Transforms
Abort(取消)
DESCRIPTION(描述)
一旦接收到输入数据,Abort转换就终止正在运行的管道。此转换的主要用例是在发生意外或不想要的情况时抛出错误。
例如,您可以使用此转换,以便在经过错误跳的x行流量后中止管道。
OPTIONS(选择项)
| Option |
Description |
Transform name
(转化名称) |
Name of the transform.
转换的名称 |
Abort threshold
终端阈值 |
The threshold of number of rows after which to abort the pipeline. E.g. If threshold is 0, the abort transform will abort after seeing the first row. If threshold is 5, the abort transform will abort after seeing the sixth row.
终止管道的行数阈值。例:如果阈值为0,中止转换将在看到第一行后中止。如果阈值为5,则中止转换将在看到第6行后中止 |
Abort message
中断消息 |
The message to put in the log upon aborting. If not filled in a default message will be used.
中止时要放入日志中的消息。如果不填写,将使用默认消息 |
Always log
|
Always log the rows processed by the Abort transform. This allows the rows to be logged although the log level of the pipeline would normally not do it. This way you can always see in the log which rows caused the pipeline to abort.
始终记录由Abort转换处理的行。这允许记录行,尽管管道的日志级别通常不会这样做。通过这种方式,您总是可以在日志中看到哪些行导致管道中止 |
Add a checksum
Descripton
The Add a Checksum transform calculates checksums for one or more fields in the input stream and adds this to the output as a new field.
添加校验和转换计算输入流中一个或多个字段的校验和,并将其作为新字段添加到输出中。
Options
| Option |
Description |
Transform name
转换名称 |
Name of the transform. Note: This name has to be unique in a single pipeline.
|
Type
类型 |
需要计算的校验和的类型。这些是可用的类型:
CRC32: 32位循环冗余校验:http://en.wikipedia.org/wiki/Cyclic_redundancy_check
ADLER32:Mark Adler的校验和算法:http://en.wikipedia.org/wiki/Adler-32
MD5:消息摘要算法 5http://en.wikipedia.org/wiki/MD5
SHA-1: 安全哈希算法 1 :http://en.wikipedia.org/wiki/SHA-1
SHA-256: 安全哈希算法 2 :http://en.wikipedia.org/wiki/SHA-256
|
Result Type
结果类型 |
Some checksum types allow to set different result types: String, Hexadecimal and Binary
一些校验和类型允许设置不同的结果类型:字符串、十六进制和二进制 |
Result field
结果字段 |
The name of the result field containing the checksum
包含校验和的结果字段的名称 |
Fields used in the checksum
校验和中使用的字段 |
The names of the fields to include in the checksum calculation. Note: You can use the “Get Fields” button to insert all input fields from previous transforms.
要包括在校验和计算中的字段的名称。注意:您可以使用“获取字段”按钮插入以前转换中的所有输入字段。 |
Add Constants
Add Sequence
Description
The Add Sequence transform adds a sequence to the Hop stream. A sequence is an ever-changing integer value with a specific start and increment value.
“添加序列”转换将序列添加到跃点流。序列是具有特定起始值和增量值的不断变化的整数值。
You can either use a database sequence (if supported, e.g. Oracle, PostgreSQL) to determine the value of the sequence, or have it generated by Hop.
您可以使用数据库序列(如果支持,例如 Oracle、PostgreSQL)来确定序列的值,也可以由 hop 生成。
Hop-generated sequence values are unique when used in the same pipeline, and return to the same starting value each time you run the pipeline. Hop sequences are unique only when used in the same pipeline. Also, they are not stored, so the values start back at the same value every time the pipeline is launched.
跃点生成的序列值在同一管道中使用时是唯一的,并且每次运行管道时都会返回到相同的起始值。仅在同一管道中使用跃点序列时才是唯一的。此外,它们不会存储,因此每次启动管道时,这些值都会从相同的值开始。
Options
| Option |
Description |
Transform name
转换名称 |
The name of this transform as it appears in the pipeline workspace. This name must be unique within a single pipeline.
此转换在管道工作区中显示的名称。此名称在单个管道中必须是唯一的。 |
Name of value
值的名称 |
Name of the new sequence value that is added to the stream.
添加到流中的新序列值的名称。 |
Use DB to generate the sequence
使用数据库生成序列 |
Enable if you want the sequence to be driven by a database sequence, then set these parameters: Connection name, Schema name (optional), Sequence name.
如果您希望序列由数据库序列驱动,请启用,然后设置以下参数:连接名称、架构名称(可选)、序列名称。 |
Connection name
连接名称 |
The name of the connection on which the database sequence resides.
数据库序列所在的连接的名称。 |
Schema name (optional)
架构名称(可选) |
The table’s schema name.
表的架构名称。 |
Sequence name
序列名称 |
The name of the database sequence.
数据库序列的名称。 |
Use a pipeline counter to generate the sequence
使用管道计数器生成序列 |
Enable if you want the sequence to be generated by Hop, then set these parameters: Counter name (optional), Start at, Increment by, Maximum value.
如果您希望序列由 Hop 生成,请启用,然后设置以下参数:计数器名称(可选)、起始于、递增依据、最大值。 |
| Use counter to calculate sequence? |
使用计数器计算序列 |
Counter name (optional)
计数器名称 |
If multiple transforms in a pipeline generate the same value name, this option enables you to specify the name of the counter to associate with. Avoids forcing unique sequencing across multiple steps.
如果管道中的多个转换生成相同的值名称,则此选项允许你指定要与之关联的计数器的名称。避免跨多个步骤强制进行唯一排序。 |
Start at
开始于 |
The value to begin the sequence with.
序列开头的值。 |
Increment by
递增依据 |
The amount by which the sequence increases or decreases.
序列增加或减少的量。 |
Maximum value
最大值 |
The value after which the sequence returns to the Start At value.
序列返回到“起始位置”值的值。 |
Add value fields changing sequence
Add XML
Analytic Query(分析查询)
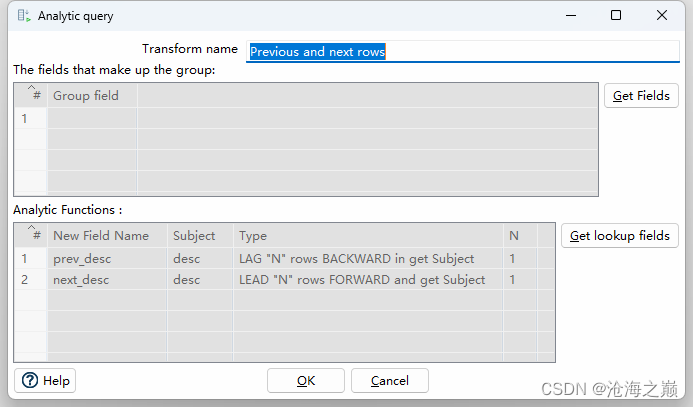
Description
The Analytic Query transform allows you to peek forward and backwards across rows in a pipeline.
分析查询转换允许您向前和向后查看管道中的行。
Examples of common use cases are:
常见用例的示例包括:
- Calculate the “time between orders” by ordering rows by order date, and LAGing 1 row back to get previous order time.
- 通过按订单日期对行进行排序来计算“订单之间的时间”,然后向后拖取 1 行以获得之前的订单时间。
- Calculate the “duration” of a web page view by LEADing 1 row ahead and determining how many seconds the user was on this page.
- 通过提前 1 行并确定用户在此页面上停留的秒数来计算网页浏览的“持续时间”。
Options
| Option |
Description |
Transform name
转换名称 |
The name of this transform as it appears in the pipeline workspace.
此转换在管道工作区中显示的名称。 |
Group fields table
组字段表 |
Specify the fields you want to group. Click Get Fields to add all fields from the input stream(s). The transform will do no additional sorting, so in addition to the grouping identified (for example CUSTOMER_ID) here you must also have the data sorted (for example ORDER_DATE).
指定要分组的字段。单击获取字段以添加输入流中的所有字段。转换不会执行其他排序,因此除了标识的分组(例如 CUSTOMER_ID)之外,您还必须对数据进行排序(例如ORDER_DATE)。 |
Analytic Functions table
“分析函数”表 |
Specify the analytic functions to be solved.
