5
# 将关键点坐标应用旋转矩阵
new_landmarks = np.matmul(landmarks, transformation_matrix)
# 恢复关键点坐标范围
new_landmarks = new_landmarks + 0.5
return Image.fromarray(image), new_landmarks
def resize(self, image, landmarks, img_size):
# 调整图像大小
image = TF.resize(image, img_size)
return image, landmarks
def color_jitter(self, image, landmarks):
# 定义颜色调整的参数:亮度、对比度、饱和度和色调
color_jitter = transforms.ColorJitter(brightness=0.3,
contrast=0.3,
saturation=0.3,
hue=0.1)
# 对图像进行颜色调整
image = color_jitter(image)
return image, landmarks
def crop_face(self, image, landmarks, crops):
# 获取裁剪参数
left = int(crops['left'])
top = int(crops['top'])
width = int(crops['width'])
height = int(crops['height'])
# 对图像进行裁剪
image = TF.crop(image, top, left, height, width)
# 获取裁剪后的图像形状
img_shape = np.array(image).shape
# 对关键点坐标进行裁剪后的调整
landmarks = torch.tensor(landmarks) - torch.tensor([[left, top]])
# 归一化关键点坐标
landmarks = landmarks / torch.tensor([img_shape[1], img_shape[0]])
return image, landmarks
def __call__(self, image, landmarks, crops):
# 将图像从数组转换为 PIL 图像对象
image = Image.fromarray(image)
# 裁剪图像并调整关键点
image, landmarks = self.crop_face(image, landmarks, crops)
# 调整图像大小
image, landmarks = self.resize(image, landmarks, (224, 224))
# 对图像进行颜色调整
image, landmarks = self.color_jitter(image, landmarks)
# 对图像和关键点进行旋转变换
image, landmarks = self.rotate(image, landmarks, angle=10)
# 将图像从 PIL 图像对象转换为 Torch 张量
image = TF.to_tensor(image)
# 标准化图像像素值
image = TF.normalize(image, [0.5], [0.5])
return image, landmarks
4 数据集类
现在我们已经准备好转换,让我们编写数据集类。labels_ibug_300W_train.xml 包含图像路径、标记点和人脸包围盒(用于裁剪脸部)坐标。我们会将这些值存储在列表中,以便在训练期间轻松访问它们。
本文在彩色图像上训练神经网络,训练集的BATCH_SIZE = 512,验证集的BATCH_SIZE = 64需要15G左右的显存,训练10个epoch需要2个小时左右。读者可根据自身的GPU情况自行更改这些超参数,若GPU显存过小或使用CPU训练,建议在灰色图像上训练。本文也给出灰色图像上训练神经网络的代码(已被注释)。
import cv2
import xml.etree.ElementTree as ET
from torch.utils.data import Dataset
class FaceLandmarksDataset(Dataset):
def __init__(self, transform=None):
# 解析 XML 文件
tree = ET.parse('ibug_300W_large_face_landmark_dataset/labels_ibug_300W_train.xml')
root = tree.getroot()
# 初始化变量
self.image_filenames = []
self.landmarks = []
self.crops = []
self.transform = transform
self.root_dir = 'ibug_300W_large_face_landmark_dataset'
# 遍历 XML 数据:root[2] 表示 XML 中的第三个元素,即 <images> 部分,其中包含了每张图像的标注信息
for filename in root[2]:
self.image_filenames.append(os.path.join(self.root_dir, filename.attrib['file']))
self.crops.append(filename[0].attrib)
landmark = []
for num in range(68):
x_coordinate = int(filename[0][num].attrib['x'])
y_coordinate = int(filename[0][num].attrib['y'])
landmark.append([x_coordinate, y_coordinate])
self.landmarks.append(landmark)
self.landmarks = np.array(self.landmarks).astype('float32')
assert len(self.image_filenames) == len(self.landmarks)
def __len__(self):
return len(self.image_filenames)
def __getitem__(self, index):
# 读取图像以及关键点坐标
image = cv2.imread(self.image_filenames[index]) # 以彩色模式读取图像
# image = cv2.imread(self.image_filenames[index], 0) # 以灰色模式读取图像
landmarks = self.landmarks[index]
if self.transform:
# 如果存在预处理变换,应用变换
image, landmarks = self.transform(image, landmarks, self.crops[index])
landmarks = landmarks - 0.5 # 进行中心化操作
return image, landmarks
# 创建数据集对象,并应用预处理变换
dataset = FaceLandmarksDataset(Transforms())
5 训练变换可视化
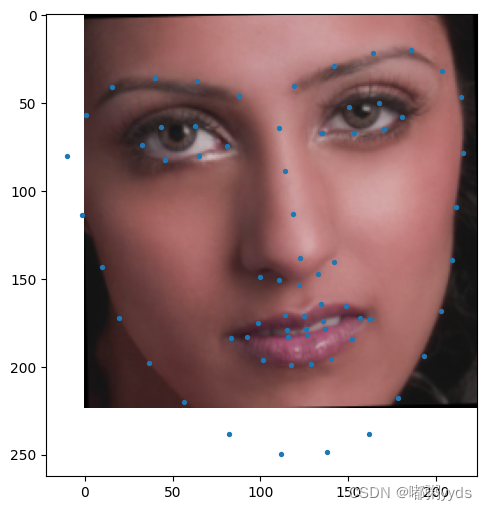
注意: landmarks = landmarks - 0.5 对标记点作零中心处理,因为神经网络更容易学习零中心数据。预处理后的数据集输出将类似于以下内容(标记点已绘制在图像上)。
image, landmarks = dataset[5]
landmarks = (landmarks + 0.5) * 224
plt.figure(figsize=(6, 6))
image_color = np.transpose(image.numpy(), (1, 2, 0)) # 将通道维度移到最后
image_color_normalized = (image_color + 1) / 2
image_rgb = image_color_normalized[..., ::-1]
