l 采集网站
【场景描述】采集京东电视分类中的所有商品信息。
【使用工具】前嗅ForeSpider数据采集系统,免费版本下载链接:http://www.forenose.com/view/forespider/view/download.html
【入口网址】https://list.jd.com/list.html?cat=737,794,798&ev=4155_97865&sort=sort_rank_asc&trans=1&JL=3_%E7%94%B5%E8%A7%86%E7%B1%BB%E5%9E%8B_%E5%85%A8%E9%9D%A2%E5%B1%8F#J_crumbsBar
【采集内容】采集亚马逊搜索关键词搜索出来的商品信息,包括商品名称、价格、店铺和商品链接。
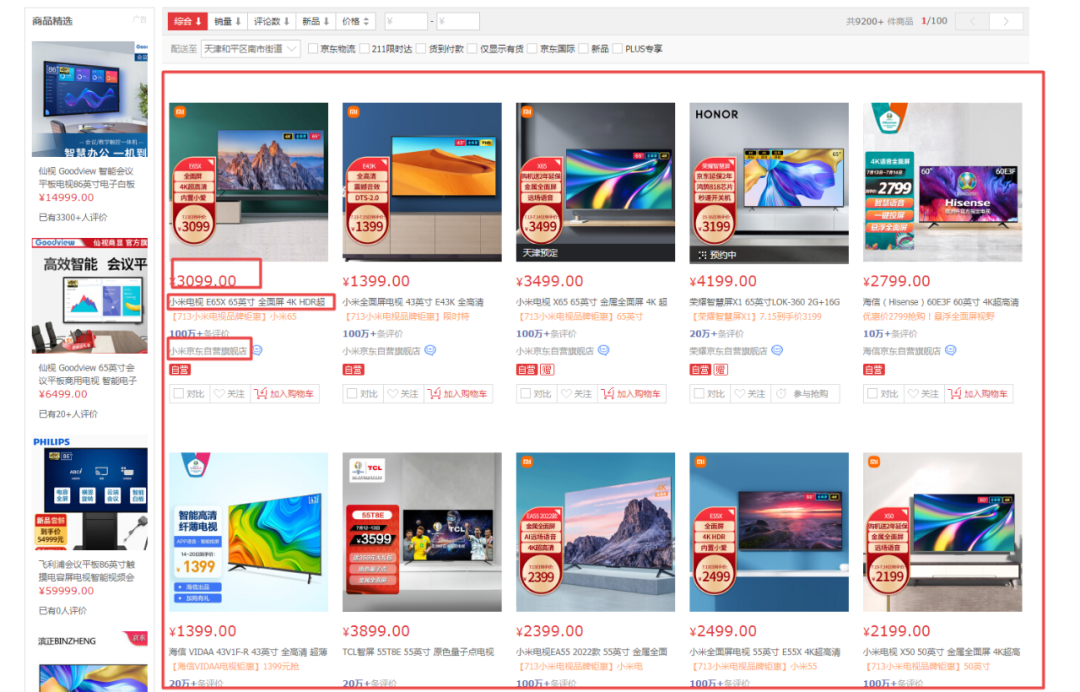
【采集效果】如下图所示:

l 思路分析
配置思路概览:

l 配置步骤
一. 新建采集任务
选择【采集配置】,点击任务列表右上方【+】号可新建采集任务,将采集入口地址填写在【采集地址】框中,【任务名称】自定义即可,点击下一步。
