
代码来源:https://github.com/bubbliiiing/segformer-pytorch
网络特点:
- 结合了Transformers与轻量级的多层感知机(MLP)解码器。
- 包含一个新颖的分层结构的Transformer编码器,该编码器输出多尺度特征。它不需要位置编码,因此避免了位置编码的插值,这在测试分辨率与训练时不同的情况下可能会导致性能下降。
- 避免使用复杂的解码器。提议的MLP解码器从不同的层中聚合信息,从而同时结合了局部注意力和全局注意力来呈现强大的表示。
- 设计非常简单和轻量级,这是在Transformers上实现高效分割的关键。
- SegFormer系列模型从SegFormer-B0到SegFormer-B5有多个版本,与之前的模型相比,它们的性能和效率都有显著的提高。
SegFormer.py码解析:
nets/segformer.py 文件中定义了与 SegFormer 相关的几个类:
-
MLP:一个简单的多层感知机,将输入特征转化为所需的嵌入维度。
-
ConvModule:一个卷积模块,包括卷积层、批量归一化和激活函数。
-
SegFormerHead:定义了 SegFormer 的解码头。它接受从 backbone 提取的特征,并通过 MLP 将它们转化为所需的嵌入维度。然后,这些特征被上采样并融合,最后通过一个卷积层生成最终的语义分割结果。
-
SegFormer:这是主要的 SegFormer 模型类。它首先选择一个预训练的 backbone(这里提到了多个版本,如 b0、b1 等),然后使用
SegFormerHead 进行解码。
从上述代码中,我们可以看到 SegFormer 的基本数据流:
- 输入图像首先通过选择的 backbone(例如 mit_b0、mit_b1 等)进行特征提取。
- 这些特征(通常是多尺度的)被传递给
SegFormerHead。
- 在
SegFormerHead 中,特征首先通过 MLP 被转化为所需的嵌入维度。
- 这些嵌入特征然后被上采样并融合。
- 最后,融合的特征通过一个卷积层得到最终的语义分割结果。
数据流及尺寸变化:输入为512x512x3的图片(使用b0主干网络)
Encoder
mit(backbone)
为了更好地理解输入图像在网络中的数据流和其尺寸如何变化,我们首先需要查看 backbone.py 文件中的内容,特别是与 mit_b0(B0 主干)相关的部分。这将帮助我们了解 backbone 的结构和每一层的输出尺寸。
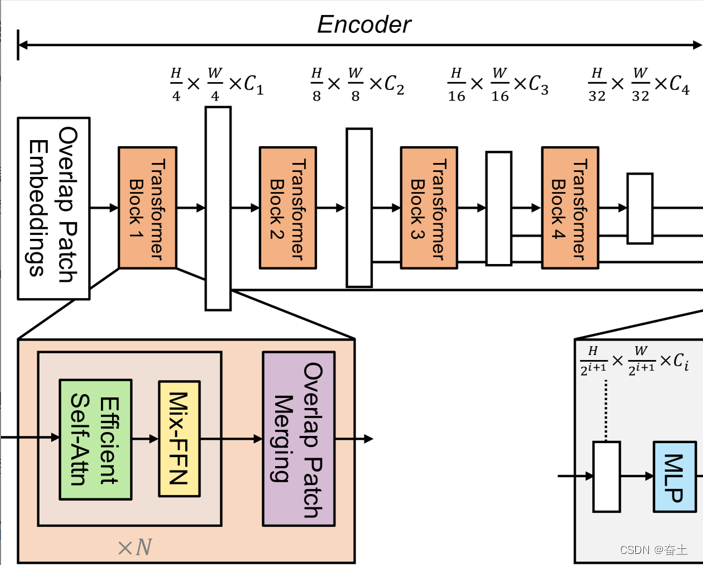
OverlapPatchEmbed 这是一个通过2D卷积操作将图像分块并将其嵌入到指定的维度的模块。例如,如果输入图像尺寸为512x512x3,并且指定了卷积核大小为7、步长为4和嵌入维度为768,则该模块将输出的特征图的维度变为较小,但通道数增加。
从 backbone.py 文件中提取的代码片段中,我们可以看到 mit_b0 是 MixVisionTransformer 的一个子类。从 MixVisionTransformer 的代码中,我们可以看到以下关于 mit_b0 主干的关键信息:
- 使用了
OverlapPatchEmbed 进行图像嵌入,这将使图像分块,并通过2D卷积操作将其嵌入到指定的维度。
- 接下来,输入经过一系列的 Transformer 模块进行特征提取。具体地,
mit_b0 有4个部分,每部分由多个 Transformer 块组成。每个 Transformer 块都会保持其输入特征的尺寸不变。
这是 mit_b0 类的定义,它是 MixVisionTransformer 的子类。我们可以从这个定义中提取以下关键参数和信息:
class mit_b0(MixVisionTransformer):
def __init__(self, pretrained = False):
super(mit_b0, self).__init__(
embed_dims=[32, 64, 160, 256], num_heads=[1, 2, 5, 8], mlp_ratios=[4, 4, 4, 4],
qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1],
drop_rate=0.0, drop_path_rate=0.1)
if pretrained:
print("Load backbone weights")
self.load_state_dict(torch.load("model_data/segformer_b0_backbone_weights.pth"), strict=False)
-
嵌入维度 (
embed_dims):在网络的不同阶段,特征图的通道数(或嵌入维度)是 [32, 64, 160, 256]。这表示在第一阶段输出的特征图通道数为32,第二阶段为64,第三阶段为160,第四阶段为256。
-
头数 (
num_heads):这是 Transformer 注意力机制中的多头注意力的头数。在不同的阶段,头数分别是 [1, 2, 5, 8]。
-
MLP比率 (
mlp_ratios):这决定了 MLP 中隐藏层的大小。在所有阶段,比率都是4。
-
QKV偏差 (
qkv_bias):设置为 True,这意味着 Transformer 中的 QKV 矩阵都有偏差项。
-
规范化层 (
norm_layer):使用 LayerNorm,并设置 epsilon 为 1e-6。
-
深度 (
depths):表示在每个阶段中有多少个 Transformer 块。在这种情况下,每个阶段都有2个 Transformer 块。
-
SR比率 (
sr_ratios):这些是空间缩减的比率,它们决定了在各个阶段如何减少特征图的尺寸。
-
Dropout比率 (
drop_rate 和 drop_path_rate):这些是常规 dropout 和路径 dropout 的比率。
最后,如果在train.py中将 pretrained 设置为 True,那么会从指定的路径加载预训练的 mit_b0 主干的权重。
现在,让我们结合这个定义和之前的分析来详细描述 mit_b0 的数据流和每一步的尺寸变化。
Stage
-
输入:输入图像的尺寸为
512
×
512
×
3
512 \times 512 \times 3
512×512×3
-
PatchEmbed:输入图像首先通过 PatchEmbed 层。这一步的具体操作是将图像分块,并通过2D卷积操作将其嵌入到指定的维度。经过 PatchEmbed 之后的输出尺寸是
128
×
128
×
32
128 \times 128 \times 32
128×128×32。
-
Stage1:
-
Transformer 块:包含2个 Transformer 块(由
depths 参数给出),每个块都包括注意力机制和 MLP。
-
输出尺寸:由于每个 Transformer 块都不会改变其输入特征的尺寸,因此第一阶段的输出尺寸仍然是
128
×
128
×
32
128 \times 128 \times 32
128×128×32。
-
Stage2:
-
Transformer 块:同样包含2个 Transformer 块。
-
输出尺寸:考虑到
embed_dims 参数,这一阶段的输出尺寸应为
64
×
64
×
64
64 \times 64 \times 64
64×64×64(这里假设特征图的尺寸减半)。
-
Stage3:
-
Transformer 块:同样包含2个 Transformer 块。
