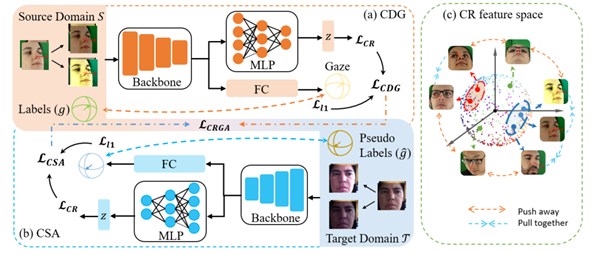
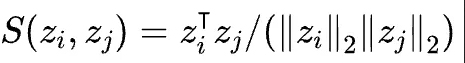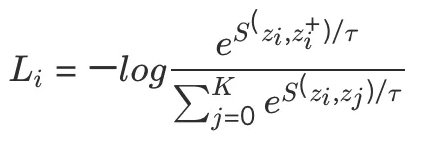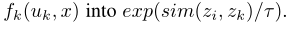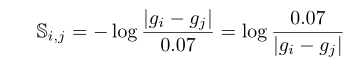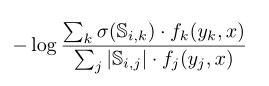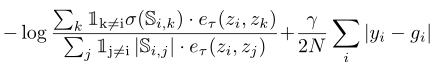原文链接 补充材料 概括:本文将分类对比学习推广到回归,采用回归任务里真值的相似性代替分类任务里的类别标签一致性划分,在无标注的目标域采用伪标签进行训练。 分类对比学习损失:s为特征的余弦相似性,损失函数L分子与正样本对特征相似程度和正相关,分母与所有样本对特征相似度和正相关。该损失函数能够使得正样本对特征拉近,负样本对特征拉远。 本文回归任务损失:S为回归任务真值的相似程度,σ是relu函数,对标分类任务负样本对不参与分子计算,loss能够push负样本对拉远(分子不变,分母变小,总体变大),正样本对拉近(3/5>1/3) 训练的时候loss包括回归对比损失以及视线估计准确性损失两部分:I在ij相等时为0,其余时候为1,避免自身参与相似度计算加快收敛
文章在训练时还进行了增强,对于每个输入样本,在数据增强操作集合中随机选择两个不同的操作对样本进行增强,因此每个批次有2N个样本。 伪代码:
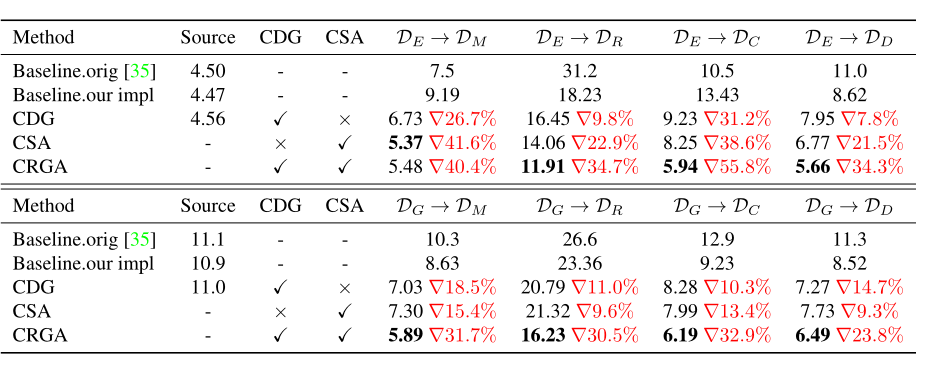
实验: