目录
1 绪论
1.1 引言
近些年来,随着信息技术的发展、互联网的兴起以及智能手机的普及,人们可以获取信息的形式变得越来越多样化,例如文字、图像、音频、视频等等。在如此纷繁错杂的信息表现形式中,图像及包含图像内容的视频,因其直观、对真实世界的还原度高、储存媒介多等特点而逐渐成为人们日常获取信息的主要形式。
1.2 研究背景
在人工智能浪潮的大背景下,深度学习技术发展非常迅猛,利用计算机对图像进行分析和处理的能力越来越强。国内外研究学者对多尺度物体目标检测的研究越来越青睐,多尺度目标检测已经成为计算机视觉领域的一大热点研究问题。
传统的目标检测方法中,多尺度形变部件模型(Deformable Part Model,简称DPM)表现非常优秀,连续获得VOC(Visual Object Class)2007到2009的检测冠军。
后来,随着深度学习的发展,目标检测问题逐渐尝试采用深度学习的方法来处理,很多之前研究传统目标检测算法的研究者也开始转向深度学习。但是,基于深度学习的目标检测发展起来后,其实效果也一直表现平平。在VOC 2007测试集上的mAP只能30%多一点,OverFeat在ILSVRC 2013测试集上的mAP只能达到24.3%。
2013年R-CNN(Region-based Convolutional Neural Networks)的诞生使基于深度学习的目标检测进入了一个全新的时期,R-CNN在VOC 2007测试集的mAP达到48%。此后R-CNN的作者Ross Girshick连续推出了Fast R-CNN、Faster R-CNN,受Ross Girshick启发许多基于深度学习的目标检测算法被提出。
1.3 研究意义
多尺度目标检测是计算机视觉、模式识别和图像处理领域中最活跃的研究主题之一,其核心是利用计算机视觉技术分类、识别图像或视频中的目标并对其内容进行识别与描述。
目标检测是大量高级视觉任务的必备前提,包括活动或事件识别、场景内容理解等。而且目标检测也被应用到很多实际任务,例如高级驾驶辅助系统(ADAS)、图像检索、机器人导航和增强现实等。目标检测对计算机视觉领域和实际应用具有重要意义,在过去几十年里激励大批研究人员密切关注并投入研究。而且随着强劲的机器学习理论和特征分析技术的发展,近几年目标检测课题相关的研究活动有增无减,每年甚至每个月都有最新的研究成果和实际应用发表和公布。
1.4 目前存在的问题
由于图像或视频采集过程中很容易受到环境的影响,例如光照变化、局部遮挡、目标尺度变化等,使得要检测的目标发生形状上的变化,从而导致检测失败;此外,同样类型的目标物体形状可能会有很大差异,不同类型的目标物体的形状差异可能较小,这也给运动目标检测和识别带来了很大的挑战。
截至调研时,目标检测算法在VOC2012数据集上的m-AP只有88.6%[1],如下图所示。
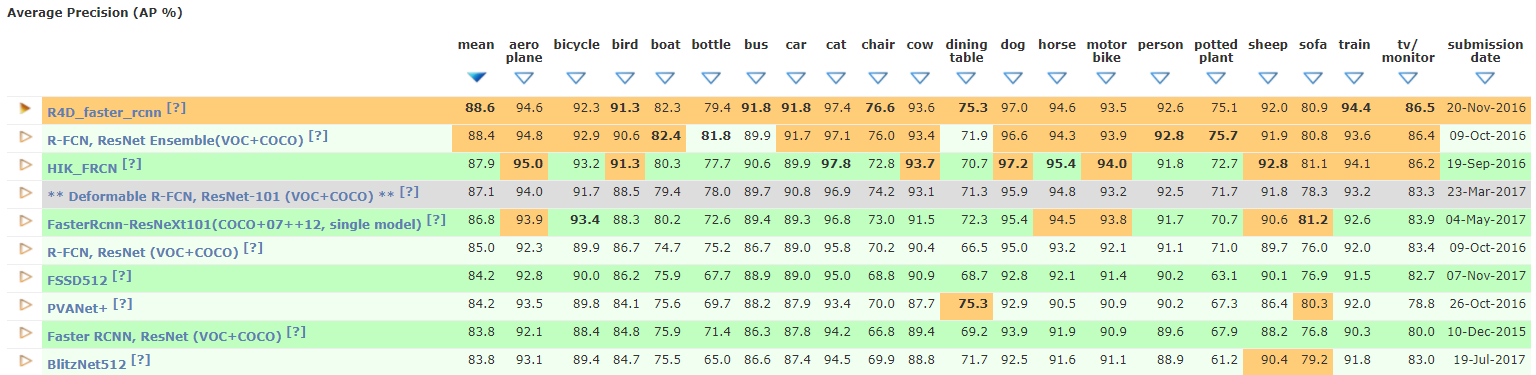
图1.1 VOC2012 m-AP排行榜
当目标检测应用于自动驾驶等场景下时,对准确率的要求极高,容不得如此大的错误率,可以看出,当前方法的检测准确率仍然较低而不能应用于实际通用的检测任务。因此,目标检测尤其是多尺度目标检测还远未被完美解决,仍旧是重要的并且充满挑战性的研究课题。
2 传统目标检测方法
2.1 HOG+SVM
