以下需要一些html, css, mysql,python,bootstrap基础
python爬虫+数据分析
准备:在pycharm(python的开发环境,需下载)该项目下下载相应需要的包 代码有:
import re
from bs4 import BeautifulSoup
import urllib.request, urllib.error
import xlwt
import pymysql
1.定义爬取指定网页(按F12查看)的访问路径函数

def askURL(url):
headers = {
"User-Agent": "Mozilla / 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit / 537.36 (KHTML, like Gecko) Chrome / 92.0.4515.159 Safari / 537.36"
}
request = urllib.request.Request(url, headers=headers)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except Exception as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
2.定义获取数据,传入基本路径参数,在该路径下爬取需要的数据(即解析数据),这里获取了电影的
"电影详情链接", "图片链接", "影片中文名", "影片英文名", "评分", "评价数", "概述", "相关信息"
利用python对这些信息进行处理,详情如下:
def getData(baseurl):
datalist = []
for i in range(0, 10):
url = baseurl + str(i * 25)
html = askURL(url)
# 解析数据
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"):
data = [] # 保存一部电影的信息
item = str(item)
# 影片详情链接
link = re.findall(findLink, item)[0]
data.append(link)
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc)
titles = re.findall(findTitle, item)
if len(titles) == 2:
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "")
data.append(otitle)
else:
data.append(titles[0])
data.append(' ') # 留空外文名
rating = re.findall(findRating, item)[0]
data.append(rating)
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum)
inq = re.findall(findInq, item)
if len(inq) != 0:
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(" ")
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', " ", bd)
bd = re.sub('/', " ", bd)
data.append(bd.strip()) # 去除前后空格
datalist.append(data) # 处理好一部电影信息
print(datalist)
return datalist
3.保存数据(我已经在PyCharm里连接了数据库(MySQL))
def saveDataDB(datalist):
conn = pymysql.connect(host='localhost', user='用户名', password='密码', database='数据库名')
cur = conn.cursor()
for data in datalist:
for index in range(len(data)):
data[index] = '"' + data[index] + '"'
sql = '''
insert into movie250 (
info_link, pic_link, cname, ename, score, rated, introduction, info)
values(%s)'''%",".join(data)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
4.主函数(可以存在数据库也可以是excel表里)
def main():
baseurl = "https://movie.douban.com/top250?start=" # 基本路径
datalist = getData(baseurl) #爬取250部电影的全部数据
saveDataDB(datalist) #保存到我连接的mysql数据库中
# savepath = "豆瓣电影Top250.xls" #保存数据直接放在excel表里
# saveData(datalist, dbpath) #保存到excel表里
附存在excel表操作函数:
def saveData(datalist, savepath):
print("save....")
book = xlwt.Workbook(encoding="utf-8", style_compression=0)
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True)
col = ("电影详情链接", "图片链接", "影片中文名", "影片英文名", "评分", "评价数", "概述", "相关信息")
for i in range(0, 8):
sheet.write(0, i, col[i])
for i in range(0, 250):
print("第%d条" % i)
data = datalist[i]
for j in range(0, 8):
sheet.write(i+1, j, data[j])
book.save(savepath)
至此爬取和数据分析就完成了,可以在数据库可视化界面(Navicat数据库可视化界面)查看:
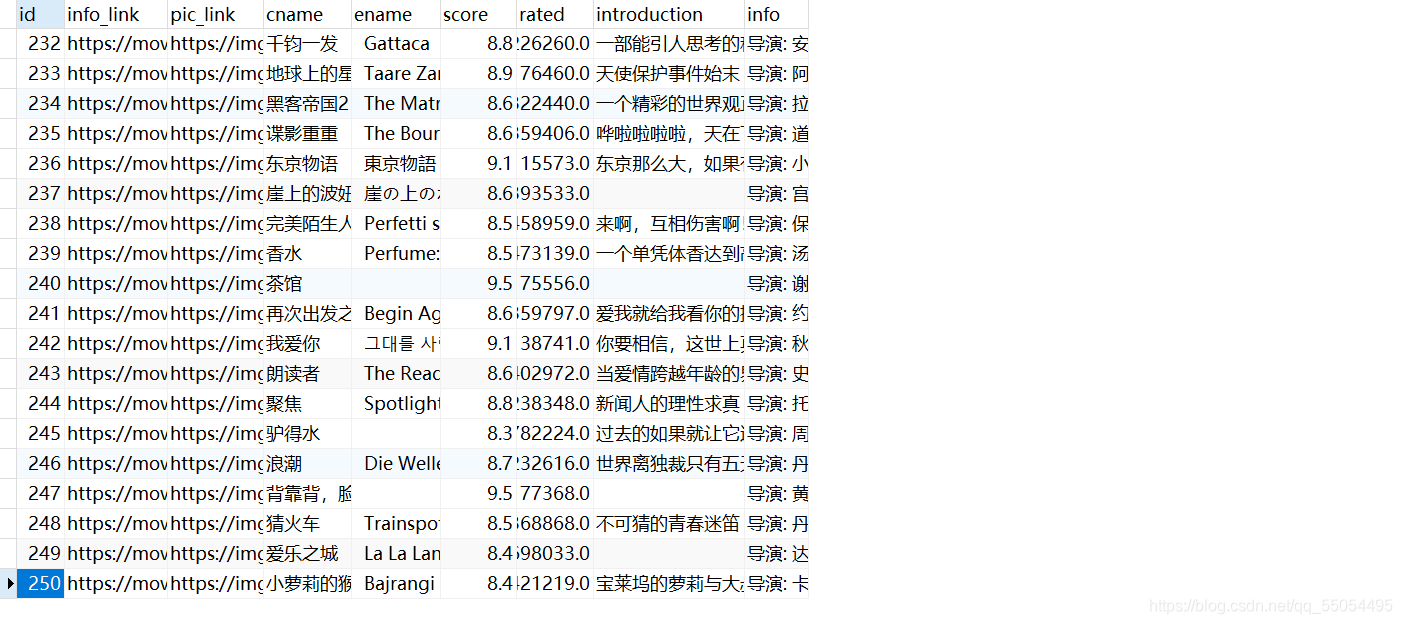
数据可视化Bootstrap(Bootstrap 是全球最受欢迎的前端组件库,用于开发响应式布局、移动设备优先的 WEB 项目 百度百科解释)就是直接用他已经写好封装后的组件,不需要我们写太多的css和js,十分方便,他还有一个好的地方就是响应式布局
首页界面效果:


