DolphinScheduler3.0.1(数据质量)
Refer
dolphinscheduler3.0.1HIVE数据源
dolphinscheduler3.0.1数据质量
1.data-quality-jar包修改
1.配置文件修改
- 想要执行数据质量相关的任务,首先需要对配置文件进行修改
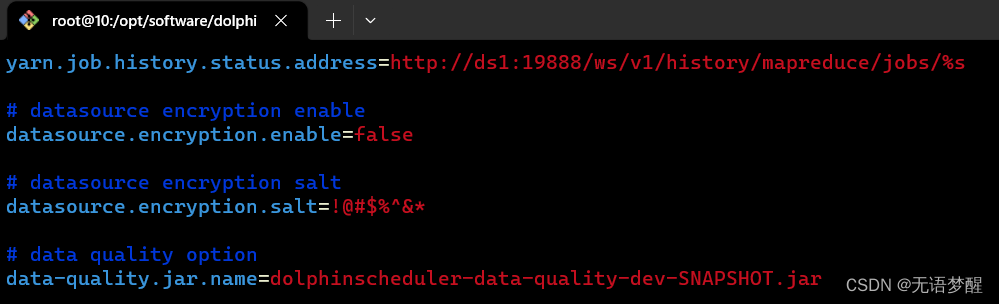
- 文件位置:/dolphinscheduler/tools/conf/common.properties
- 修改内容:将data-quality.jar.name变更为work-server下libs中的对应data-quality的jar包名称(/dolphinscheduler/worker-server/libs/dolphinscheduler-data-quality-3.0.1.jar)
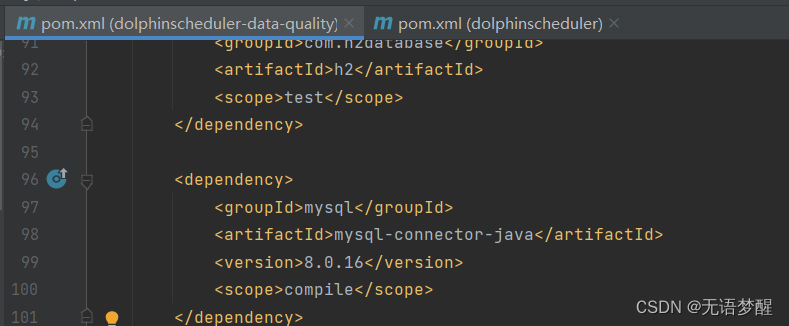
- 其次是自己打包的data-quality文件夹中一定要注意修改mysql8的连接器scope为compile,需要在对应pom的位置添加一下scope,否则会报错ClassNotFoundException
- 源码中关于spark的scope不需要修改!!!
[INFO] 2023-05-16 14:30:08.590 +0800 - -> Exception in thread "main" java.lang.ClassNotFoundException: com.mysql.cj.jdbc.Driver
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at org.apache.spark.sql.execution.datasources.jdbc.DriverRegistry$.register(DriverRegistry.scala:46)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.$anonfun$driverClass$1(JDBCOptions.scala:101)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.$anonfun$driverClass$1$adapted(JDBCOptions.scala:101)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.<init>(JDBCOptions.scala:101)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.<init>(JDBCOptions.scala:39)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:33)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:350)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:274)
at org.apache.spark.sql.DataFrameReader.$anonfun$load$3(DataFrameReader.scala:245)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:245)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:174)
at org.apache.dolphinscheduler.data.quality.flow.batch.reader.JdbcReader.read(JdbcReader.java:72)
at org.apache.dolphinscheduler.data.quality.execution.SparkBatchExecution.registerInputTempView(SparkBatchExecution.java:77)
at org.apache.dolphinscheduler.data.quality.execution.SparkBatchExecution.lambda$execute$0(SparkBatchExecution.java:48)
at java.util.ArrayList.forEach(ArrayList.java:1259)
at org.apache.dolphinscheduler.data.quality.execution.SparkBatchExecution.execute(SparkBatchExecution.java:48)
at org.apache.dolphinscheduler.data.quality.context.DataQualityContext.execute(DataQualityContext.java:62)
at org.apache.dolphinscheduler.data.quality.DataQualityApplication.main(DataQualityApplication.java:70)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:955)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1043)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1052)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
[INFO] 2023-05-16 14:30:08.854 +0800 - process has exited, execute path:/opt/software/dolphinscheduler/data/exec/process/8741536538048/8741552919232_24/16267/77676, processId:713393 ,exitStatusCode:1 ,processWaitForStatus:true ,processExitValue:1
- 不进行修改肯定报错

2.依赖不明确问题
Multiple sources found for csv (org.apache.spark.sql.execution.datasources.v2.csv.CSVDataSourceV2, org.apache.spark.sql.execution.datasources.csv.CSVFileFormat),
please specify the fully qualified class name.