-
输出尺寸:考虑到
embed_dims 参数,这一阶段的输出尺寸应为
32
×
32
×
160
32 \times 32 \times 160
32×32×160(这里假设特征图的尺寸再次减半)。
-
Stage4:
-
Transformer 块:同样包含2个 Transformer 块。
-
输出尺寸:考虑到
embed_dims 参数,这一阶段的输出尺寸应为
16
×
16
×
256
16 \times 16 \times 256
16×16×256(这里假设特征图的尺寸再次减半)。
Transformer Block
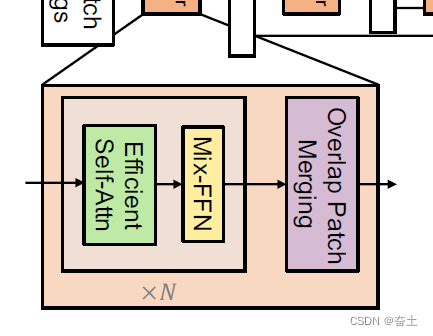
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=GELU, norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio
)
self.norm2 = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x), H, W))
return x
一个 Block 包含了一个注意力模块 (Attention) 和一个多层感知机 (Mlp)。
-
规范化层 (norm_layer):每个 Block 在输入注意力模块和 MLP 之前都有一个规范化层。这是一种预处理步骤,用于标准化输入数据,使其具有零均值和单位方差。
-
注意力模块 (Attention):输入数据经过注意力模块进行处理。这个模块包含一个或多个自注意力头,这些头可以分别学习输入的不同方面。这个模块的输出与原始输入相加,形成一个残差连接。
-
多层感知机 (Mlp):这是一个简单的全连接网络,由一个或多个线性层和一个非线性激活函数组成。这个模块的输出也与原始输入相加,形成一个残差连接。
-
DropPath:这是一种特殊的 Dropout 技术,用于正则化网络并防止过拟合。它在训练过程中随机丢弃某些路径,而不是丢弃单个节点。
结合这个定义和之前的分析,详细解释 Block 的数据流和每一步的输入输出尺寸变化:
-
输入:输入 x 的尺寸为 ((N, C, H, W)),其中 N 是批量大小,C 是通道数,H 和 W 分别是输入特征图的高度和宽度。输入还包括 H 和 W 本身,这可能与空间缩减 (sr_ratio) 有关,但这需要查看 Attention 模块的实现来进一步确定。
-
规范化层:输入 x 首先经过规范化层 norm1,这不会改变输入的尺寸,所以输出尺寸仍然是 ((N, C, H, W))。
-
注意力模块:经过规范化的输入接下来进入注意力模块。注意力模块的具体工作方式需要查看 Attention 类的实现来确定,但在大多数情况下,它不会改变特征的尺寸。因此,我们可以假设注意力模块的输出尺寸仍然是 ((N, C, H, W))。
-
残差连接:注意力模块的输出与原始输入相加,形成一个残差连接。这也不会改变特征的尺寸,所以此步骤后的输出尺寸仍然是 ((N, C, H, W))。
-
第二个规范化层和 MLP:注意力模块的输出经过第二个规范化层和 MLP。与前面的规范化层和注意力模块类似,这些操作也不会改变特征的尺寸,所以 MLP 的输出尺寸仍然是 ((N, C, H, W))。
-
第二个残差连接:MLP 的输出与其输入相加,形成第二个残差连接。这也不会改变特征的尺寸,所以此步骤后的输出尺寸仍然是 ((N, C, H, W))。
所以,对于 Block 类,我们可以得出以下结论:无论输入特征的尺寸是什么,输出特征的尺寸都将是相同的。这是因为所有的操作,包括注意力模块、MLP 和残差连接,都保持特征的尺寸不变。希望这能帮助您更好地理解 Block 的结构和工作原理!
