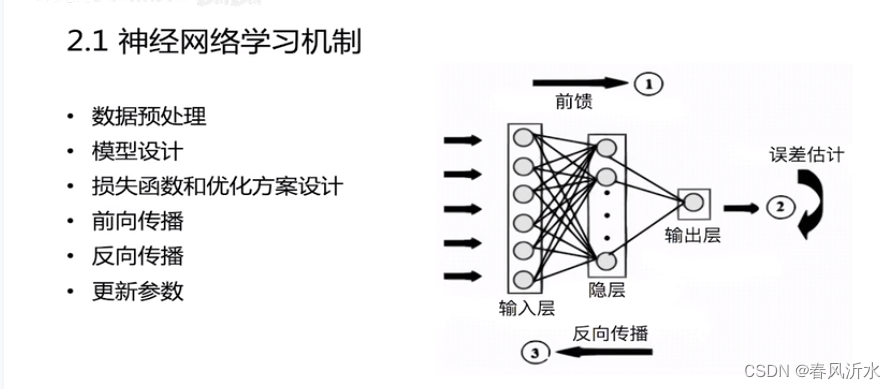
学习目标:
pytorch的各个组件和实战
学习内容:
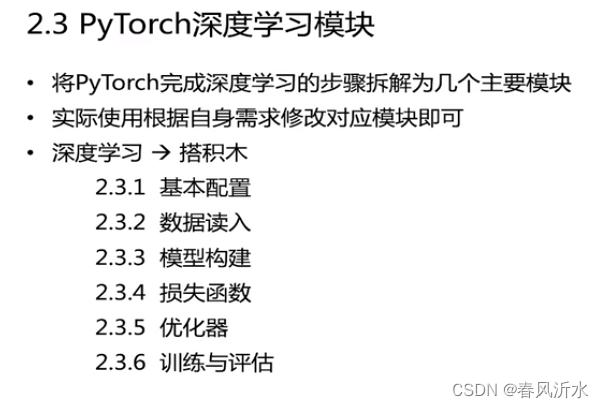
## 基本配置
首先导入必须的包。对于一个PyTorch项目,我们需要导入一些Python常用的包来帮助我们快速实现功能。常见的包有os、numpy等,此外还需要调用PyTorch自身一些模块便于灵活使用,比如torch、torch.nn、torch.utils.data.Dataset、torch.utils.data.DataLoader、torch.optimizer等等。注意这里只是建议导入的包导入的方式,可以采用不同的方案,比如涉及到表格信息的读入很可能用到pandas,对于不同的项目可能还需要导入一些更上层的包如cv2等。如果涉及可视化还会用到matplotlib、seaborn等。涉及到下游分析和指标计算也常用到sklearn。
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torch.optim as optimizer
根据前面我们对深度学习任务的梳理,有如下几个超参数可以统一设置,方便后续调试时修改:
batch size
初始学习率(初始)
训练次数(max_epochs)
GPU配置
batch_size = 16
lr = 1e-4
max_epochs = 100
GPU的设置有两种常见的方式:
#方案一:使用os.environ,这种情况如果使用GPU不需要设置
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
#方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
当然还会有一些其他模块或用户自定义模块会用到的参数,有需要也可以在一开始进行设置。


学习时间:
时间4小时
学习产出:
1、如何安装包参考博文(http://t.zoukankan.com/du-hong-p-10271604.html)
进入自己的虚拟环境
pip3 list
pip3 install pandas
2、未找到cpu参考博文(https://blog.csdn.net/qq_41400623/article/details/123167922)
import torch
print(torch.version)
print(torch.version.cuda)
print(torch.backends.cudnn.enabled)
print(torch.cuda.is_available())