2.1.1 简介
方向梯度直方图(Histogram of Oriented Gradient,简称HOG)是应用在计算机视觉和图像处理领域,用于目标检测的特征描述子。这项技术是用来计算局部图像梯度的方向信息的统计值。HOG特征结合SVM分类器已经被广泛应用于目标检测中,尤其在行人检测中获得了极大的成功。
其作者Navneet Dalal和Bill Triggs是法国国家计算机技术和控制研究所(INRIA)的研究员,他们在2005年的CVPR上首先发表了描述方向梯度直方图的论文[2]。在这篇论文里,他们主要是将这种方法应用在静态图像中的行人检测上,但在后来,他们也将其应用在影片中的行人检测,以及静态图像中的车辆和常见动物的检测。
2.1.2 检测流程
HOG算法流程描述如下:
(1)灰度化;
(2)标准化gamma空间;
(3)计算图像每个像素的梯度(包括大小和方向);
(4)将图像分割为小的Cell单元格;
(5)为每个单元格构建梯度方向直方图;
(6)把单元格组合成大的块(block),块内归一化梯度直方图;
(7)将所有“块”的HOG描述符组合在一起,生成HOG特征描述向量。
流程图如下图所示:

图2.1 HOG算法检测流程图
2.2 DPM
2.2.1 简介
DPM算法[3]由Felzenszwalb于2008年提出,是一种基于部件的检测方法,对目标的形变具有很强的鲁棒性。目前DPM已成为众多分类、分割、姿态估计等算法的核心部分,Felzenszwalb本人也因此被VOC授予“终身成就奖”。
DPM算法采用了改进后的HOG特征,SVM分类器和滑动窗口(Sliding Windows)检测思想,针对目标的多视角问题,采用了多组件(Component)的策略,针对目标本身的形变问题,采用了基于图结构(Pictorial Structure)的部件模型策略。此外,将样本的所属的模型类别,部件模型的位置等作为潜变量(Latent Variable),采用多示例学习(Multiple-instance Learning)来自动确定。
2.2.2 检测流程
DPM采用了传统的滑动窗口检测方式,通过构建尺度金字塔在各个尺度下进行搜索。下图为行人模型的匹配过程。某一位置与根模型/部件模型的响应得分,为该模型与以该位置为锚点(即左上角坐标)的子窗口区域内的特征的内积。也可以将模型看作一个滤波算子,响应得分为特征与待匹配模型的相似程度,越相似则得分越高。左侧为根模型的检测流程,滤波后的图中,越亮的区域代表响应得分越高。右侧为各部件模型的检测过程。
(1)将特征图像与模型进行匹配得到滤波后的图像;
(2)进行响应变换:以锚点为参考位置,综合部件模型与特征的匹配程度和部件模型相对理想位置的偏离损失,得到的最优的部件模型位置和响应得分。
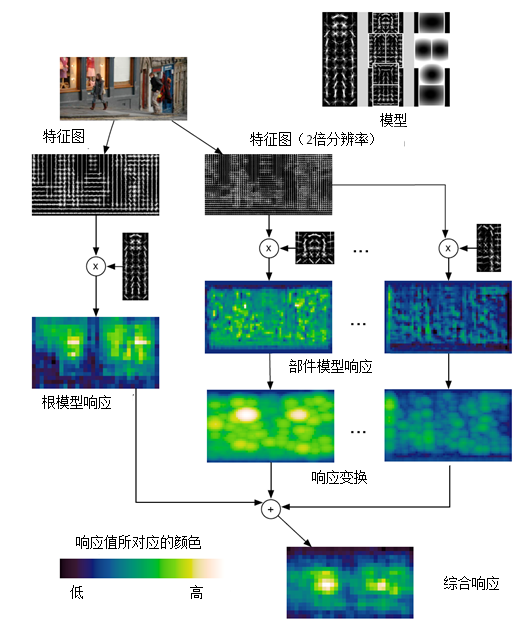
图2.2 DPM算法检测流程
3 基于REGION PROPOSAL的方法
3.1 R-CNN
Region CNN(R-CNN)是利用深度学习进行目标检测的开山之作,将CNN方法引入目标检测领域,大大提高了目标检测效果,改变了目标检测领域的主要研究思路。
论文[4]发表的2014年,DPM已经进入瓶颈期,即使使用复杂的特征和结构得到的提升也十分有限。论文将深度学习引入检测领域,一举将PASCAL VOC上的m-AP从35.1%提升到53.7%。