解码头 (Head):
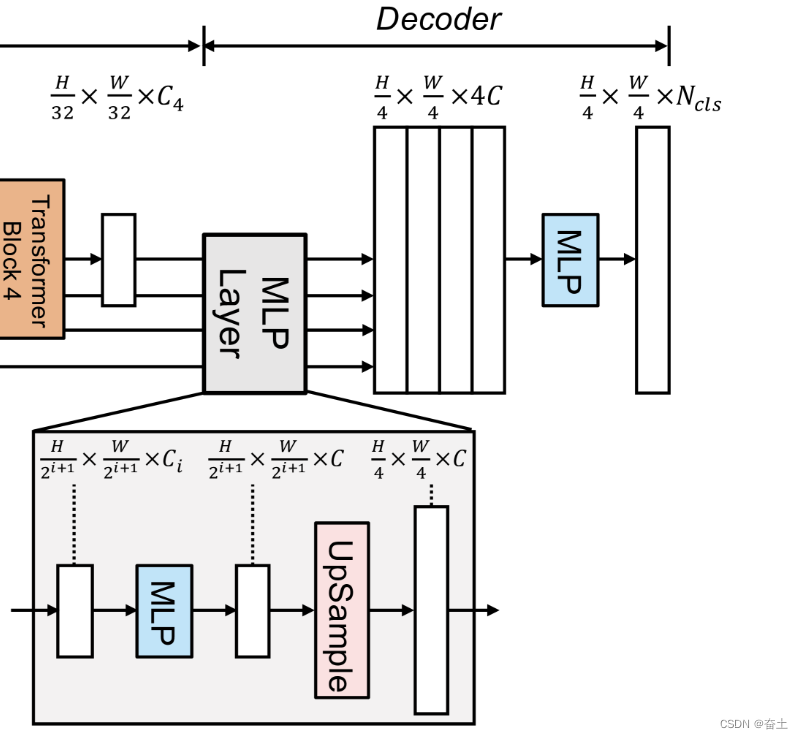
-
MLP解码器:首先,每个特征图
c
1
,
c
2
,
c
3
,
c
4
c1, c2, c3, c4
c1,c2,c3,c4(这些特征来自 mit_b0 主干)都通过一个 MLP 层进行处理,将其转化为指定的嵌入维度(embedding_dim)。
-
上采样:经过 MLP 的特征图
c
4
,
c
3
,
c
2
c4, _c3, _c2
c4,c3,c2 都被上采样到与
c
1
c1
c1相同的尺寸。
-
特征融合:接下来,所有的特征图都被串联在一起,并通过一个卷积模块 (linear_fuse) 进行融合。
-
预测:最后,融合的特征图经过一个卷积层生成最终的语义分割结果。
为了明确每一步的输出尺寸,我们可以总结如下:
-
输入尺寸:
-
c
1
c1
c1:
128
×
128
×
32
128 \times 128 \times 32
128×128×32
-
c
2
c2
c2:尺寸较小,但经过上采样后为
128
×
128
×
64
128 \times 128 \times 64
128×128×64
-
c
3
c3
c3:尺寸更小,但经过上采样后为
128
×
128
×
160
128 \times 128 \times 160
128×128×160
-
c
4
c4
c4:尺寸最小,但经过上采样后为
128
×
128
×
256
128 \times 128 \times 256
128×128×256
-
经过 MLP 和上采样后,所有的特征图都有相同的尺寸
128
×
128
128 \times 128
128×128,但通道数为嵌入维度(embedding_dim)。
-
融合后的特征图尺寸为
128
×
128
×
e
m
b
e
d
d
i
n
g
_
d
i
m
128\times 128\times embedding\_ dim
128×128×embedding_dim。
-
最终的语义分割输出尺寸为
128
×
128
×
n
u
m
_
c
l
a
s
s
e
s
128\times 128\times num\_ classes
128×128×num_classes。