为什么要做持久化存储?
在k8s中部署的应用都是以pod容器的形式运行的,假如我们部署MySQL、Redis等数据库,需要对这些数据库产生的数据做备份。因为Pod是有生命周期的,如果pod不挂载数据卷,那pod被删除或重启后这些数据会随之消失,如果想要长久的保留这些数据就要用到pod数据持久化存储。
k8s支持那些持久化存储
[root@master1 ~]# kubectl explain pods.spec.volumes
常用的如下:
emptyDir、hostPath、nfs、persistenVolumeClaim、glusterfs、cephfs、configMap、secret
如果我们使用持久化存储,需要以下步骤:
- 定义pod的volume,这个volume要指明它关联到哪个存储上的
- 在容器中要使用volumemounts挂载对应的存储
emptyDir持久化存储
emptyDir是最基础的Volume类型。正如其名字所示,一个 emptyDir Volume是Host上的一个空目录。
emptyDir Volume对于容器来说是持久的,对于Pod则不是。当 Pod从节点删除时,Volume的内容也会被删除。但如果只是容器被销 毁而Pod还在,则Volume不受影响。
也就是说:emptyDir Volume的生命周期与Pod一致
Pod中的所有容器都可以共享Volume,它们可以指定各自的 mount路径。
这里我们模拟了一个producer-consumer场景。Pod有两个容器 producer和consumer,它们共享一个Volume。producer负责往Volume 中写数据,consumer则是从Volume读取数据。
① 文件最底部volumes定义了一个emptyDir类型的Volume shared- volume。
② producer容器将shared-volume mount到/producer_dir目录。
③ producer通过echo将数据写到文件hello里。
④ consumer容器将shared-volume mount到/consumer_dir目录。
⑤ consumer通过cat从文件hello读数据
[root@master1 emptydir]# cat emptydir.yaml
apiVersion: v1
kind: Pod
metadata:
name: producer-comsumer
spec:
containers:
- image: busybox
name: producer
volumeMounts:
- mountPath: /producer_dir
name: shared-volume
args:
- /bin/sh
- -c
- echo "hello world" > /producer_dir/hello ; sleep 3600
- image: busybox
name: comsumer
volumeMounts:
- mountPath: /comsumer_dir
name: shared-volume
args:
- /bin/sh
- -c
- cat /comsumer_dir/hello; sleep 3600
volumes:
- name: shared-volume
emptyDir: {}
[root@master1 emptydir]# kubectl apply -f emptydir.yaml
pod/producer-comsumer created
[root@master1 emptydir]# kubectl logs producer-comsumer comsumer
hello world
kubectl logs显示容器consumer成功读到了producer写入的数据, 验证了两个容器共享emptyDir Volume。
因为emptyDir是Docker Host文件系统里的目录,其效果相当于执 行了docker run -v/producer_dir和docker run -v /consumer_dir。通过 docker inspect查看容器的详细配置信息,我们发现两个容器都mount 了同一个目录,
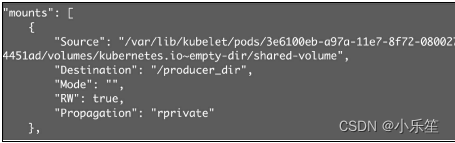
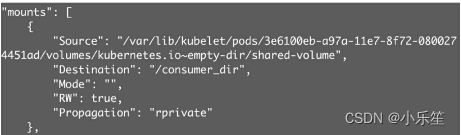
emptyDir是Host上创建的临时目录,其优点是能够方便地为Pod 中的容器提供共享存储,不需要额外的配置。它不具备持久性,如果 Pod不存在了,emptyDir也就没有了。根据这个特性,emptyDir特别 适合Pod中的容器需要临时共享存储空间的场景,比如前面的生产者 消费者用例
注意: 存储的卷一般在宿主机的/var/lib/kubelet/pods目录下
hostpath持久化存储
hostPath Volume的作用是将Docker Host文件系统中已经存在的目 录mount给Pod的容器。大部分应用都不会使用hostPath Volume,因为 这实际上增加了Pod与节点的耦合,限制了Pod的使用。不过那些需 要访问Kubernetes或Docker内部数据(配置文件和二进制库)的应用 则需要使用hostPath。
hostPath Volume是指Pod挂载宿主机上的目录或文件。 hostPath Volume使得容器可以使用宿主机的文件系统进行存储,hostpath(宿主机路径):节点级别的存储卷,在pod被删除,这个存储卷还是存在的,不会被删除,所以只要同一个pod被调度到同一个节点上来,在pod被删除重新被调度到这个节点之后,对应的数据依然是存在的。
查看hostpath的用法
[root@master1 ~]# kubectl explain pods.spec.volumes.hostPath
创建一个Pod,挂载HostPath存储卷