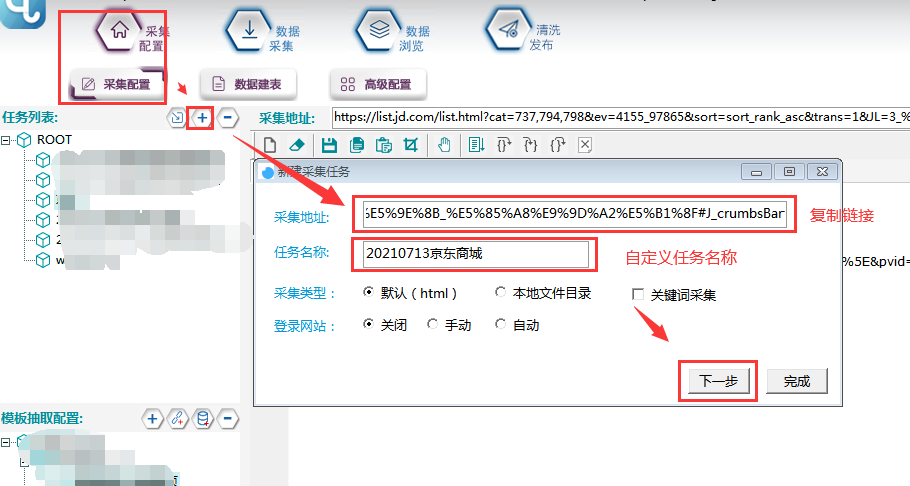
选择普通翻页,点击完成按钮,即创建任务完成。
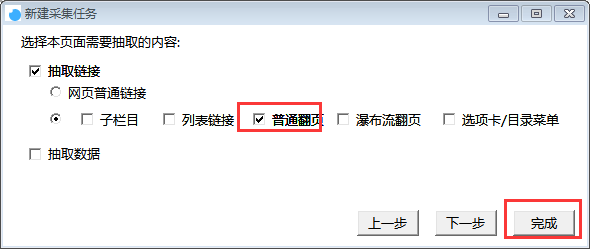
二. 商品翻页链接获取
1.在浏览器中点击第二页,第三页和第四页的翻页,将翻页链接复制出来,观察链接规律。

发现翻页链接规律为:
https://list.jd.com/list.html?cat=737%2C794%2C798&ev=4155_97865%5E&pvid=ebb0e3c519de4f649049b645a6598eed&page=+2*页码-1+&s=+5+(页码-2)*6+7&click=0
2.打开刚才新建的模板任务,选中翻页链接,打开脚本窗口,新建一个脚本。
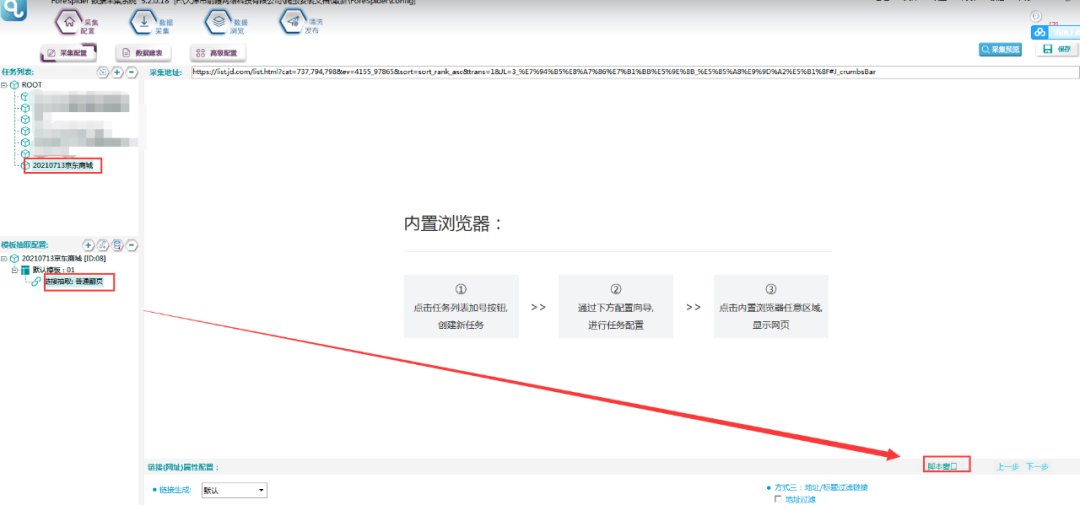
3.根据刚才发现的翻页规律,用脚本来拼翻页链接。具体如下所示:

脚本文本:
url u;//定义一个url
for(var i=1;i<=10;i++)//i表示页数,此时表示采集1-10页商品数据
{
var a=2*i-1;//定义a为2*页数-1
var b=5+(i-2)*6;//定义b为5+(页数-2)*6
u.urlname = "https://list.jd.com/list.html?cat=737%2C794%2C798&ev=4155_97865%5E&pvid=ebb0e3c519de4f649049b645a6598eed&page="+a+"&s="+b+"7&click=0";//根据翻页规律拼出翻页请求
u.title = URL.title+"#"+"第"+i+"页"; //返回链接名称为第i页
u.entryid = CHANN.id;
u.tmplid = 2; //关联模板2
RESULT.AddLink(u);
}
4.采集预览,复制任意一条翻页,在浏览器中打开,看是否为该页内容。

三.商品数据抽取
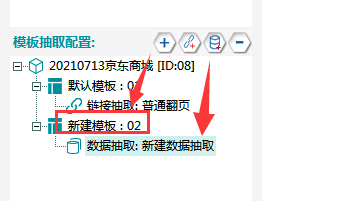
1.新建模板02,在模板02下建一个数据抽取,具体操作如下图所示。
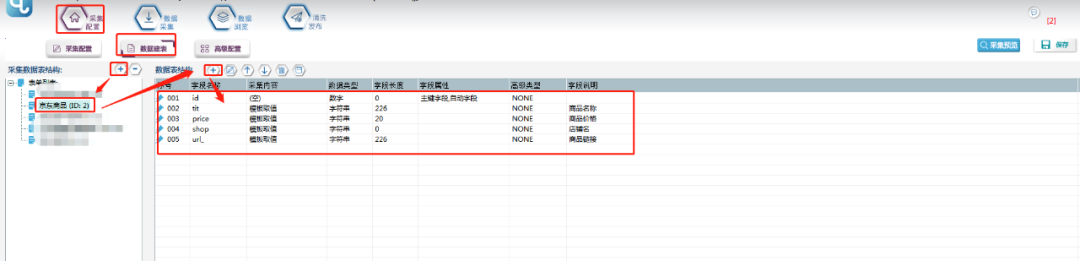
2.数据建表
点击图中加号,新建一个数据表,然后添加字段,各字段属性如下图所示:
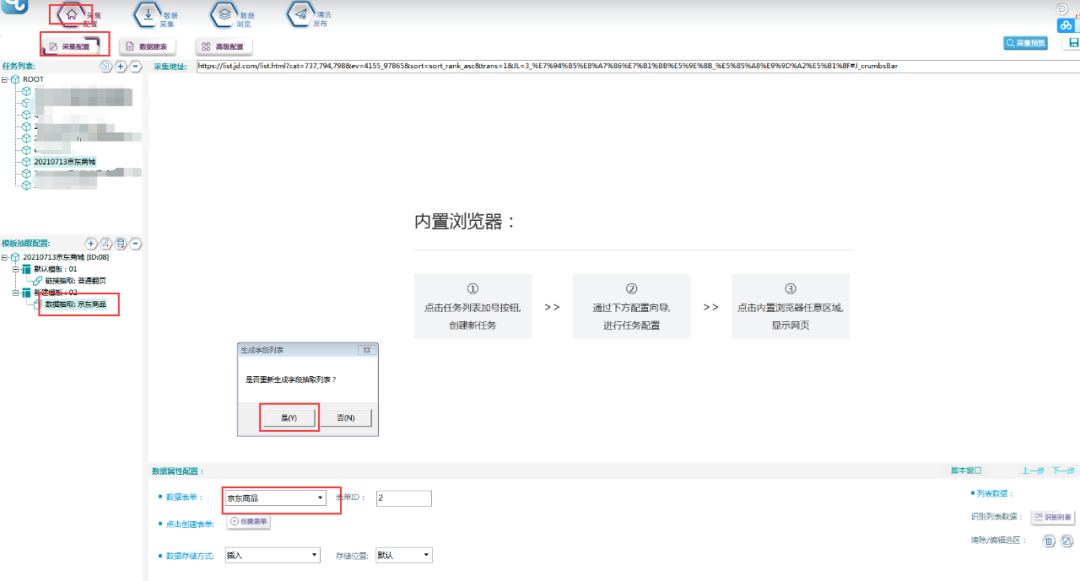
3.将新建好的数据表,关联到模板中去,如下图所示:
4.字段抽取
字段抽取使用脚本抽取的方法,在数据抽取模板中新建一个脚本窗口。
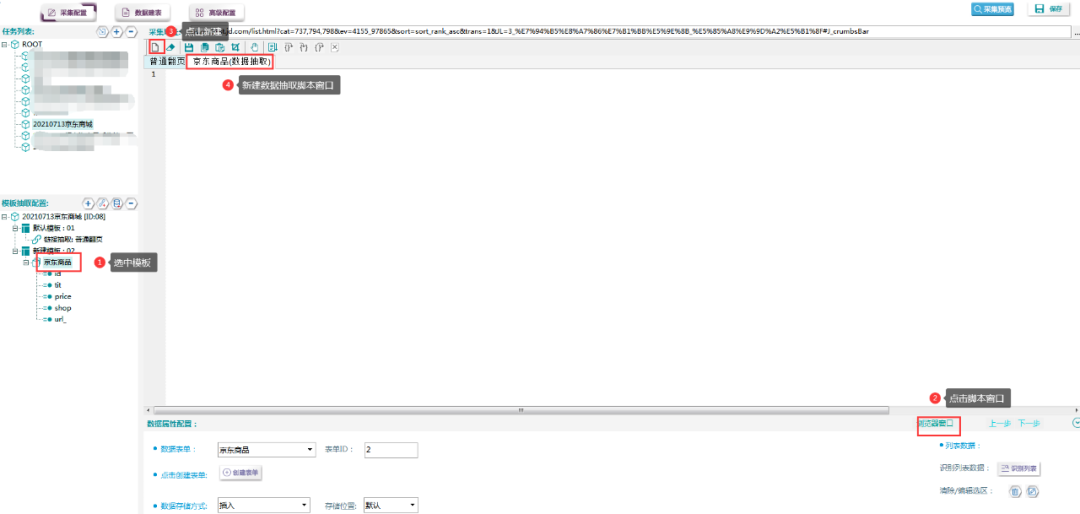
5.采集预览,复制一条翻页的链接,在浏览器中打开。
6.点击F12,点击指针(源码框左上角),让指针指到第一个商品处,在右侧源码中找到对应位置。
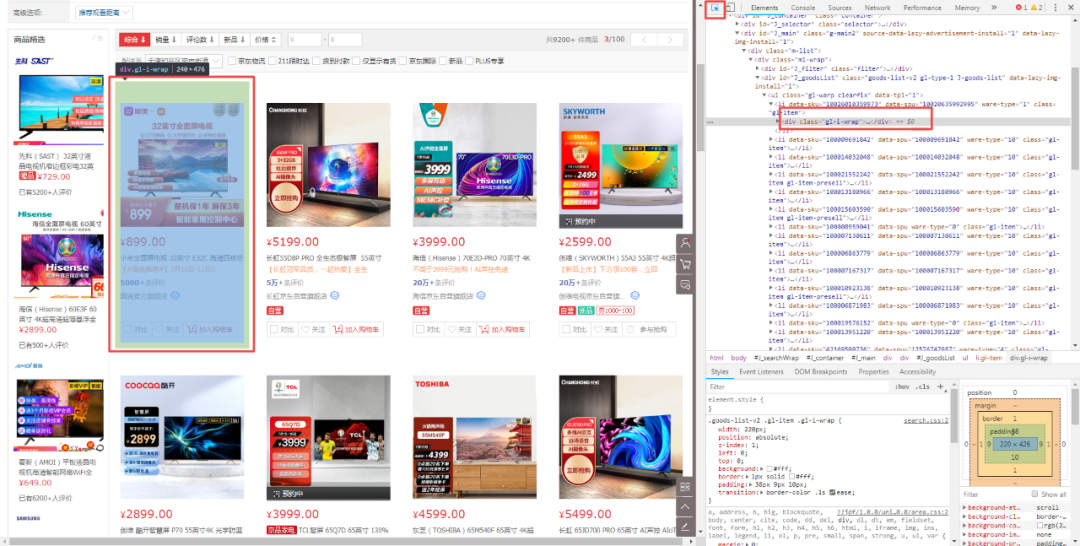
经观察发现,每个商品的内容在class为【gl-warp clearfix】的节点下的每个name为【li】的节点中。