指定要求解的分析函数。 |
New Field Name
新字段名称 |
the name you want this new field to be named on the stream (for example PREV_ORDER_DATE)
您希望在流中命名此新字段的名称(例如 PREV_ORDER_DATE) |
Subject
主题 |
The existing field to grab (for example ORDER_DATE)
要抓取的现有字段(例如 ORDER_DATE) |
Type
类型 |
Set the type of analytic function:
LEAD “N” rows FORWARD and get Subject
LAG “N” rows BACKWARD in get Subject
设置分析函数的类型:
前进 - 前进 N 行并获取主题的值
滞后 - 向后 N 行并获取主题的值 |
| N |
The number of rows to offset (backwards or forwards)
要偏移的行数(向后或向前) |
Group field example
While it is not mandatory to specify a group, it can be useful for certain cases. If you create a group (made up of one or more fields), then the “lead forward / lag backward” operations are made only within each group. For example, suppose you have this:
虽然指定组不是强制性的,但在某些情况下可能很有用。如果创建一个组(由一个或多个字段组成),则仅在每个组中执行“前进/滞后”操作。例如,假设您有以下内容:
X , Y
--------
aaa , 1
aaa , 2
aaa , 3
bbb , 4
bbb , 5
bbb , 6
And you want to create a field named Z, with the Y value in the previous row.
并且您要创建一个名为 Z 的字段,其中 Y 值位于上一行。
If you only care about the Y field, you don’t need to group. And you will have the following result:
如果您只关心 Y 字段,则无需分组。您将得到以下结果:
X , Y , Z
------------
aaa , 1 , <null>
aaa , 2 , 1
aaa , 3 , 2
bbb , 4 , 3
bbb , 5 , 4
bbb , 6 , 5
But if you don’t want to mix the values for aaa and bbb, you can group by the X field, and you will have this:
但是,如果您不想混合 aaa 和 bbb 的值,您可以按 X 字段分组,您将获得以下内容:
X , Y , Z
------------
aaa , 1 , <null>
aaa , 2 , 1
aaa , 3 , 2
bbb , 4 , <null>
bbb , 5 , 4
bbb , 6 , 5
Thus, by grouping (provided the input is sorted according to your grouping), you can be assured that lead or lag operations will not return row values outside of the defined group.
因此,通过分组(前提是输入根据您的分组进行排序),您可以确保超前或滞后操作不会返回定义组之外的行值。
Apache Tika
Append Streams
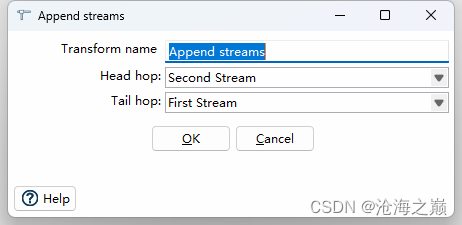
Description
The Append Streams transform reads the data from two transforms, only processing the second stream after the first one is finished.
追加流转换从两个转换读取数据,仅在第一个转换完成后处理第二个流。
As always, the row layout for the input data coming from both transforms has to be identical: the same row lengths, the same data types, the same fields at the same field indexes in the row.
与往常一样,来自两个转换的输入数据的行布局必须相同:行长度相同、数据类型相同、行中相同字段索引处的相同字段。
Important: If you don’t care about the order in which the output rows occur, you can use any transform to create a union of 2 or more data streams.
重要提示:如果您不关心输出行的出现顺序,则可以使用任何转换来创建 2 个或更多数据流的联合。
Options
| Option |
Description |
Transform name
转换名称 |
Name of the transform. Note: This name has to be unique in a single pipeline.
转换的名称。注意:此名称在单个管道中必须是唯一的。 |
Head hop
头跳 |
The name of the transform from which will be read the first stream.
将从中读取第一个流的转换的名称。 |
Tail hop
尾跳 |
The name of the transform from which will be read the second stream.
将从中读取第二个流的转换的名称。 |
Metadata Injection Support
All fields of this transform support metadata injection.
此转换的所有字段都支持元数据注入。
Avro Decode
Avro Encode
Avro File Input
Azure Event Hubs Listener
Azure Event Hubs Writer
Beam BigQuery Input
Beam BigQuery Output
Beam GCP Pub/Sub : Publish
Beam GCP Pub/Sub : Subscribe
Beam Input
Beam Kafka Consume
Beam Kafka Produce
Beam Output
Beam Timestamp
Beam Window
Blocking transform(阻塞)
Description
The Blocking transform blocks all output until the very last row is received from the previous transform.