at org.apache.spark.sql.errors.QueryCompilationErrors$.findMultipleDataSourceError(QueryCompilationErrors.scala:1045)
at org.apache.spark.sql.execution.datasources.DataSource$.lookupDataSource(DataSource.scala:697)
at org.apache.spark.sql.execution.datasources.DataSource$.lookupDataSourceV2(DataSource.scala:720)
at org.apache.spark.sql.DataFrameWriter.lookupV2Provider(DataFrameWriter.scala:852)
at org.apache.spark.sql.DataFrameWriter.saveInternal(DataFrameWriter.scala:256)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:239)
at org.apache.spark.sql.DataFrameWriter.csv(DataFrameWriter.scala:839)
at org.apache.dolphinscheduler.data.quality.flow.batch.writer.file.BaseFileWriter.outputImpl(BaseFileWriter.java:113)
at org.apache.dolphinscheduler.data.quality.flow.batch.writer.file.HdfsFileWriter.write(HdfsFileWriter.java:40)
at org.apache.dolphinscheduler.data.quality.execution.SparkBatchExecution.executeWriter(SparkBatchExecution.java:130)
at org.apache.dolphinscheduler.data.quality.execution.SparkBatchExecution.execute(SparkBatchExecution.java:58)
at org.apache.dolphinscheduler.data.quality.context.DataQualityContext.execute(DataQualityContext.java:62)
at org.apache.dolphinscheduler.data.quality.DataQualityApplication.main(DataQualityApplication.java:70)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:955)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1043)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1052)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
3.scope多修改问题
-
源码中关于spark的scope不需要修改!!!,修改了的话则会跟原始集群里的版本冲突,这个我整了好久才明白。。。避坑避坑!
[INFO] 2023-05-16 12:08:24.026 +0800 - -> Exception in thread "main" org.apache.spark.sql.AnalysisException:
Multiple sources found for csv (org.apache.spark.sql.execution.datasources.v2.csv.CSVDataSourceV2, org.apache.spark.sql.execution.datasources.csv.CSVFileFormat),