[root@master1 volume]# cat hostpath.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-hostpath
spec:
containers:
- name: test-nginx
image: nginx
volumeMounts:
- name: test-volume
mountPath: /test-nginx
- name: test-tomcat
image: tomcat
volumeMounts:
- name: test-volume
mountPath: /test-tomcat
volumes:
- name: test-volume
hostPath:
path: /data1
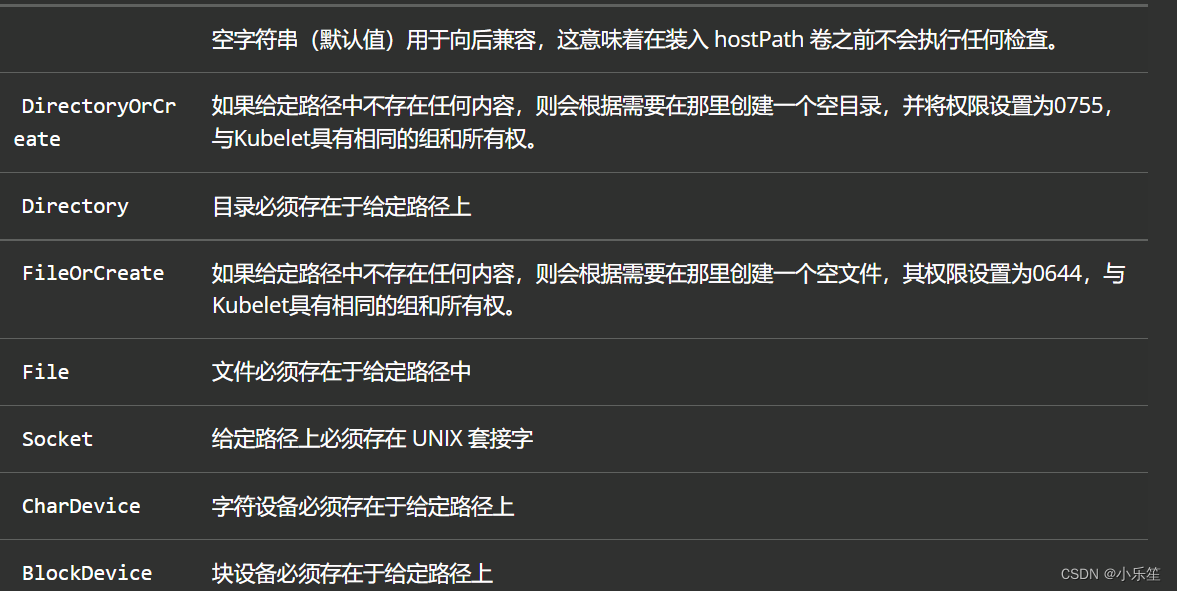
type: DirectoryOrCreate
注意:
DirectoryOrCreate表示本地有/data1目录,就用本地的,本地没有就会在pod调度到的节点自动创建一个
常见的type类型有:
[root@master1 volume]# kubectl apply -f hostpath.yaml
pod/test-hostpath created
[root@master1 volume]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-hostpath 2/2 Running 0 3m30s 10.1.104.12 node2 <none> <none>
[root@node2 ~]# ll /data1/
total 0
[root@node2 data1]# mkdir test
[root@node2 data1]# ls
test
[root@master1 ~]# kubectl exec -it test-hostpath -c test-nginx -- /bin/bash
root@test-hostpath:/# ls /test-nginx/
test
[root@master1 ~]# kubectl exec -it test-hostpath -c test-tomcat -- /bin/bash
root@test-hostpath:/usr/local/tomcat# ls /test-tomcat/
test
通过上面测试可以看到,同一个pod里的test-nginx和test-tomcat这两个容器是共享存储卷的。
hostpath存储卷缺点:
单节点
pod删除之后重新创建必须调度到同一个node节点,数据才不会丢失
NFS持久化存储
hostPath存储,存在单点故障,pod挂载hostPath时,只有调度到同一个节点,数据才不会丢失。那可以使用nfs作为持久化存储。
搭建的nfs服务器
[root@master1 ~]# yum install nfs-utils -y
# 创建共享目录
[root@master1 ~]# mkdir /data/volumes -p
# 配置nfs共享服务器上的/data/volumes目录
[root@master1 ~]# vim /etc/exports
/data/volumes 192.168.0.0/24(rw,no_root_squash)
#no_root_squash: 用户具有根目录的完全管理访问权限
#使NFS配置生效
[root@master1 ~]# exportfs -arv
exporting 192.168.0.0/24:/data/nfs_pro
[root@master1 ~]# systemctl restart nfs
[root@master1 ~]# systemctl enable nfs
在pod中使用nfs存储作为持久化存储
[root@master1 volume]# cat nfs.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-nfs-volume
spec:
containers:
- name: test-nfs
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: nginx-port
protocol: TCP
volumeMounts:
- name: nfs-volumes
mountPath: /usr/share/nginx/html
volumes:
- name: nfs-volumes
nfs:
path: /data/volumes
server: 192.168.0.180
[root@master1 volume]# kubectl apply -f nfs.yaml
pod/test-nfs-volume created
[root@master1 volume]# kubectl get pods -o wide | grep nfs
test-nfs-volume 1/1 Running 0 102s 10.1.166.166 node1 <none> <none>
[root@master1 volumes]# pwd
/data/volumes
[root@master1 volumes]# cat index.html
hello, Nice to meet you!
[root@master1 volume]# curl 10.1.166.166
hello, Nice to meet you!
通过上面可以看到,在共享目录创建的index.html已经被pod挂载了,nfs支持多个客户端挂载,可以创建多个pod,挂载同一个nfs服务器共享出来的目录;但是nfs如果宕机了,数据也就丢失了,所以需要使用分布式存储,常见的分布式存储有glusterfs和cephfs
PVC持久化存储
参考官网:
https://kubernetes.io/docs/concepts/storage/persistent-volumes/#access-modes
PV是什么?
