基于邻域的算法应该算是推荐系统中最基础的算法之一了,主要包括基于用户的协同过滤和基于物品的协同过滤,我觉得他们是最符合直觉的推荐算法了。你想想看,如果给你若干人的行为数据,你怎么去做推荐,一个就是找到和他最相似的用户,因为他们臭味相投,所以看看这些用户都看了些啥,然后给他推荐这些用户看过而待推荐用户没看过的商品;另一个就是找到和用户历史放生交互的商品最相似的商品,用户以前喜欢过它,也许会喜欢和它相似或者相关的东西。今天我们就从User-based CF开始,也就是基于用户的协同过滤。
那么问题来了,最最关键的一个问题,如何找出和待推荐用户口味相似的用户呢?哎呀,其实也没有其他选择啦,就是根据用户的历史行为记录,如果两个人的历史记录里有非常多共同的部分,那么大概率他们是志趣相投的,所以可以通过余弦相似度进行计算
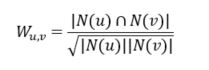
直观地来看,对用户做两层嵌套的循环就可以算出来,但事实上在海量用户的情况下,这样的复杂度是很难接受的,那么可优化的空间在哪里呢?其实用户的交互是稀疏的,所以对于很多(u,v)对来说其实没有计算的必要。所以可以选择做一个物品-用户倒排表,用一个矩阵C[u][v]来表示用户之间相同的交互数量,对于倒排表中的每个物品对应的用户,两两之间在C中+1,通过这种方式得到所有交互不为0的用户相似度,实现算法如下所示:
def User_Similarity(train_set):
# Build inverse table
item_user = {}
for u, items in train_set.items():
for i in items:
if i not in item_user.keys():
item_user[i] = set()
item_user[i].add(u)
print('Inverse table finished')
# Co-rated items between users
C = {}
N = {}
W = {}
for u in train_set.keys():
N[u] = 0
C[u] = {}
W[u] = {}
for v in train_set.keys():
if v == u:
continue
C[u][v] = 0
W[u][v] = 0
for i, users in item_user.items():
for u in users:
N[u] += 1
for v in users:
if v == u:
continue
C[u][v] += 1
print('Co-rated items count finished')
# Calculate similarity matrix
for u, related_users in C.items():
for v, cuv in related_users.items():
W[u][v] = cuv/(N[u]*N[v])**0.5
print('Similarity calculation finished')
return W
有了相似度矩阵之后我们就可以进行推荐了,首先找出和用户相似度最高的K个用户,然后得到这K个用户发生交互商品的集合,去除用户原本已经发生交互的商品就得到了带推荐的集合,如何去衡量这些待推荐商品的优先级呢,很容易想到,如果它来自和用户相似度非常高的用户,那么它的优先级肯定应该高一点对吧,所以可以用如下公式来描述
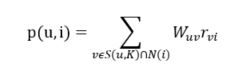
与用户最相似的K个用户中如果用户v与待推荐商品发生过交互,则用户对该商品的兴趣加上这两个用户的相似度和该用户对该商品的兴趣的乘积,如果只是单纯的行为数据,则兴趣为1。有了用户对待推荐商品的兴趣之后,可以选择一个阈值N,将用户兴趣度最高的N个商品作为最后的推荐集合,代码实现如下
def Recommend(user, train, W, K):
rank = {}
already_items = train[user]
for v, wuv in sorted(W[user].items(), key=itemgetter(1), reverse=True)[:K]:
for i in train[v]:
if i in already_items:
continue
if i not in rank.keys():
rank[i] = 0
rank[i] += wuv
return rank
到了这里,其实咱们已经完成了User-based CF算法,下面咱们得操练操练呀。例子来自于《推荐系统实践》这本书,利用MovieLens的数据集进行离线实验。首先是训练集和测试集的划分,这里比例选择是4:1,每一次将所有的数据打乱,前80%用作训练集,后20%用于测试集,代码实现如下:
def train_test_split(data, seed):
train_set = {}
test_set = {}
for user, movies in data.groupby('user_id'):
movies = movies.sample(
frac=1, random_state=seed).reset_index(drop=True)
train = movies[:int(0.8*len(movies))]
test = movies[int(0.8*len(movies)):]
train_set[user] = set(train['movies_id'].tolist())
test_set[user] = set(test['movies_id'].tolist())
print('Data preparation finished')
return train_set, test_set
划分好数据集之后我们就可以进行预测了,包括交互表的统计,相似度排序,兴趣度计算和截断,生成推荐集。那么这边问题来了,我们怎么去评价推荐的效果呢,这里主要计算了以下四个指标
1 Recall
召回率是指实际发生交互的商品中被预测出来部分的比例,实现如下
def Recall(train, test, N, K, W):
hit = 0
all = 0
for user in train.keys():
tu = test[user]
recommend_list = get_recommendation(N, user, K, W, train)
for item in recommend_list:
if item in tu:
hit += 1
all += len(tu)
return hit/(all*1.0)
2 Precision
准确率是指实推荐的商品中用户真正发生交互商品的比例,实现如下
