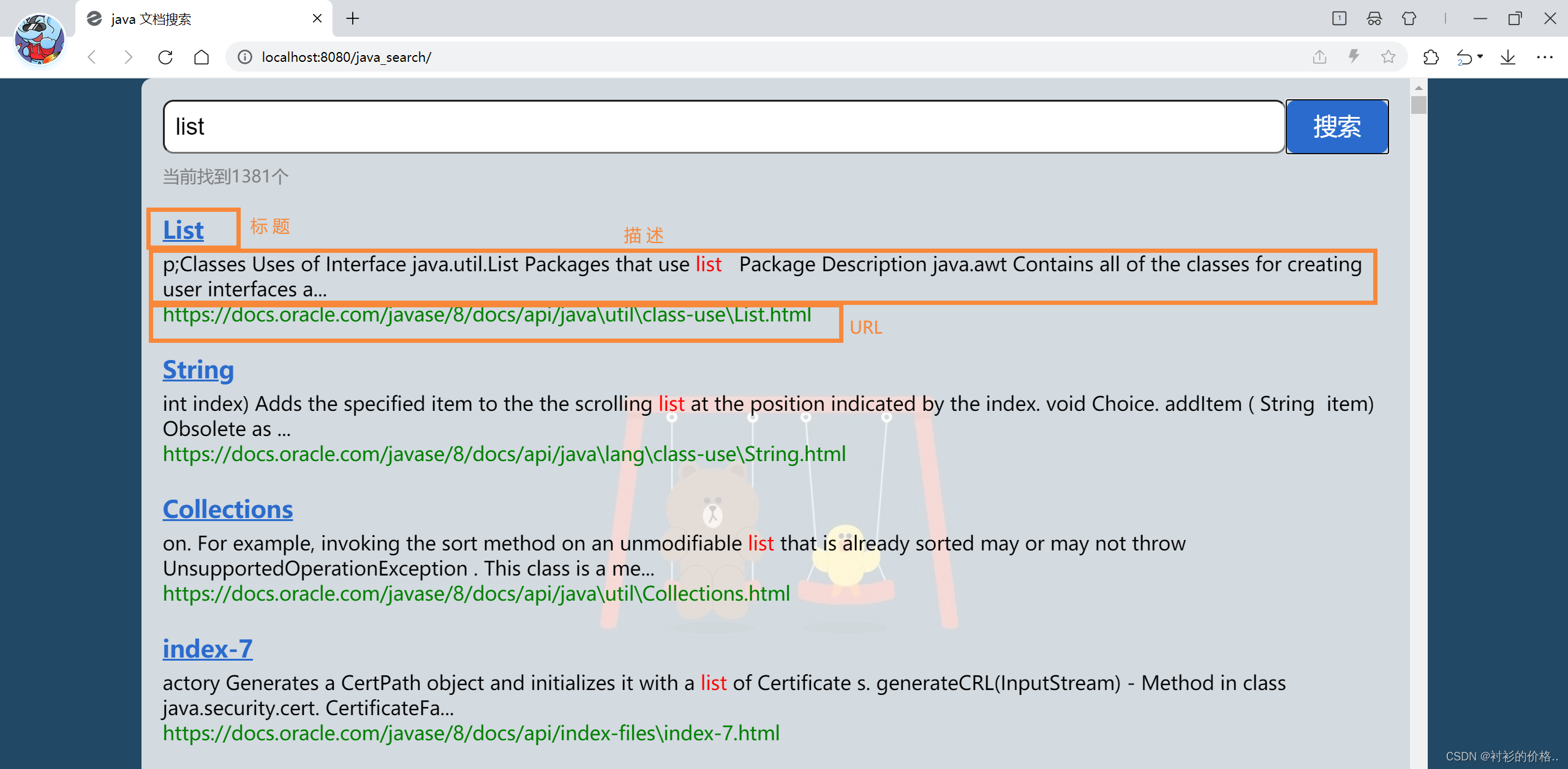
项目介绍
本项目是一个基于SpringBoot的针对Java文档的站内搜索引擎,当用户在页面上输入查询词后,就会快速的查询出相关的文档然后跳转至在线页面,弥补了Java在线文档中没有搜索查询的缺陷
因为当前这个项目只是针对 Java 官方文档设计的一个搜索引擎,总共也就一万多条记录,所以我们可以提前将 Java官方文档下载到本地, 然后对其进行预处理。
此处的预处理就是构建正排索引,倒排索引
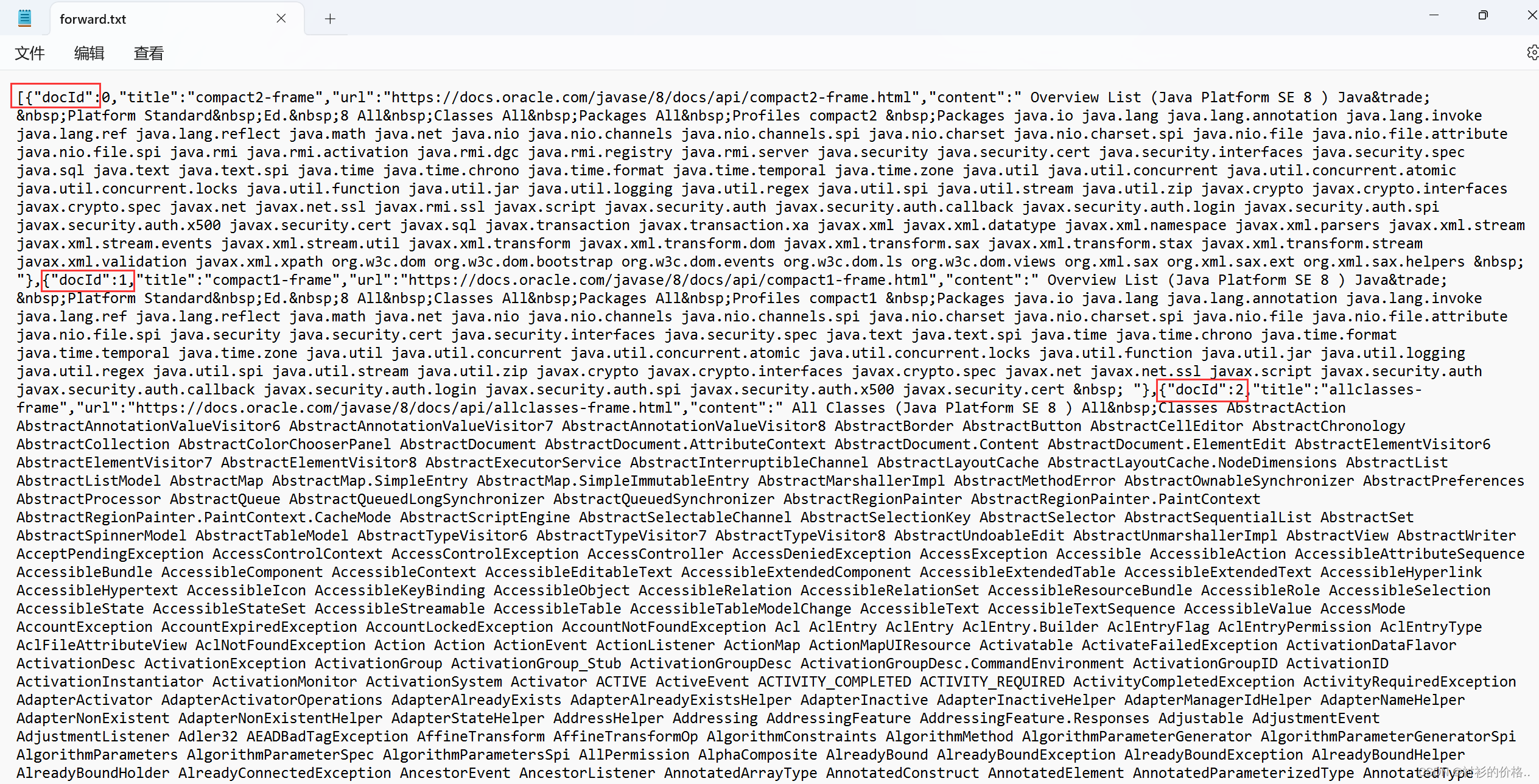
- 正排索引 : 给一个 id,可以查出对应文档的基本信息,包括文档标题,文档正文,文档 URL
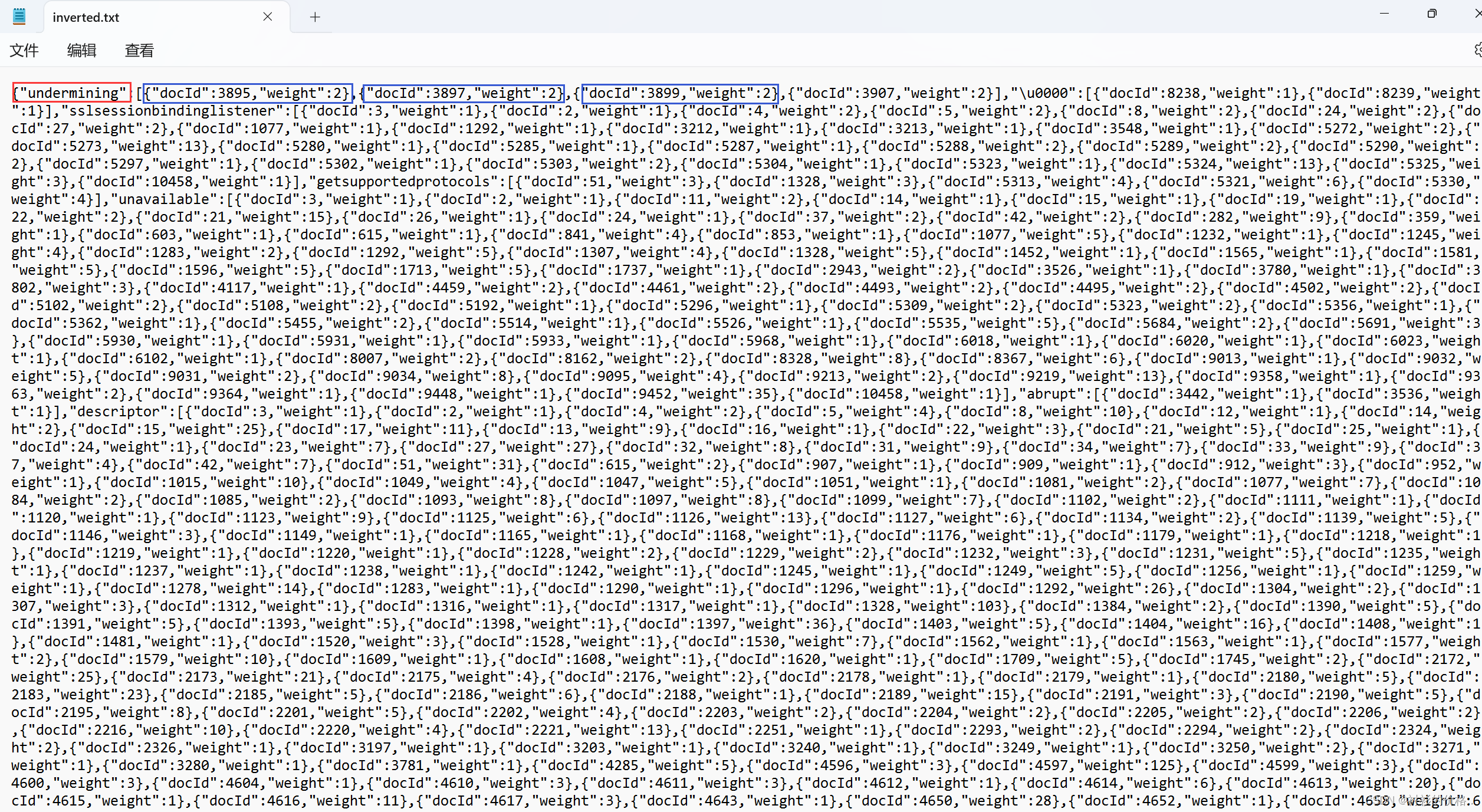
- 倒排索引 : 给一个查询词,查那些文档和这个词有关联,文档肯定很多,所以返会一个List
项目模块划分及分析
1.索引模块
- 整个索引模块主要涉及2个类 . Parser类主要负责解析文件 , Index类主要负责把在内存中构造好的索引数据结构,保存到指定的文件中
Parser 类核心业务

- 根据指定的路径,使用 enumFile() 枚举 出该路径中所有的 html 文件,这个过程需要把所有子目录中的文件都能获取到
private void enumFile(String inputPath, ArrayList<File> fileList) {
File rootPath = new File(inputPath);
//使用 listFiles 只能看到一级目录,看不到子目录里的内容
//要想看到子目录里的内容,还要进行递归
File[] files = rootPath.listFiles();//listFiles 能够获取到 rootPath 当前目录下所包含的文件/目录
for(File f : files){
//根据当前 f 的类型,是否要来递归
//如果 f 是一个普通文件,就把 f 加入到 listFiles 结果中
