
论文标题:Large Language Models for Generative Information Extraction: A Survey
论文链接:https://arxiv.org/pdf/2312.17617.pdf
论文主要探讨了大型语言模型(LLMs)在生成式信息抽取(IE)任务中的应用,并对这一领域的最新进展进行了全面系统的回顾。
摘要
信息抽取(IE)是自然语言处理(NLP)中的一个重要领域,它将文本转换为结构化知识。随着大型语言模型(如GPT-4和Llama)的出现,它们在文本理解和生成方面展现出了卓越的能力,使得跨领域和任务的泛化成为可能。因此,越来越多的研究开始利用LLMs的生成能力来解决IE任务,而不是从文本中提取结构化信息。这些方法在实际应用中更加实用,因为它们能够有效处理包含数百万实体的模式,而不会显著降低性能。
1. 引言
信息抽取(IE)是将文本转换为结构化知识的过程,对于知识图谱构建、知识推理和问答系统等下游任务至关重要。LLMs的出现极大地推动了NLP的发展,因为它们在文本理解和生成方面的能力非常出色。因此,研究者们对采用LLMs进行生成式IE方法的兴趣日益增长。
2. 生成式IE的初步知识
在这部分,论文介绍了生成式IE的定义和目标,包括命名实体识别(NER)、关系抽取(RE)和事件抽取(EE)等子任务。这些任务被以生成式的方式制定,即使用一个提示(prompt)来增强LLMs对任务的理解,并生成相应的提取序列。
3. IE任务
在这一部分,论文详细介绍了信息抽取(IE)的三个主要子任务:命名实体识别(NER)、关系抽取(RE)和事件抽取(EE),并对每种任务的代表性模型和方法进行了概述。

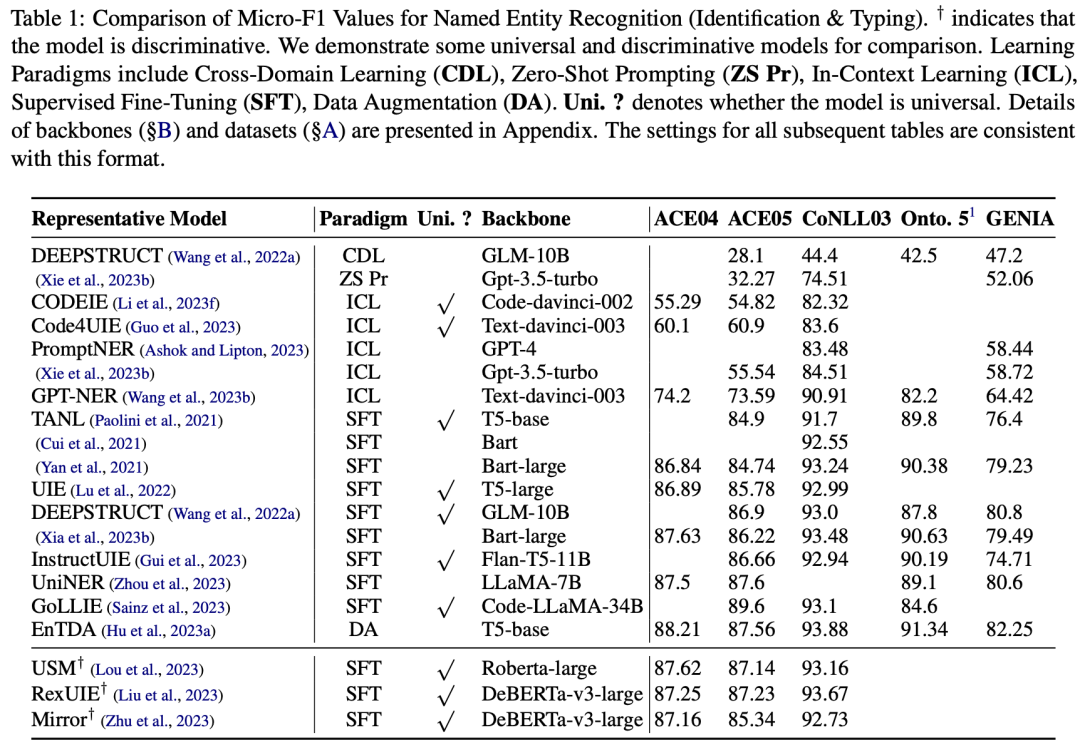