plt.imshow(image_rgb)
plt.scatter(landmarks[:,0], landmarks[:,1], s=8);
划分数据集
# split the dataset into validation and test sets
len_valid_set = int(0.1*len(dataset))
len_train_set = len(dataset) - len_valid_set
print("The length of Train set is {}".format(len_train_set))
print("The length of Valid set is {}".format(len_valid_set))
train_dataset , valid_dataset, = torch.utils.data.random_split(dataset , [len_train_set, len_valid_set])
# shuffle and batch the datasets
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=512, shuffle=True, num_workers=2)
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=64, shuffle=True, num_workers=2)
6 神经网络架构
我们将使用 ResNet18 作为基本框架。我们需要修改第一层和最后一层以适合本项目的目的。在第一层中,我们将使神经网络接受彩色图像的输入通道数为 3(若选择灰色图像训练则设为1)。同样,在最后一层中,模型的输出通道数应等于
68
68
68 x
2
=
136
2 = 136
2=136,以预测人脸
68
68
68 个标记点的
(
x
,
y
)
(x, y)
(x,y) 坐标。
import torch
import torch.nn as nn
import torchvision.models as models
class Network(nn.Module):
def __init__(self,num_classes=136):
super().__init__()
self.model_name='resnet18'
self.model=models.resnet18()
self.model.conv1=nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
# self.model.conv1=nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False) # 灰色图像训练
self.model.fc=nn.Linear(self.model.fc.in_features, num_classes)
def forward(self, x):
x=self.model(x)
return x
7 训练神经网络
我们将使用预测和真实标记点之间的均方误差作为损失函数。请记住,学习率应保持较低以避免梯度爆炸。每当验证损失达到新的最小值时,将保存网络权重。训练至少 20 个 epochs 以获得最佳性能。(本文在GPU资源有限的情况下,仅训练了10个epoch)。
import torch
import torch.nn as nn
import torch.optim as optim
import time
from tqdm import tqdm
# 记录每个 epoch 的训练和验证损失
train_losses = []
valid_losses = []
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch.autograd.set_detect_anomaly(True)
network = Network().to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(network.parameters(), lr=0.0001)
loss_min = np.inf
num_epochs = 10
start_time = time.time()
for epoch in range(1, num_epochs + 1):
loss_train = 0
loss_valid = 0
running_loss = 0
network.train()
for step in tqdm(range(1, len(train_loader) + 1)):
images, landmarks = next(iter(train_loader))
images = images.to(device)
landmarks = landmarks.view(landmarks.size(0), -1).to(device)
predictions = network(images)
optimizer.zero_grad()
loss_train_step = criterion(predictions, landmarks)
loss_train_step.backward()
optimizer.step()
loss_train += loss_train_step.item()
running_loss = loss_train / step
network.eval()
with torch.no_grad():
for step in range(1, len(valid_loader) + 1):
images, landmarks = next(iter(valid_loader))
images = images.to(device)
landmarks = landmarks.view(landmarks.size(0), -1).to(device)
predictions = network(images)
loss_valid_step = criterion(predictions, landmarks)
loss_valid += loss_valid_step.item()
running_loss = loss_valid / step
loss_train /= len(train_loader)
loss_valid /= len(valid_loader)
train_losses.append(loss_train)
valid_losses.append(loss_valid)
print('\n--------------------------------------------------')
print('Epoch: {} Train Loss: {:.4f} Valid Loss: {:.4f}'.format(epoch, loss_train, loss_valid))
print('--------------------------------------------------')
if loss_valid < loss_min:
loss_min = loss_valid
torch.save(network.state_dict(), 'face_landmarks.pth')
print("\nMinimum Validation Loss of {:.4f} at epoch {}/{}".format(loss_min, epoch, num_epochs))
print('Model Saved\n')
print('Training Complete')
print("Total Elapsed Time: {} s".format(time.time() - start_time))
100%|██████████| 12/12 [23:22<00:00, 116.91s/it]
--------------------------------------------------
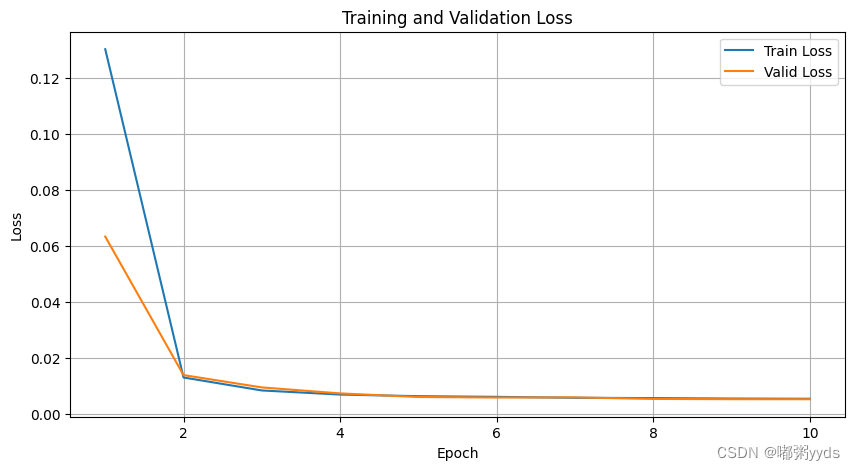
Epoch: 1 Train Loss: 0.1304 Valid Loss: 0.0634
