为什么将回归问题转化成分类问题?
解空间变小。
softmax和sigmoid的区别?
为什么用多项分布,多项分布能天然刻画值域变化趋势的。
有序回归不适合上下关系传导的。
softmax是建模多项分布,可以天然刻画值域变化趋势的。这种多项分布能够很好的进行传递到下游。而有序回归,不适合上下游关系的传导。
梯度空洞问题。
树
1、在以下集成学习模型的调参中,哪个算法没有用到学习率learning rate? B
A.XGboost
B.随机森林Random Forest
C.LightGBM
D.Adaboost
分析:其他三个都是基于梯度的算法,有梯度基本都有学习率,详细的可以去看看他们的更新公式。
2、在集成学习两大类策略中,boosting和bagging如何影响模型的偏差(bias)和方差(variance)?C
A. boosting和bagging均使得方差减小
B. boosting和bagging均使得偏差减小
C. boosting使得偏差减小,bagging使得方差减小
D. boosting使得方差减小,bagging使得偏差减小
3、梯度提升决策树(GBDT)是在工业界和竞赛里最常用的模型之一,Xgboost和Lightgbm均是改进版的GBDT模型。关于调整参数缓解过拟合,以下说法正确的是:C
1、增大正则化参数
2、减小树数量tree numbers
3、减小子采样比例subsample
4、增大树深度max_depth
A.1、2、3
B.1、2、4
C.1、3、4
D.2、3、4
分析:树越多越不会过拟合;树的深度,越深代表模型越复杂,越容易过拟合;减小子采样比例subsample,类似神经网络里面的dropout,能缓解过拟合。
2叉和3叉的区别
1、稳定不一样,二叉树鲁棒性更强
2、3叉高阶组合少了,二叉树表达能力更强
3、男女这种特证做三叉树不好做
xgboost相对于GBDT的改进?
lt相对于xgboost的改进?
特征工程
1、特征选择(Feature selection)对于机器学习任务是十分重要的,是解决维度灾难的有效方法。以下关于特征选择算法的说法不正确的是? D
A. 过滤式方法(Filter)通常是独立地选择特征,这可能会忽略特征组合之间的相关性。
B. 封装式方法(Wrapper)可能所选特征效果好,但是时间复杂度通常非常高。
C. 方差选择法、相关系数法、假设检验法、互信息法均属于过滤式方法。
D. 在嵌入式方法(Embedded )中,特征选择与模型训练是独立的过程。
连续特征的离散化:在什么情况下将连续的特征离散化之后可以获得更好的效果?
有人说:在工业界,很少直接将连续值作为逻辑回归模型的特征输入,而是将连续特征离散化为一系列0、1特征交给逻辑回归模型。
1.计算速度:稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
2.鲁棒性:离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;
4. 表达能力:离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
5.稳定性:特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问;
6.过拟合:特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。
李沐也曾经说过:模型是使用离散特征还是连续特征,其实是一个“海量离散特征+简单模型”同“少量连续特征+复杂模型”的权衡。既可以离散化用线性模型,也可以用连续特征加深度学习。就看是喜欢折腾特征还是折腾模型了。通常来说,前者容易,而且可以n个人一起并行做,有成功经验;后者目前看很赞,能走多远还须拭目以待。
为什么要将数字(一个完全有效的模型输入)拆分为分类值?请注意,该分类将单个输入数字分成了一个四元素矢量。因此,模型现在可以学习四个单独的权重,而非仅仅一个;相比一个权重,四个权重能够创建一个内容更丰富的模型。更重要的是,借助分桶,模型能够清楚地区分不同年份类别,因为仅设置了一个元素 (1),其他三个元素则被清除 (0)。当我们仅将单个数字(年份)用作输入时,模型只能学习线性关系。因此,分桶为模型提供了可用于学习的额外灵活性。
连续变离散特征怎么划分:
1、naive的可以通过人为先验知识划分
2、通过训练单特征的决策树桩,根据Information Gain/Gini系数等来有监督的划分。
注:https://www.zhihu.com/question/31989952
one hot后有什么优点
1、起到了扩充特征的作用
2、逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个特征后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合。
LR是广义线性模型,因此如果特征“年龄”不做离散化直接输入,那么只能得到“年龄”和魅力指数的一个线性关系。但是这种线性关系是不准确的,并非年龄越大魅力指一定越大;如果将年龄划分为M段,则可以针对每段有一个对应的权重;这种分段的能力为模型带来类似“折线”的能力,也就是所谓的非线性。
什么情况需要one hot
将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码。 有些基于树的算法在处理变量时,并不是基于向量空间度量,数值只是个类别符号,即没有偏序关系,所以不用进行独热编码。 Tree Model不太需要one-hot编码,对于决策树来说,one-hot的本质是增加树的深度。
总的来说,要是one hot encoding的类别数目不太多,建议优先考虑。
样本处理
1、用于样本划分的函数
randomSplit(weigh , seed),作用于spark RDD
参数:
weights: 是一个数组。根据 weight 将一个RDD划分成多个RDD,权重越高划分得到的元素较多的几率就越大,数组的长度即为划分成RDD的数量。如rdd1 = rdd.randomSplit([0.25,0.25,0.25,0.25]),作用是把原本的RDD尽可能的划分成4个相同大小的RDD,需要注意的是weight数组内数据的加和应为1。