//如果 f 是一个目录,就递归的调用 enumFile 这个方法,进一步获取子目录中的内容
if(f.isDirectory()){
enumFile(f.getAbsolutePath(),fileList);
}else{
if(f.getAbsolutePath().endsWith(".html")){
//有些是图片,文字等等,js文件
//找到以 .html结尾的文件,然后在添加
fileList.add(f);
}
}
}
}
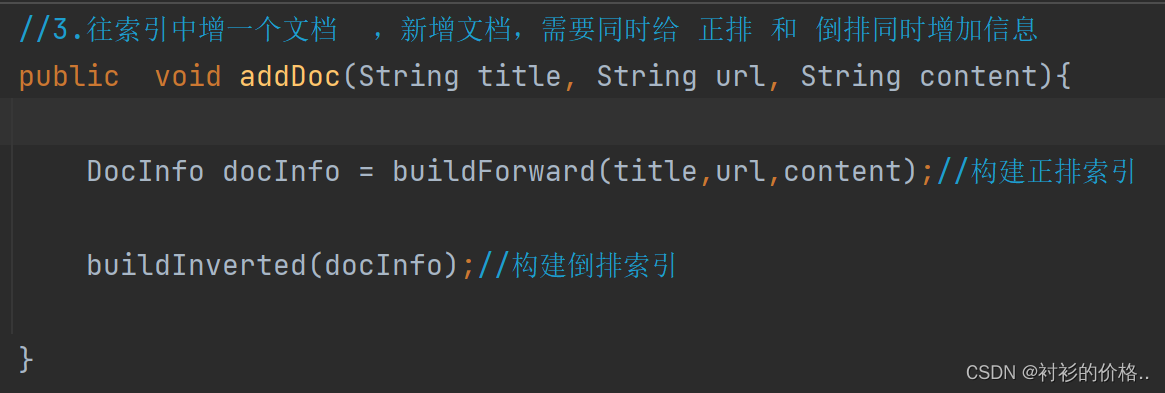
- 针对上面罗列出的文件的路径,打开文件,读取文件内容并进行解析parseHTML(),并构建索引
- 把解析的结果调用index里面的addDoc 方法,构建倒排和正排索引
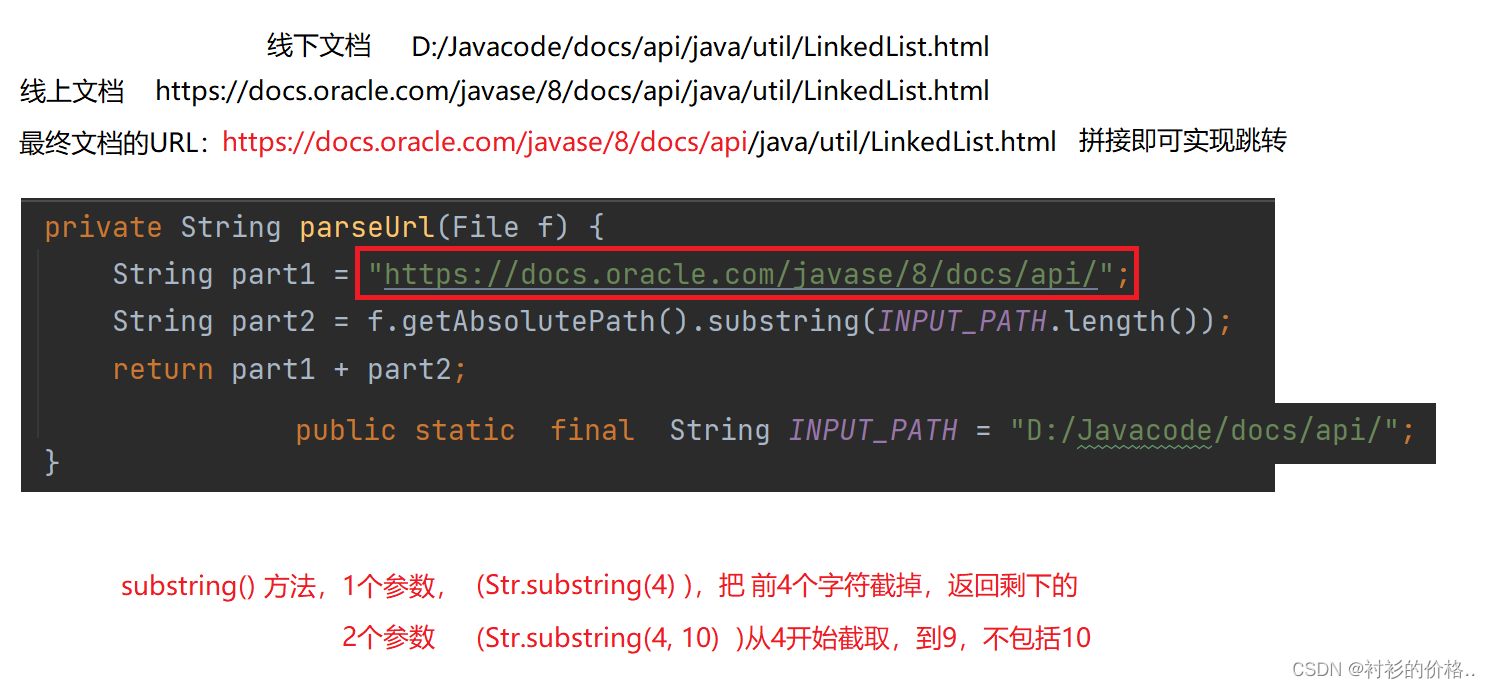
private void parseHTML(File f) {
//1.解析标题
String title = parseTitle(f);
//2.解析对应的URL
String url = parseUrl(f);
//3.解析对应的正文(描述)
//String content = parseContent(f);
String content = parseContentByRegex(f);
//4.把解析出来的信息,加入到索引当中
index.addDoc(title,url,content);
}
- 保存索引

- 解析URL
Index 核心业务
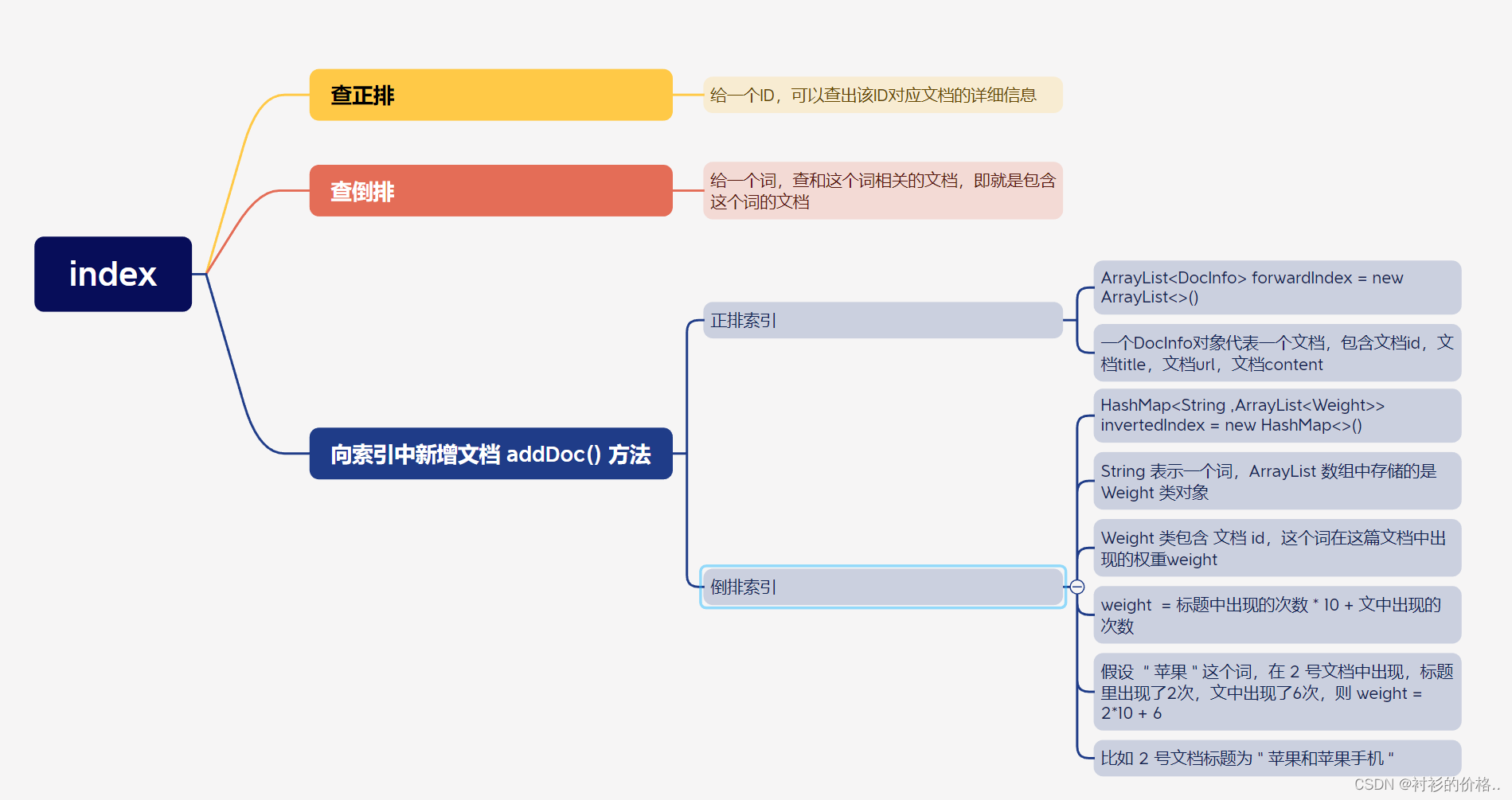
- 构建正排索引 ,给定一个id,查对应文档的详细信息返回DocInfo类的对象

public class DocInfo {
private int docId;
private String title;
private String url;
private String content;