阻止转换会阻止所有输出,直到从上一个转换收到最后一行。
|
the transform blocks until it gets the last row. It does not block until the previous transform is finished 100% which is functionality found in the other transform Blocking until transforms finish. |
|
转换会阻塞,直到它获得最后一行。在上一个转换完成 100% 之前,它不会阻塞,这是在另一个转换中找到的功能阻塞直到转换完成。 |
At that point, the last row is sent to the next transform or the complete input is sent off to the next transform. Use the Blocking transform for triggering plugins, stored procedures, Java scripts, … or for synchronization purposes.
此时,最后一行将发送到下一个转换,或者将完整的输入发送到下一个转换。使用阻塞转换来触发插件、存储过程、Java 脚本…或用于同步目的。
Options
| Option |
Description |
Transform name
转换名称 |
Name of the transform; this name has to be unique in a single pipeline.
转换的名称;此名称在单个管道中必须是唯一的。 |
Pass all rows?
传递所有行? |
Determines whether to pass one row or all rows
确定是传递一行还是传递所有行 |
Spool directory
临时文件目录 |
The directory in which the temporary files are stored if needed; the default is the standard temporary directory for the system
如果需要,存储临时文件的目录;默认值为系统的标准临时目录 |
Spool-file prefix
临时文件前缀 |
Choose a recognizable prefix to identify the files when they appear in the temp directory
选择一个可识别的前缀,以便在文件出现在临时目录中时对其进行标识 |
Cache size
缓存大小 |
The more rows you can store in memory, the faster the transform works
内存中可以存储的行越多,转换工作的速度就越快 |
Compress spool files?
是否压缩临时文件 |
Compresses temporary files when they are needed
在需要时压缩临时文件 |
Blocking until transforms finish(阻塞直到转换完成)
Description
This transform simply waits until all the transform copies that are specified in the dialog have finished.
此转换只是等待,直到对话框中指定的所有转换副本完成。
You can use it to avoid the natural concurrency (parallelism) that exists between pipeline transform copies.
可以使用它来避免管道转换副本之间存在的自然并发性(并行性)。
Options
| Option |
Description |
Transform name
转换名称 |
Name of the transform.
转换的名称。 |
Watch the following transforms
监控以下转换 |
Use this grid to specify the transforms to wait for.
使用此网格指定要等待的转换。 |
Get transforms
获取转换 |
Push this button to auto-fill the “Watch the following transforms” grid with all transforms available in the pipeline.
按此按钮可自动填充“监控以下转换”网格,其中包含管道中可用的所有转换。 |
| Option |
Description |
Transform name
转换名称 |
The name of the transform to wait for.
要等待的转换的名称。 |
CopyNr
|
The (0-based) copy number of the transform. If the named transform has an explicit setting for “Change number of copies to start”, and you want to wait for all copies to finish, you’ll need to enter one row in the grid for each copy, and use this column to specify which copy of the transform to wait for. For the default number of copies (1), the CopyNr is always 0.
转换的(从 0 开始)副本编号。如果命名转换具有“更改要开始的副本数”的显式设置,并且你想要等待所有副本完成,则需要在网格中为每个副本输入一行,并使用此列指定要等待的转换副本。对于默认副本数 (1),CopyNr 始终为 0。 |
Calculator(计算器)
description
The Calculator transform provides you with predefined functions that can be executed on input field values.
计算器转换为您提供了可对输入字段值执行的预定义函数。
*Note:* The execution speed of the Calculator is far better than the speed provided by custom scripts (JavaScript).
***注意:***计算器的执行速度远远优于自定义脚本(JavaScript)提供的速度。
In addition to the arguments (Field A, Field B and Field C) you must also specify the return type of the function. You can also choose to remove the field from the result (output) after all values are calculated; this is useful in cases where you use temporary values that don’t need to end up in your pipeline fields.