please specify the fully qualified class name.
at org.apache.spark.sql.errors.QueryCompilationErrors$.findMultipleDataSourceError(QueryCompilationErrors.scala:1045)
at org.apache.spark.sql.execution.datasources.DataSource$.lookupDataSource(DataSource.scala:697)
at org.apache.spark.sql.execution.datasources.DataSource$.lookupDataSourceV2(DataSource.scala:720)
at org.apache.spark.sql.DataFrameWriter.lookupV2Provider(DataFrameWriter.scala:852)
at org.apache.spark.sql.DataFrameWriter.saveInternal(DataFrameWriter.scala:256)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:239)
at org.apache.spark.sql.DataFrameWriter.csv(DataFrameWriter.scala:839)
at org.apache.dolphinscheduler.data.quality.flow.batch.writer.file.BaseFileWriter.outputImpl(BaseFileWriter.java:113)
at org.apache.dolphinscheduler.data.quality.flow.batch.writer.file.HdfsFileWriter.write(HdfsFileWriter.java:40)
at org.apache.dolphinscheduler.data.quality.execution.SparkBatchExecution.executeWriter(SparkBatchExecution.java:130)
at org.apache.dolphinscheduler.data.quality.execution.SparkBatchExecution.execute(SparkBatchExecution.java:58)
at org.apache.dolphinscheduler.data.quality.context.DataQualityContext.execute(DataQualityContext.java:62)
at org.apache.dolphinscheduler.data.quality.DataQualityApplication.main(DataQualityApplication.java:70)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:955)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1043)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1052)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
2.实现方式
1.Spark提交
- DolphinScheduler这边是按照安装的spark,按照自定义资源配置,使用data-quality的jar包提交匹配的内容语句来实现质量实现规则和数据拉取等流程

2.结构解析
{
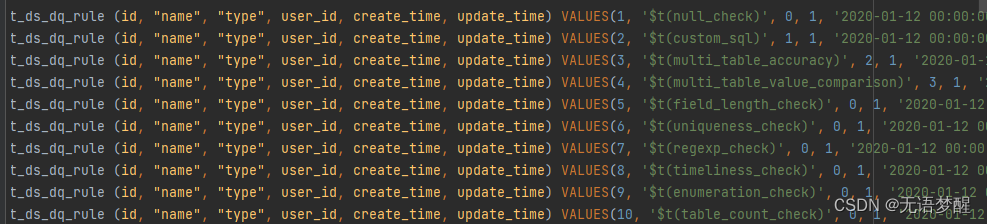
// 源工程:dolphinscheduler_dml.sql
