图的深度优先搜索算法(dfs)
图的深度优先搜索算法是以一个顶点为起始点开始挖掘,一个分支挖掘完,再继续挖掘下一个分支,在实现上需要用到栈,因此,图的深度优先搜索算法有很多条路径,取决于哪个顶点最先入栈。
实现思路(非递归):
dfs可以用栈来进行实现。首先需要确定哪个顶点最先入栈并对其进行标记,之后开始寻找它的邻接点。让它所有的邻接点依次入栈后,由于栈只能从栈顶取元素,因此它也就实现了以一条路线开始进行深度挖掘直到这条路径被挖掘完,才会从起始顶点的下一个邻接点开始进行下一次挖掘。
下面用一个图作为例子来描述整个过程

如图,如果A先入栈,那么A首先会被标记,并且在A的邻接点C,D,F入栈之前A会出栈 ,同时C,D,F也会被标记。按照入栈 的顺序,栈顶元素应该是F,所以F出栈,并开始寻找F的邻接点。经过搜索,F的邻接点有A和G两个,但由于A已经被标记过了,所以F的下一个邻接点为G,F出栈,G入栈。经过搜索,G的邻接点有F和E两个,但由于F已经被标记过了,所以G的邻接点只有E,将E标记后出栈。至此,AFGE这条路径已经被走过,并且A,F,G,E已经全被标记,栈中目前还有C和D,接下来寻找D的邻接点,由于D的邻接点A,C已经被标记过了,因此AD这条路径也走完了。栈中还有C,接下来寻找C的邻接点,C的邻接点A已经被标记过了,因此只有B可以入栈,B后面也无处可走了,至此,ACB路线也已经被走完,此时栈为空,dfs结束。
代码如下:
//该图的邻接矩阵
int matrix[7][7] = {
//A B C D E F G
/*A*/ {0,0,1,1,0,1,0},
/*B*/ {0,0,1,0,0,0,0},
/*C*/ {1,1,0,1,0,0,0},
/*D*/ {1,0,1,0,0,0,0},
/*E*/ {0,0,0,0,0,0,1},
/*F*/ {1,0,0,0,0,0,1},
/*G*/ {0,0,0,0,1,1,0}
};
bool vis[7];//标记数组
void dfs()
{
stack<int> s;
s.push(0);//相当于把A放入栈
vis[0] = 1;//把A标记
while (!s.empty())
{
int tmp = s.top();
s.pop();
cout << char(tmp + 'A');
for (int i = 0; i < 7; i++)
{
if (matrix[tmp][i] == 1 && vis[i] != 1)
{
s.push(i);
vis[i] = 1;
}
}
}
}
实现思路(递归):
与栈本质相同,都是先进后出的思想。如果想获取挖掘深度,在递归时多添加一个变量depth即可。
代码如下:
#include <iostream>
#include <string>
using namespace std;
//该图的邻接矩阵
int matrix[7][7] = {
//A B C D E F G
/*A*/ {0,0,1,1,0,1,0},
/*B*/ {0,0,1,0,0,0,0},
/*C*/ {1,1,0,1,0,0,0},
/*D*/ {1,0,1,0,0,0,0},
/*E*/ {0,0,0,0,0,0,1},
/*F*/ {1,0,0,0,0,0,1},
/*G*/ {0,0,0,0,1,1,0}
};
bool vis[7];//标记数组
int maxx = 0;
int final_depth = 0;
void dfs(int index,int depth)
{
vis[index] = 1;
cout << char(index + 'A');
final_depth=max(maxx, depth);
for (int i = 0; i < 7; i++)
{
if (matrix[index][i] == 1 && vis[i] != 1)
{
dfs(i,depth+1);
}
}
}
int main()
{
dfs(0,1);