}
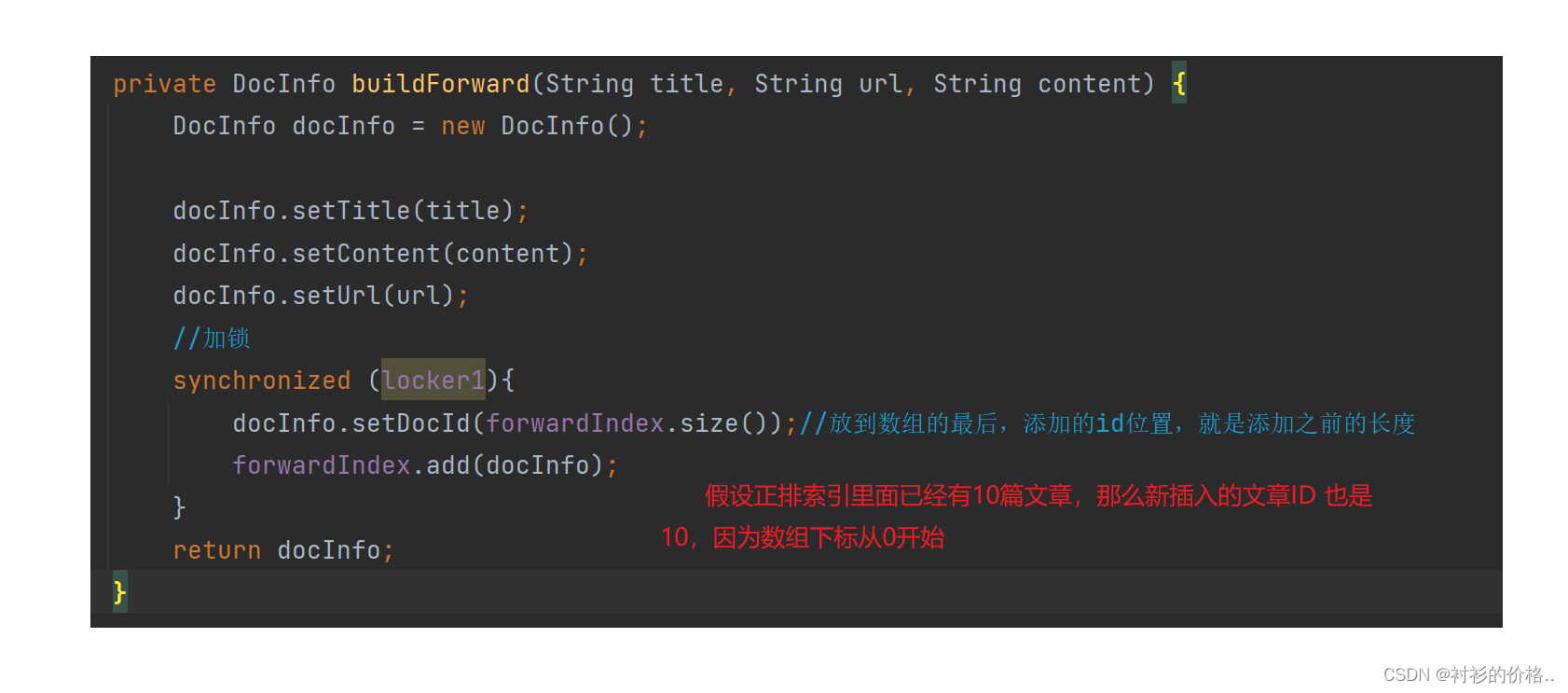
- 构建倒排索引,给定一个词,查那些文档和这个词有关联,文档肯定很多,所以返会一个List

private void buildInverted(DocInfo docInfo) {
class WordCnt{//内部类
public int titleCount;//表示这个词在标题中出现的次数
public int contentCount;//表示这个词在正文中出现的次数
}
HashMap<String,WordCnt> wordCntHashMap = new HashMap<>();//这个数据结构用来统计词频
//1.针对文档标题进行分词
List<Term> terms = ToAnalysis.parse(docInfo.getTitle()).getTerms();
//2.遍历分词结果,统计每个词出现的次数
for(Term term:terms){
//先判定 term 是否存在
String word = term.getName();
WordCnt wordCnt = wordCntHashMap.get(word);
if(wordCnt == null){
//如果不存在,就创建一个新的键值对,插入进去,
WordCnt newWordCnt = new WordCnt();
newWordCnt.titleCount = 1;//标题中出现的次数+1
newWordCnt.contentCount = 0;
wordCntHashMap.put(word,newWordCnt);
}else{
//如果存在,就找到之前的值,然后把对应的 titleCount +1
wordCnt.titleCount += 1;
}
}
//3.针对正文进行分词
terms = ToAnalysis.parse(docInfo.getContent()).getTerms();
//4.遍历分词结果,统计每个词出现的次数