// 数据表:t_ds_dq_rule
// 该表中配置了基础规则的基础功能,下图1
"name":"$t(uniqueness_check)",
"env":{
"type":"batch",
"config":null
},
"readers":[
{
"type":"HIVE",
"config":{
"database":"${hive_database_name}",
"password":"${password}",
"driver":"org.apache.hive.jdbc.HiveDriver",
"user":"root",
"output_table":"${hive_database_name}_${hive_table_name}",
"table":"${hive_table_name}",
"url":"jdbc:hive2://${ip}:${port}/${hive_database_name}"
}
},
{
"type":"JDBC",
"config":{
"database":"${mysql_database_name}",
"password":"${password}",
"driver":"com.mysql.cj.jdbc.Driver",
"user":"root",
"output_table":"t_ds_dq_task_statistics_value",
"table":"t_ds_dq_task_statistics_value",
"url":"jdbc:mysql://${ip}:${port}/${mysql_database_name}?useUnicode=true&characterEncoding=UTF-8&useSSL=false&allowPublicKeyRetrieval=true&allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false"
}
}
],
"transformers":[
{
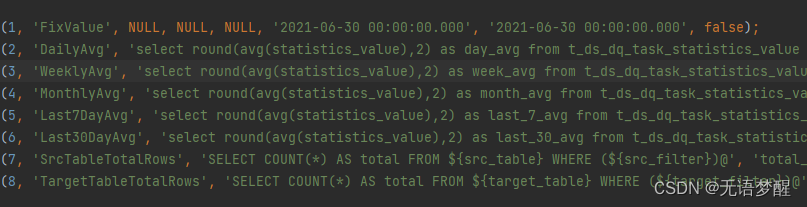
// 源工程:dolphinscheduler_dml.sql
// 数据表:t_ds_dq_comparison_type
// 该表中配置了基础规则的基础功能,下图2
"type":"sql",
"config":{
"index":1,
"output_table":"day_range",
"sql":"select round(avg(statistics_value),2) as day_avg from t_ds_dq_task_statistics_value where data_time >=date_trunc('DAY', '2023-05-15 17:28:53') and data_time < date_add(date_trunc('day', '2023-05-15 17:28:53'),1) and unique_code = 'JRS5R5DSESMCYT3LQ5JQ6GV2I/R7J/KYV2/KTF1N9V4=' and statistics_name = 'cnt'"
}
},
{
"type":"sql",
"config":{
"index":2,
"output_table":"duplicate_items",
"sql":"SELECT type FROM ${hive_database_name}_${hive_table_name} group by type having count(*) > 1"
}
},
{
// 源工程:dolphinscheduler_dml.sql
// 数据表:t_ds_dq_rule_execute_sql
// 该表中配置了基础规则的基础功能,下图3
"type":"sql",
"config":{
"index":3,
"output_table":"duplicate_count",
"sql":"SELECT COUNT(*) AS duplicates FROM duplicate_items"
}
}
],
"writers":[