除了参数(字段 A、字段 B 和字段 C)之外,还必须指定函数的返回类型。您还可以选择在计算完所有值后从结果(输出)中删除该字段;这在使用不需要最终出现在管道字段中的临时值的情况下非常有用。
Options
| Function |
Description |
Set field to constant A
将字段设置为常量 A |
|
Create a copy of field A
创建字段 A 的副本 |
|
| A + B |
A plus B. |
| A - B |
A minus B. |
| A * B |
A multiplied by B. |
| A / B |
A divided by B. |
| A * A |
The square of A. |
| SQRT( A ) |
The square root of A. |
| 100 * A / B |
Percentage of A in B. |
| A - ( A * B / 100 ) |
Subtract B% of A. |
| A + ( A * B / 100 ) |
Add B% to A. |
| A + B *C |
Add A and B times C. |
| SQRT( AA + BB ) |
Calculate ?(A2+B2). |
| ROUND( A ) |
Returns the closest Integer to the argument. The result is rounded to an Integer by adding 1/2, taking the floor of the result, and casting the result to type int. In other words, the result is equal to the value of the expression: floor (a + 0.5). In case you need the rounding method “Round half to even”, use the following method ROUND( A, B ) with no decimals (B=0). |
| ROUND( A, B ) |
Round A to the nearest even number with B decimals. The used rounding method is “Round half to even”, it is also called unbiased rounding, convergent rounding, statistician’s rounding, Dutch rounding, Gaussian rounding, odd-even rounding, bankers’ rounding or broken rounding, and is widely used in bookkeeping. This is the default rounding mode used in IEEE 754 computing functions and operators. In Germany it is often called “Mathematisches Runden”. |
| STDROUND( A ) |
Round A to the nearest integer. The used rounding method is “Round half away from zero”, it is also called standard or common rounding. In Germany it is known as “kaufmännische Rundung” (and defined in DIN 1333). |
| STDROUND( A, B ) |
Same rounding method used as in STDROUND (A) but with B decimals. |
| CEIL( A ) |
The ceiling function map a number to the smallest following integer. |
| FLOOR( A ) |
The floor function map a number to the largest previous integer. |
| NVL( A, B ) |
If A is not NULL, return A, else B. Note that sometimes your variable won’t be null but an empty string. |
| Date A + B days |
Add B days to Date field A. Note: Only integer values for B are supported. If you need non-integer calculations, please add a second calculation with hours. |
| Year of date A |
Calculate the year of date A. |
| Month of date A |
Calculate number the month of date A. |
| Day of year of date |
A Calculate the day of year (1-365). |
| Day of month of date A |
Calculate the day of month (1-31). |
| Day of week of date A |
Calculate the day of week (1-7). 1 is Sunday, 2 is Monday, etc. |
| Week of year of date A |
Calculate the week of year (1-54). |
| ISO8601 Week of year of date A |
Calculate the week of the year ISO8601 style (1-53). |
| ISO8601 Year of date A |
Calculate the year ISO8601 style. |
| Byte to hex encode of string A |
Encode bytes in a string to a hexadecimal representation. |
| Hex encode of string A |
Encode a string in its own hexadecimal representation. |
| Char to hex encode of string A |
Encode characters in a string to a hexadecimal representation. |
| Hex decode of string A |
Decode a string from its hexadecimal representation (add a leading 0 when A is of odd length). |
| Checksum of a file A using CRC-32 |
Calculate the checksum of a file using CRC-32. |
| Checksum of a file A using Adler-32 |
Calculate the checksum of a file using Adler-32. |
| Checksum of a file A using MD5 |
Calculate the checksum of a file using MD5. |
| Checksum of a file A using SHA-1 |
Calculate the checksum of a file using SHA-1. |
| Levenshtein Distance (Source A and Target B) |
Calculates the Levenshtein Distance: http://en.wikipedia.org/wiki/Levenshtein_distance |
| Metaphone of A (Phonetics) |
Calculates the metaphone of A: http://en.wikipedia.org/wiki/Metaphone |
| Double metaphone of A |
Calculates the double metaphone of A: http://en.wikipedia.org/wiki/Double_Metaphone |
| Absolute value ABS(A) |
Calculates the Absolute value of A. |
| Remove time from a date A |
Removes time value of A. Note: Daylight Savings Time (DST) changes in Sao Paulo and some other parts of Brazil at midnight 0:00. This makes it impossible to set the time to 0:00 at the specific date, when the DST changes from 0:00 to 1:00 am. So, there is one date in one year in these regions where this function will fail with an “IllegalArgumentException: HOUR_OF_DAY: 0 → 1”. It is not an issue for Europe, the US and other regions where the time changes at 1:00 or 2:00 or 3:00 am. |
| Date A - Date B (in days) |
Calculates difference, in days, between A date field and B date field. |
| A + B + C |