for(Term term:terms){
//先判定 term 是否存在
String word = term.getName();
WordCnt wordCnt = wordCntHashMap.get(word);
if(wordCnt == null){
//如果不存在,就创建一个新的键值对,插入进去,
WordCnt newWordCnt = new WordCnt();
newWordCnt.titleCount = 0;
newWordCnt.contentCount = 1;//文章中出现的次数+1
wordCntHashMap.put(word,newWordCnt);
}else{
//如果存在,就找到之前的值,然后把对应的 titleCount +1
wordCnt.contentCount += 1;
}
}
//5.把上面的结果汇总到一个HashMap中,最终文档的权重,就设定成 标题中出现的次数*10+正文中出现的次数
//6.遍历这个HashMap,依次更新倒排索引中的结构
for (Map.Entry<String ,WordCnt> entry: wordCntHashMap.entrySet()) {
//Map不好遍历,先把Map转成Set然后才可以进行遍历
synchronized (locker2){
List<Weight> invertedList = invertedIndex.get(entry.getKey());//一个值
if(invertedList == null){
//如果为空,插入新的键值对
ArrayList<Weight> newInvertedList = new ArrayList<>();
//把新的文档(当前DocInfo)构造成 search.Weight 对象,插入进来
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
newInvertedList.add(weight);