3.1.1 算法思想
R-CNN方法相较于传统方法而言,解决了目标检测中的两个关键的问题:
(1)运行效率
传统的目标检测算法使用滑动窗口法依次判断所有可能的区域。R-CNN则预先提取一系列比较大可能性是物体的候选区域,之后仅在这些候选区域上提取特征,进行判断,算法的执行效率更高,运行速度更快。
(2)训练集
传统的目标检测算法通过人工设定的特征在区域中进行特征提取,而R-CNN则需要训练深度网络进行特征提取。可供使用的有两个数据库:
- 一个较大的识别库(ImageNet ILSVC 2012):标定每张图片中物体的类别。100W张图像,1000类。
- 一个较小的检测库(PASCAL VOC 2007):标定每张图片中,物体的类别和位置。1W张图像,20类。
一般使用识别库进行预训练,而后用检测库调优参数,最后在检测库上评测。
3.1.2 检测流程
R-CNN算法分为以下4个步骤:
(1)采用Selective Search方法从一张图像中提取约2K个候选区域;
(2)首先归一化为统一尺寸,再对每个候选区域,使用深度网络提取特征;
(3)将提取出的特征送入每一类的SVM 分类器,判别是否属于该类;
(4)使用回归器精细修正候选框位置。因为目标检测问题的衡量标准是重叠面积:许多看似准确的检测结果,往往因为候选框不够准确,导致重叠面积很小。
对于流程的图示如下:
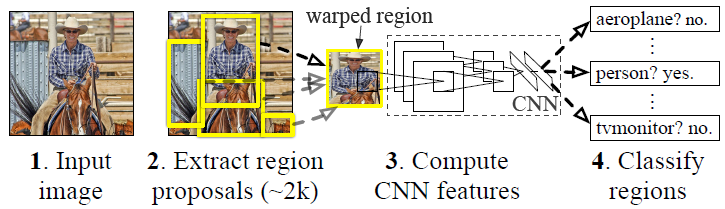
图3.1 R-CNN算法的流程图
3.2 SPP-NET
上文3.1节介绍的R-CNN的最大缺点是约2k个候选区域都要经过一次CNN,在速度上就会非常慢。Kaiming He最先对此作出改进,提出了SPP-net(全称:Spatial Pyramid Pooling),最大的改进是只需要将原图输入一次,就可以得到每个候选区域的特征。
3.2.1 算法思想
在R-CNN中,候选区域需要经过变形缩放,以适应CNN输入,可以通过修改网络结构,使得任意大小的图片都能输入到CNN中。Kaiming He在论文[5]中提出了SPP结构来适应任何大小的图片输入。
SPP-net对R-CNN最大的改进就是特征提取步骤做了修改,其他模块仍然和R-CNN一样。特征提取不再需要每个候选区域都经过CNN,只需要将整张图片输入到CNN就可以了,ROI特征直接从特征图获取。和R-CNN相比,速度提高了24~102倍。
3.2.2 改进说明
R-CNN提取特征比较耗时,需要对每个warp的区域进行学习,而SPP-net只对图像进行一次卷积,之后使用SPP-net在特征图上提取特征。结合EdgeBoxes提取的proposal,系统处理一幅图像需要0.5s。
下图所示为CNN和SPP-net网络结构的对比,第一行为CNN网络结构,第二行为SPP-net的网络结构:
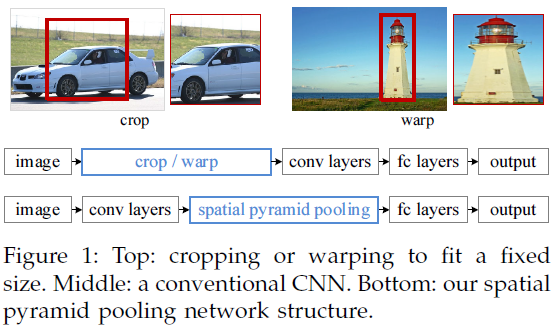
图3.2 CNN和SPP-net网络结构对比
卷积层既然可以适应任何尺寸,那么只需要在卷积层的最后加入某种结构,使得后面全连接层得到的输入为固定长度就可以了,这个结构就是spatial pyramid pooling layer:将紧跟最后一个卷积层的池化层使用SPP代替,输出向量作为全连接层的输入。至此,网络不仅可对任意长宽比的图像进行处理,而且可对任意尺度的图像进行处理。