A plus B plus C. |
| First letter of each word of a string A in capital |
Transforms the first letter of each word within a string. |
| UpperCase of a string A |
Transforms a string to uppercase. |
| LowerCase of a string A |
Transforms a string to lowercase. |
| Mask XML content from string A |
Escape XML content; replace characters with &values. |
| Protect (CDATA) XML content from string A |
Indicates an XML string is general character data, rather than non-character data or character data with a more specific, limited structure. The given string will be enclosed into <![CDATA[String]]>. |
| Remove CR from a string A |
Removes carriage returns from a string. |
| Remove LF from a string A |
Removes linefeeds from a string. |
| Remove CRLF from a string A |
Removes carriage returns/linefeeds from a string. |
| Remove TAB from a string A |
Removes tab characters from a string. |
| Return only digits from string A |
Outputs only digits (0-9) from a string. |
| Remove digits from string A |
Removes all digits (0-9) from a string. |
| Return the length of a string A |
Returns the length of the string. |
| Load file content in binary |
Loads the content of the given file (in field A) to a binary data type (e.g. pictures). |
| Add time B to date A |
Add the time to a date, returns date and time as one value. |
| Quarter of date A |
Returns the quarter (1 to 4) of the date. |
| variable substitution in string A |
Substitute variables within a string. |
| Unescape XML content |
Unescape XML content from the string. |
| Escape HTML content |
Escape HTML within the string. |
| Unescape HTML content |
Unescape HTML within the string. |
| Escape SQL content |
Escapes the characters in a String to be suitable to pass to an SQL query. |
| Date A - Date B (working days) |
Calculates the difference between Date field A and Date field B (only working days Mon-Fri). |
| Date A + B Months |
Add B months to Date field A. Note: Only integer values for B are supported. If you need non-integer calculations, please add a second calculation with days. |
| Check if an XML file A is well formed |
Validates XML file input. |
| Check if an XML string A is well formed |
Validates XML string input. |
| Get encoding of file A |
Guess the best encoding (UTF-8) for the given file. |
| Dameraulevenshtein distance between String A and String B |
Calculates Dameraulevenshtein distance between strings: http://en.wikipedia.org/wiki/Damerau%E2%80%93Levenshtein_distance
|
| NeedlemanWunsch distance between String A and String B |
Calculates NeedlemanWunsch distance between strings: http://en.wikipedia.org/wiki/Needleman%E2%80%93Wunsch_algorithm
|
| Jaro similitude between String A and String B |
Returns the Jaro similarity coefficient between two strings. |
| JaroWinkler similitude between String A and String B |
Returns the Jaro similarity coefficient between two string: http://en.wikipedia.org/wiki/Jaro%E2%80%93Winkler_distance
|
| SoundEx of String A |
Encodes a string into a Soundex value. |
| RefinedSoundEx of String A |
Retrieves the Refined Soundex code for a given string object |
| Date A + B Hours |
Add B hours to Date field. Note: Only integer values for B are supported. If you need non-integer calculations, please add a second calculation with minutes. |
| Date A + B Minutes |
Add B minutes to Date field. Note: Only integer values for B are supported. If you need non-integer calculations, please add a second calculation with seconds. |
| Date A - Date B (milliseconds) |
Subtract B milliseconds from Date field A |
| Date A - Date B (seconds) |
Subtract B seconds from Date field A. Note: Only integer values for B are supported. If you need non-integer calculations, please add a second calculation with milliseconds. |
| Date A - Date B (minutes) |
Subtract B minutes from Date field A. Note: Only integer values for B are supported. If you need non-integer calculations, please add a second calculation with seconds. |
| Date A - Date B (hours) |
Subtract B hours from Date field A. Note: Only integer values for B are supported. If you need non-integer calculations, please add a second calculation with minutes. |
| Hour of Day of Date A |
Extract the hour part of the given date |
| Minute of Hour of Date A |
Extract the minute part of the given date |
| Second of Hour of Date A |
Extract the second part of a given date |
FAQ
Q: I made a pipeline using A/B in a calculator transform and it rounded wrong: the 2 input fields are integer but my result type was Number(6, 4) so I would expect the integers to be cast to Number before executing the division.