--------------------------------------------------
Minimum Validation Loss of 0.0634 at epoch 1/10
Model Saved
100%|██████████| 12/12 [10:42<00:00, 53.57s/it]
--------------------------------------------------
Epoch: 2 Train Loss: 0.0130 Valid Loss: 0.0139
--------------------------------------------------
Minimum Validation Loss of 0.0139 at epoch 2/10
Model Saved
100%|██████████| 12/12 [09:42<00:00, 48.53s/it]
--------------------------------------------------
Epoch: 3 Train Loss: 0.0084 Valid Loss: 0.0095
--------------------------------------------------
Minimum Validation Loss of 0.0095 at epoch 3/10
Model Saved
100%|██████████| 12/12 [09:49<00:00, 49.09s/it]
--------------------------------------------------
Epoch: 4 Train Loss: 0.0069 Valid Loss: 0.0073
--------------------------------------------------
Minimum Validation Loss of 0.0073 at epoch 4/10
Model Saved
100%|██████████| 12/12 [10:04<00:00, 50.35s/it]
--------------------------------------------------
Epoch: 5 Train Loss: 0.0063 Valid Loss: 0.0060
--------------------------------------------------
Minimum Validation Loss of 0.0060 at epoch 5/10
Model Saved
100%|██████████| 12/12 [09:27<00:00, 47.26s/it]
--------------------------------------------------
Epoch: 6 Train Loss: 0.0061 Valid Loss: 0.0058
--------------------------------------------------
Minimum Validation Loss of 0.0058 at epoch 6/10
Model Saved
100%|██████████| 12/12 [10:18<00:00, 51.53s/it]
--------------------------------------------------
Epoch: 7 Train Loss: 0.0058 Valid Loss: 0.0059
--------------------------------------------------
100%|██████████| 12/12 [09:48<00:00, 49.01s/it]
--------------------------------------------------
Epoch: 8 Train Loss: 0.0057 Valid Loss: 0.0054
--------------------------------------------------
Minimum Validation Loss of 0.0054 at epoch 8/10
Model Saved
100%|██████████| 12/12 [09:47<00:00, 48.92s/it]
--------------------------------------------------
Epoch: 9 Train Loss: 0.0055 Valid Loss: 0.0053
--------------------------------------------------
Minimum Validation Loss of 0.0053 at epoch 9/10
Model Saved
100%|██████████| 12/12 [09:51<00:00, 49.27s/it]
--------------------------------------------------
Epoch: 10 Train Loss: 0.0054 Valid Loss: 0.0052
--------------------------------------------------
Minimum Validation Loss of 0.0052 at epoch 10/10
Model Saved
Training Complete
Total Elapsed Time: 7878.068931341171 s
# 可视化损失曲线
plt.figure(figsize=(10, 5))
plt.plot(range(1, num_epochs + 1), train_losses, label='Train Loss')
plt.plot(range(1, num_epochs + 1), valid_losses, label='Valid Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.grid()
plt.show()
8 测试集上预测
OpenCV Harr 级联分类器用于检测图像中的脸部。使用 Haar 级联进行对象检测是一种基于机器学习的方法,其中使用一组输入数据来训练级联函数。OpenCV 包含许多针对面部、眼睛、行人等已经训练好的分类器。这里我们使用的是脸部分类器,你需要为其下载预训练的分类器 XML 文件并将其保存到工作目录中。该代码在不支持GPU的代码上也能正常运行,不过效果不如下面的仅能在支持GPU的环境下正常运行的代码。
import time
import cv2
import os
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import imutils
import torch
import torch.nn as nn
from torchvision import models
import torchvision.transforms.functional as TF
#######################################################################
image_path = 'Sample1.jpg'
weights_path = 'face_landmarks.pth'
frontal_face_cascade_path = 'haarcascade_frontalface_default.xml'
#######################################################################
class Network(nn.Module):
def __init__(self, num_classes=136):
super().__init__()
self.model_name = 'resnet18'
self.model = models.resnet18(pretrained=False)
self.model.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) # 1:单通道训练 3:三通道训练