cout << final_depth;
return 0;
}
综上,图的深度优先搜索算法有三个要点:一是采用先进后出的思想,可以采用栈或递归;二是采用标记数组-目的是防止被重复搜索;三是要能够列出图的邻接矩阵。
图的广度优先搜索算法(bfs)
实现思路:
图的广度优先搜索注重以层的形式来进行搜索,在实现的时候可以用队列进行实现。由于队列先进先出的特点,保证了在队列中下一层的顶点一定排在上一层顶点的后面,而且只能从队头出队,从队尾入队。
下面用一个图来展示图的广度优先搜索
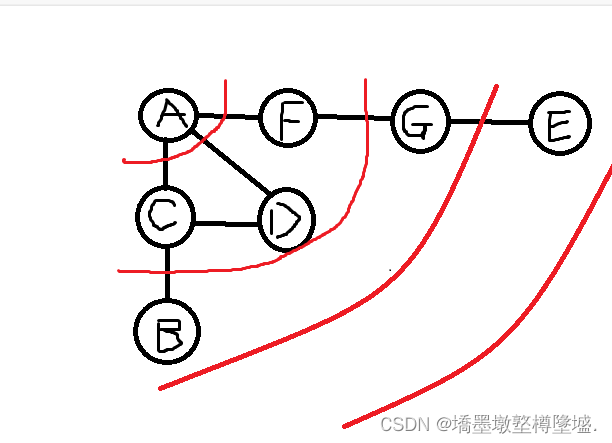
如图所示,先将A入队并将其标记,然后开始寻找A的邻接点CDF,将三者也入队并进行标记。tmp作为临时值先记录下队头C,从C开始找它的邻接点B,将B入队并进行标记,然后将C出队后开始找D的邻接点。D没有未被标记过的邻接点,因此D出队,开始寻找F的邻接点。F未被标记过的邻接点只有G,因此G入队,并被标记,F出队。至此,队列中只有B和G,再找B的未被标记过的邻接点,没有找到,则B出队,G的未被标记过的邻接点只有F,则F入队并被标记,G出队。最后寻找F的邻接点,F没有未被标记过的邻接点,则直接出队,至此,队列为空,bfs结束。
代码如下:
int matrix[7][7] = {
//A B C D E F G
/*A*/ {0,0,1,1,0,1,0},
/*B*/ {0,0,1,0,0,0,0},
/*C*/ {1,1,0,1,0,0,0},
/*D*/ {1,0,1,0,0,0,0},
/*E*/ {0,0,0,0,0,0,1},
/*F*/ {1,0,0,0,0,0,1},
/*G*/ {0,0,0,0,1,1,0}
};
bool vis[7];//标记数组
void bfs()
{
queue<int> q;
q.push(0);
vis[0] = 1;
while(!q.empty())
{
int tmp = q.front();
q.pop();
cout << char(tmp + 'A');
for (int i = 0; i < 7; i++)
{
if (matrix[tmp][i] == 1 && vis[i] != 1)
{
q.push(i);
vis[i] = 1;
}
}
}
}
为了获取广度优先搜索深度,可以传结构体,代码如下:
//该图的邻接矩阵
int matrix[7][7] = {
//A B C D E F G
/*A*/ {0,0,1,1,0,1,0},
/*B*/ {0,0,1,0,0,0,0},
/*C*/ {1,1,0,1,0,0,0},
/*D*/ {1,0,1,0,0,0,0},
/*E*/ {0,0,0,0,0,0,1},
/*F*/ {1,0,0,0,0,0,1},
/*G*/ {0,0,0,0,1,1,0}
};
bool vis[7];//标记数组
struct node
{
int index;
int depth;
};
int maxx = 0;
int final_depth = 0;
void bfs()
{
queue<node> q;
q.push(node{0,1});
vis[0] = 1;
while(!q.empty())
{
node tmp = q.front();
q.pop();
cout << char(tmp.index + 'A');
final_depth = max(maxx, tmp.depth);
for (int i = 0; i < 7; i++)
{
if (matrix[tmp.index][i] == 1 && vis[i] != 1)
{
q.push(node{i,tmp.depth+1});
vis[i] = 1;
}
}
}
}
综上,图的广度优先搜索算法有三个要点:一是采用先进先出的思想,可以采用队列;二是采用标记数组-目的是防止被重复搜索;三是要能够列出图的邻接矩阵。