这是
如何使用TensorRT加速深度学习推理的
更新版本*。此版本从 PyTorch 模型而不是 ONNX 模型开始,将示例应用程序升级为使用 TensorRT 7,并将 ResNet-50 分类模型替换为 UNet,这是一种分段模型。*
 图 1.张量RT标志
图 1.张量RT标志
NVIDIA TensorRT 是一款用于深度学习推理的 SDK。TensorRT 提供 API 和解析器,用于从所有主要深度学习框架导入训练的模型。然后,它会生成可在数据中心以及汽车和嵌入式环境中部署的优化运行时引擎。
这篇文章提供了使用TensorRT的简单介绍。您将学习如何将深度学习应用程序部署到 GPU 上,从而提高吞吐量并减少推理期间的延迟。它使用一个C++示例来引导您完成将 PyTorch 模型转换为 ONNX 模型并将其导入 TensorRT、应用优化以及为数据中心环境生成高性能运行时引擎的过程。
TensorRT同时支持C++和Python;如果使用任何一种,则此工作流讨论可能很有用。如果您更喜欢使用 Python,请参阅 TensorRT 文档中的使用 Python API。
深度学习适用于广泛的应用,如自然语言处理、推荐系统、图像和视频分析。随着越来越多的应用程序在生产中使用深度学习,对准确性和性能的要求导致模型复杂性和大小的强劲增长。
汽车等安全关键型应用对深度学习模型预期的吞吐量和延迟提出了严格的要求。这同样适用于某些消费类应用程序,包括推荐系统。
TensorRT 旨在帮助为这些用例部署深度学习。由于支持每个主要框架,TensorRT 通过强大的优化、使用降低的精度和高效的内存使用,帮助以低延迟处理大量数据。
要遵循这篇文章,您需要一台具有支持CUDA的GPU的计算机或带有GPU的云实例以及TensorRT的安装。在 Linux 上,最简单的入门方法是从 NVIDIA NGC 容器注册表下载具有 TensorRT 集成的 GPU 加速 PyTorch 容器。
示例应用程序使用来自 Kaggle 的脑 MRI 分段数据的输入数据来执行推理。
简单张量RT示例
以下是此示例应用程序的四个步骤:
- 将预训练的图像分割 PyTorch 模型转换为 ONNX。
- 将 ONNX 模型导入 TensorRT。
- 应用优化并生成引擎。
- 在 GPU 上执行推理。
导入 ONNX 模型包括从磁盘上保存的文件加载它,并将其从其本机框架或格式转换为 TensorRT 网络。ONNX是表示深度学习模型的标准,使它们能够在框架之间传输。
许多框架,如Caffe2,Chainer,CNTK,PaddlePaddle,PyTorch和MXNet都支持ONNX格式。接下来,根据输入模型、目标GPU平台和指定的其他配置参数构建优化的TensorRT引擎。最后一步是向TensorRT引擎提供输入数据以执行推理。
该应用程序在 TensorRT 中使用以下组件:
- **ONNX 解析器:**将转换后的 PyTorch 训练模型转换为 ONNX 格式作为输入,并在 TensorRT 中填充网络对象。
-
建筑工人: 在TensorRT中获取网络,并生成针对目标平台优化的引擎。
- **发动机:**获取输入数据,执行推理,并发出推理输出。
- **记录:**与构建器和引擎关联,以在构建和推理阶段捕获错误、警告和其他信息。
将预训练的图像分割 PyTorch 模型转换为 ONNX
从NGC注册表中的 PyTorch容器开始,以预安装框架和CUDA组件并准备就绪。成功安装 PyTorch 容器后,运行以下命令以下载运行此示例应用程序所需的所有内容(示例代码、测试输入数据和引用输出),更新依赖项,并使用提供的 makefile 编译应用程序。
>> sudo apt-get install libprotobuf-dev protobuf-compiler # protobuf is a prerequisite library
>> git clone --recursive https://github.com/onnx/onnx.git # Pull the ONNX repository from GitHub
>> cd onnx
>> mkdir build && cd build
>> cmake .. # Compile and install ONNX
>> make # Use the ‘-j’ option for parallel jobs, for example, ‘make -j $(nproc)’
>> make install
>> cd ../..
>> git clone https://github.com/parallel-forall/code-samples.git
>> cd code-samples/posts/TensorRT-introduction
>> make clean && make # Compile the TensorRT C++ code
>> cd ..