invertedIndex.put(entry.getKey(),newInvertedList);
}else {
//如果非空,就把当前文档,构造成一个 search.Weight 对象,
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
invertedList.add(weight);
}
}
}
}
public DocInfo getDocInfo(int docId){
return forwardIndex.get(docId);
}
- 查倒排
-
直接通过 key 获取 value , 返回 Weight 类 数组 , 每个 Weight 存放该词所在的文章及在这篇文章中的权重(或者说与这篇文章的关联性)
-
我们认为一个词 在标题中出现比在文章中出现重要的多,最终文档的权重,就设定成
-
weight = 标题中出现的次数 *20 + 正文中出现的次数
public List<Weight> getInverted(String term){
return invertedIndex.get(term);
}
多线程制作索引
- 创建固定数量的线程池
- 使用submit 提交任务到线程池中
提交任务,是否存在submit已经提交完任务了,但是线程池还没有把文档解析完
必须要等待所有的线程把所有的文档任务都处理完,才能保存索引
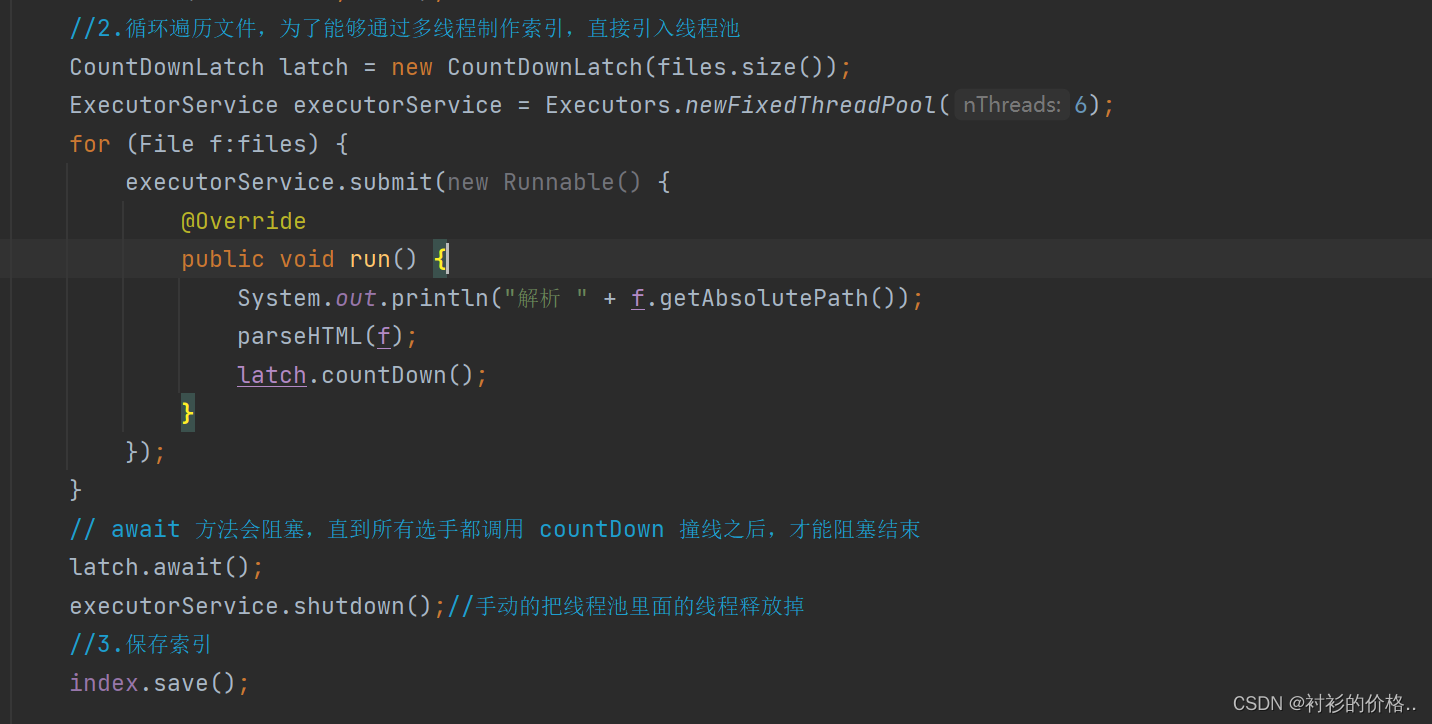
构建索引的核心是解析HTML文件
- 构建正排可能会有几个线程同时向1个位置添加,因此会出现线程安全问题
构建倒排更新倒排索引的时候,也有可能会有线程安全问题
- 如果直接把Synchronized 加到parseHTML,那只能顺序的执行解析标题,解析正文,添加索引,速度又慢了,并且解析标题,和解析正文,并不会有线程安全问题,
或者直接锁到 addDoc()这样的方法上,锁的粒度太粗了,并发程度不高
都针对index 实例加锁,构建正排的时候,就不能构建倒排