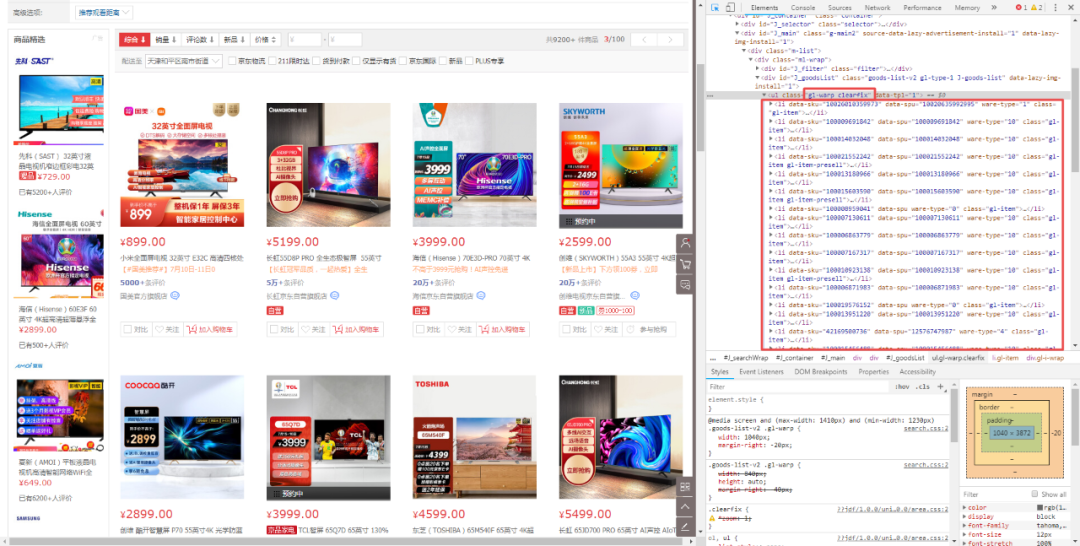
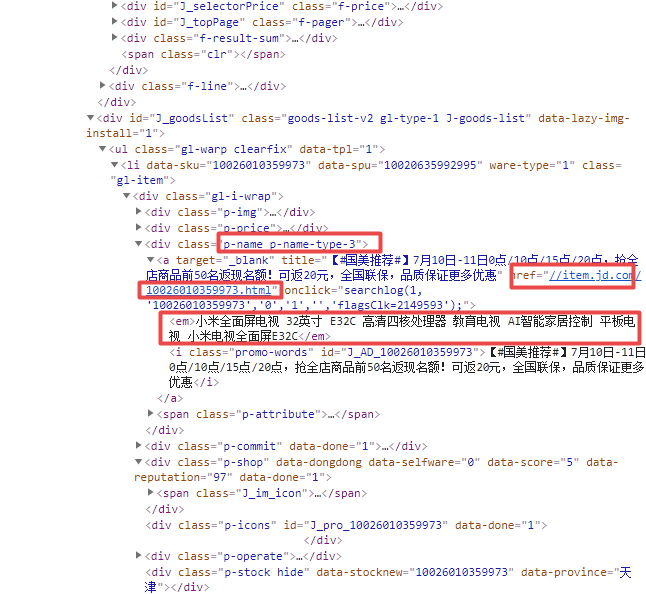
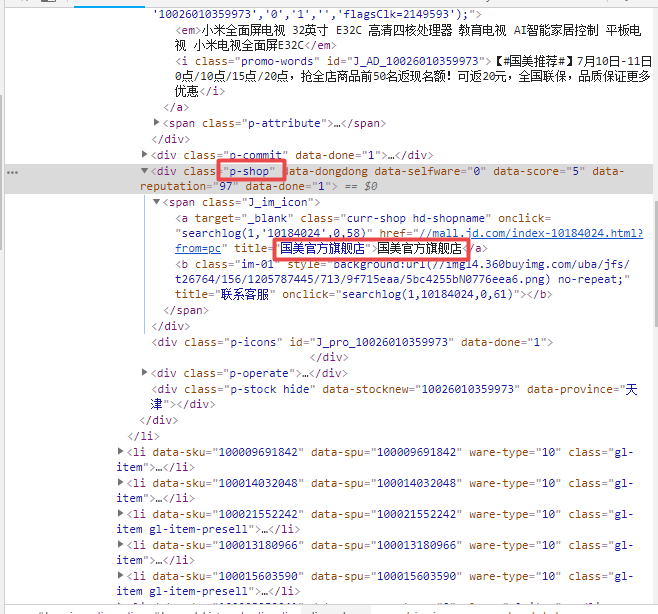
打开第一个商品的源码,发现class为【p-price】节点中有商品的价格,class为【p-name p-name-type-3】节点中有商品的名称和url,class为【p-shop】节点中有商品的店铺名。
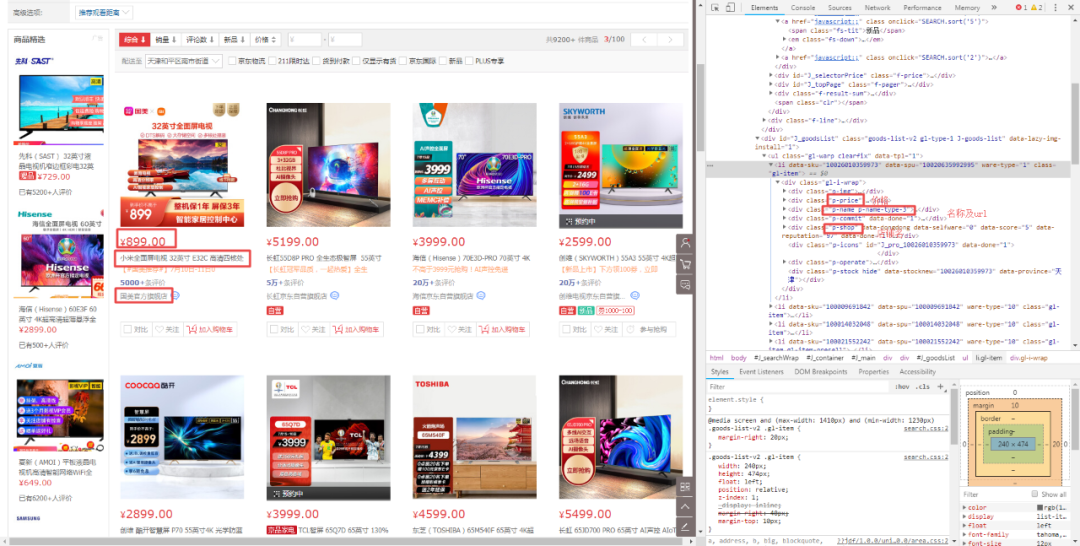
价格位置如下图所示:
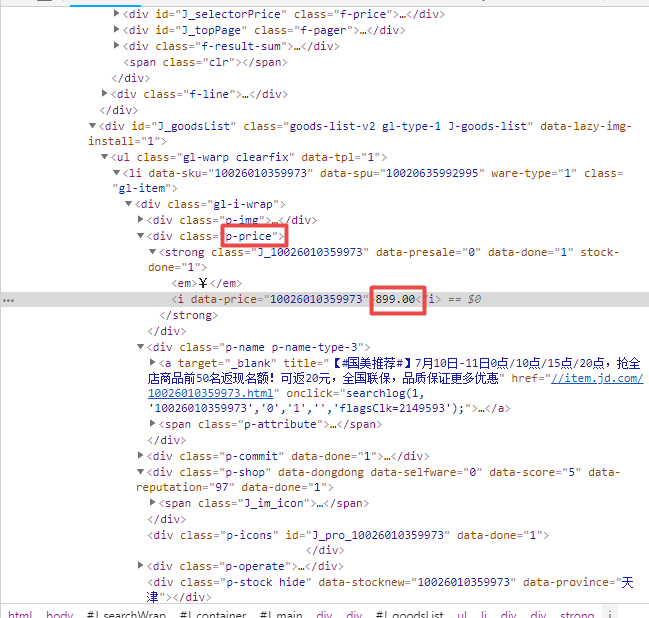
商品名称和url位置如下图所示:
商品店铺名位置如下图所示:
7.根据以上观察,编写数据抽取脚本,具体如下图所示:
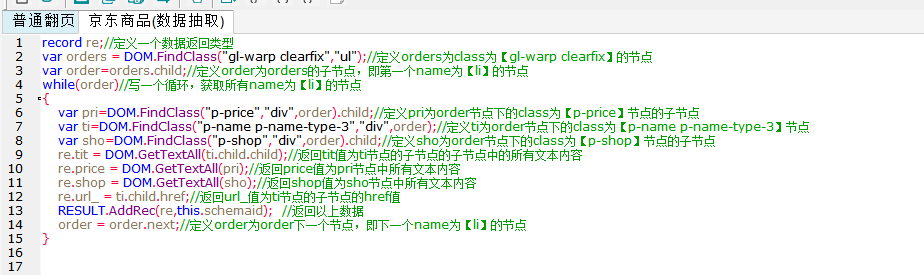
脚本文本如下所示:
record re;//定义一个数据返回类型