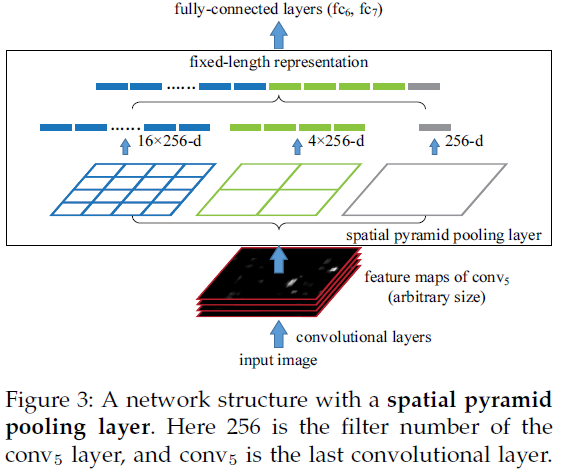
图3.3 SPP层的结构
3.3 FAST R-CNN
继2014年的R-CNN之后,Ross Girshick在15年推出Fast R-CNN[6],构思精巧,流程更为紧凑,大幅提升了目标检测的速度。
对于相同规模的网络,Fast R-CNN和R-CNN相比,训练时间从84小时减少为9.5小时,测试时间从47秒减少为0.32秒。在PASCAL VOC 2007上的准确率相差无几,约在67%左右。
3.3.1 算法思想
Fast R-CNN在继承R-CNN的同时,吸收了SPP-net的特点。相对于R-CNN,Fast R-CNN解决了如下问题:
(1)测试速度慢
R-CNN一张图像内候选框之间大量重叠,提取特征操作冗余。而Fast R-CNN则将整张图像归一化后直接送入深度网络。在邻接时,才加入候选框信息,在末尾的少数几层处理每个候选框。
(2)训练速度慢、空间开销大
对于训练速度慢的问题,Fast R-CNN在训练时先将一张图像送入网络,紧接着送入从这幅图像上提取出的候选区域,这些候选区域的前几层特征不需要再重复计算。对于空间开销大的问题,Fast R-CNN去掉了SVM这一步,所有的特征都暂时储存在显存中,就不需要额外的磁盘空间了。
3.3.2 整体框架
整体框架可以概括为:
(1)通过selective search生成region proposal,每张图片大约2000个RoI;
(2)Fast-RCNN把整张图片送入CNN,进行特征提取,把region proposal映射到CNN的最后一层卷积feature map上;
(4)通过RoI pooling层(也可以称为单层的SPP layer)使得每个建议窗口生成固定大小的feature map;
(5)继续经过两个全连接层(FC)得到特征向量。特征向量经由各自的FC层,得到两个输出向量,第一个是分类,使用softmax,第二个是每一类的bounding box回归。利用Softmax Loss(探测分类概率)和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding Box Regression)联合训练。
框架图示如下:
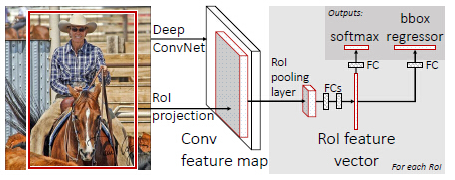
图3.4 Fast R-CNN框架图
3.4 FASTER R-CNN
3.4.1 算法思想
由于Fast R-CNN仍然是基于Selective Search方法提取region proposal,而Selective Search方法提取region proposal的计算是无法用GPU进行的,无法借助GPU的高度并行运算能力,所以效率极低。而且选取2000个候选区域,也加重了后面深度学习的处理压力。Faster R-CNN[7]在吸取了Fast R-CNN的特点的前提下,采用共享的卷积网组成RPN(Region Proposal Network)网络,用RPN直接预测出候选区域建议框,数据限定在300个,RPN的预测绝大部分在GPU中完成,而且卷积网和Fast R-CNN部分共享,因此大幅度提升了目标检测的速度。