PersistentVolume(PV)是群集中的一块存储,由管理员配置或使用存储类动态配置。 它是集群中的资源,就像pod是k8s集群资源一样。 PV是容量插件,如Volumes,其生命周期独立于使用PV的任何单个pod。
PVC是什么?
PersistentVolumeClaim(PVC)是一个持久化存储卷,我们在创建pod时可以定义这个类型的存储卷。 它类似于一个pod。 Pod消耗节点资源,PVC消耗PV资源。 Pod可以请求特定级别的资源(CPU和内存)。 pvc在申请pv的时候也可以请求特定的大小和访问模式(例如,可以一次读写或多次只读)。
特别说明:
PV是群集中的资源。 PVC是对这些资源的请求。
PV和PVC之间的相互作用遵循以下生命周期:
- pv的供应方式
- 绑定
用户创建pvc并指定需要的资源和访问模式。在找到可用pv之前,pvc会保持未绑定状态
- 常用访问模式(accessModes):
- ReadWriteOnce表示PV能以read-write模式mount到单个节点
- ReadOnlyMany表示PV能以read-only模式mount到多个节点
- ReadWriteMany表示PV能以read-write模式mount到多个节点。
- 使用
- 需要找一个存储服务器,把它划分成多个存储空间
- k8s管理员可以把这些存储空间定义成多个pv
- 在pod中使用pvc类型的存储卷之前需要先创建pvc,通过定义需要使用的pv的大小和对应的访问模式,找到合适的pv
- pvc被创建之后,就可以当成存储卷来使用了,我们在定义pod时就可以使用这个pvc的存储卷
- pvc和pv它们是一一对应的关系,pv如果被pvc绑定了,就不能被其他pvc使用了
- 我们在创建pvc的时候,应该确保和底下的pv能绑定,如果没有合适的pv,那么pvc就会处于pending状态
- 回收策略
当我们创建pod时如果使用pvc做为存储卷,那么它会和pv绑定,当删除pod,pvc和pv绑定就会解除,解除之后和pvc绑定的pv卷里的数据需要怎么处理,目前,卷可以保留,回收或删除
- Retain表示需要管理员手工回收
当删除pvc的时候,pv仍然存在,处于released状态,但是它不能被其他pvc绑定使用,里面的数据还是存在的,当我们下次再使用的时候,数据还是存在的,这个是默认的回收策略
- Recycle表示清除PV中的数据(不推荐使用,1.15可能被废弃了)
- Delete表示删除Storage Provider上的对应存储资源
删除pvc时即会从Kubernetes中移除PV,也会从相关的外部设施中删除存储资产
以nfs为存储服务器,使用pvc作为持久化存储卷
# 创建用于存储的的共享目录
[root@master1 volume]# mkdir /data/volume_test/v{1,2,3,4,5,6,7,8,9,10} -p
# 修改配置文件,实目录成为共享
[root@master1 volume]# cat /etc/exports
/data/volumes 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v1 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v2 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v3 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v4 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v5 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v6 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v7 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v8 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v9 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v10 192.168.0.0/24(rw,no_root_squash)
# 加载配置文件
[root@master1 volume]# exportfs -arv
exporting 192.168.0.0/24:/data/nfs_pro
exporting 192.168.0.0/24:/data/volume_test/v10
exporting 192.168.0.0/24:/data/volume_test/v9
exporting 192.168.0.0/24:/data/volume_test/v8
exporting 192.168.0.0/24:/data/volume_test/v7
exporting 192.168.0.0/24:/data/volume_test/v6
exporting 192.168.0.0/24:/data/volume_test/v5
exporting 192.168.0.0/24:/data/volume_test/v4
exporting 192.168.0.0/24:/data/volume_test/v3
exporting 192.168.0.0/24:/data/volume_test/v2
exporting 192.168.0.0/24:/data/volume_test/v1
exporting 192.168.0.0/24:/data/volumes
# 重启服务
[root@master1 volume]# systemctl restart nfs
[root@master1 volume]# cat pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: v1
spec:
capacity:
storage: 1Gi
accessModes: ["ReadWriteOnce"]
nfs:
path: /data/volume_test/v1
server: 192.168.0.180
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v2
spec:
capacity:
storage: 2Gi
accessModes: ["ReadWriteMany"]
nfs:
path: /data/volume_test/v2
server: 192.168.0.180
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v3
spec:
capacity:
storage: 3Gi
accessModes: ["ReadOnlyMany"]
nfs:
path: /data/volume_test/v3
server: 192.168.0.180
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v4
spec:
capacity:
storage: 4Gi
accessModes: ["ReadWriteOnce","ReadWriteMany"]
nfs:
path: /data/volume_test/v4
server: 192.168.0.180
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v5
spec:
capacity:
storage: 5Gi
accessModes: ["ReadWriteOnce","ReadWriteMany"]
nfs:
path: /data/volume_test/v5
server: 192.168.0.180
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v6
spec:
capacity:
storage: 6Gi
accessModes: ["ReadWriteOnce","ReadWriteMany"]
nfs:
path: /data/volume_test/v6
server: 192.168.0.180
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v7
spec:
capacity:
storage: 7Gi
accessModes: ["ReadWriteOnce","ReadWriteMany"]
nfs:
path: /data/volume_test/v7
server: 192.168.0.180
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v8
spec:
capacity:
storage: 8Gi
accessModes: ["ReadWriteOnce","ReadWriteMany"]
nfs:
path: /data/volume_test/v8
server: 192.168.0.180
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v9
spec:
capacity:
storage: 9Gi
accessModes: ["ReadWriteOnce","ReadWriteMany"]