var orders = DOM.FindClass("gl-warp clearfix","ul");//定义orders为class为【gl-warp clearfix】的节点
var order=orders.child;//定义order为orders的子节点,即第一个name为【li】的节点
while(order)//写一个循环,获取所有name为【li】的节点
{
var pri=DOM.FindClass("p-price","div",order).child;//定义pri为order节点下的class为【p-price】节点的子节点
var ti=DOM.FindClass("p-name p-name-type-3","div",order);//定义ti为order节点下的class为【p-name p-name-type-3】节点
var sho=DOM.FindClass("p-shop","div",order).child;//定义sho为order节点下的class为【p-shop】节点的子节点
re.tit = DOM.GetTextAll(ti.child.child);//返回tit值为ti节点的子节点的子节点中的所有文本内容
re.price = DOM.GetTextAll(pri);//返回price值为pri节点中所有文本内容
re.shop = DOM.GetTextAll(sho);//返回shop值为sho节点中所有文本内容
re.url_ = ti.child.href;//返回url_值为ti节点的子节点的href值
RESULT.AddRec(re,this.schemaid); //返回以上数据
order = order.next;//定义order为order下一个节点,即下一个name为【li】的节点
}
8.采集预览
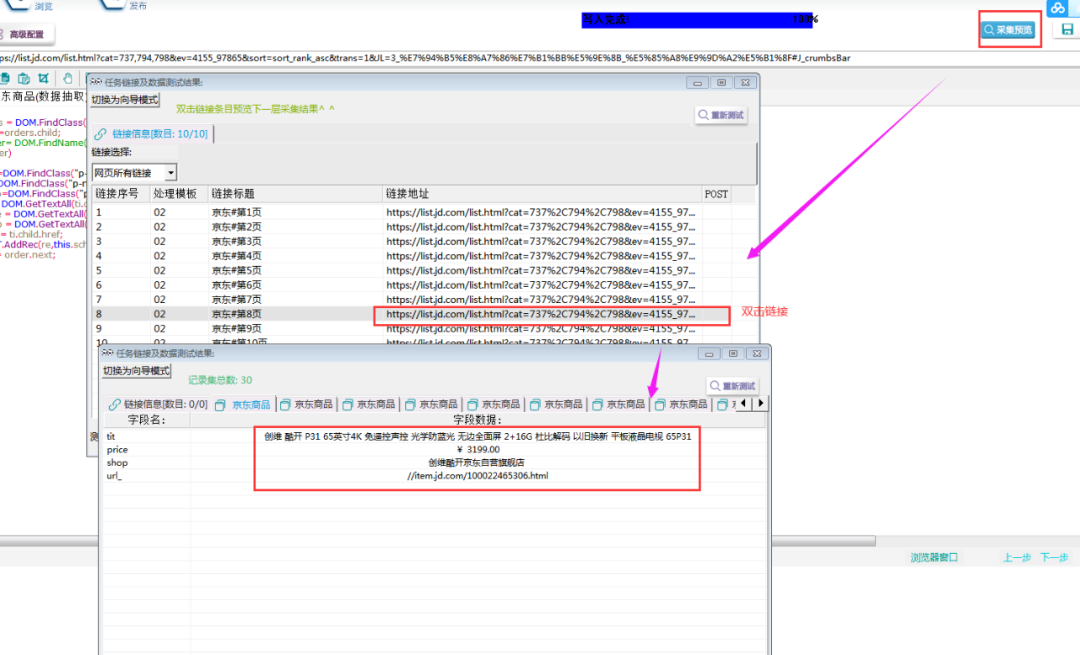
点击右上角采集预览,双击任意一条翻页链接,看是否采集到商品信息,如下图所示:
l 采集步骤
模板配置完成,采集预览没有问题后,进行数据采集。
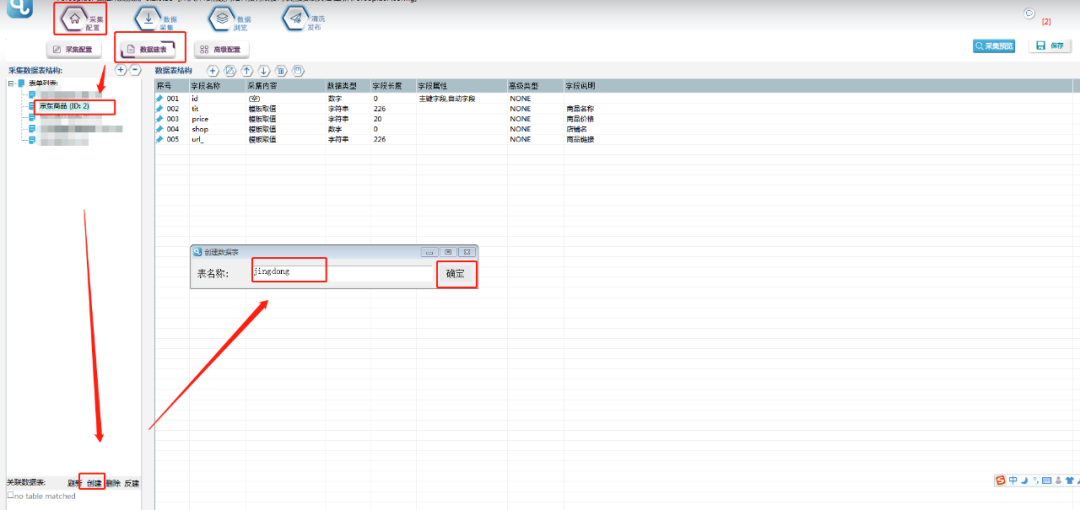