- 构建正排和构建倒排,操作不同的对象,不应该产生锁竞争,因此加上不同的锁
2.搜索模块
调用索引模块,来完成搜索的核心过程
- 分词:针对用户输入的查询词进行分词,(因为用户输入的查询词,可能不是一个词,可能是一句话)
- 触发:拿着每个分词结果, 去倒排索引中查,找到具有相关性的文档(调用Index类里面的查倒排的方法)
List<Weight> allTermResult = new ArrayList<>();
for(Term term : terms){
String word = term.getName();//获取每个词的内容
List<Weight> invertedList = index.getInverted(word);
if(invertedList == null){
continue;
}
allTermResult.addAll(invertedList);
}
-
排序,针对上面触发的结果,按照相关性,降序排序
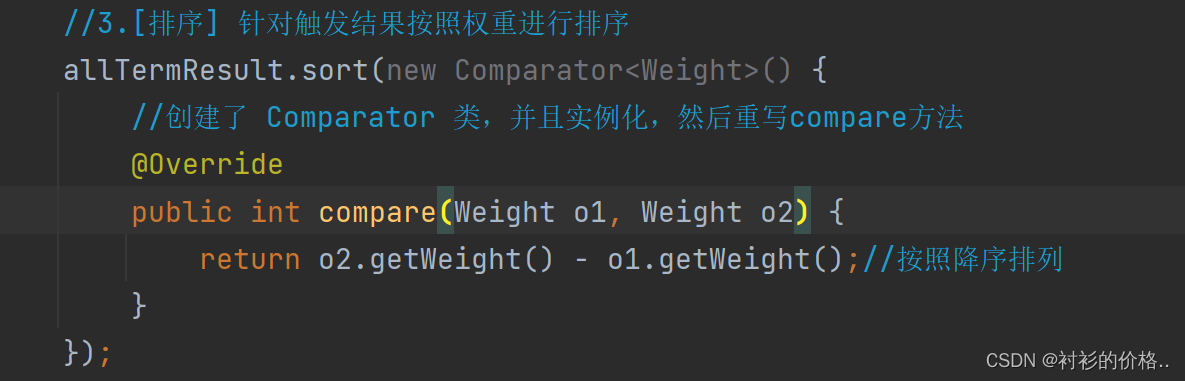
-
包装结果,根据排序后的结果,依次去查正排,获取到每个文档的详细信息,保装成一定结构的数据返回去
List<Result> results = new ArrayList<>();
for (Weight weight : allTermResult){
DocInfo docInfo = index.getDocInfo(weight.getDocId());
Result result = new Result();
result.setTitle(docInfo.getTitle());
result.setUrl(docInfo.getUrl());
result.setDesc(GenDesc(docInfo.getContent(),terms));
results.add(result);
}
return results;
分词
- 用户在搜索引擎中输入的可能是一个词,也可能是一句话,并不会按照你的理想情况进行输入,因此要进行分词