>> wget https://developer.download.nvidia.com/devblogs/speeding-up-unet.7z // Get the ONNX model and test the data
>> tar xvf speeding-up-unet.7z # Unpack the model data into the unet folder
>> cd unet
>> python create_network.py #Inside the unet folder, it creates the unet.onnx file
将 PyTorch 训练的 UNet 模型转换为 ONNX,如下面的代码示例所示:
import torch
from torch.autograd import Variable
import torch.onnx as torch_onnx
import onnx
def main():
input_shape = (3, 256, 256)
model_onnx_path = "unet.onnx"
dummy_input = Variable(torch.randn(1, *input_shape))
model = torch.hub.load('mateuszbuda/brain-segmentation-pytorch', 'unet',
in_channels=3, out_channels=1, init_features=32, pretrained=True)
model.train(False)
inputs = ['input.1']
outputs = ['186']
dynamic_axes = {'input.1': {0: 'batch'}, '186':{0:'batch'}}
out = torch.onnx.export(model, dummy_input, model_onnx_path, input_names=inputs, output_names=outputs, dynamic_axes=dynamic_axes)
if __name__=='__main__':
main()
接下来,准备用于推理的输入数据。从 Kaggle 目录中下载所有图像。将文件名中没有_mask的任何三个图像复制到 /unet 目录,并从 brain-segmentation-pytorch 存储库中 utils.py 文件。准备三个图像,以便在本文后面用作输入数据。准备input_0。pb 和 ouput_0。pb 文件供以后使用,请运行以下代码示例:
import torch
import argparse
import numpy as np
from torchvision import transforms
from skimage.io import imread
from onnx import numpy_helper
from utils import normalize_volume
def main(args):
model = torch.hub.load('mateuszbuda/brain-segmentation-pytorch', 'unet',
in_channels=3, out_channels=1, init_features=32, pretrained=True)
model.train(False)
filename = args.input_image
input_image = imread(filename)
input_image = normalize_volume(input_image)
input_image = np.asarray(input_image, dtype='float32')
preprocess = transforms.Compose([
transforms.ToTensor(),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)
tensor1 = numpy_helper.from_array(input_batch.numpy())
with open(args.input_tensor, 'wb') as f:
f.write(tensor1.SerializeToString())
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model = model.to('cuda')
with torch.no_grad():
output = model(input_batch)
tensor = numpy_helper.from_array(output[0].cpu().numpy())
with open(args.output_tensor, 'wb') as f:
f.write(tensor.SerializeToString())
if __name__=='__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--input_image', type=str)
parser.add_argument('--input_tensor', type=str, default='input_0.pb')
parser.add_argument('--output_tensor', type=str, default='output_0.pb')
args=parser.parse_args()
main(args)
要生成用于推理的已处理输入数据,请运行以下命令:
>> pip install medpy #dependency for utils.py file
>> mkdir test_data_set_0
>> mkdir test_data_set_1
>> mkdir test_data_set_2
>> python prepareData.py --input_image your_image1 --input_tensor test_data_set_0/input_0.pb --output_tensor test_data_set_0/output_0.pb # This creates input_0.pb and output_0.pb
>> python prepareData.py --input_image your_image2 --input_tensor test_data_set_1/input_0.pb --output_tensor test_data_set_1/output_0.pb # This creates input_0.pb and output_0.pb
>> python prepareData.py --input_image your_image3 --input_tensor test_data_set_2/input_0.pb --output_tensor test_data_set_2/output_0.pb # This creates input_0.pb and output_0.pb
就是这样,您已经准备好了输入数据来执行推理。从应用程序的简化版本开始,simpleONNX_1.cpp并在此基础上进行构建。后续版本可在同一文件夹中使用,simpleONNX_2.cpp和 simpleONNX.cpp。
将 ONNX 模型导入 TensorRT,生成引擎并执行推理
使用训练的模型和作为输入传递的输入数据运行示例应用程序。数据以 ONNX 原型文件的形式提供。示例应用程序将从 TensorRT 生成的输出与同一文件夹中作为 ONNX .pb 文件提供的参考值进行比较,并在提示符下汇总结果。
导入 UNet ONNX 模型并生成引擎可能需要几秒钟的时间。它还以可移植的灰色映射 (PGM) 格式生成输出图像,作为 output.pgm。
>> cd to code-samples/posts/TensorRT-introduction
>> ./simpleOnnx_1 path/to/unet/unet.onnx path/to/unet/test_data_set_0/input_0.pb # The sample application expects output reference values in path/to/unet/test_data_set_0/output_0.pb
...
Tactic: 0 is the only option, timing skipped
: Fastest Tactic: 0 Time: 0
: Formats and tactics selection completed in 2.26589 seconds.
: After reformat layers: 32 layers
: Block size 1073741824
: Block size 536870912
...
: Total Activation Memory: 2248146944
INFO: Detected 1 inputs and 1 output network tensors.
Engine generation completed in 3.37261 seconds.