{
"type":"JDBC",
"config":{
"database":"${mysql_database_name}",
"password":"${password}",
"driver":"com.mysql.cj.jdbc.Driver",
"user":"root",
"table":"t_ds_dq_execute_result",
"url":"jdbc:mysql://${ip}:${port}/${mysql_database_name}?useUnicode=true&characterEncoding=UTF-8&useSSL=false&allowPublicKeyRetrieval=true&allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false",
"sql":"select 0 as rule_type,'$t(uniqueness_check)' as rule_name,0 as process_definition_id,16235 as process_instance_id,77488 as task_instance_id,cnt AS statistics_value,day_range.day_avg AS comparison_value,2 AS comparison_type,0 as check_type,0 as threshold,0 as operator,0 as failure_strategy,'hdfs://${HDFS_NAME}/data_quality_error_data/0_16235_data_quality_test' as error_output_path,'2023-05-15 17:28:53' as create_time,'2023-05-15 17:28:53' as update_time from duplicate_count full join day_range"
}
},
{
"type":"JDBC",
"config":{
"database":"${mysql_database_name}",
"password":"${password}",
"driver":"com.mysql.cj.jdbc.Driver",
"user":"root",
"table":"t_ds_dq_task_statistics_value",
"url":"jdbc:mysql://${ip}:${port}/${mysql_database_name}?useUnicode=true&characterEncoding=UTF-8&useSSL=false&allowPublicKeyRetrieval=true&allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false",
"sql":"select 0 as process_definition_id,77488 as task_instance_id,6 as rule_id,'JRS5R5DSESMCYT3LQ5JQ6GV2I/R7J/KYV2/KTF1N9V4=' as unique_code,'cnt'AS statistics_name,cnt AS statistics_value,'2023-05-15 17:28:53' as data_time,'2023-05-15 17:28:53' as create_time,'2023-05-15 17:28:53' as update_time from duplicate_count"
}
},
{
"type":"hdfs_file",
"config":{
"path":"hdfs://${HDFS_NAME}/data_quality_error_data/0_16235_data_quality_test",
"input_table":"duplicate_items"
}
}
]
}
1.图1
2.图2
3.图3及问题