seed: 是可选参数 ,作为random的种子。根据种子构造出一个Random类。在电脑中实际上是无法产生真正的随机数的,都是根据给定的种子,通过一个固定的计算公式来得到下一个随机数。seed就是要求使用固定的种子来开始生成随机数,在给定相同的种子下,生成的随机数序列总是相同的。
返回值:
返回一个rdd数组
例子:
rdd = sc.parallelize(range(20))
rdd.colect()
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
rdd1 = rdd.randomSplit([0.25,0.25,0.25,0.25])
rdd1[0].collect()
# [1, 13]
rdd1[1].collect()
# [3, 6, 8, 10, 11]
rdd1[2].collect()
# [5, 9, 12, 14, 16]
rdd1[3].collect()
# [0, 2, 4, 7, 15, 17, 18, 19]
sklearn的train_test_split:train_test_split函数用于将矩阵随机划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签。
X_train,X_test, y_train, y_test =cross_validation.train_test_split(train_data,train_target,test_size=0.3, random_state=0)
参数:
train_data:被划分的样本特征集
train_target:被划分的样本标签
test_size:如果是浮点数,在0-1之间,表示样本占比;如果是整数的话就是样本的数量。
random_state:是随机数的种子。随机数种子填0或不填,每次随机的数都会不一样。
import numpy as np
from sklearn.model_selection import train_test_split
X, y = np.arange(10).reshape((5, 2)), range(5)
'''
X array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
'''
list(y)
#[0, 1, 2, 3, 4]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
'''
X_train:array([[4, 5],
[0, 1],
[6, 7]])
y_train:[2, 0, 3]
X_test :array([[2, 3],
[8, 9]])
y_test:[1, 4]
'''
分层抽样:根据给定的比例获取DataFrame的分层抽样。
sampleBy(col, fractions, seed=None)
参数:
col ——— 按该列进行分层
fractions ——– 抽样比例
seed ——– 抽样种子
注:当抽样比例为0.8时,抽到的样本数在80%左右;当抽样比例为1.0时,抽到的样本数是全量。
from pyspark.sql.functions import lit
list = [(2147481832,23355149,1),(2147481832,973010692,1),(2147481832,2134870842,1),(2147481832,541023347,1),(2147481832,1682206630,1),(2147481832,1138211459,1),(2147481832,852202566,1),(2147481832,201375938,1),(2147481832,486538879,1),(2147481832,919187908,1),(214748183,919187908,1),(214748183,91187908,1)]
df = spark.createDataFrame(list, ["x1","x2","x3"])
df.show()
# +----------+----------+---+
# | x1| x2| x3|
# +----------+----------+---+
# |2147481832| 23355149| 1|
# |2147481832| 973010692| 1|
# |2147481832|2134870842| 1|
# |2147481832| 541023347| 1|
# |2147481832|1682206630| 1|
# |2147481832|1138211459| 1|
# |2147481832| 852202566| 1|
# |2147481832| 201375938| 1|
# |2147481832| 486538879| 1|
# |2147481832| 919187908| 1|
# | 214748183| 919187908| 1|
# | 214748183| 91187908| 1|
# +----------+----------+---+
df.groupBy("x1").count().show()
# +----------+-----+
# | x1|count|
# +----------+-----+
# |2147481832| 10|
# | 214748183| 2|
# +----------+-----+
seed = 12
fractions = df.select("x1").distinct().withColumn("fraction", lit(0.8)).rdd.collectAsMap()
print(fractions)
# {2147481832: 0.8, 214748183: 0.8}
sampled_df = df.stat.sampleBy("x1", fractions, seed)
sampled_df.show()