If I wanted to execute e.g. 28/222, I got 0.0 instead of 0.1261 which I expected. So it seems the result type is ignored. If I change the input types both to Number(6, 4) I get as result 0.12612612612612611 which still ignores the result type (4 places after the comma).
Why is this?
A: Length & Precision are just metadata pieces.
If you want to round to the specified precision, you should do this in another transform. However: please keep in mind that rounding double point precision values is futile anyway. A floating point number is stored as an approximation (it floats) so 0.1261 (your desired output) could (would probably) end up being stored as 0.126099999999 or 0.1261000000001 (Note: this is not the case for BigNumbers)
So in the end we round using BigDecimals once we store the numbers in the output table, but NOT during the pipeline. The same is true for the Text File Output transform. If you would have specified Integer as result type, the internal number format would have been retained, you would press “Get Fields” and it the required Integer type would be filled in. The required conversion would take place there and then.
In short: we convert to the required metadata type when we land the data somewhere, NOT BEFORE.
Q: How do the data types work internally?
A: You might notice that if you multiply an Integer and Number, the result is always rounded. That is because Calculator takes data type of the left hand size of the multiplication (A) as the driver for the calculation. As such, if you want more precision, you should put field B on the left hand side or change the data type to Number and all will be well.
Cassandra Input
Cassandra Output
Cassandra SSTable Output
Call DB procedure
Change file encoding
Check if file is locked
Check if webservice is available
Clone row(克隆行)
Description
The Clone Row transform creates copies (clones) of a row and outputs them directly after the original row to the next transforms.
克隆行转换创建行的副本(克隆),并将它们直接在原始行之后输出到下一个转换。
Options
| Option |
Description |
Transform name
转换名称 |
Name of the transform. Note: This name has to be unique in a single pipeline.
转换的名称。注意:此名称在单个管道中必须是唯一的。 |
Nr clones
Nr 克隆 |
The number of clones you want to add after the original row.
要在原始行之后添加的克隆数。 |
Nr clone in field
|
|
Nr clone field
|
|
Add clone flag
添加克隆标志 |
Check this option if you want to add a boolean field in the output indicating if the row is a clone or not.
如果要在输出中添加布尔字段,指示该行是否为克隆,请选中此选项。
N / false : this is not a cloned row, it’s the original row
N / false :这不是克隆的行,而是原始行
Y / true : this is a cloned row, a copy of the original row
Y / true:这是一个克隆的行,原始行的副本 |
Clone flag field
克隆标志字段 |
The name of the clone flag field
克隆标志字段的名称 |
Add clone num to
|
|
Clone num field
|
|
Closure(闭环,2.1版中叫closure generate)
description
The Closure transform allows you to generate a Reflexive Transitive Closure Table for the Mondrian OLAP engine. For more information on how a closure table can help Mondrian gain performance, go here Technically, this transform reads all input rows in memory and calculates all possible parent-child relationships. It attaches the distance (in levels) from parent to child.
闭包转换允许您为蒙德里安 OLAP 引擎生成自反传递闭包表。有关闭包表如何帮助 Mondrian 获得性能的更多信息,请转到此处 从技术上讲,此转换读取内存中的所有输入行并计算所有可能的父子关系。它附加从父级到子级的距离(以级别为单位)。
Options
| Option |
Description |
Transform name
转换名称 |
The name that uniquely identifies the transform.
唯一标识转换的名称。 |
Parent ID field
父 ID 字段 |
The field name that contains the parent ID of the parent-child relationship.
包含父子关系的父 ID 的字段名称。 |
Child ID field
子 ID 字段 |
The field name that contains the child ID of the parent-child relationship.
