计算物品的相似度矩阵
例如现在有A、B、C、D四个用户,分别对a、b、c、d、e五个物品表达了自己喜好程度(通过评分高低来表现自己的偏好程度高低),计算物品之间的相似度矩阵

算法
1、建立用户物品倒排表
A a b d
B a c e
C b e
D b d e
2、构建同现矩阵
同现矩阵表示同时喜欢两个物品的用户数,根据用户物品倒排表计算出来
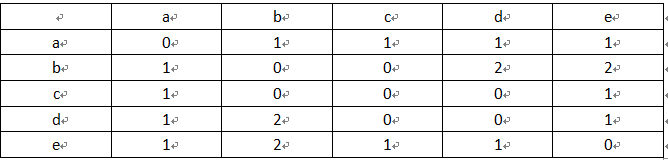
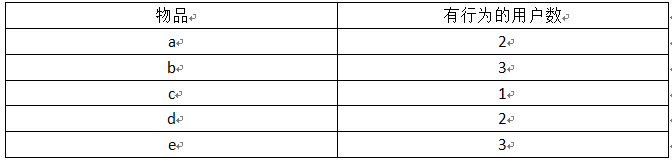
3、统计每个物品有行为的用户数
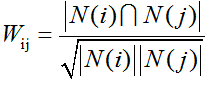
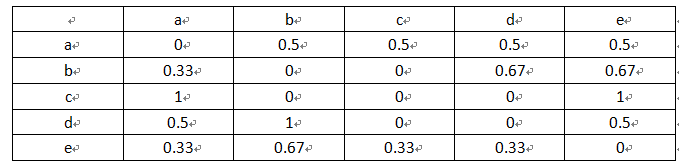
4、计算物品之间的相似度,得到物品之间的相似度矩阵

分母 是喜欢物品i的用户数;
分子 是同时喜欢物品i和物品j的用户数。
代码
class ItemCF:
def __init__(self):
self.user_score_dict = self.initUserScore()
self.items_sim = self.ItemSimilarity()
# 初始化用户评分数据
def initUserScore(self):
user_score_dict = {
"A": {"a": 3.0, "b": 4.0, "c": 0.0, "d": 3.5, "e": 0.0},
"B": {"a": 4.0, "b": 0.0, "c": 4.5, "d": 0.0, "e": 3.5},
"C": {"a": 0.0, "b": 3.5, "c": 0.0, "d": 0.0, "e": 3.0},
"D": {"a": 0.0, "b": 4.0, "c": 0.0, "d": 3.5, "e": 3.0},
}
return user_score_dict
# 计算item之间的相似度
def ItemSimilarity(self):
itemSim = dict()
# 得到每个物品有多少用户产生过行为
item_user_count = dict()
# 同现矩阵
count = dict()
for user, item in self.user_score_dict.items():
for i in item.keys():
item_user_count.setdefault(i, 0)
if self.user_score_dict[user][i] > 0.0:
item_user_count[i] += 1
for j in item.keys():
count.setdefault(i, {}).setdefault(j, 0)
if (
self.user_score_dict[user][i] > 0.0
and self.user_score_dict[user][j] > 0.0
and i != j
):
count[i][j] += 1
# 共现矩阵 -> 相似度矩阵
for i, related_items in count.items():
itemSim.setdefault(i, dict())
for j, cuv in related_items.items():
itemSim[i].setdefault(j, 0)
itemSim[i][j] = cuv / item_user_count[i]
return itemSim
if __name__ == "__main__":
m=ItemCF()
print(m.ItemSimilarity())
运行结果

参考书本
项 亮编著,陈 义 ,王 益审校.北京:人民邮电出版社,2016:6