# +----------+---------+---+
# | x1| x2| x3|
# +----------+---------+---+
# |2147481832| 23355149| 1|
# |2147481832|973010692| 1|
# |2147481832|541023347| 1|
# |2147481832|852202566| 1|
# |2147481832|201375938| 1|
# |2147481832|486538879| 1|
# |2147481832|919187908| 1|
# | 214748183|919187908| 1|
# | 214748183| 91187908| 1|
# +----------+---------+---+
sampled_df.groupBy("x1").count().show()
# +----------+-----+
# | x1|count|
# +----------+-----+
# |2147481832| 7|
# | 214748183| 2|
# +----------+-----+
sampleByKey:
df = sc.parallelize([ (1,1234,282),(1,1234,282),(1,1234,282),(1,1234,282),(1,1396,179),(2,8620,178),(3,1620,191),(3,8820,828) ] ).toDF(["ID","X","Y"])
df.show()
+---+----+---+
| ID| X| Y|
+---+----+---+
| 1|1234|282|
| 1|1396|179|
| 2|8620|178|
| 3|1620|191|
| 3|8820|828|
+---+----+---+
fractions = df.rdd.map(lambda x: (x[0],x[1])).distinct().map(lambda x: (x,0.3)).collectAsMap()
kb = df.rdd.keyBy(lambda x: (x[0],x[1]))
sampleddf = kb.sampleByKey(False,fractions).map(lambda x: x[1]).toDF(df.columns)
sampleddf.show()
+---+----+---+
| ID| X| Y|
+---+----+---+
| 1|1234|282|
| 1|1396|179|
| 3|1620|191|
+---+----+---+
kb.sampleByKey(False,fractions).map(lambda x: x[1]).toDF(df.columns).show()
+---+----+---+
| ID| X| Y|
+---+----+---+
| 2|8620|178|
+---+----+---+
kb.sampleByKey(False,fractions).map(lambda x: x[1]).toDF(df.columns).show()
+---+----+---+
| ID| X| Y|
+---+----+---+
| 1|1234|282+
K近邻
1、在K-NN最近邻算法中,一般采用哪种方法来计算类别特征的距离? D
A.欧式距离(Euclidean distance)
B.曼哈顿距离(Manhattan distance)
C.明可夫斯基距离(Minkowski distance)
D.汉明 g距离(Hamming distance)
分析:欧式距离和曼哈顿距离可以一起来看,二者的性质是一样的。
2、在K-NN最近邻算法中,如果为了减少噪声样本的影响,应该如何调整k值? A
A. 增大k
B. 减少k
C. 与k无关
分析:k太小会导致过拟合,很容易将一些噪声学习到模型中,而忽略了数据真实的分布。
**3、在K-NN最近邻算法中, k值增大,会导致模型的偏差(bias)和方差(variance)有什么变化? **
A. 偏差增大,方差增大
B. 偏差增大,方差减小
C. 偏差减小,方差增大
D. 偏差减小,方差减小
分析:KNN中的k值,表示所取近邻样本的个数。首先我们看两个极端,当k值取1时,为最近邻算法,新样本S的预测分类,取决于与它相似度最高的那一个样本所属的类别;当k取N时(N为样本数量),新样本的预测分类,取决于样本数据中哪一个类别的样本数量最多,已经跟样本记录间的相似度没有关系了。
当k取1时,根据最相似的一个样本判断分类,很有可能预测准确,为低bias,但是不同数据集中,与新样本S相似度最高的那个样本可能属于不同分类,那么预测结果则各不相同,为高variance。
当k取N时,完全根据样本数据的分布进行预测,不管新样本什么样,全部都会预测成样本数据中样本数量最多的那个类别。例如,有100个样本,60个属于A类,30个属于B累,10个属于C类,那么所有的新样本都会被预测为A类。此时为高bias,高variance。
当k值在1到N之间变化时,一定存在一个最优的k值,使得bias和variance最低,当大于或小于这个最优k值时,都会造成bias和variance变大。
聚类
1、影响聚类算法结果的主要因素有(B、C、D )。
A.已知类别的样本质量;
B.分类准则;
C.特征选取;
D.模式相似性测度
分析:聚类不需要类别标签。
2、影响基本K-均值算法的主要因素有(ABD)。
A.样本输入顺序;
B.模式相似性测度;
C.聚类准则;
D.初始类中心的选取
3、kmeans的复杂度
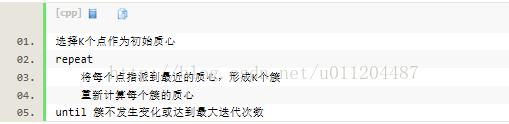
时间复杂度:O(tKmn),其中,t为迭代次数,K为簇的数目,m为记录数,n为维数。
空间复杂度:O((m+K)n),其中,K为簇的数目,m为记录数,n为维数。
深度学习
输入图片大小为200×200,依次经过一层卷积(kernel size 5×5,padding 1,stride 2),pooling(kernel size 3×3,padding 0,stride 1),又一层卷积(kernel size 3×3,padding 1,stride 1)之后,输出特征图大小为: C
A、95
B、96
C、97
D、98
E、99
F、100
分析:计算尺寸不被整除只在GoogLeNet中遇到过。卷积向下取整,池化向上取整。
本题 (200-5+21)/2+1 为99.5,取99
(99-3)/1+1 为97
(97-3+21)/1+1 为97
研究过网络的话看到stride为1的时候,当kernel为3 padding为1或者kernel为5 padding为2,一看就是卷积前后尺寸不变。
tf.keras 和 keras有什么区别?