包含父子关系的子 ID 的字段名称。 |
Distance field name
距离字段名称(层级) |
The name of the distance field that will be added to the output
将添加到输出的距离字段的名称 |
Root is zero
根为零 |
Check this box if the root of the parent-child tree is not empty (null) but zero (0)
如果父子树的根不为空 (null) 而是零 (0),请选中此框 |
Coalesce(合并)
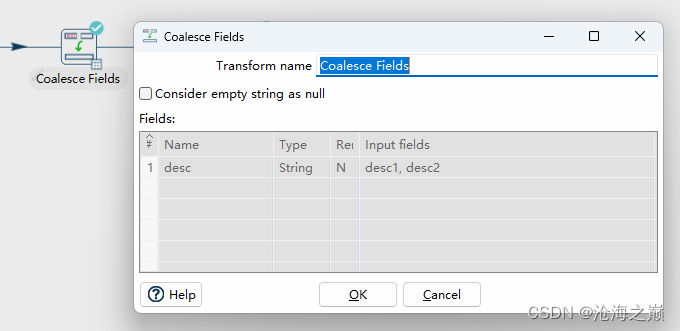
description
The Coalesce transform lets you list multiple fields and returns the first non-null value.
合并转换允许您列出多个字段并返回第一个非空值。
Options
| Option |
Description |
Transform name
转换名称 |
Name of the transform. Note: This name has to be unique in a single pipeline.
转换的名称。注意:此名称在单个管道中必须是唯一的。 |
Considered empty string as null
将空字符串视为空字符串 |
The transform can consider empty string as null.
转换可以将空字符串视为 null。 |
Fields
|Fields|specify the name, type, and value in the form of a string. Then, specify the formats to convert the value into the chosen data type.
| Name |
The result field name, can overwrite an existing one. |
Type
类型 |
The formats to convert the value into the chosen data type.
将值转换为所选数据类型的格式。 |
Remove
删除 |
Remove input fields from the stream.
从流中删除输入字段。 |
Input fields
输入字段 |
The order of the input fields listed in the columns determines the order in which they are evaluated.
列中列出的输入字段的顺序决定了计算这些字段的顺序。 |
Column exists(列存在)
Description
The Column Exists transforms allows you to verify the existence of a specific column in a database table
描述“列存在”转换允许您验证数据库表中是否存在特定列。
Options
| Option |
Description |
Transform name
转换名称 |
Name of the transform; This name has to be unique in a single pipeline
转换的名称;此名称在单个管道中必须是唯一的 |
Connection
连接 |
The database connection to use
要使用的数据库连接 |
Schema name
架构名称 |
(optional) The schema name of the table of the column to check
(可选)要检查的列的表的架构名称 |
Table name
表名 |
The name of the table of the column to check
要检查的列的表的名称 |
Tablename in field?
字段中的表名? |
Enable to read the name of the table in an input field
启用此选项可读取输入字段中的表名称 |
Tablename field
表名字段 |
Specify the fieldns containing parameters and the parameter type
指定包含参数的字段和参数类型 |
Columnname field
列名字段 |
The name of the column field in the input stream
输入流中列字段的名称 |
Result fieldname
结果字段名称 |
The name of the resulting boolean flag field
生成的布尔标志字段的名称 |
Combination lookup/update
Concat Fields
Copy rows to result
Credit card validator
CSV File Input(CSV文件输入)
description
The CSV File Input transform reads data from a delimited file.
CSV 文件输入转换从分隔文件中读取数据。
The CSV label for this transform is a misnomer because you can define whatever separator you want to use, such as pipes, tabs, and semicolons; you are not constrained to using commas. Internal processing allows this transform to process data quickly. Options for this transform are a subset of the Text File Input transform.
此转换的 CSV 标签用词不当,因为您可以定义要使用的任何分隔符,例如管道、制表符和分号;您不必使用逗号。内部处理允许此转换快速处理数据。此转换的选项是文本文件输入转换的子集。
This transform has fewer overall options than the general Text File Input transform, but it has a few advantages over it:
与常规文本文件输入转换相比,此转换的总体选项较少,但与它相比,它有一些优点:
- NIO — Native system calls for reading the file means faster performance, but it is limited to only local files currently. No VFS support.
- NIO — 本机系统调用读取文件意味着更快的性能,但目前仅限于本地文件。不支持