可以看成:Faster-RCNN = RPN(区域生成网络)+ Fast-RCNN,用RPN网络代替Fast-RCNN中的Selective Search是Faster-RCNN的核心思想。[8]
3.4.2 整体框架
Faster R-CNN的整体框架描述如下:
(1)输入测试图像;
(2)将整张图片输入CNN,进行特征提取;
(3)用RPN生成建议窗口(proposals),每张图片生成300个建议窗口;
(4)把建议窗口映射到CNN的最后一层卷积feature map上;
(5)通过RoI pooling层使每个RoI生成固定尺寸的feature map;
(6)利用Softmax Loss(探测分类概率)和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding Box Regression)联合训练。
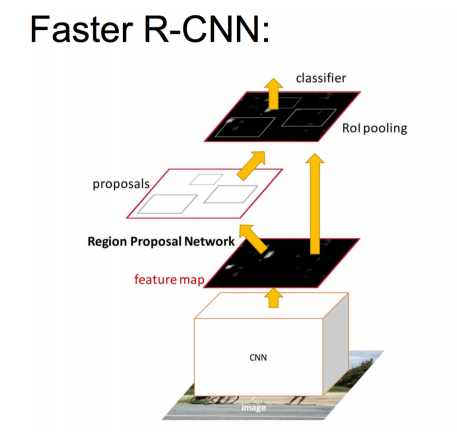
图3.5 Faster R-CNN的整体框架
4 基于回归的方法/端到端的方法
4.1 YOLO
YOLO(全称:You Only Look Once)是Joseph Redmon和Ali Farhadi等人于2015年提出的第一个基于单个神经网络的目标检测系统[9]。
4.1.1 算法思想
基于深度学习方法的一个特点就是实现端到端的检测。相对于其它目标检测与识别方法(比如Fast R-CNN)将目标识别任务分类目标区域预测和类别预测等多个流程,YOLO将目标区域预测和目标类别预测整合于单个神经网络模型中,实现在准确率较高的情况下快速目标检测与识别,基础版可以达到45帧/s的实时检测;Fast YOLO可以达到155帧/s,与当前最好系统相比,YOLO更加适合现场应用环境。
YOLO的核心思想就是利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别。
4.1.2 实现方法
YOLO的具体实现方法阐述如下:
(1)首先,将一幅图像分成S×S个网格(grid cell),如果某个物体的中心落在这个网格中,则这个网格就负责预测这个物体。见下图:
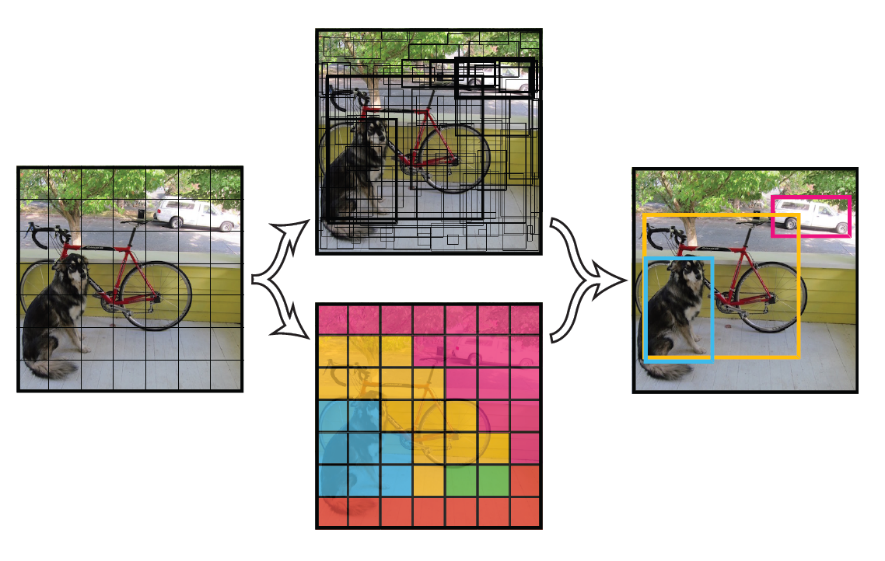
图4.1 YOLO网格划分
(2)每个网格要预测B个bounding box,每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence。这个confidence代表了所预测的box中含有object的置信度和这个box预测的有多准这两重信息。
(3)每个bounding box要预测(x, y, w, h)和confidence共5个值,每个cell还要预测一个类别信息,记为C类。则S×S个网格,每个网格要预测B个bounding box还要预测C个categories。输出就是S×S×(5×B+C)的一个tensor。
现举例说明,在PASCAL VOC中,图像输入为448×448,取S=7,B=2,一共有20个类别(C=20)。则输出就是7x7x30的一个tensor。网络结构示意如下:

图4.2 YOLO网络结构
4.1.3 存在的问题
