import numpy as np
import pandas as pd
from pandas import Series, DataFrame
内容:
·Series数组
·DataFrame数组
【构建一个多层级索引】
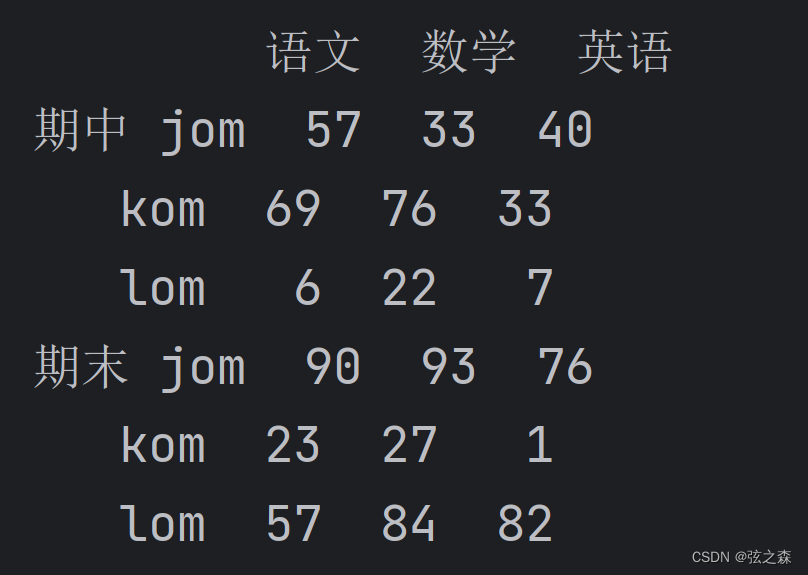
# 构造一个多维索引
index = pd.MultiIndex.from_product([["期中", "期末"], ["jom", "kom", "lom"]])
columns = ["语文", "数学", "英语"]
data = np.random.randint(0, 100, size=(6, 3))
df_things = DataFrame(data=data, index=index, columns=columns)
print(df_things)
print()
运行结果:
【Series数组】
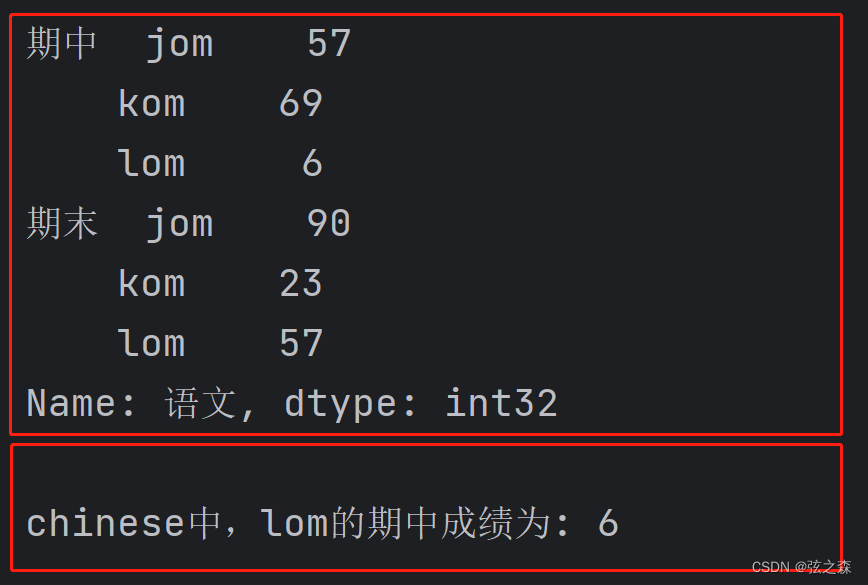
单曲去除df_things数组中的“语文”列,就可以得到一个Series数组。
在对Series数组进行多层级索引操作时,和一维索引操作的不同之处在loc的传入参数。
当传入参数是元组时,元组中元素的等级依次减小,每一个元素,代表着该层级的索引位置。
"""Series数组操作"""
# 得到一个Series数组:
chinese = df_things["语文"]
print(chinese)
print()