1.首先要建立采集数据表:
选择【数据建表】,点击【表单列表】中该模板的表单,在【关联数据表】中选择【创建】,表名称自定义,这里命名为【jingdong】(注意命名不能用数字和特殊符号),点击【确定】。
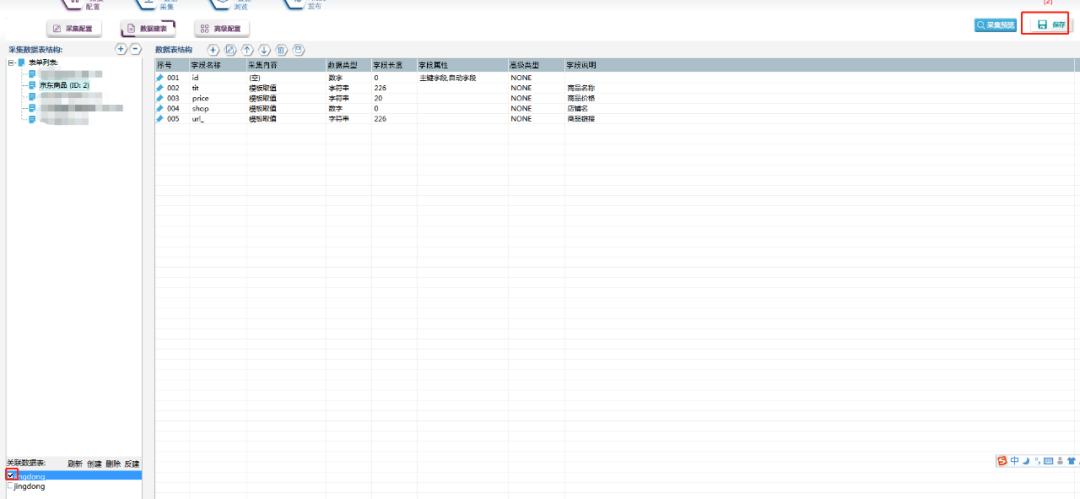
创建完成,勾选数据表。
2.选择【数据采集】,勾选任务名称,点击【开始采集】,则正式开始采集。
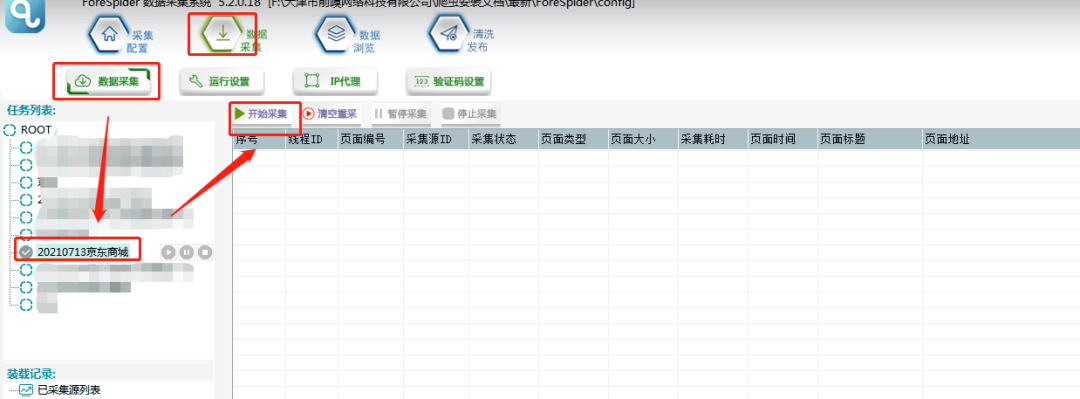
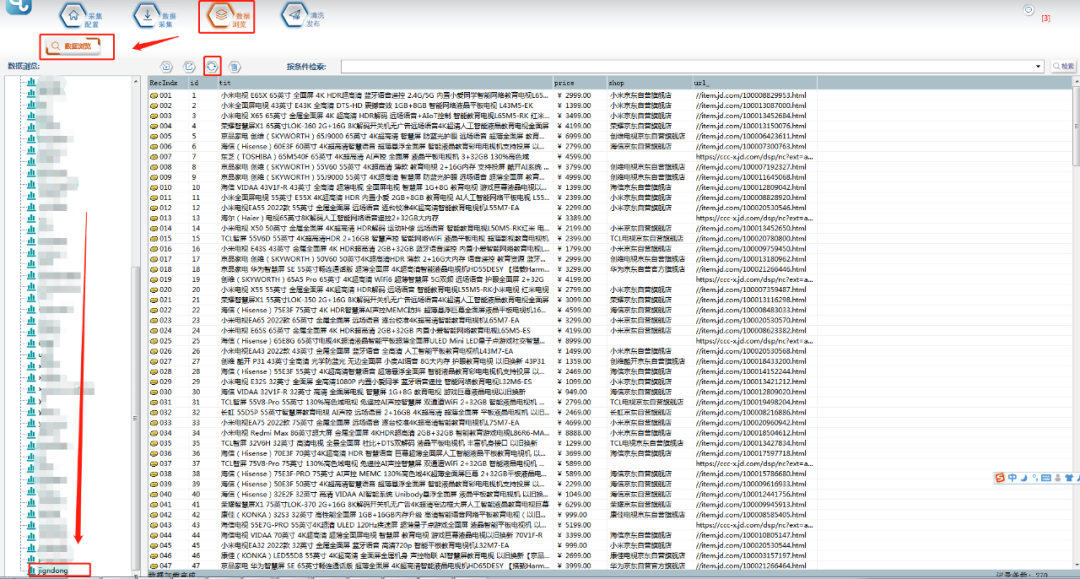
3.可以在【数据浏览】中,选择数据表查看采集数据,并可以导出数据。
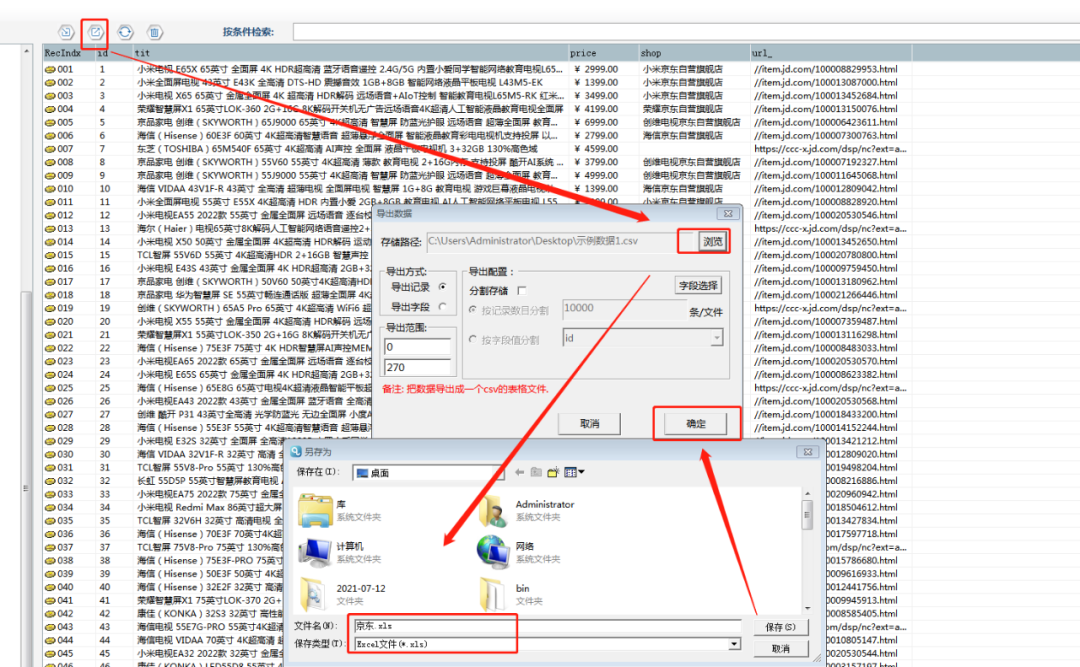
4.导出的文件打开如下图所示:
l 前嗅简介
前嗅大数据,国内领先的研发型大数据专家,多年来致力于为大数据技术的研究与开发,自主研发了一整套从数据采集、分析、处理、管理到应用、营销的大数据产品。前嗅致力于打造国内第一家深度大数据平台!