OK
就是这样,你有一个使用TensorRT优化并在GPU上运行的应用程序。图 2 显示了示例测试用例的输出。
-
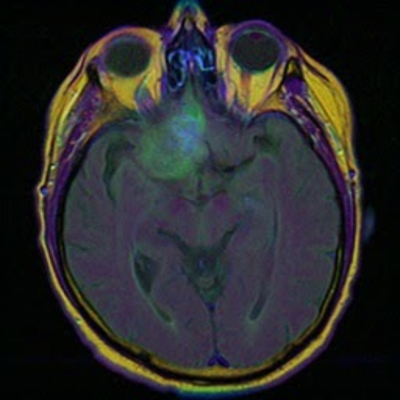
(2a):原始核磁共振成像输入图像
-
 (2b):来自测试数据集的分段地面实况
(2b):来自测试数据集的分段地面实况
-
 (2c):使用 TensorRT 预测分割图像
(2c):使用 TensorRT 预测分割图像
图 2:在脑部 MRI 图像上使用 TensorRT 进行推理。
下面是前面的示例应用程序中使用的几个关键代码示例。
下面的代码示例中的 main 函数首先声明一个 CUDA 引擎来保存网络定义和训练的参数。引擎在函数中生成,该函数将 ONNX 模型的路径作为输入。createCudaEngine
// Declare the CUDA engineunique_ptr<ICudaEngine, Destroy<ICudaEngine>> engine{nullptr};
...
// Create the CUDA engine
engine.reset(createCudaEngine(onnxModelPath));
该函数分析 ONNX 模型并将其保存在网络对象中。若要处理 U-Net 模型的输入图像和形状张量的动态输入维度,必须从生成器类创建优化配置文件,如下面的代码示例所示。createCudaEngine
优化配置文件使您能够为配置文件设置最佳输入、最小和最大尺寸。构建器选择的核可导致输入张量维度的最小运行时间,并且该核对最小和最大维度之间的范围内的所有输入张量维度都有效。它还将网络对象转换为TensorRT引擎。
下面的代码示例中的函数用于指定 TensorRT 引擎所需的最大批大小。该函数允许您在引擎构建阶段增加 GPU 内存占用量。setMaxBatchSize``setMaxWorkspaceSize
nvinfer1::ICudaEngine* createCudaEngine(string const& onnxModelPath, int batchSize){
unique_ptr<nvinfer1::IBuilder, Destroy<nvinfer1::IBuilder>> builder{nvinfer1::createInferBuilder(gLogger)};
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
unique_ptr<nvinfer1::INetworkDefinition, Destroy<nvinfer1::INetworkDefinition>> network{builder->createNetworkV2(explicitBatch)};
unique_ptr<nvonnxparser::IParser, Destroy<nvonnxparser::IParser>> parser{nvonnxparser::createParser(*network, gLogger)};
unique_ptr<nvinfer1::IBuilderConfig,Destroy<nvinfer1::IBuilderConfig>> config{builder->createBuilderConfig()};
if (!parser->parseFromFile(onnxModelPath.c_str(), static_cast<int>(ILogger::Severity::kINFO)))
{
cout << "ERROR: could not parse input engine." << endl;
return nullptr;
}
builder->setMaxBatchSize(batchSize);
config->setMaxWorkspaceSize((1 << 30));
auto profile = builder->createOptimizationProfile();
profile->setDimensions(network->getInput(0)->getName(), OptProfileSelector::kMIN, Dims4{1, 3, 256 , 256});
profile->setDimensions(network->getInput(0)->getName(), OptProfileSelector::kOPT, Dims4{1, 3, 256 , 256});
profile->setDimensions(network->getInput(0)->getName(), OptProfileSelector::kMAX, Dims4{32, 3, 256 , 256});
config->addOptimizationProfile(profile);
return builder->buildEngineWithConfig(*network, *config);
}
创建引擎后,创建一个执行上下文以保存推理期间生成的中间激活值。下面的代码演示如何创建执行上下文。
// Declare the execution context
unique_ptr<IExecutionContext, Destroy<IExecutionContext>> context{nullptr};
...