3.1 命名实体识别(NER)
命名实体识别是IE的一个关键组成部分,它涉及识别文本中的实体(如人名、地点、组织等)及其类型。论文讨论了几种不同的NER方法,包括基于规则的方法、统计方法和基于深度学习的方法。特别地,论文提到了使用大型语言模型(LLMs)进行NER的几种策略,例如通过添加额外的提示(prompts)来增强任务的可理解性。
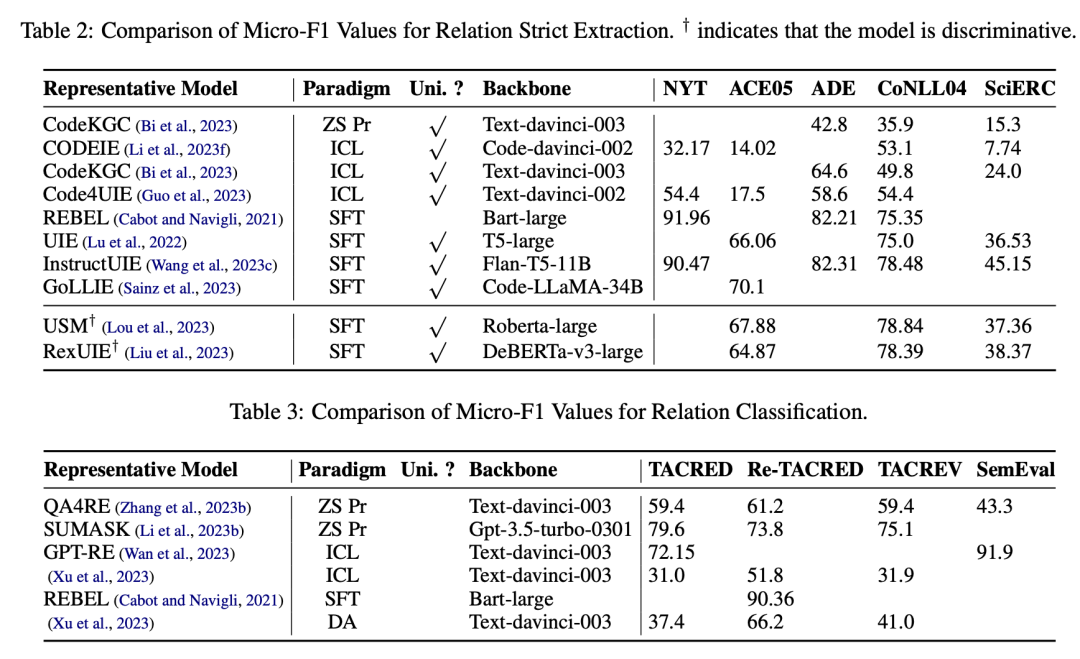
3.2 关系抽取(RE)
关系抽取在IE中也扮演着重要角色,它通常有不同的设置,如关系分类、关系三元组和关系严格。论文分类了RE的不同设置,并介绍了各种方法,包括基于规则的方法、机器学习方法和基于LLMs的方法。这些方法旨在识别和分类实体之间的关系。
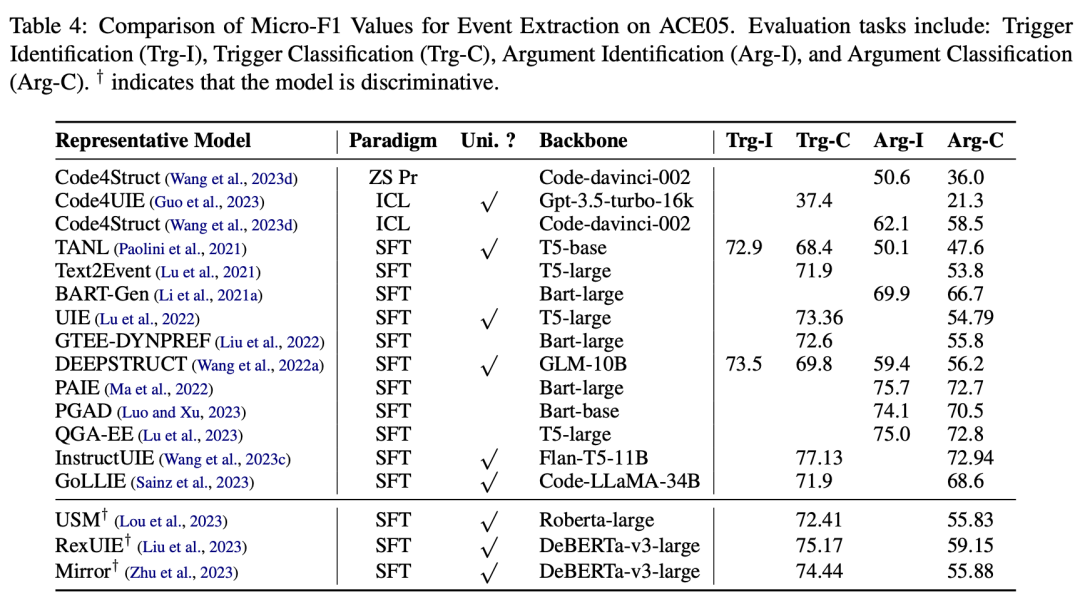
3.3 事件抽取(EE)
事件抽取涉及识别和分类文本中的事件触发词和类型,以及提取与事件相关的论元。论文讨论了事件检测和事件论元提取两个子任务,并介绍了一些基于LLMs的方法,这些方法在事件抽取任务上取得了显著的性能提升。
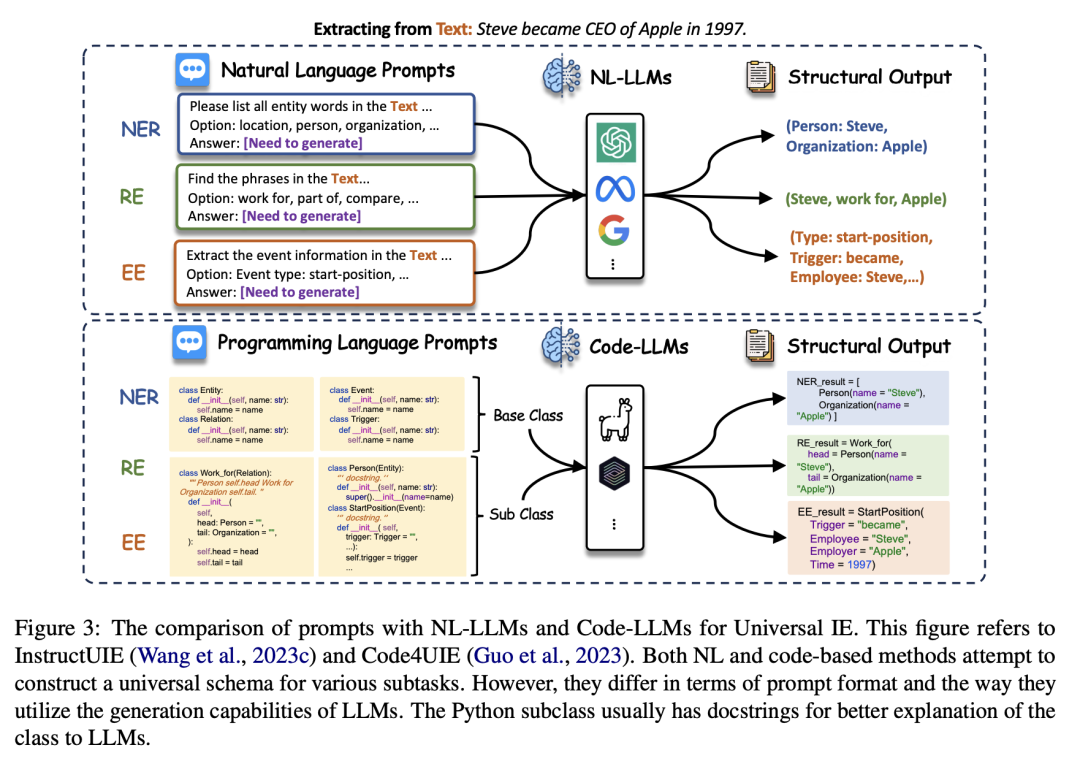
3.4 通用信息抽取(UIE)
论文还探讨了通用信息抽取(UIE)框架,这些框架旨在同时处理多个IE子任务。这些框架通常采用自然语言(NL-LLMs)或代码语言(Code-LLMs)的形式。NL-LLMs通过自然语言提示来统一所有IE任务,而Code-LLMs则利用编程语言的特性来生成代码,以处理结构化预测任务。
4. 学习范式
在这一部分,论文对使用LLMs进行IE的各种学习范式进行了分类,包括有监督微调、少样本学习、零样本学习和数据增强。
4.1 有监督微调(Supervised Fine-tuning)
有监督微调是将预训练的LLMs进一步训练在特定的IE任务上,使用标注数据来提高模型的性能。这种方法允许模型学习到数据中的具体结构模式,并能够更好地泛化到未见过的任务。论文中提到了几种微调策略,例如结构预训练,它通过在一系列任务无关的语料库上预训练模型来增强其结构理解能力。此外,还有目标蒸馏和任务聚焦指令调整,这些方法通过训练学生模型来实现广泛的应用,如命名实体识别(NER)。
4.2 少样本学习(Few-shot Learning)
少样本学习是指在只有少量标注示例的情况下进行模型训练。这种方法面临的挑战包括过拟合和难以捕捉复杂关系。然而,通过增加LLMs的参数规模,它们展现出了惊人的泛化能力,即使在少样本设置中也能取得优异的性能。论文中提到了几种创新方法,如翻译增强自然语言框架(Translation between Augmented Natural Languages framework)、文本到结构生成框架(text-to-structure generation framework)和协作领域前缀调整(Collaborative Domain-Prefix Tuning),这些方法在少样本微调中取得了最先进的性能。
4.3 零样本学习(Zero-shot Learning)
零样本学习是指在没有特定IE任务的训练示例的情况下进行预测。这种方法的主要挑战在于使模型能够有效地泛化到未见过的任务和领域,以及对LLMs的预训练范式进行对齐。由于LLMs嵌入了大量的知识,它们在零样本场景中展现出了惊人的能力。论文中讨论了如何通过引入创新的训练提示(如指令和指南)来实现零样本跨域泛化。此外,还提到了跨类型泛化,即模型能够处理不同类型的任务,例如将事件抽取任务转化为条件生成问题。
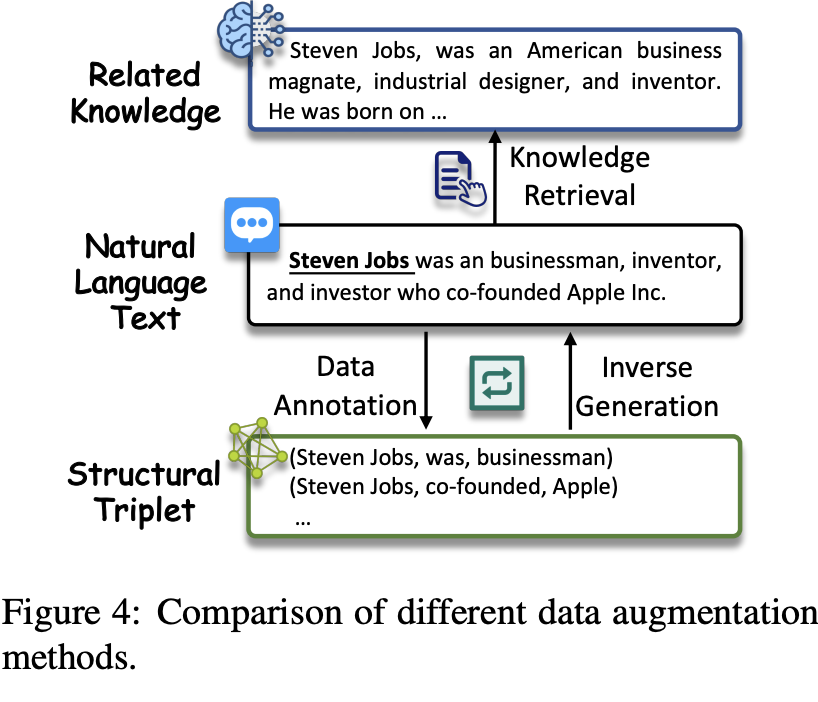
4.4 数据增强(Data Augmentation)
数据增强涉及使用LLMs生成有意义的多样化数据,以增强现有数据。这种方法可以分为三种策略:数据注释、知识检索和逆向生成。数据注释策略直接使用LLMs生成标注数据,知识检索策略从LLMs中检索相关信息,而逆向生成策略则根据结构化数据生成自然文本或问题。这些策略各有优势和局限性,例如数据注释可以直接满足任务要求,但LLMs的结构化生成能力仍需改进;知识检索可以提供关于实体和关系的额外信息,但可能会引入噪声;逆向生成与LLMs的问答范式相一致,但需要结构化数据,并且生成的对之间存在领域差距。
5. 特定领域
论文还探讨了LLMs在特定领域(如多模态、科学、医学等)的应用,并评估了LLMs在IE任务上的性能。
6. 评估与分析
这部分介绍了一些研究,它们探索了LLMs在IE任务上的能力和性能,包括对多个IE子任务的全面分析。
7. 未来方向
最后,论文提出了未来研究的可能方向,包括开发更灵活的通用IE框架、探索在资源有限场景下的IE系统、优化IE的提示设计,以及在开放IE设置中进一步探索LLMs的潜力。
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了NLP面试与大模型技术交流群,
想要进交流群、需要本文源码、提升技术的同学,可以直接加微信号:
mlc2060
。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:
机器学习社区
,后台回复:技术交流
资料