YOLO为一种基于单独神经网络模型的目标检测方法,具有可以高准确率快速检测的特点,同时具有一定鲁棒性,可以适用于实时目标检测。但YOLO原始版本也存在一些缺点。例如:
(1)对距离近的物体检测效果不好;
(2)泛化能力偏弱。当同一类物体出现的新的不常见的长宽比时,识别不佳;
(3)多尺度物体检测有待加强。由于损失函数的问题,定位误差是影响检测效果的主要原因。
4.2 YOLOV2 & YOLO9000
YOLO的升级版有两种:YOLOv2和YOLO9000[10]。采用了一系列的方法优化了YOLO的模型结构,产生了YOLOv2,在快速的同时准确率也非常高。采用多尺度的训练方法,YOLOv2可以根据速度和精确度需求调整输入尺寸。67FPS时,YOLOv2在VOC2007数据集上可以达到76.8m-AP;40FPS,可以达到78.6m-AP,比目前最好的Faster R-CNN和SSD精确度更高,检测速度更快。然后作者采用wordtree的方法,综合ImageNet数据集和COCO数据集训练YOLO9000,使之可以实时识别超过9000种物品。
4.2.1 改进点
对于YOLO的改进集中于在保持分类准确率的基础上增强定位精确度。论文中YOLO和YOLOv2的改进对比如下:

图4.3 YOLO和YOLOv2的对比
(1)Batch Normalization:可以提高模型收敛速度,减少过拟合;
(2)High Resolution Classifier:首先采用448×448分辨率的ImageNet数据finetune使网络适应高分辨率输入;然后将该网络用于目标检测任务finetune;
(3)Convolutional With Anchor Boxes:去除了YOLO的全连接层,采用固定框(anchor boxes)来预测bounding boxes;采用anchor boxes,提升了精确度;
(4)Dimension Clusters:Anchor boxes是通过k-means在训练集中学得的,并且作者定义了新的距离公式,使用k-means获取anchor boxes来预测bounding boxes让模型更容易学习如何预测bounding boxes;
(5)Direct location prediction:YOLOv2网络为每个栅格预测5个bounding boxes(对应5个anchor boxes),每个bounding box预测5个坐标;
(6)Fine-Grained Features:YOLOv2通过添加一个pass through layer,将前一个卷积块的特征图的信息融合起来;
(7)Multi-Scale Training:YOLOv2网络只用到了卷积层和池化层,因此可以进行动态调整输入图像的尺寸,作者希望YOLOv2对于不同尺寸图像的检测都有较好的鲁棒性,因此做了针对性训练。这种策略让YOLOv2网络不得不学着对不同尺寸的图像输入都要预测得很好,这意味着同一个网络可以胜任不同分辨率的检测任务,在网络训练好之后,在使用时只需要根据需求,修改网络输入图像尺寸(width和height的值)即可。
4.3 SSD
SSD(全称:Single Shot MultiBox Detector)论文[12]发表在ECCV2016上,这篇文章在既保证速度,又要保证精度的情况下,提出了SSD物体检测模型,与现在流行的检测模型一样,将检测过程整个成一个单个深度神经网络,便于训练与优化,同时提高检测速度。
