一、协同过滤(collaborative filtering)
一种ItemCF推荐baseline:
1.输入:user-item相关矩阵
2.中间结果:item间相似度计算:item_i与item_j间相似度:分子:与二者均有关联的user数,被同一个人购买的次数多则相似;分母包含各自关联的总用户数,用以惩罚热门item;
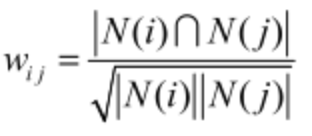
p.s.认为无评分时相当于做了热度衰减的频繁项集推荐方式;
如有user-item关系有权重(如用户对影片评分):相似度取决于对二者皆有交互的用户评分,将上式分子换为两item评分向量内积(余弦相似度),或对二者的评分减去二者各自平均值后相乘结果(皮尔逊相关系数)
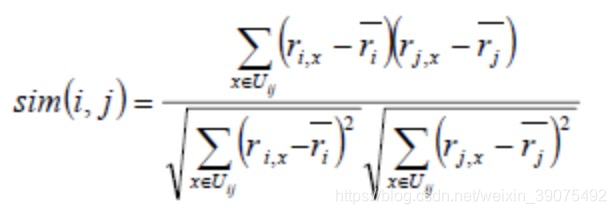
保存item相似度矩阵;
3.user推荐:根据user-item相关矩阵得到user-itemlist,遍历该user交互过的itemlist,对每个item取相似N个,根据相似度聚合排序得到用户推荐结果;
ItemCF推荐用户交互过的item的相似item,适合item集比较稳定的情况下,如长视频等,对新item的推荐不友好,如推荐新闻等变化快的item,则UserCF更具优势,推荐以往相似兴趣的用户在看的内容;
附代码如下:
import math
def ItemSimilarity(train):
# 物品-物品的共同矩阵
C = dict()
# 物品被多少个不同用户购买
N = dict()
for u, items in train.items():
for i in items.keys():
N.setdefault(i, 0)
N[i] += 1
C.setdefault(i, {
})
for j in items.keys():
if i == j:
continue
C[i].setdefault(j, 0)
C[i][j] += 1
# 计算相似度矩阵
W = dict()
for i, related_items in C.items():
W.setdefault(i