nfs:
path: /data/volume_test/v9
server: 192.168.0.180
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v10
spec:
capacity:
storage: 10Gi
accessModes: ["ReadWriteOnce","ReadWriteMany"]
nfs:
path: /data/volume_test/v10
server: 192.168.0.180
[root@master1 volume]# kubectl apply -f pv.yaml
persistentvolume/v1 created
persistentvolume/v2 created
persistentvolume/v3 created
persistentvolume/v4 created
persistentvolume/v5 created
persistentvolume/v6 created
persistentvolume/v7 created
persistentvolume/v8 created
persistentvolume/v9 created
persistentvolume/v10 created
# #STATUS是Available,表示pv是可用的
[root@master1 volume]# kubectl get pv
v1 1Gi RWO Retain Available 54s
v10 10Gi RWO,RWX Retain Available 54s
v2 2Gi RWX Retain Available 54s
v3 3Gi ROX Retain Available 54s
v4 4Gi RWO,RWX Retain Available 54s
v5 5Gi RWO,RWX Retain Available 54s
v6 6Gi RWO,RWX Retain Available 54s
v7 7Gi RWO,RWX Retain Available 54s
v8 8Gi RWO,RWX Retain Available 54s
v9 9Gi RWO,RWX Retain Available 54s
[root@master1 volume]# cat pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes: ["ReadWriteMany"]
resources:
requests:
storage: 2Gi
[root@master1 volume]# kubectl apply -f pvc.yaml
persistentvolumeclaim/my-pvc created
[root@master1 volume]# kubectl get pv | grep v2
v2 2Gi RWX Retain Bound default/my-pvc 10m
[root@master1 volume]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
my-pvc Bound v2 2Gi RWX 87s
[root@master1 volume]# cat pod-pvc.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-pvc
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
volumeMounts:
- name: nginx-html
mountPath: /usr/share/nginx/html
volumes:
- name: nginx-html
persistentVolumeClaim:
claimName: my-pvc
[root@master1 volume]# kubectl apply -f pod-pvc.yaml
pod/pod-pvc created
[root@master1 volume]# kubectl get pods -o wide | grep pod-pvc
pod-pvc 1/1 Running 0 111s 10.1.166.167 node1 <none> <none>
[root@master1 v2]# pwd
/data/volume_test/v2
[root@master1 v2]# cat index.html
hello, test pv
[root@master1 v2]# curl 10.1.166.167
hello, test pv
pvc和pv绑定,如果使用默认的回收策略retain,那么删除pvc之后,pv会处于released状态,我们想要继续使用这个pv,需要手动删除pv,kubectl delete pv pv_name,删除pv,不会删除pv里的数据,当我们重新创建pvc时还会和这个最匹配的pv绑定,数据还是原来数据,不会丢失。
[root@master1 volume]# kubectl delete -f pod-pvc.yaml
pod "pod-pvc" deleted
[root@master1 volume]# kubectl delete -f pvc.yaml
persistentvolumeclaim "my-pvc" deleted
You have new mail in /var/spool/mail/root
[root@master1 volume]# kubectl apply -f pvc.yaml
persistentvolumeclaim/my-pvc created
[root@master1 volume]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
my-pvc Bound v4 4Gi RWO,RWX 4s
[root@master1 volume]# cat pv.yaml | grep persistentVolumeReclaimPolicy
persistentVolumeReclaimPolicy: Delete
[root@master1 volume]# kubectl apply -f pv.yaml
persistentvolume/v1 created
persistentvolume/v2 created
persistentvolume/v3 created
persistentvolume/v4 created
persistentvolume/v5 created
persistentvolume/v6 created
persistentvolume/v7 created
persistentvolume/v8 created
persistentvolume/v9 created
persistentvolume/v10 created
[root@master1 volume]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
v1 1Gi RWO Retain Available 6s
v10 10Gi RWO,RWX Retain Available 6s
v2 2Gi RWX Delete Available 6s
v3 3Gi ROX Retain Available 6s
v4 4Gi RWO,RWX Retain Available 6s
v5 5Gi RWO,RWX Retain Available 6s
v6 6Gi RWO,RWX Retain Available 6s
v7 7Gi RWO,RWX Retain Available 6s
v8 8Gi RWO,RWX Retain Available 6s
v9 9Gi RWO,RWX Retain Available 6s
[root@master1 volume]# kubectl apply -f pvc.yaml
persistentvolumeclaim/my-pvc created
[root@master1 volume]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
my-pvc Bound v2 2Gi RWX 4s
[root@master1 volume]# kubectl delete pvc my-pvc
persistentvolumeclaim "my-pvc" deleted
You have new mail in /var/spool/mail/root
[root@master1 volume]# kubectl delete pv v2
persistentvolume "v2" deleted
[root@master1 v2]# ls
index.html
[root@master1 volume]# kubectl apply -f pv.yaml
[root@master1 volume]# kubectl apply -f pvc.yaml
[root@master1 volume]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
my-pvc Bound v2 2Gi RWX 4s
从上面可以看到,即使pv和pvc删除了,也不会删除nfs共享目录下的数据,删除的过的v2pvc,再从重新生成新的pvc,还是会绑定到原来的v2上。持有原来的数据!
PV动态供给
动态供给是通过StorageClass实现的,StorageClass定义了如何创 建PV。
V和PVC模式都是需要先创建好PV,然后定义好PVC和pv进行一对一的Bond,但是如果PVC请求成千上万,那么就需要创建成千上万的PV,对于运维人员来说维护成本很高,Kubernetes提供一种自动创建PV的机制,叫StorageClass,它的作用就是创建PV的模板。k8s集群管理员通过创建storageclass可以动态生成一个存储卷pv供k8s pvc使用。
StorageClass会定义以下两部分:
1、PV的属性 ,比如存储的大小、类型等;
2、创建这种PV需要使用到的存储插件,比如Ceph、NFS等
有了这两部分信息,Kubernetes就能够根据用户提交的PVC,找到对应的StorageClass,然后Kubernetes就会调用 StorageClass声明的存储插件,创建出需要的PV。
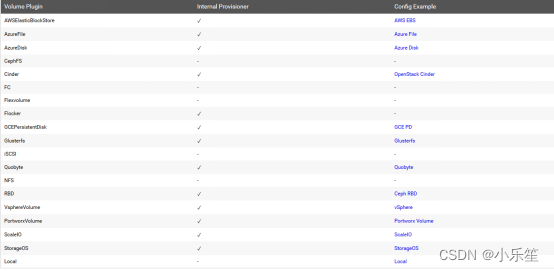
StorageClass的provisioner字段
storageclass需要有一个供应者,用来确定我们使用什么样的存储来创建pv,常见的provisioner如下:
provisioner既可以由内部供应商提供,也可以由外部供应商提供,如果是外部供应商可以参考https://github.com/kubernetes-incubator/external-storage/下提供的方法创建。
StorageClass的reclaimPolicy字段: 回收策略
- allowVolumeExpansion:允许卷扩展
- PersistentVolume 可以配置成可扩展 将此功能设置为true时,允许用户通过编辑相应的 PVC 对象来调整卷大小。当基础存储类的allowVolumeExpansion字段设置为 true 时,以下类型的卷支持卷扩展。
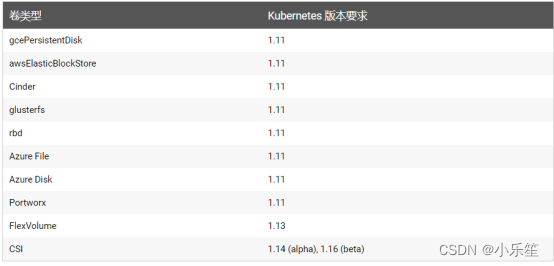
安装nfs provisioner,用于配合存储类动态生成pv
- 创建运行nfs-provisioner需要的sa( serviceaccount )账号
- 什么是sa?
serviceaccount是为了方便Pod里面的进程调用Kubernetes API或其他外部服务而设计的。
指定了serviceaccount之后,我们把pod创建出来了,我们在使用这个pod时,这个pod就有了我们指定的账户的权限了。
[root@master1 storageclass]# cat serviceaccount.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-provisioner
[root@master1 storageclass]# kubectl apply -f serviceaccount.yaml
serviceaccount/nfs-provisioner created
- 对 nfs-provisioner这个sa用户授权
[root@master1 storageclass]# kubectl create clusterrolebinding nfs-provisioner-clusterrolebinding --clusterrole=cluster-admin --serviceaccount=default:nfs-provisioner
# 创建提供sc自动创建pv的存储资源
[root@master1 storageclass]# mkdir /data/nfs_pro -p
[root@master1 storageclass]# cat /etc/exports
/data/nfs_pro 192.168.0.0/24(rw,no_root_squash)
[root@master1 storageclass]# exportfs -arv
exporting 192.168.0.0/24:/data/volumes
[root@master1 storageclass]# systemctl restart nfs
[root@master1 storageclass]# cat nfs-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-provisioner
spec:
selector:
matchLabels:
app: nfs-provisioner
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: nfs-provisioner
spec:
serviceAccount: nfs-provisioner
containers:
- name: nfs-provisioner
image: registry.cn-beijing.aliyuncs.com/mydlq/nfs-subdir-external-provisioner:v4.0.0
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: example.com/nfs
- name: NFS_SERVER
value: 192.168.0.180
- name: NFS_PATH
value: /data/nfs_pro
volumes:
- name: nfs-client-root
nfs:
server: 192.168.0.180
path: /data/nfs_pro
[root@master1 storageclass]# kubectl apply -f nfs-deployment.yaml
deployment.apps/nfs-provisioner created
[root@master1 storageclass]# kubectl get pods | grep nfs
nfs-provisioner-75c9ccfb8f-96b22 1/1 Running 0 40s
[root@master1 storageclass]# cat nfs-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs
provisioner: example.com/nfs # provisioner处写的example.com/nfs应该跟安装nfs provisioner时候的env下的PROVISIONER_NAME的value值保持一致,
[root@master1 storageclass]# kubectl apply -f nfs-storageclass.yaml
storageclass.storage.k8s.io/nfs created
- 创建pvc,通过storageclass动态生成pv
[root@master1 storageclass]# cat claim.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-claim
spec:
accessModes: ["ReadWriteMany"]
resources:
requests:
storage: 1Gi
storageClassName: nfs # 这里使用的是上一步创建的storageclass
[root@master1 storageclass]# kubectl apply -f claim.yaml
persistentvolumeclaim/test-claim created
[root@master1 storageclass]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
test-claim Bound pvc-49c4f612-8bca-462e-9648-654ac73ff5f1 1Gi RWX nfs 29s
通过上面可以看到test-claim1的pvc已经成功创建了,绑定的pv是pvc-49c4f612-8bca-462e-9648-654ac73ff5f1 ,这个pv是由storageclass调用nfs provisioner自动生成的。
步骤总结:
1、供应商:创建一个nfs provisioner
2、创建storageclass,storageclass指定刚才创建的供应商
3、创建pvc,这个pvc指定storageclass
- 创建pod,挂载storageclass动态生成的pvc:test-claim1
[root@master1 storageclass]# cat read-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: read-pod
spec:
containers:
- name: read-pod
image: nginx
volumeMounts:
- name: nfs-pvc
mountPath: /usr/share/nginx/html
restartPolicy: "Never"
volumes:
- name: nfs-pvc
persistentVolumeClaim:
claimName: test-claim
[root@master1 storageclass]# kubectl apply -f read-pod.yaml
pod/read-pod created
[root@master1 storageclass]# kubectl get pods -o wide | grep read
read-pod 1/1 Running 0 3m3s 10.1.104.19 node2 <none> <none>
[root@master1 default-test-claim-pvc-49c4f612-8bca-462e-9648-654ac73ff5f1]# pwd
/data/nfs_pro/default-test-claim-pvc-49c4f612-8bca-462e-9648-654ac73ff5f1
[root@master1 default-test-claim-pvc-49c4f612-8bca-462e-9648-654ac73ff5f1]# echo "this is test" > index.html
[root@master1 default-test-claim-pvc-49c4f612-8bca-462e-9648-654ac73ff5f1]# curl 10.1.104.19
this is test
Statefulset控制器
StatefulSet是为了管理有状态服务的问题而设计的
什么是有状态服务?
StatefulSet是有状态的集合,管理有状态的服务,它所管理的Pod的名称不能随意变化。数据持久化的目录也是不一样,每一个Pod都有自己独有的数据持久化存储目录。比如MySQL主从、redis集群等。
什么是无状态服务
RC、Deployment、DaemonSet都是管理无状态的服务,它们所管理的Pod的IP、名字,启停顺序等都是随机的。个体对整体无影响,所有pod都是共用一个数据卷的,部署的tomcat就是无状态的服务,tomcat被删除,在启动一个新的tomcat,加入到集群即可,跟tomcat的名字无关。
StatefulSet由以下几个部分组成:
- Headless Service:用来定义pod网路标识,生成可解析的DNS记录
- volumeClaimTemplates:存储卷申请模板,创建pvc,指定pvc名称大小,自动创建pvc,且pvc由存储类供应。
- StatefulSet:管理pod的
什么是Headless service?
Headless service不分配clusterIP,headless service可以通过解析service的DNS,返回所有Pod的dns和ip地址 (statefulSet部署的Pod才有DNS),普通的service,只能通过解析service的DNS返回service的ClusterIP。
- headless service会为service分配一个域名
service name.name spacename.svc.cluster.local
为什么要用headless service(没有service ip的service)?
在使用Deployment时,创建的Pod名称是没有顺序的,是随机字符串,在用statefulset管理pod时要求pod名称必须是有序的 ,每一个pod不能被随意取代,pod重建后pod名称还是一样的。因为pod IP是变化的,所以要用Pod名称来识别。pod名称是pod唯一性的标识符,必须持久稳定有效。这时候要用到无头服务,它可以给每个Pod一个唯一的名称。
为什么要用volumeClaimTemplate?
对于有状态应用都会用到持久化存储,比如mysql主从,由于主从数据库的数据是不能存放在一个目录下的,每个mysql节点都需要有自己独立的存储空间。而在deployment中创建的存储卷是一个共享的存储卷,多个pod使用同一个存储卷,它们数据是同步的,而statefulset定义中的每一个pod都不能使用同一个存储卷,这就需要使用volumeClainTemplate,当在使用statefulset创建pod时,volumeClainTemplate会自动生成一个PVC,从而请求绑定一个PV,每一个pod都有自己专用的存储卷。
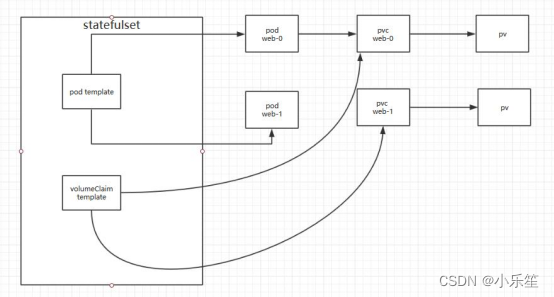
Statefulset使用案例
部署web站点
[root@master1 statefulset]# cat class-web.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-web
provisioner: example.com/nfs
[root@master1 statefulset]# kubectl apply -f class-web.yaml
storageclass.storage.k8s.io/nfs-web created
[root@master1 statefulset]# cat statefulset.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx
serviceName: "nginx"
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: "nfs-web"
resources:
requests:
storage: 1Gi
[root@master1 statefulset]# kubectl apply -f statefulset.yaml
service/nginx unchanged
statefulset.apps/web created
[root@master1 statefulset]# kubectl get statefulset -o wide
NAME READY AGE CONTAINERS IMAGES
web 2/2 2m17s nginx nginx
# 可以看见这个nginx service是没有ip的
[root@master1 statefulset]# kubectl get service -o wide | grep nginx
nginx ClusterIP None <none> 80/TCP 3m25s app=nginx
#可以看到创建的pod是有序的
[root@master1 statefulset]# kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 5m12s
web-1 1/1 Running 0 5m10s
[root@master1 statefulset]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
www-web-0 Bound pvc-1a16870f-1ce8-466e-95e7-83a9806e3632 1Gi RWO nfs-web 3d5h
www-web-1 Bound pvc-acc86b7d-ae3f-4d35-8972-01a652eb4ae6 1Gi RWO nfs-web 3d5h
[root@master1 statefulset]# kubectl get pods -l app=nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-0 1/1 Running 0 30m 10.1.104.20 node2 <none> <none>
web-1 1/1 Running 0 30m 10.1.104.15 node2 <none> <none>
[root@master1 ~]# kubectl exec -it web-0 -- /bin/bash
root@web-0:/# apt-get update
root@web-0:/# apt-get install -y dnsutils
root@web-0:/# nslookup web-0.nginx.default.svc.cluster.local
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: web-0.nginx.default.svc.cluster.local
Address: 10.1.104.20
root@web-0:/# nslookup web-1.nginx.default.svc.cluster.local
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: web-1.nginx.default.svc.cluster.local
Address: 10.1.104.15
root@web-0:/# nslookup nginx.default.svc.cluster.local
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: nginx.default.svc.cluster.local
Address: 10.1.104.20
Name: nginx.default.svc.cluster.local
Address: 10.1.104.15
通过上面可以看到可以成功解析出pod里
service 和headless service区别:
[root@master1 statefulset]# cat deploy-service.yaml
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
type: ClusterIP
ports:
- port: 80 #service的端口,暴露给k8s集群内部服务访问
protocol: TCP
targetPort: 80 #pod容器中定义的端口
selector:
run: my-nginx #选择拥有run=my-nginx标签的pod
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: busybox
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
command:
- sleep
- "3600"
[root@master1 statefulset]# kubectl apply -f deploy-service.yaml
service/my-nginx created
deployment.apps/my-nginx created
[root@master1 statefulset]# kubectl get svc -l run=my-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx ClusterIP 10.104.61.124 <none> 80/TCP 12s
[root@master1 statefulset]# kubectl get pods -l run=my-nginx
NAME READY STATUS RESTARTS AGE
my-nginx-68f486d49b-sxzjt 1/1 Running 0 17s
my-nginx-68f486d49b-trvbt 1/1 Running 0 17s
# 通过上面可以看到deployment创建的pod是随机生成的
[root@master1 statefulset]# kubectl exec -it web-1 -- /bin/bash
root@web-1:/# nslookup my-nginx.default.svc.cluster.local
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: my-nginx.default.svc.cluster.local
Address: 10.104.61.124 #解析的是service的ip地址
root@web-1:/# exit
Statefulset管理pod:扩容、缩容、更新
- 扩容
- 方法1: 修改配置文件statefulset.yaml里的replicas的值即可,原来replicas: 2,现在变成replicaset: 3
[root@master1 statefulset]# vim statefulset.yaml
[root@master1 statefulset]# kubectl apply -f statefulset.yaml
service/nginx unchanged
statefulset.apps/web configured
[root@master1 statefulset]# kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 95m
web-1 1/1 Running 0 95m
web-2 1/1 Running 0 15s
-
- 方法2: 直接编辑控制器实现扩容

[root@master1 statefulset]# kubectl edit sts web
statefulset.apps/web edited
[root@master1 statefulset]# kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 97m
web-1 1/1 Running 0 97m
web-2 1/1 Running 0 2m26s
web-3 1/1 Running 0 42s
-
缩容更扩容差不多,把数字改小就好了
-
Statefulset实现pod的更新
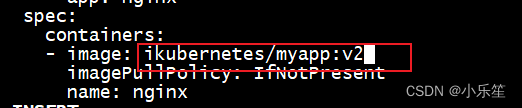
[root@master1 statefulset]# kubectl edit sts web
statefulset.apps/web edited
<none>
[root@master1 statefulset]# kubectl get sts -o wide
NAME READY AGE CONTAINERS IMAGES
web 4/4 103m nginx ikubernetes/myapp:v2
[root@master1 statefulset]# kubectl get pods -o wide -l app=nginx
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-0 1/1 Running 0 69s 10.1.104.18 node2 <none> <none>
web-1 1/1 Running 0 79s 10.1.104.21 node2 <none> <none>
web-2 1/1 Running 0 112s 10.1.166.173 node1 <none> <none>
web-3 1/1 Running 0 2m7s 10.1.104.14 node2 <none> <none>
DaemonSet概述
DaemonSet控制器能够确保k8s集群所有的节点都运行一个相同的pod副本,当向k8s集群中增加node节点时,这个node节点也会自动创建一个pod副本,当node节点从集群移除,这些pod也会自动删除;删除Daemonset也会删除它们创建的pod
DaemonSet工作原理:如何管理Pod?
daemonset的控制器会监听kuberntes的daemonset对象、pod对象、node对象,这些被监听的对象之变动,就会触发syncLoop循环让kubernetes集群朝着daemonset对象描述的状态进行演进。
Daemonset典型的应用场景
在集群的每个节点上运行存储,比如:glusterd 或 ceph。
在每个节点上运行日志收集组件,比如:flunentd 、 logstash、filebeat等。
在每个节点上运行监控组件,比如:Prometheus、 Node Exporter 、collectd等。
DaemonSet 与 Deployment 的区别
Deployment 部署的副本 Pod 会分布在各个 Node 上,每个 Node 都可能运行好几个副本。
DaemonSet 的不同之处在于:每个 Node 上最多只能运行一个副本。
资源清单文件编写技巧
查看定义Daemonset资源需要的字段有哪些?
[root@master1 ~]# kubectl explain daemonset
KIND: DaemonSet
VERSION: apps/v1
DESCRIPTION:
DaemonSet represents the configuration of a daemon set.
FIELDS:
apiVersion <string> #当前资源使用的api版本,跟VERSION: apps/v1保持一致
kind <string> #资源类型,跟KIND: DaemonSet保持一致
metadata <Object> #元数据,定义DaemonSet名字的
spec <Object> #定义容器的
status <Object> #状态信息,不能改
查看DaemonSet的spec字段如何定义?
[root@master1 ~]# kubectl explain ds.spec
KIND: DaemonSet
VERSION: apps/v1
RESOURCE: spec <Object>
DESCRIPTION:
The desired behavior of this daemon set. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
DaemonSetSpec is the specification of a daemon set.
FIELDS:
minReadySeconds <integer> #当新的pod启动几秒种后,再kill掉旧的pod。
revisionHistoryLimit <integer> #历史版本
selector <Object> -required- #用于匹配pod的标签选择器
template <Object> -required-
#定义Pod的模板,基于这个模板定义的所有pod是一样的
updateStrategy <Object> #daemonset的升级策略
#查看DaemonSet的spec.template字段如何定义?
#对于template而言,其内部定义的就是pod,pod模板是一个独立的对象
查看DaemonSet的spec字段如何定义?
[root@master1 ~]# kubectl explain daemonset.spec
KIND: DaemonSet
VERSION: apps/v1
RESOURCE: spec <Object>
DESCRIPTION:
The desired behavior of this daemon set. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
DaemonSetSpec is the specification of a daemon set.
FIELDS:
minReadySeconds <integer> #当新的pod启动几秒种后,再kill掉旧的pod。
revisionHistoryLimit <integer> #历史版本
selector <Object> -required- #用于匹配pod的标签选择器
template <Object> -required-
#定义Pod的模板,基于这个模板定义的所有pod是一样的
updateStrategy <Object> #daemonset的升级策略
查看DaemonSet的spec.template字段如何定义?
[root@master1 ~]# kubectl explain ds.spec.template
KIND: DaemonSet
VERSION: apps/v1
RESOURCE: template <Object>
FIELDS:
metadata <Object> # 定义pod的元数据
spec<Object> # 定义容器
日志收集案例实战
[root@master1 daemonset]# cat daemonset.yaml
apiVersion: apps/v1 # Daemonset使用api的版本
kind: DaemonSet # 资源类型
metadata:
name: fluentd-elasticsearch # 资源的名字
namespace: kube-system # 资源所在的名称空间:
labels:
k8s-app: fluentd-logging # 资源具有的标签
spec:
selector: # 标签选择器
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch # 基于模版,定义pod的标签
spec:
tolerations: # 定义容忍度
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers: #定义容器
- name: fluentd-elasticsearch
image: fluentd
imagePullPolicy: IfNotPresent
resources: # 容器的资源配额
requests:
cpu: 100m
memory: 200Mi
limits:
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log #把本地的/var/log/目录挂载到容器内
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true # 挂载目录制度权限
terminationGracePeriodSeconds: 30 #优雅关闭服务
volumes:
- name: varlog # 基于本地目录,创建一个卷
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
查看daemonset控制器的资源
[root@master1 daemonset]# kubectl apply -f daemonset.yaml
daemonset.apps/fluentd-elasticsearch unchanged
[root@master1 daemonset]# kubectl get ds -n kube-system | grep fluentd-elasticsearch
fluentd-elasticsearch 3 3 3 3 3 <none> 65s
[root@master1 daemonset]# kubectl get pods -n kube-system -o wide | grep fluentd
fluentd-elasticsearch-9nttl 1/1 Running 0 2m59s 10.1.137.100 master1 <none> <none>
fluentd-elasticsearch-fb4cb 1/1 Running 0 2m59s 10.1.166.158 node1 <none> <none>
fluentd-elasticsearch-lkn7v 1/1 Running 0 2m59s 10.1.104.2 node2 <none> <none>
通过上面可以看到在k8s的三个节点均创建了fluentd这个pod
pod的名字是由控制器的名字-随机数组成的
daemonset的滚动更新
查看滚动更新的字段定义
[root@master1 ~]# kubectl explain ds.spec.updateStrategy.rollingUpdate
KIND: DaemonSet
VERSION: apps/v1
RESOURCE: rollingUpdate <Object>
DESCRIPTION:
Rolling update config params. Present only if type = "RollingUpdate".
Spec to control the desired behavior of daemon set rolling update.
FIELDS:
maxUnavailable <string>
上面表示rollingUpdate更新策略只支持maxUnavailabe,先删除在更新;因为我们不支持一个节点运行两个pod,因此需要先删除一个,在更新一个。
[root@master1 daemonset]# kubectl set image daemonsets fluentd-elasticsearch fluentd-elasticsearch=ikubernetes/filebeat:5.6.6-alpine -n kube-system
daemonset.apps/fluentd-elasticsearch image updated