系列文章目录
前言
在项目进度管理中,NSGA-II是常用的求解多目标项目进度管理优化问题的算法,虽然NSGA-III也出来了些日子,但是目前主流的研究MORCPSP问题的论文大多采用NSGA-II算法。我认为主要有三个原因:
第一个是,NSGA-III算法需要更大的计算代价,因为它需要进行额外的种群初始化和排序操作来维护解的分布。这增加了算法的时间复杂度。第二就是,NSGA-III算法需要更多的参数设置,如分治桶的数量和邻域半径等。这些参数的不恰当设置可能会影响算法的性能。最后一点我觉得应该是,NSGA-III算法对目标函数的连续性和可微性有更高的要求。如果目标函数不满足这些条件,NSGA-III算法可能无法找到全局最优解。
所以,在多目标资源受限问题上,NSGA-II算法仍然是一种更为通用和高效的解决方案,因为它具有更快的速度、更少的参数和对目标函数的较低要求。而我们在求解MORCPSP问题的时候,往往最追求的就是效率问题,即在短时间内求得问题的最优解(或近似最优解)。
为了能吃透NSGA-II算法,为求解MORCPSP问题打基础,我这里先用NSGA-II求解一个常规的多目标高次函数的帕累托前沿。
一、模型的建立
研究的模型为:min(y1=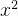 ,x
,x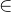 [0,10]), min(y2=
[0,10]), min(y2=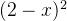 ,x[0,10])。 即求解两个目标函数最小值的问题。
,x[0,10])。 即求解两个目标函数最小值的问题。
二、算法的步骤
1 设置参数,定义种群大小、进化代数、交叉概率、变异概率等
2 定义一个自变量的类,这个类的属性值包括自变量x的值、目标函数值、非支配排序列表、拥挤度距离。
3 通过random.uniform()函数初始化种群。
4 迭代进化部分:
4.1 计算目标函数的值
4.2 进行非支配排序
4.3 计算拥挤度距离
4.4 依次变异、交叉、更新种群
5 输出最优解集合并可视化展示出帕累托前沿离散图像
三、代码的实现
代码如下:
import copy
import random
import matplotlib.pyplot as plt
# 设置参数
pop_size = 100 # 种群大小
gen_size = 500 # 进化代数
pc = 1 # 交叉概率
pm = 0.3 # 变异概率
num_obj = 2 # 目标函数个数
x_range = (-10, 10) # 自变量取值范围
# 定义自变量的类
class Individual:
def __init__(self, x):
self.x = x
self.objs = [None] * num_obj
self.rank = None
self.distance = 0.0
# 计算目标函数的值
def evaluate(self):
self.objs[0] = self.x * self.x
self.objs[1] = (2 - self.x) ** 2
# 初始化种群
pop = [Individual(random.uniform(*x_range)) for _ in range(pop_size)]
# 进化
for _ in range(gen_size):
print(f"第{_}次迭代")
# 计算目标函数的值
for ind in pop:
ind.evaluate()
# 非支配排序
fronts = [set()]
for ind in pop:
ind.domination_count = 0
ind.dominated_set = set()
for other in pop:
if ind.objs[0] < other.objs[0] and ind.objs[1] < other.objs[1]:
ind.dominated_set.add(other)
elif ind.objs[0] > other.objs[0] and ind.objs[1] > other.objs[1]:
ind.domination_count += 1
if ind.domination_count == 0:
ind.rank = 1
fronts[0].add(ind)
rank = 1
while fronts[-1]:
next_front = set()
for ind in fronts[-1]:
ind.rank = rank
for dominated_ind in ind.dominated_set:
dominated_ind.domination_count -= 1
if dominated_ind.domination_count == 0:
next_front.add(dominated_ind)
fronts.append(next_front)
rank += 1
# 计算拥挤度距离
pop_for_cross=set()
