前言
author:Liu Zhao
作为刚入坑机器学习的一名小白,写这篇文章的初衷是想作为自己的一个学习笔记,防止知识遗忘,同时也希望能够跟大家一起交流,共同进步
人工神经网络是近几年人工智能、机器学习领域的热门方向,它是根据人脑神经建立的一种模型,在各种工业领域解决了大量的实际问题,具有广泛的应用前景。本文主要介绍如何构建一个较完整的简单神经网络,包括前向传播、反向传播(梯度下降)等内容
一、神经网络能够做什么
神经网络本质上是一种算法,这种算法能够将m个输入x1,x2,x3…xn映射成n个输出y1,y2,y3…yn。类比到人类的大脑,大脑可以接受各种信息,再对各种信息进行处理后输出合适的信息。但神经网络无法使用人类的思维方式,很难立刻输出我们想要的结果。于是,神经网络每输出一个值,我们就把它与期望的值相比较,用一个误差函数来表示它们之间的差值,再通过反向传播一次次修改算法模型,这个过程称为训练。一个完善的神经网络模型需要大量的训练。
就拿神经网络应用中入门的Mnist手写识别数据集来介绍吧
简单来说,Mnist是一个包含数万张手写图片的数据集,类似如下的图片:

我们要做的,是经过对程序进行训练后,输入一张类似的图片,程序就能立刻识别出该图片所代表的数字。
怎么做到的呢?我们知道,一张图片是由许多个像素组成的,每个像素都有一个值来代表该位置,而代表着同一个数字的图片在相同位置的像素是相似的,我们输入大量类似的图片代表训练集,利用神经网络算法对程序进行训练,机器就能够自己“学会”每个数字图片的“特征”,最终达到识别的效果。
二、简单神经网络结构介绍

上图是最简单的一种神经网络,甚至并不能称为神经网络,它只有一个神经元,包含两层,x1,x2称为输入层,y1,y2称为输出层,简单来说,我们输入2个数据x1和x2,对x1和x2进行处理,给它们各乘一个独立的权重W,然后再加上一个相同的偏置单元b,得
a1=w1x1+b,
a2=w2x2+b,
然后,我们需要对a1,a2利用一种函数F进行运算,这个F函数称为激活函数,常用的一种激活函数为sigmoid函数:
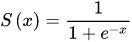
于是有
y1=sigmoid(a1)
y2=sigmoid(a2)
经过计算得到的结果y1,y2,我们称为输出层,y1,y2就是估计值。
这样,我们就完成了一次最简单的神经网络算法。这样的一次计算过程我们称为前向传播。
实际应用中简单神经网络往往是三层的,包含输入层、隐藏层和输出层。
事实上,不论多少层的神经网络,它的前向传播都是相同的,即上一层输出经过新的w,b处理后变为下一层的输入。
需要注意的是,每层神经元的每个输入x的权重w都是独立的不相同的,但每个神经元只有一个相同的b
实际应用中的神经网络结构要复杂得多,比如常用的Mnist手写识别模型,要用到3层神经网络结构,它的输入层的每组数据有784个数值,假设它的第二层(隐藏层)有40个神经元,那么它的第一层运算就会有784*40个w和40个b。
下面,我们就利用这个方法去找Mnist对线吧
然而,这样得到的y1,y2往往并不是我们期望的结果,要最终得到想要的数值,怎么做呢?
三、反向传播(梯度下降法)
反向传播是简单神经网络算法的精华,也是比较难以理解的一部分内容。
完成一次训练后,为了使y偏向正确的数值,我们需要跟据y与正确值之间的差距来不断修正每层神经元所有w和b的值,这样的过程,我们称为反向传播。每经过一次训练,我们就更新一次w和b,使整个神经网络逐渐接近正确的模型。因此,一个完善的神经网络模型往往需要大量的训练
一个三层神经网络结构如下:

(这里三层的n是不同的数值)
那么,反向传播是如何实现的呢?这里我们介绍梯度下降的方法。首先,我们引入损失函数:
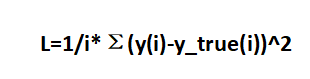
L表示估计值和真实值之间的距离,我们要找的就是使L最小的那个点

根据梯度的定义,我们知道函数f(x)沿它的导数f’(x)<0的方向不断下降,于是,我们对损失函数L不断地求其关于各个w和b的偏导数,再乘上一个较小的学习率以防止其下降得过快而越过了最小值,用w,b与其相减来更新w,b。但是,L本身是关于y和y_true的一个函数,不含有w与b,因此这里我们需要利用链式求导来得到w与b。下面,我们来推导反向传播的公式
假设有一个这样的三层神经网络
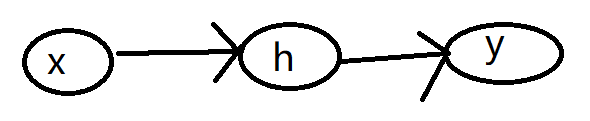
设:
x:输入层
h:隐藏层
y:输出层
h_in=w1x+b1
h=sigmoid(h_in)
y_in=w2h+b2
y=sigmoid(y_in)
L:损失函数
η:学习率(设为0.1)
有:
新w2=w2-η* ∂L/∂w2
新 b2=b2-η* ∂L/∂b2
新w1=w1-η* ∂L/∂w1
新b1=b1-η* ∂L/∂b1
而
∂L/∂w2=∂L/∂y * ∂y/∂y_in * ∂y_in/∂w2
∂L/∂b2=∂L/∂y * ∂y/∂y_in * ∂y_in/∂b2
∂L/∂w1=∂L/∂y * ∂y/∂y * ∂y_in/∂y_in * ∂h/∂h_in * ∂h_in/∂w1
∂L/∂b1=∂L/∂y * ∂y/∂y * ∂y_in/∂y_in * ∂h/∂h_in * ∂h_in/∂b
下面来分别计算每个式子的值
L=(y-y_true)^2
∂L/∂y=2(y-y_true)
∂y/∂y_in=y(1-y) (这里利用了sigmoid求导公式,即s’(x)=s(x)*(1-s(x))
∂y_in/∂w2=h
可得
∂L/∂w2=2(y-y_true)*(y(1-y))h
因此更新后的的w2=w2-0.1 * 2(y-y_true)(y(1-y))*h
类似地,我们能够求出每一个更新后的值。
当网络中所有w和b全部完成更新,一次反向传播就完成了,一次完整的训练应当包含正向传播和反向传播的内容。当然,实际编程的过程中还会有各种各样的问题,在以后的博客中我会贴上代码展示。
总结
这就是构建一个简单神经网络的过程。它的核心思想就是通过反复的训练最终得到理想的w和b的值,而η则需要人为地调整达到最优。