4.3.1 论文贡献
这篇论文的主要贡献总结如下:
(1)提出了新的物体检测方法SSD,比原先最快的 YOLO要快并且精确。保证速度的同时,其m-AP可与使用region proposals技术的方法(如 Faster R-CNN)相媲美;
(2)SSD方法的核心就是预测物体以及其归属类别的得分;同时,在feature map上使用小的卷积核,去预测一系列bounding boxes的box offsets;
(3)为了得到高精度的检测结果,在不同层次的feature maps上去预测物体以及box offsets,同时,还得到不同aspect ratio的预测值。
(4)能够在当输入分辨率较低的图像时,保证检测的精度。同时,整体端到端的设计,训练也变得简单。
(5)模型在不同的数据集上都进行了测试。在检测时间、检测精度上,均与目前物体检测领域最新的检测方法进行了比较。
4.3.2 整体框架
SSD的框架如下图所示。图(a)表示带有两个Ground Truth边框的输入图片,图 (b)和(c)分别表示8×8网格和4×4网格,显然前者适合检测小的目标,比如图片中的猫,后者适合检测大的目标,比如图片中的狗。在每个格子上有一系列固定大小的Box,这些在SSD称为Default Box,用来框定目标物体的位置,在训练的时候Ground Truth会赋予给某个固定的Box,比如图 (b)中的蓝框和图 (c)中的红框。
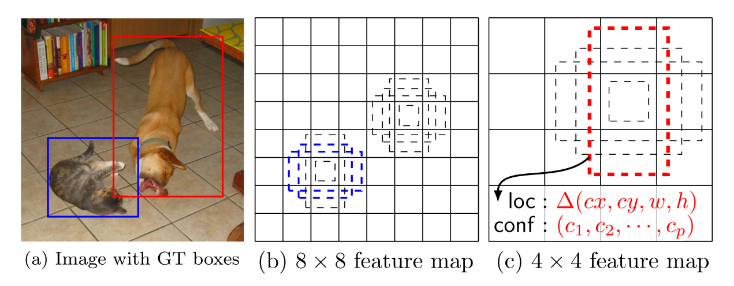
图4.4 SSD框架
SSD的网络分为两部分,前面的是用于图像分类的标准网络(去掉了分类相关的层),后面的网络是用于检测的多尺度特征映射层,从而达到检测不同大小的目标。SSD和YOLO的网络结构对比如下图所示。
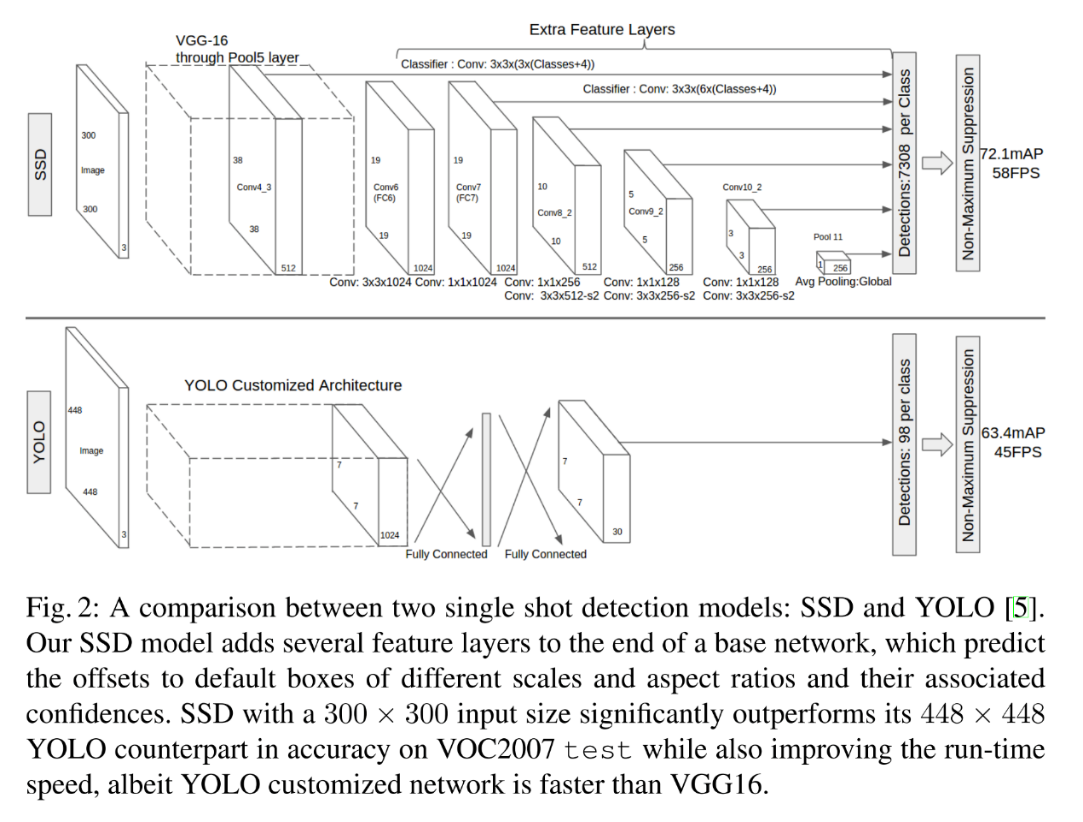
图4.5 SSD和YOLO的网络结构对比
由上图可以看出,SSD在保持YOLO高速的同时m-AP也提升不少,主要是借鉴了Faster R-CNN中的Anchor机制,同时使用了多尺度。但是从原理依然可以看出,Default Box的形状以及网格大小是事先固定的,那么对特定的图片小目标的提取会不够好。
5 总结
(1)传统方法和基于深度学习的目标检测方法对比:
传统方法的明显优势就是速度快,即使在嵌入式平台也可以做到实时,缺点就是识别准确率都不是很理想,效果差;基于深度学习的方法优势就是准确率好很多,但缺点很明显,速度较慢。
(2)基于深度学习的目标检测总体上分为两派:基于Region Proposal的R-CNN系列,以及基于回归的YOLO、SSD系列。下表所示为不同目标检测算法的FPS和m-AP对比,由于数据摘录自各个论文,故仅作为参考。
表5.1 不同目标检测算法的对比
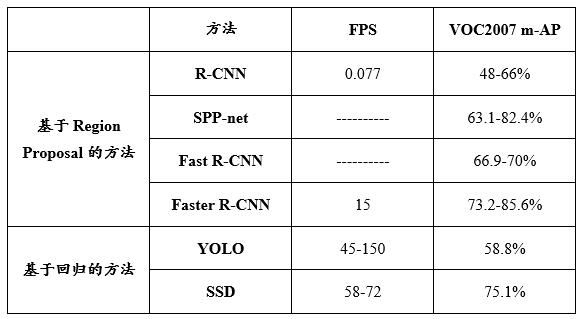
(3)多尺度目标检测仍然还有很长的路要走,比如小目标检测问题迟迟未得到突破、复杂环境下的实时检测还达不到工业的要求等。
6 参考文献
