文章目录
- 什么是single session分析
- 基于HRF的模型信号
- 多元回归
- t contrast
- f contrast
single session分析是fmri实验分析的最简单情况之一,这里以FSL官方的例子为例,总结一下这个方法:
http://fsl.fmrib.ox.ac.uk/fslcourse/lectures/feat1_part2.pdf
什么是single session分析
single-session分析是对单个被试数据进行体素级别的分析。 数据经过预处理后,得到各个体素上的时间序列数据, 之后将协变量写入design matrix进行GLM回归,得到单个被试的effect size统计量(或者也称为残差)。统计量得到的统计图像用阈值筛选后,得到具有统计显著性的体素/体素簇。举例而言,假设实验中有三种不同的事件(events):
- 第一种是word-generation
单词生成。被试在MRI扫描时屏幕会出现一个名词,要求被试想象一个和这个名词相关的动词。例如屏幕呈现单词“Burger”, 被试想到和Burger相关的动词“Fry” - 第二种是word-shadowing
单词隐藏。 被试看到屏幕上出现一个动词,被试只需要在脑海中重复这个动词就可以。例如屏幕上显示“swim”,被试只需要想一想“swim”。第三种是控制状态, Null event。 这时屏幕上出现一个十字, 被试什么都不需要想。整个session中,每个ISI大约6秒,事件顺序是随机打乱的,每个事件都会出现24次。
基于HRF的模型信号
单词生成(word-generation)这个实验中,我们预测大脑激活会是怎样的呢?首先,再整个扫描的过程中,被试看到了不同的刺激事件,这些事件都是非均匀分布在整个时间轴上的,这些刺激事件(例如word-generation)就如同一个单位脉冲,卷积上HRF模型信号,我们可以推测出大脑激活状态如下图:

如果某个体素上的信号与我们预测的高度相关,那么我们就可以推测这个体素所在的脑组织与word-generation这个事件相关。
类似,word-shadowing刺激在时间轴上的分布卷积上HRF信号,也可以得到“理论上”负责word-shadowing的voxel区域。
多元回归
别忘了,实验的过程中两个刺激事件在时间轴上是按照不等间距的方式分布的,那么理论上说,实验设计中的刺激产生的“模型”信号与实测信号吻合的非常好:

考虑到MRI的采样时间,我们可以用下面的方法生成“模型”的理论时间序列:1)在较高的时间精度上生成刺激脉冲模拟信号。2)刺激脉冲信号与HRF做卷积,得到预测的高精度理论信号。3)根据MRI设备的实际采样时间TR,对高精度信号降采样,得到模拟的理论信号。整个过程如下图所示:

根据上面的方法,可以生成word-generation和word-shadowing这两种刺激时间的模拟信号时间序列。
下面我们就要寻找让这两个信号可以最好地线性拟合实测信号的参数beta1, beta2。 但是在不同的voxel上,得到的线性拟合参数取值是不同的,如下图。同时,我们还可以得到每个voxel上与理论模型线性拟合的残差,见图中右侧最下方图。
 GLM模型到目前为止,我们已知可以用一系列回归器将模型信号拟合实际信号,而模型信号是利用事件脉冲与HRF信号做卷积生成,回归器生成模型信号拟合实际信号的最佳线性参数,每个体素上得到的参数都是不同的,GLM就是用这样用一个简单的模型拟合所有体素上的实际信号,拟合效果可以用残差来评估。拟合参数也被称为effect size。不同体素位置上的时间序列信号经过GLM回归后,都可以得到拟合参数
β
1
\beta_1
β1和
β
2
\beta_2
β2, 将每个体素位置的
β
\beta
β 值绘制出来,就得到了下面图中右侧的图片。
GLM模型到目前为止,我们已知可以用一系列回归器将模型信号拟合实际信号,而模型信号是利用事件脉冲与HRF信号做卷积生成,回归器生成模型信号拟合实际信号的最佳线性参数,每个体素上得到的参数都是不同的,GLM就是用这样用一个简单的模型拟合所有体素上的实际信号,拟合效果可以用残差来评估。拟合参数也被称为effect size。不同体素位置上的时间序列信号经过GLM回归后,都可以得到拟合参数
β
1
\beta_1
β1和
β
2
\beta_2
β2, 将每个体素位置的
β
\beta
β 值绘制出来,就得到了下面图中右侧的图片。
 这里必须要提到的是,这些时间序列的平均值在GLM分析中并不重要(均值与被试个体状态有关,例如是否喝咖啡等因素),通常都会做去平均化处理(demean)。
这里必须要提到的是,这些时间序列的平均值在GLM分析中并不重要(均值与被试个体状态有关,例如是否喝咖啡等因素),通常都会做去平均化处理(demean)。
在FSL的first-level analyses中采用了直接在信号中去掉均值的方法,在higher-level analyses中则是在模型中加入了一个均值参数去掉均值效应。所以在first-level analyses中并不需要“显式”地设置去均值。
这里由HRF和刺激时序卷积生成的“模型信号”又被称为设计矩阵(design matrix),GLM多元回归可以形象地表示如下:

t contrast
参数估计对比 COPE( contrast of parameter estimates)是根据不同的研究问题,结合实验设计的控制变量(在这里就表现为具体的刺激)通过选择
β
\beta
β的符号和0/1得到。
 对比方案设置为[1 0]的时候,也就是当前只考虑EV1的作用,对比的是word-generation和rest
对比方案设置为[1 0]的时候,也就是当前只考虑EV1的作用,对比的是word-generation和rest
如果对比方案设置为[0 1],就是对比word-shadowing和rest。
Contrast = [0 1], word-generation VS rest
Contrast = [1 0], word-shadowing VS rest
Contrast = [1 1], mean activation
Contrast = [-1 1], more activated by shadowing than generation
Contrast = [1 -1], more activated by generation than shadowing
COPE的t统计量可以写为:
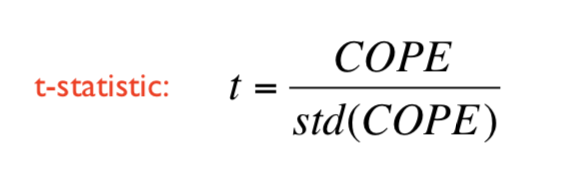
分母部分std(COPE)取决于理论模型,对比方案(contrast)和残差。
根据0假设(null hypothesis) beta=0, t统计量

服从t分布。
f contrast
F contrast 定义为:
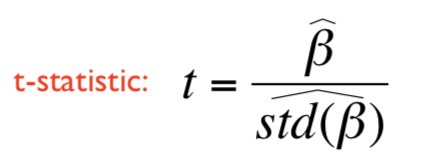
f参数对比的本质在于下面两个问题的等价性:
Is there an activation to any condition?
等价于
Does any regressor explain the variance in the data?
从这个角度出发,F参数对比也就是要求模型信号对实测数据方差的描述能力。
下图显示了f参数对比的计算过程。首先根据模型信号对实测信号的拟合,减去实测信号本身得到的残差(组间均方差),代表了对应的刺激对整体信号波动的贡献能力。同时,实测信号本身的方差(组内均方差),代表了实测信号本身的波动情况。如此得到的F值,符合f分布,通过f检验可以得到具有统计显著性的区域。

更多阅读:
Anova与F检验的定义:
https://blog.csdn.net/happyhorizion/article/details/87372100
假设检验:https://cosx.org/2010/11/hypotheses-
https://blog.csdn.net/amazingmango/article/details/784525
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)