- 针对标题进行分词,针对文档进行分词
- 遍历分词结果,统计每个词出现的次数
//1.针对文档标题进行分词
List<Term> terms = ToAnalysis.parse(docInfo.getTitle()).getTerms();
//2.遍历分词结果,统计每个词出现的次数
for(Term term:terms){
//先判定 term 是否存在
String word = term.getName();
WordCnt wordCnt = wordCntHashMap.get(word);
if(wordCnt == null){
//如果不存在,就创建一个新的键值对,插入进去,
WordCnt newWordCnt = new WordCnt();
newWordCnt.titleCount = 1;//标题中出现的次数+1
newWordCnt.contentCount = 0;
wordCntHashMap.put(word,newWordCnt);
}else{
//如果存在,就找到之前的值,然后把对应的 titleCount +1
wordCnt.titleCount += 1;
}
}
生成描述
- 前端页面展示的有标题,描述,URL
描述就是正文的一段摘要,摘要来自于正文,可以获取到所有查询词的分词结果,遍历分词结果,看哪个结果在正文中出现
- 针对当前这个文档 来说,不一定会包含所有的分词结果
就针对这个被包含的分词结果,去正文中查找,找到对应的位置,以这个词的位置为中心,往前截取40个字符,作为描述的开始,再从描述开始,往后截取190个字符,作为整个描述
- 这个数字不是唯一的,可以根据情况来定
private String GenDesc(String content, List<Term> terms) {
//先遍历分词结果,看看那个结果是在 content 中存在
int firstPos = -1;
for(Term term : terms){
String word = term.getName();