for front in fronts:
if len(front) == 0:
continue
sorted_front = sorted(list(front), key=lambda ind: ind.rank)
for i in range(num_obj):
sorted_front[0].objs[i] = float('inf')
sorted_front[-1].objs[i] = float('inf')
for j in range(1, len(sorted_front) - 1):
delta = sorted_front[j + 1].objs[i] - sorted_front[j - 1].objs[i]
if delta == 0:
continue
sorted_front[j].distance += delta / (x_range[1] - x_range[0])
front_list = list(sorted_front)
front_list.sort(key=lambda ind: (-ind.rank, -ind.distance))
selected_inds =front_list
if len(pop_for_cross) + len(selected_inds)<=pop_size:
pop_for_cross.update(selected_inds)
elif len(pop_for_cross)+len(selected_inds)>=pop_size and len(pop_for_cross)<pop_size:
part_selected_inds=selected_inds[:(pop_size-len(pop_for_cross))]
pop_for_cross.update(part_selected_inds)
break
# 交叉
new_pop=set()
# print(len(pop_for_cross))
while len(new_pop) < len(pop_for_cross):
x1, x2 = random.sample(pop_for_cross, 2)
if random.random() < pc:
new_x = (x1.x + x2.x) / 2
delta_x = abs(x1.x - x2.x)
new_x += delta_x * random.uniform(-1, 1)
new_x = max(x_range[0], min(x_range[1], new_x))
new_pop.add(Individual(new_x))
# 变异
for ind in new_pop:
if random.random() < pm:
delta_x = random.uniform(-1, 1) * (x_range[1] - x_range[0])
ind.x += delta_x
ind.x = max(x_range[0], min(x_range[1], ind.x))
# 更新种群,把原来的精英(pop_for_cross)保留下来。即精英保留策略
pop = list(new_pop)+list(pop_for_cross)
# 输出最优解集合
for ind in pop:
ind.evaluate()
pareto_front = set()
for ind in pop:
dominated = False
for other in pop:
if other.objs[0] < ind.objs[0] and other.objs[1] < ind.objs[1]:
dominated = True
break
if not dominated:
pareto_front.add(ind)
print("Pareto front:")
for ind in pareto_front:
print(f"x={ind.x:.4f}, y1={ind.objs[0]:.4f}, y2={ind.objs[1]:.4f}")
# 可视化
plt.scatter([ind.objs[0] for ind in pop], [ind.objs[1] for ind in pop], c='gray', alpha=0.5)
plt.scatter([ind.objs[0] for ind in pareto_front], [ind.objs[1] for ind in pareto_front], c='r')
plt.xlabel('Objective 1')
plt.ylabel('Objective 2')
plt.show()
四、输出的结果
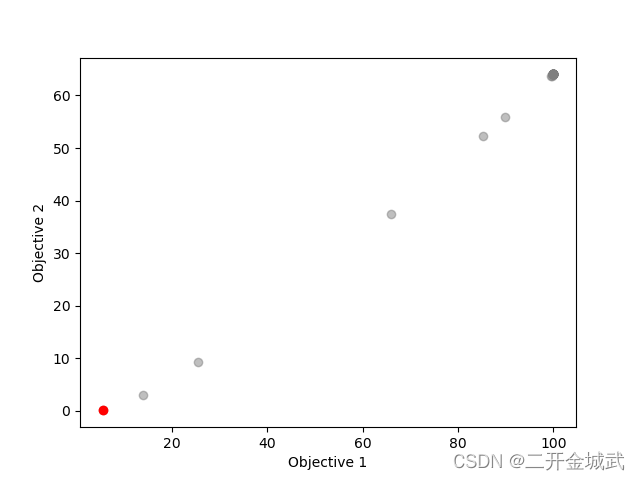
分别输出了最优解(近似最优解)及帕累托前沿的离散图像:

总结
程序每一次运行的结果可能都不一样,这也是像遗传算法这样的启发式算法的特性。此外,还可以考虑画一条种群的平均适应度函数值(最好归一化处理后)随着迭代次数变化的曲线,能够更加直观地展示迭代的梯度上升的过程。