def Precision(train, test, N, K, W):
hit = 0
all = 0
for user in train.keys():
tu = test[user]
recommend_list = get_recommendation(N, user, K, W, train)
for item in recommend_list:
if item in tu:
hit += 1
all += N
return hit/(all*1.0)
3 Coverage
覆盖率,这算是推荐系统中独有的指标了,指推荐的商品占总商品数的比例。这个比例越高表明推荐系统发掘长尾的能力越强,实现如下
def All_item(train):
all_items = set()
for user in train.keys():
for item in train[user]:
all_items.add(item)
return all_items
def Coverage(train, test, N, K, W,all_items):
recommend_items = set()
for user in train.keys():
recommend_list = get_recommendation(N, user, K, W, train)
for item in recommend_list:
recommend_items.add(item)
return len(recommend_items)/(len(all_items)*1.0)
4 Popularity
流行度,推荐商品的平均流行度,该值越高表明推荐的商品大多是比较热门的内容,推荐系统发掘长尾的能力较差,可以和覆盖率联合起来看,表征推荐的新颖度,实现如下
def Item_popularity(train):
item_popularity = {}
for user, items in train.items():
for item in items:
if item not in item_popularity.keys():
item_popularity[item] = 0
item_popularity[item] += 1
return item_popularity
def Popularity(train, test, N, K, W,item_popularity):
ret = 0
n = 0
for user in train.keys():
recommend_list = get_recommendation(N, user, K, W, train)
for item in recommend_list:
ret += np.log(1+item_popularity[item])
n += 1
return ret/(n*1.0)
OK,到了这里我们应该算是完成一个小小的User-based CF的实现及测试了,那么还有什么问题呢?在我们的算法里有两个超参数,一个是选择和用户最相似的K个用户,一个是选择用户兴趣度最高的N个商品生成推荐集。想一想,N固定的情况下,K越高,参与用户兴趣度计算的相似用户越多,那么更多的用户潜在交互商品被发掘出来,推荐的召回率和精确率肯定都会上升,但是应该会有一个边际效应,当K提升到某个值之后,基本没有提高了;而对于覆盖率和流行度而言,越多用户参与评分,推荐出来的东西肯定更热门,那么覆盖率肯定下降,流行度提升。同样的,在K固定的情况下,如果N越高,肯定有更多的用户潜在交互商品被推荐出来,所以召回率肯定会提升,而对于准确率,一开始也许会有一个提升,但后来肯定会下降,因为预测出的商品数量越来越多;至于覆盖率,由于商品数量变多,所以肯定会上升,而对于流行度,推荐排行越靠后的商品相对越小众一点,所以平均流行度会下降。
这里做一个小实验,我固定了N值,对不同的K值进行计算,采用八折计算的平均结果作为最后的对应K值地结果,可以看看趋势变化是否和我们分析一致

确实是随着K值的提高,召回率和准确率有所提升,但到80左右已经几乎达到了峰值,进一步提高到160甚至略微有所下降;而覆盖率和流行度和预测完全一致,覆盖率不停下降,流行度不断上升,越来越倾向于推荐热门内容。
最后还有一个小改进,是关于咱们计算用户之间相似度的,现在我们用的是不同用户对同一物品都发生过交互,则相似度加一,对于所有的物品一视同仁。但是仔细想想存在这样一种商品,它超级热门,基本人人都和它发生过交互,可它对我们判断有两个人相似有作用吗?米有,所以我们针对热门产品需要加一波惩罚,具体就是该商品的交互人数的对数的倒数作为相似度累加时的加权,减少热门产品对我们预测的影响,实现如下,
def User_Similarity2(train_set):
# Build inverse table
item_user = {}
for u, items in train_set.items():
for i in items:
if i not in item_user.keys():
item_user[i] = set()
item_user[i].add(u)
print('Inverse table finished')
# Co-rated items between users
C = {}
N = {}
W = {}
for u in train_set.keys():
N[u] = 0
C[u] = {}
W[u] = {}
for v in train_set.keys():
if v == u:
continue
C[u][v] = 0
W[u][v] = 0
for i, users in item_user.items():
for u in users:
N[u] += 1
for v in users:
if v == u:
continue
C[u][v] += 1/np.log(1+len(users)*1.0)
print('Co-rated items count finished')
# Calculate similarity matrix
for u, related_users in C.items():
for v, cuv in related_users.items():
W[u][v] = cuv/(N[u]*N[v])**0.5
print('Similarity calculation finished')
return W
这里我们再做一个小实验,固定N值为10,K值为刚才最好表现的80,采用两种不同的相似度计算方法,比较一下它们的结果,如下图所示

从图中我们就可以看出,在计算相似度时考虑到物品的流行度对我们的预测确实是有帮助的,而且是全方位无死角的提高,蛤蛤蛤,不过计算时间长了15倍……
今天就到这儿,下一篇咱们来聊一聊Item-based CF。