写在前面
之前更新过两期关于中文羊驼模型的效果体验:
【类ChatGPT】本地CPU部署中文羊驼大模型LLaMA和Alpaca_nlpstarter的博客-CSDN博客
【类ChatGPT】中文羊驼大模型Alpaca-13B体验_nlpstarter的博客-CSDN博客
实际这段期间,这个项目还有持续不断更新,今天正好有时间可以和大家分享一下体验效果。
项目地址:https://github.com/ymcui/Chinese-LLaMA-Alpaca
比拼模型
之前这个项目最好的模型是Alpaca-Plus-13B,使用了120G语料做了预训练,指令精调阶段用了大概400万的数据。这个项目还最新推出了33B版本的模型(但不是plus版),基本已经快达到我的电脑能承受的最大限制了。
今天就以这两个模型为例做一些PK,正好也能看看是训练数据量更多效果更好,还是模型规模更大会更好。
- Alpaca-Plus-13B:120G预训练,400万指令精调
- Alpaca-33B:20G预训练,400万指令精调
评测中,13B版本使用的是Q8量化版,33B用的是Q4量化版,虽然对33B不太公平但我的机器也只能跑这个量化级别了,再高就不出字了。运行还是用的是llama.cpp这个工具。
测试开始!
还是问一下关于温室效应的问题
Plus-13B:

33B:

小结:Plus-13B 相比我之前测试的7B和13B都有显著的提升,内容更加丰富了,回复长度也有所增长。33B的回答比较简练,内容长度上不占优,看来还是需要用更多数据训练才行,希望后续也能有plus版。
数学问题:骑7个猴
Plus-13B:

33B:

小结:33B的完胜Plus-13B,可能模型量级对于这种数值计算和推理类的有较大优势吧。Plus-13B的虽然也能答对部分内容,但对问题的理解还不算透彻。
如何制作宫保鸡丁?
Plus-13B:

33B:

小结:两个都比之前的7b/13b效果好,至少不会出现猪肉了。Plus-13b多了个青椒,但我印象中宫保鸡丁好像没有这个材料?33B的回复也差不多,口味方面少了甜味?
写一封信
Plus-13B:

33B:

小结:Plus-13B占优一些,内容详实。可能33B吃了训练数据少的亏,写的内容不是特别生动。
代码方面
Plus-13B:

33B:
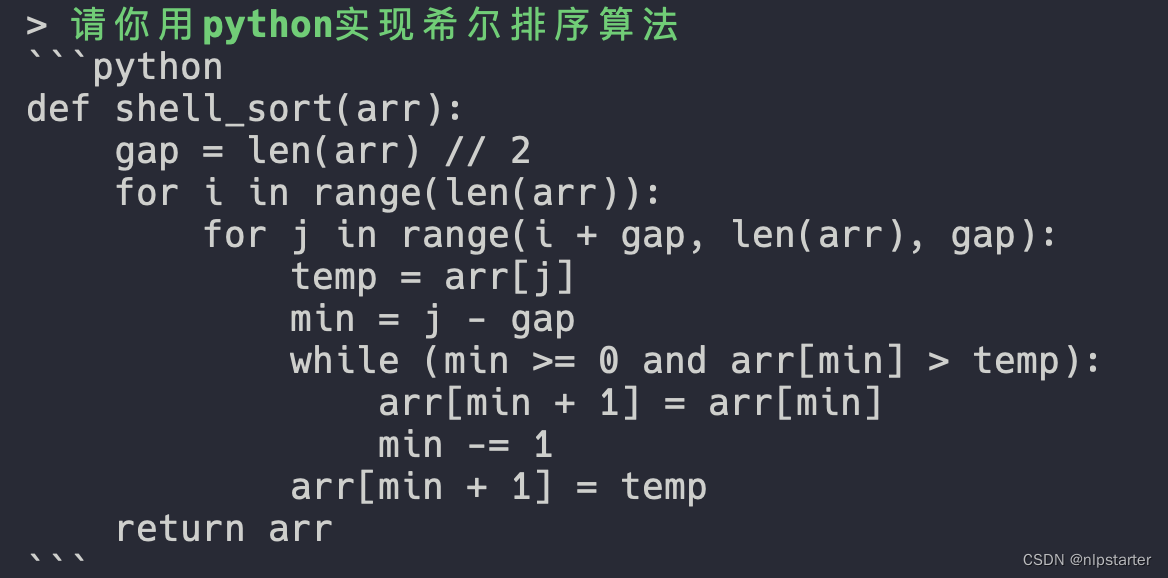
小结:33B显著胜出,以下是GPT-4作为裁判的点评结果,可以看到33B有一些小瑕疵,但整体上没有大问题。

角色扮演
Plus-13B:

33B:

小结:两个回答都比较好,可能Plus-13B的更好一点,因为回复长度会更长一些,不过事实性方面其实没有太大的差别。
总结
Plus-13B相比之前的7B/13B已经有显著性能提升了,尤其是在生成类的任务上内容更加详实。33B的优缺点比较明显,优点是代码能力和数值计算方面确实比之前高出一截,但是在文本生成类的任务上效果略低于plus-13B。不过33B是基础版,这么比可能有点不讲武德,哈哈。这样其实就比较期待后续plus-33b的效果了,生成类任务的效果应该会有一个提升。
整体而言,两者优缺点都比较明显,主要看使用场景和资源限制了。33B的4比特量化模型也得将近20G,可能一般机器也带不起来,量力而行吧。