keras是François Chollet于2014-2015年开始编写的开源高层深度学习API,所谓“高层”,是相对于“底层”运算而言(例如add,matmul,transpose,conv2d)。keras把这些底层运算封装成一些常用的神经网络模块类型(例如Dense,Conv2D,LSTM等),再加上像Model、Optimizer等的一些的抽象,来增强API的易用性和代码的可读性,提高深度学习开发者编写模型的效率。keras本身并不具备底层运算的能力,所以它需要和一个具备这种底层运算能力的backend(后端)协同工作。
keras最初发行的时候,tensorflow还没有开源(fchollet开始写keras的时候还未加入Google)。那时的keras主要使用的是Theano后端。2015年底TensorFlow开源后,keras才开始搭建TensorFlow后端。今天TensorFlow是keras最常用的后端。
keras的代码被逐渐吸收进入tensorflow的代码库,那时fchollet也加入了Google Brain组。所以就产生了tf.keras:一个不强调后端可互换性、和tensorflow更紧密整合、得到tensorflow其他组建更好支持、且符合keras标准的高层次API。
keras和tf.keras的主要共同点:
- 基于同一个API:如果不使用tf.keras的特有特性的话,模型搭建、训练、和推断的代码应该是可以互换的。把import keras 换成from tensorflow import keras,所有功能都应该可以工作。反之则未必,因为tf.keras有一些keras不支持的特性。
- 相同的JSON和HDF5模型序列化格式和语义。从一方用model.to_json()或model.save()保存的模型,可以在另一方加载并以同一语义运行。TensorFlow的生态里面那些支持HDF5或JSON格式的其他库,比如TensorFlow.js,也同等支持keras和tf.keras保存的模型。
其他深度学习模型tf keras Theano PyTorch caffe
为什么CNN中的卷积核大小一般是奇数?
1x1的卷积核有什么用呢?
NN的卷积核和n1的卷积核?
分类
以下哪些方法不可以直接来对文本分类?A
A、Kmeans
B、决策树
C、支持向量机
D、KNN
分析:分类不同于聚类。A:Kmeans是聚类方法,典型的无监督学习方法。分类是监督学习方法,BCD都是常见的分类方法。
常见的生成式模型和判别式模型有哪些?
生成式模型:HMM、朴素贝叶斯
判别式模型:svm、最大熵模型、决策树、神经网络、条件随机场。
常见的分类算法有哪些?
SVM、神经网络、随机森林、逻辑回归、KNN、贝叶斯
常见的监督学习算法有哪些?
感知机、svm、人工神经网络、决策树、逻辑回归
距离、相似度
模式识别中,马式距离较之于欧式距离的优点是(C、D)。
A.平移不变性;
B.旋转不变性;
C.尺度不变性;
D.考虑了模式的分布
分析:
尺度不变性:在进行特征描述的时候,将尺度统一就可以实现尺度不变性了。例如量纲、图像的缩放。
平移不变性:在卷积神经网络里,卷积+最大池化约等于平移不变性。当将图片平移时,对图片的识别不受影响。
https://www.cnblogs.com/Terrypython/p/11147490.html
欧式距离具有(A B);马式距离具有(A B C D)。
A. 平移不变性;
B. 旋转不变性;
C. 尺度缩放不变性;
D. 不受量纲影响的特性
指标性能评价
下面有关分类算法的准确率,召回率,F1值的描述,错误的是? C
A.准确率是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率
B.召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率
C. 正确率、召回率和F值取值都在0和1之间,数值越接近0,查准率或查全率就越高
D. 为了解决准确率和召回率冲突问题,引入了F1分数
分析:数值越接近于1越好。
HMM
HMM中,如果已知观察序列和产生观察序列的状态序列,那么可用以下哪种方法直接进行参数估计() D
EM算法
维特比算法
前向后向算法
极大似然估计
分析:
EM算法: 只有观测序列,无状态序列时来学习模型参数,即Baum-Welch算法
维特比算法: 用动态规划解决HMM的预测问题,不是参数估计。
前向后向:用来算概率。
极大似然估计:即观测序列和相应的状态序列都存在时的监督学习算法,用来估计参数。
数学
怎么理解最大似然函数
PCA的原理