self.model.fc = nn.Linear(self.model.fc.in_features, num_classes)
def forward(self, x):
x = self.model(x)
return x
#######################################################################
face_cascade = cv2.CascadeClassifier(frontal_face_cascade_path)
if face_cascade.empty():
raise Exception("Failed to load face cascade classifier")
best_network = Network()
best_network.load_state_dict(torch.load(weights_path, map_location=torch.device('cpu')))
best_network.eval()
image = cv2.imread(image_path)
color_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 三通道训练
# color_iamge = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 单通道训练
height, width, _ = image.shape
faces = face_cascade.detectMultiScale(color_image, 1.1, 4)
all_landmarks = []
for (x, y, w, h) in faces:
face_region = color_image[y:y+h, x:x+w]
face_region = TF.resize(Image.fromarray(face_region), size=(224, 224))
face_region = TF.to_tensor(face_region)
face_region = TF.normalize(face_region, [0.5], [0.5])
with torch.no_grad():
landmarks = best_network(face_region.unsqueeze(0))
landmarks = (landmarks.view(68, 2).detach().numpy() + 0.5) * np.array([[w, h]]) + np.array([[x, y]])
all_landmarks.append(landmarks)
# 绘制人脸和关键点
plt.figure(figsize=(7, 7))
plt.imshow(color_image)
for landmarks in all_landmarks:
plt.scatter(landmarks[:, 0], landmarks[:, 1], c='c', s=5)
plt.axis('off')
plt.show()

下面这个代码仅能在支持GPU的环境下正常运行,同时需要确保安装了 face_recognition 依赖库。
!pip install -i https://pypi.tuna.tsinghua.edu.cn/simple face_recognition
import cv2
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import imutils
import torch
import torch.nn as nn
from torchvision import models
import torchvision.transforms.functional as TF
import face_recognition # 导入 face_recognition 库
#######################################################################
image_path = 'sample.jpg'
weights_path = 'face_landmarks.pth'
#######################################################################
class Network(nn.Module):
def __init__(self, num_classes=136):
super().__init__()
self.model_name = 'resnet18'
self.model = models.resnet18(pretrained=False)
self.model.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) # 1:单通道训练 3:三通道训练
self.model.fc = nn.Linear(self.model.fc.in_features, num_classes)
def forward(self, x):
x = self.model(x)
return x
best_network = Network()
best_network.load_state_dict(torch.load(weights_path, map_location=torch.device('cuda')))
best_network.eval()
# 读取图像并进行预处理
image = cv2.imread(image_path)
color_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 三通道训练时
# color_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 单通道训练时
display_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 使用 face_recognition 库进行人脸检测
face_locations = face_recognition.face_locations(color_image)
# 初始化关键点列表
all_landmarks = []
# 对于每个检测到的人脸位置
for face_location in face_locations:
top, right, bottom, left = face_location
face_region = color_image[top:bottom, left:right]
# 进行预处理
face_region = Image.fromarray(face_region)
face_region = TF.resize(face_region, size=(224, 224))
face_region = TF.to_tensor(face_region)
face_region = TF.normalize(face_region, [0.5], [0.5])
with torch.no_grad():
landmarks = best_network(face_region.unsqueeze(0))
landmarks = (landmarks.view(68, 2).detach().numpy() + 0.5) * np.array([[right - left, bottom - top]]) + np.array([[left, top]])
all_landmarks.append(landmarks)
# 绘制人脸和关键点
plt.figure(figsize=(7, 7))
plt.imshow(display_image)
for landmarks in all_landmarks:
plt.scatter(landmarks[:, 0], landmarks[:, 1], c='c', s=5)
plt.axis('off')
plt.show()