firstPos = content.toLowerCase().indexOf(" "+ word+" ");//正文转成小写
if(firstPos >= 0){
break;
}
}
if(firstPos == -1){
//所有的分词结果都不在正文中存在
if(content.length() > 160){
return content.substring(0,160) + "...";
}
return content;
}
String desc ="";
int descBegin = firstPos < 60 ? 0:firstPos-60;//找描述的起始位置,firstPos 小于 60直接返回0,否则向前找60个字符
if(descBegin + 160 > content.length()){
// descBegin + 160 大于正文的长度了,直接就是从它开始一直截到末尾
desc = content.substring(descBegin);
}else{
//否则的话,就往后再找160个字符
desc = content.substring(descBegin,descBegin + 160) + "...";
}
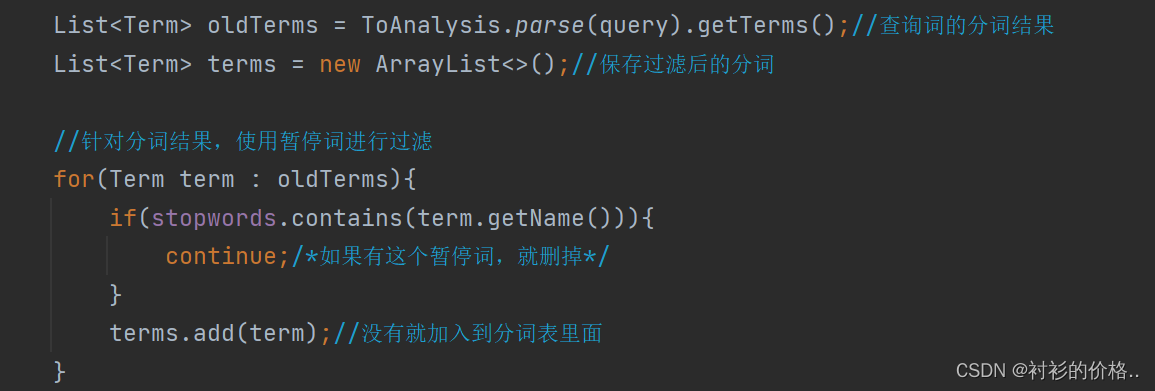
停用词
- 当我们的查询词为array空格list的时候,分词结果为:array,空格,list
因此会出现,不含array,list 但是包含空格的搜索结果,这样的就叫停用词,就是很高频,但是又没有什么意义,比如,a,is,hava,
- 把暂停词加载到内存的HashSet里面
针对查询词分词以后,使用暂停词表处理分词后的查询词,遍历分词结果,在暂停词里面查找
- 如果该词在暂停词表里面存在,则该词无意义删掉,
如果不存在,就把它加入新的分词结果List里面
3.Web模块
- 即就是前端页面,编写一个简单的页面,展示搜索结果,点击搜索结果标题能跳转到对应的 Java API 文档页面
展示