电影界面:

评分界面:

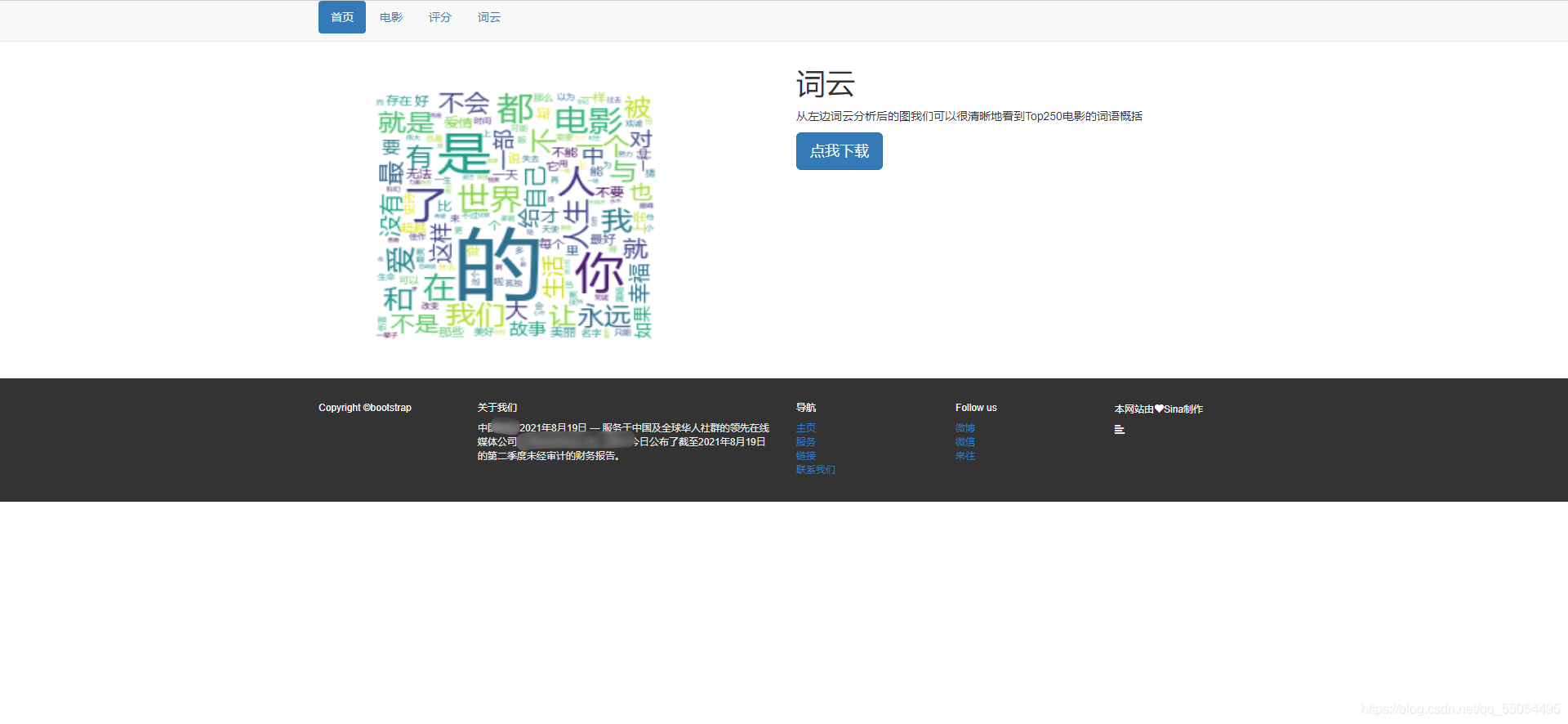
词云界面:
 第一篇博客(有点子认真写的,悄咪咪 暑假闲没事儿在某站学了点爬虫和bootstrap基础,也是方便以后自己
第一篇博客(有点子认真写的,悄咪咪 暑假闲没事儿在某站学了点爬虫和bootstrap基础,也是方便以后自己
复习啦!!
还有echarts,词云,以及如何拿数据到前端的操作下一篇
再见~mua~
给个赞再走呗Z~Z