1 报错描述
在使用spark跑任务时,进度条突然停止,并且warning了,而且持续…
WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
2 分析&解决
翻译报错:初始作业未接受任何资源;请检查群集UI以确保工作进程已注册并且有足够的资源
ok,那么就从两个角度出发:
1、检查群集UI以确保工作进程已注册
2、有足够的资源
2.1集群节点未完全开启
如果开启的是集群模式的情况下,要保证三个节点的服务都是开启的状态。否则就会报错
在./spark-3.0.3-bin-hadoop3.2/sbin 目录下,重启!
./stop-all.sh
./start-all.sh
jps #查看
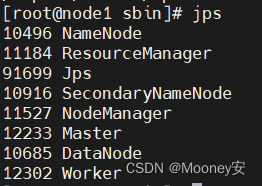
基本上问题可以解决啦~
2.2是spark节点内存不够了
内存可以在spark的配置文件—>spark-env.sh中可以看到。
文件目录: ./spark-3.0.3-bin-hadoop3.2/conf

进入后可以看到内存情况
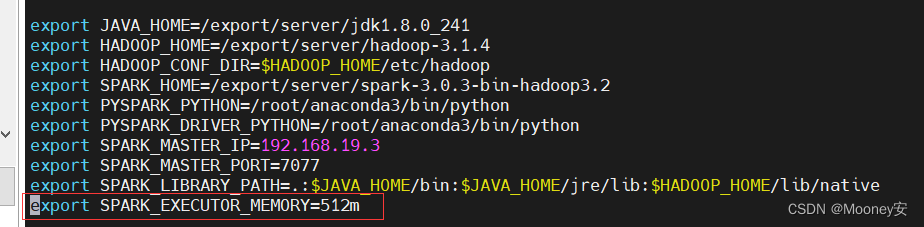
同时访问浏览器(前提是服务都起来了哈~)
http://192.168.19.3:8080/ 这个ip是我自己的master
大家可以使用你们的 master:8080 进行访问
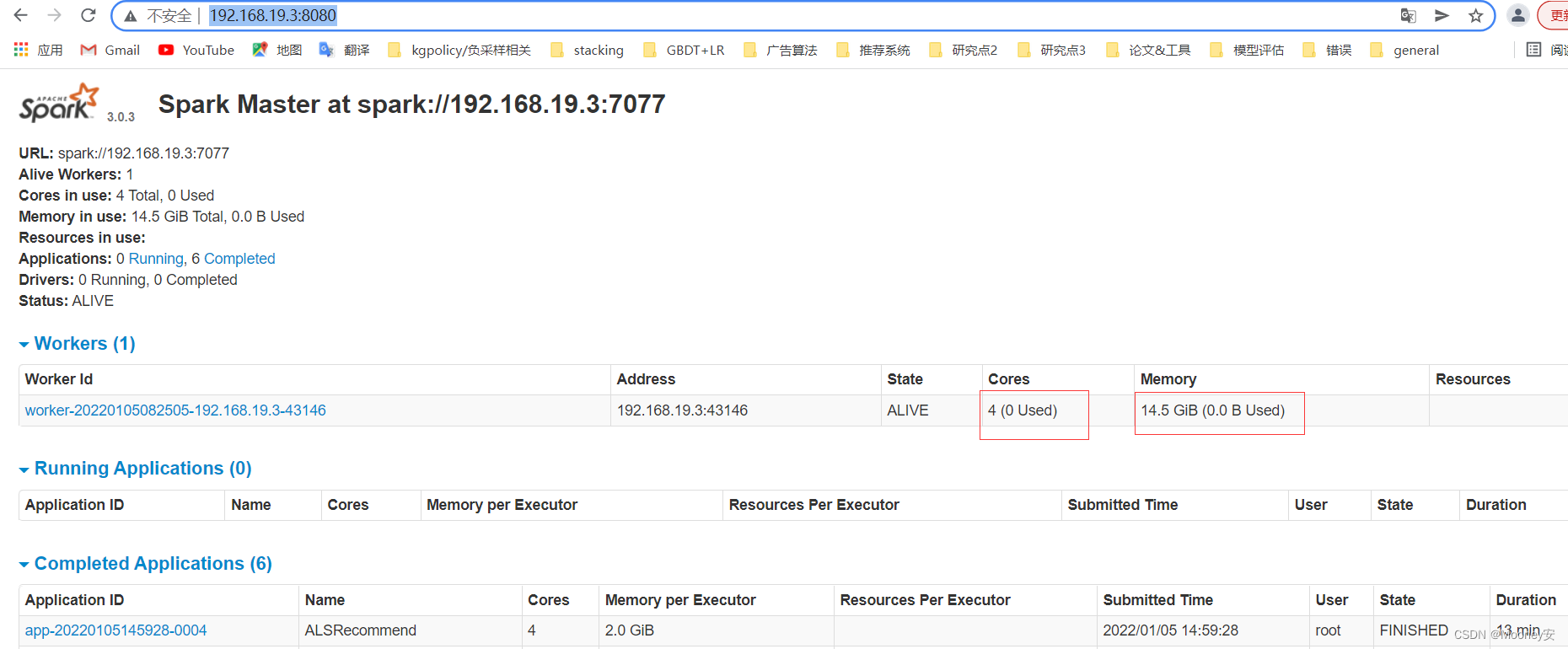
如果此时发现running模块,正在有一个进程占用,那么就找到原因了,把这个kill就行,再执行自己的
tips
也需要注意一下,自己使用的环境对不对。例如,我很久很久之前是在conda的base运行的代码,那么最好还是在这个环境下,实测之前忘记conda activate base 激活环境,然后直接运行时也报了这个错误,后面进入环境再运行就好啦~
good luck!