[1] PASCAL VOC Challenge performance evaluation server[EB/OL]. http://host.robots.ox.ac.uk:8080/leaderboard/displaylb.php?cls=mean&challengeid=11&compid=4.
[2] Dalal N, Triggs B. Histograms of Oriented Gradients for Human Detection[C]// Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on. IEEE, 2005:886-893.
[3] Felzenszwalb P, Mcallester D, Ramanan D. A discriminatively trained, multiscale, deformable part model[C]// Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on. IEEE, 2008:1-8.
[4] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 580-587.
[5] He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2015, 37(9): 1904-1916.
[6] Girshick R. Fast r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2015: 1440-1448.
[7] Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]//Advances in neural information processing systems. 2015: 91-99.
[8] 浅谈RCNN、SPP-net、Fast-Rcnn、Faster-Rcnn - CSDN博客[EB/OL]. http://blog.csdn.net/sunpeng19960715/article/details/54891652.
[9] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 779-788.
[10] Redmon J, Farhadi A. YOLO9000: better, faster, stronger[J]. arXiv preprint arXiv:1612.08242, 2016.
[11] YOLO升级版:YOLOv2和YOLO9000解析[EB/OL]. https://zhuanlan.zhihu.com/p/25052190.
[12] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.
[13] #Deep Learning回顾#之基于深度学习的目标检测[EB/OL]. https://www.52ml.net/20287.html.
更多机器学习干货、最新论文解读、AI资讯热点等欢迎关注“AI学院(FAICULTY)”,内容持续更新中……
欢迎加入faiculty机器学习交流qq群:451429116(点此进群)
版权声明:可以任意转载,转载时请务必标明文章原始出处和作者信息。