# 用元组来表达索引逻辑,元组中元素的等级依次减小,得到lom的期中成绩:
return_number = chinese.loc[("期中", "lom")]
print("chinese中,lom的期中成绩为:", return_number)
# 总结,在进行索引操作时,只有loc的传入参数发生了变化,其余都没发生改变
print()
运行结果:
【DataFrame数组】
想要得到多个值时,只需要将loc的第一个传入参数设置为列表(由目标索引组成的元组)即可,可以显式索引,也可以隐式索引。
"""DataFrame数组"""
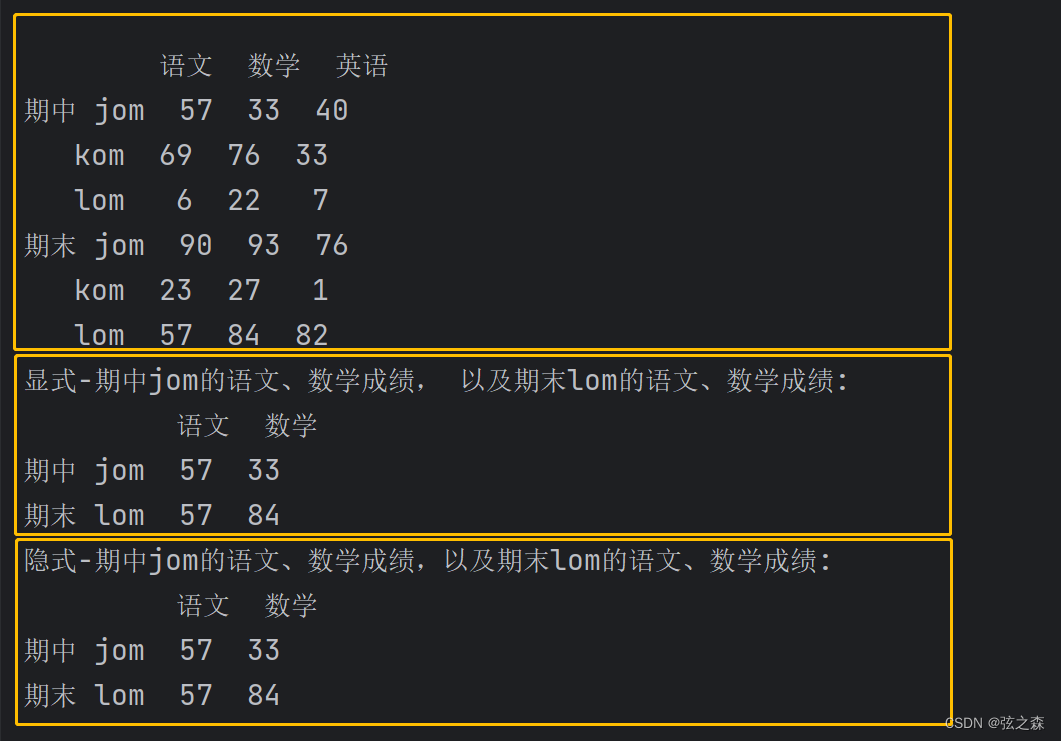
# 得到期中jom的语文、数学成绩,以及期末lom的语文、数学成绩
print(df_things)
index_1 = ("期中", "jom")
index_2 = ("期末", "lom")
columns = ["语文", "数学"]
things_1 = df_things.loc[[index_1, index_2], columns]
things_2 = df_things.iloc[[0, 5], [0, 1]]
print("显式-期中jom的语文、数学成绩, 以及期末lom的语文、数学成绩:\n", things_1)
# 隐式索引不受到多层级索引的影响,隐式索引永远是单层级
print("隐式-期中jom的语文、数学成绩,以及期末lom的语文、数学成绩:\n", things_2)
print()
运行结果: