1、pytorch
OS:ubuntu16.04
gpu: GTX 1080Ti
cuda: 9.0 (系统预装+cudnn)
pytorch官网:https://pytorch.org/
官网给出的安装命令是:conda install pytorch torchvision cudatoolkit=9.0 -c pytorch
(此处有个小说明,由于系统预装了cuda和cudnn,看网上的教程还需要conda安装cudatoolkit和cudnn,一直没搞清楚conda环境安装的这个和系统安装的这个区别,然后我以为要先conda安装cudatoolkit9.0, 然后再配对官网的cudatoolkit9.0的安装命令,但是!!!!!在不小心安装了cudatoolkit8.0后,使用官网对应9.0的安装命令,发现它先把我conda安装的cudatookit8.0卸载了,自动匹配安装了cudatookit9.0。这里告诉我们,同志们,信官方说明吧,别整的有的没的,人家说了 Anaconda is our recommended package manager since it installs all dependencies。当然也就是说 不需要你自己安装cuda和cudnn了!)
但是在安装过程中发现,官网给出的命令安装很慢,甚至断掉!
解决办法在这儿。
添加清华镜像:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
# for legacy win-64
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/peterjc123/
然后将官网命令改成:
conda install pytorch torchvision cudatoolkit=9.0
conda install pytorch torchvision -i https://pypi.tuna.tsinghua.edu.cn/simple # 指定清华源
由于官网给出的命令中 -c pytorch 参数指定了conda获取pytorch的channel为conda自带的pytorch仓库。
因此,只需要将-c pytorch语句去掉,就可以使用清华镜像源快速安装pytorch了。
pytorch安装成功测试
PyTorch下 CUDA 和 CuDNN 安装验证程序
查看gpu版本和cuda的对应关系
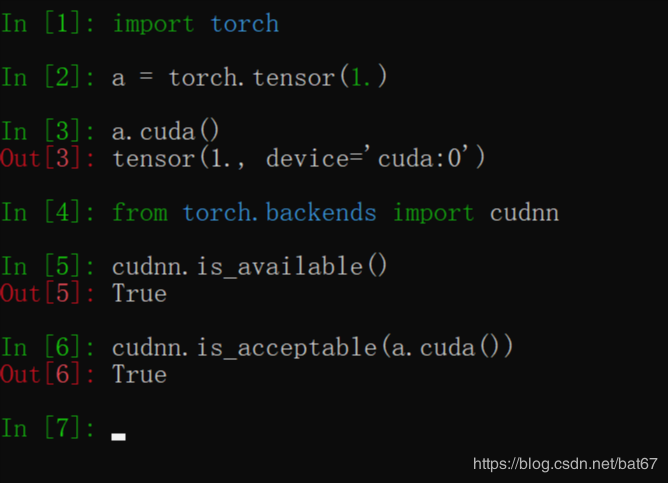
查看pytorch版本
import torch
print(torch.__version__)
# 查看cuda是否可用
print(torch.cuda.is_available())
pytorch指定版本安装/pytorch降级
之前安装的pytorch版本是1.0,但由于某个项目用到了 torchvision.transforms.ColorJitter需要使用pytorch0.3,需要对pytorch进行降级。
conda install pytorch=0.1 -c soumith
另外使用的是torchvision0.1,需要使用torchvision0.2,参考这里。
参考:
[1] conda/pip降级pytorch版本的方法以及安装指定pytorch的方法
[2] pytorch不同版本安装以及版本查看
[3] Pytorch 安装与版本查看
2、caffe
基于Anaconda安装
假如你需要用到python接口,加入你恰好用的是Anaconda,那么恭喜你,因为这个安装同样很简单,感谢万能的conda!
参考博文在这里。
首先你需要创建一个虚拟环境:
conda create -n caffe python=2.7 -c defaults
这里用-c default 表示使用默认的channel安装,据说是为了防止依赖库channel不一致产生问题。(表示试验过不加,确实产生了undefined symbol的不问题,不确定是否是因为之前自己安装了其他依赖项。但是用默认的channel安装,真的!很慢!!可以尝试一下一创建完虚拟环境,不要自己安装任何依赖项,直接安装caffe。)
然后安装caffe
source activate caffe
gpu版:conda install -c defaults caffe-gpu
cpu版:conda install -c defaults caffe
查看caffe是否安装成功
import caffe
print(dir(caffe))
编译python接口
如果你想自己安装caffe,并且编译python接口。。。。
(表示caffe预安装好了,这里说一下编译python接口的一些问题)
首先需要安装一些依赖,requirements.txt文件已经给出,我们用conda安装:
conda install --yes --file requirements.txt
注意用这种方法安装,如果某个依赖安装失败,会导致所有依赖都安装失败。
我们可以采用下面这个方法:
while read requirement; do conda install --yes $requirement; done < requirements.txt
后记:关于Anaconda安装tensorflow、caffe、opencv
参考博文"ananconda 安装tensorflow-gpu caffe-gpu opencv等简单的方法"。
具体可以通过登陆https://anaconda.org/查看安装的相关命令。
另外 pytorch现在自带caffe2了吗?(表示用conda 安装完pytorch发现可以import caffe2了。。。)