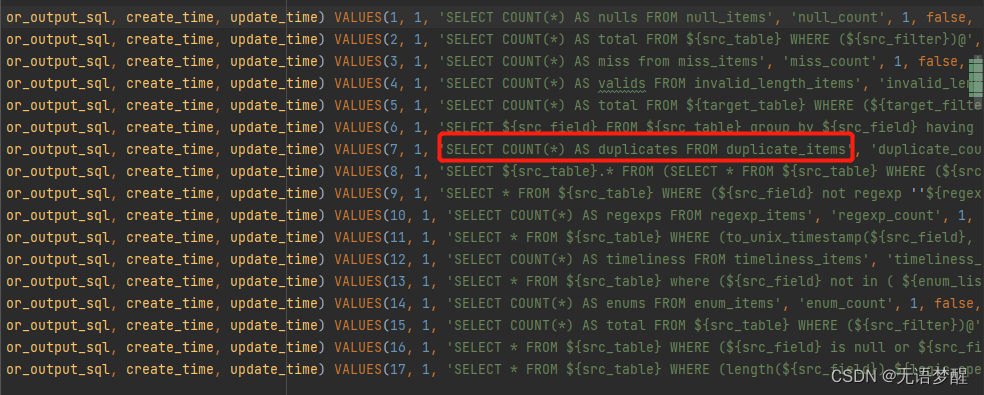
1.未知cnt字段
- 由于在图3中可见SQL语句实际上如下
- 原始SQL语句:SELECT COUNT(*) AS duplicates FROM duplicate_items
- 但是下游使用上述语句的输出表的时候实际上是duplicate_count.cnt
- 这就导致了下述的问题
- 所以需要在t_ds_dq_rule_execute_sql表中将原始SQL语句变更为
- 变更SQL语句:SELECT COUNT(*) AS cnt FROM duplicate_items
[INFO] 2023-05-15 17:29:04.335 +0800 - -> Exception in thread "main" org.apache.spark.sql.AnalysisException: cannot resolve 'cnt' given input columns: [day_range.day_avg, duplicate_count.duplicates]; line 1 pos 138;
'Project [0 AS rule_type#69, (uniqueness_check) AS rule_name#70, 0 AS process_definition_id#71, 16235 AS process_instance_id#72, 77488 AS task_instance_id#73, 'cnt AS statistics_value#74, day_avg#60 AS comparison_value#75, 2 AS comparison_type#76, 0 AS check_type#77, 0 AS threshold#78, 0 AS operator#79, 0 AS failure_strategy#80, hdfs://HDFS8001702/user/yarn/data_quality_error_data/0_16235_data_quality_test AS error_output_path#81, 2023-05-15 17:28:53 AS create_time#82, 2023-05-15 17:28:53 AS update_time#83]
+- Join FullOuter
……………………
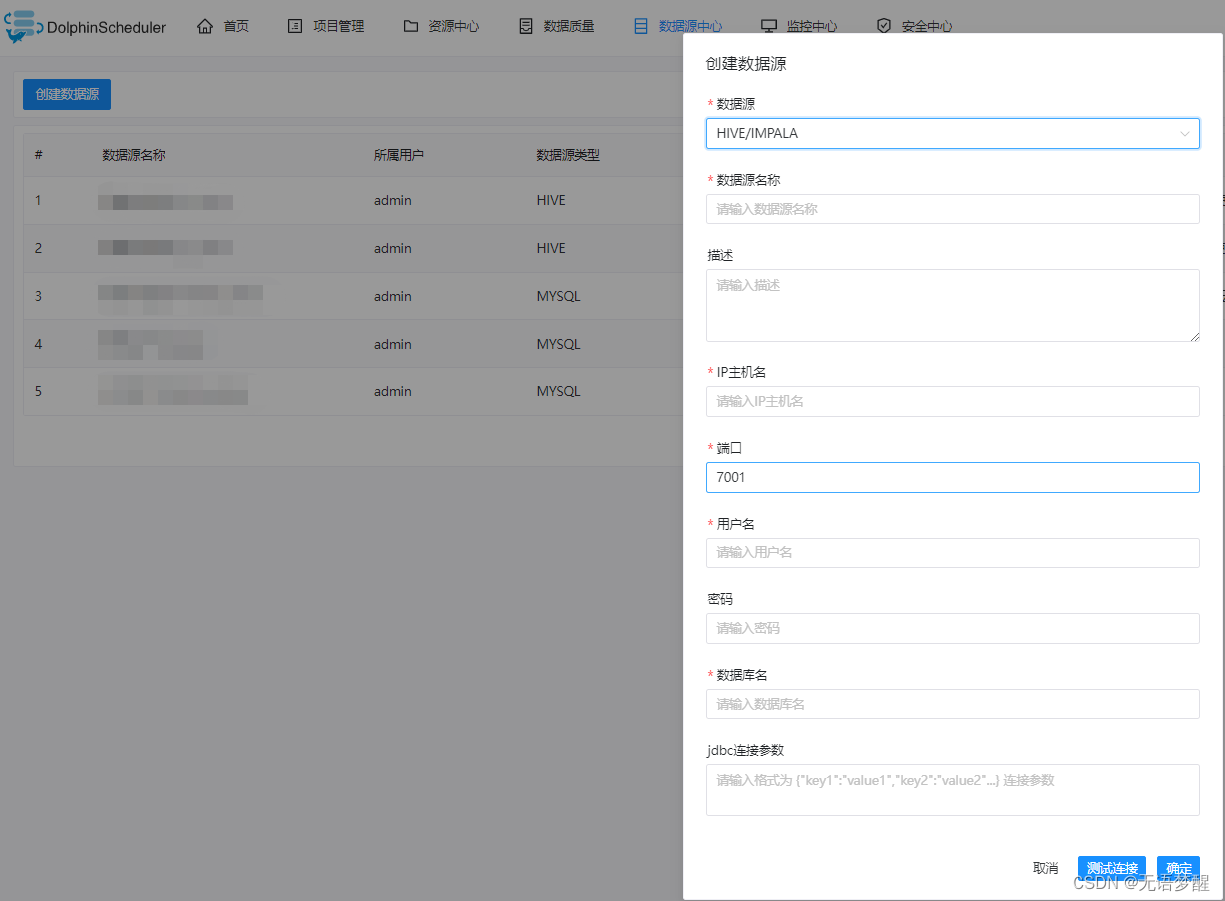
3.创建数据源
- 监控数据质量的前提是要有想要监控的源数据,所以首先需要在DolphinScheduler的数据源中心创建想要监控的目标数据源
- DolphinScheduler支持的数据源类型包括:MYSQL,POSTGRESQL,HIVE/IMPALA,SPARK,CLICKHOUSE,ORACLE,SQLSERVER,DB2,PRESTO,REDSHIFT。感觉常用的数据库连接都是支持的
- 创建过程也比较简单,选好对应的数据库类型,填写对应的IP和端口即可,HIVE的端口我这里因为是用腾讯云测试的,所以端口是7001,正常访问默认应该是10000,其实就是HiveServer提供Thrift服务的端口,密码看个人有没有配置,因为直接连接的是HiveServer所以数据库地址不用写HDFS的前缀,建好以后测试连接通过即可
4.数据质量检测节点
一开始我在数据质量的模块里找了半天如何创建监控任务,直到我在工作类型中看到DATA_QUALITY,我……
根据官方文档中的失败策略可预料的数据质量场景:

- 单独有一个模块去做所有核心数据的质量监控报警等等
- 监控上游任务数据,保障下游任务不空跑或及时发现问题避免资源浪费
核心配置项如下,不同的监控规则可以在数据质量的规则管理界面查看
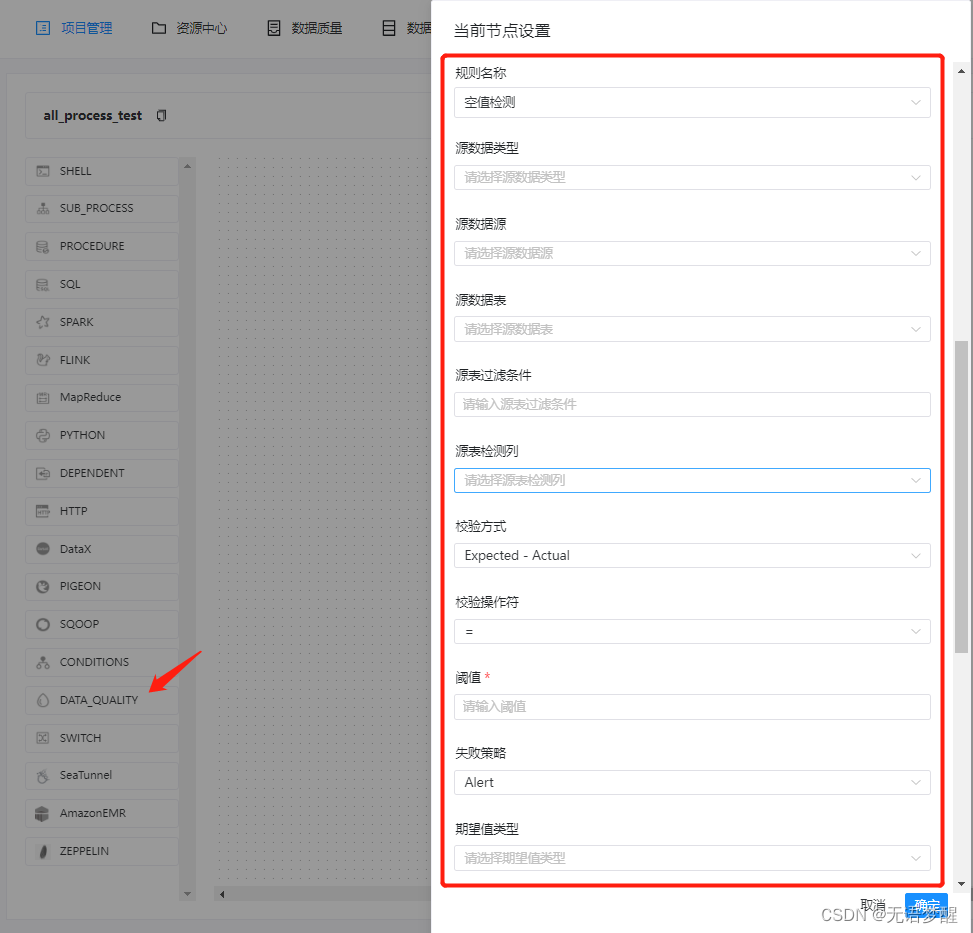
- 数据质量任务默认是用spark任务在跑的,文档中也提到了“数据质量任务的运行环境为Spark2.4.0,其他版本尚未进行过验证,用户可自行验证”,目前我这边使用的Spark版本是3.2.2,暂时妥协了,重新配置了一个spark2.4,目前是可以使用了

5.数据质量结果