// Create the execution context
context.reset(engine->createExecutionContext());
此应用程序在下面的代码示例中所示的函数中将推理请求异步放置在 GPU 上。输入从主机 (CPU) 复制到设备 (GPU), 然后使用函数执行推理,并将结果异步复制回来。launchInference``launchInference``enqueue
该示例使用 CUDA 流来管理 GPU 上的异步工作。异步推理执行通常通过重叠计算来提高性能,因为它可以最大限度地提高 GPU 利用率。该函数将推理请求放在 CUDA 流上,并作为输入运行时批大小、指向输入和输出的指针以及用于内核执行的 CUDA 流。异步数据传输从主机到设备执行,反之亦然。enqueue``cudaMemcpyAsync
void launchInference(IExecutionContext* context, cudaStream_t stream, vector<float> const& inputTensor, vector<float>& outputTensor, void** bindings, int batchSize)
{
int inputId = getBindingInputIndex(context);
cudaMemcpyAsync(bindings[inputId], inputTensor.data(), inputTensor.size() * sizeof(float), cudaMemcpyHostToDevice, stream);
context->enqueueV2(bindings, stream, nullptr);
cudaMemcpyAsync(outputTensor.data(), bindings[1 - inputId], outputTensor.size() * sizeof(float), cudaMemcpyDeviceToHost, stream);
}
在调用后使用该函数可确保在访问结果之前完成 GPU 计算。输入和输出的数量,以及每个输入和输出的值和维度,都可以使用ICudaEngine类中的函数进行查询。该示例最终将参考输出与 TensorRT 生成的推理进行比较,并将差异打印到提示符。cudaStreamSynchronize``launchInference
有关类的详细信息,请参阅 TensorRT 类列表。完整的代码示例simpleOnnx_1.cpp。
对输入进行批处理
此应用程序示例需要单个输入,并在对其执行推理后返回输出。实际应用通常批量输入以实现更高的性能和效率。可以在神经网络的不同层上并行计算一批形状和大小相同的输入。
较大的批次通常可以更有效地利用 GPU 资源。例如,在 Volta 和图灵 GPU 上使用 32 倍的倍数的批大小在较低精度下可能特别快速和有效,因为 TensorRT 可以使用特殊内核来表示利用 Tensor 核心的矩阵乘法和全连接层。
使用以下代码在命令行上将图像传递到应用程序。在命令行上作为输入参数传递的图像(.pb 文件)的数量决定了此示例中的批大小。使用 test_data_set_* 从所有目录中获取所有 input_0.pb 文件。以下命令不是只读取一个输入,而是读取文件夹中所有可用的输入。
目前,下载的数据有三个输入目录,因此批量大小为 3。此版本的示例分析应用程序并将结果输出到提示符。有关详细信息,请参阅下一节分析应用程序。
>> ./simpleOnnx_2 path/to/unet.onnx path/to/unet/test_data_set_*/input_0.pb # Use all available test data sets.
...
: Formats and tactics selection completed in 2.33156 seconds.
: After reformat layers: 32 layers
: Block size 1073741824
: Block size 536870912
...
: Total Activation Memory: 2248146944
INFO: Detected 1 inputs and 1 output network tensors.
: Engine generation completed in 3.45499 seconds.
Inference batch size 3 average over 10 runs is 5.23616ms
OK
要在一个推理通道中处理多个图像,请对应用程序进行一些更改。首先,在循环中收集所有图像(.pb 文件),以用作应用程序中的输入:
input_files.push_back(string{argv[2]});
for (int i = 2; i < argc; ++i)
input_files.push_back(string{argv[i]});
接下来,指定 TensorRT 引擎使用该函数预期的最大批大小。然后,构建器通过选择可在目标平台上最大化其性能的算法来生成针对该批大小进行调整的引擎。虽然引擎不接受较大的批大小,但允许在运行时使用较小的批大小。setMaxBatchSize
maxBatchSize 值的选择取决于应用程序以及任何给定时间的预期推理流量(例如,图像数量)。一种常见的做法是构建针对不同批大小(使用不同的 maxBatchSize 值)优化的多个引擎,然后在运行时选择最优化的引擎。
如果未指定,则默认批大小为 1,这意味着引擎不处理大于 1 的批大小。设置此参数,如下面的代码示例所示:
builder->setMaxBatchSize(batchSize);
分析应用程序
现在您已经看到了一个示例,下面介绍了如何衡量其性能。网络推理最简单的性能测量是输入呈现给网络和返回输出之间经过的时间,称为延迟。
对于嵌入式平台上的许多应用程序,延迟至关重要,而消费类应用程序需要服务质量。更低的延迟使这些应用程序变得更好。此示例使用 GPU 上的时间戳测量应用程序的平均延迟。有许多方法可以在 CUDA 中分析应用程序。有关详细信息,请参阅如何在 CUDA C/C++ 中实现性能指标 。
CUDA 提供轻量级事件 API 函数来创建、销毁和记录事件,以及计算它们之间的时间。应用程序可以在 CUDA 流中记录事件,一个在启动推理之前,另一个在推理完成后,如下面的代码示例所示。
在某些情况下,您可能关心包括推理启动之前和推理完成后在 GPU 和 CPU 之间传输数据所需的时间。存在将数据预取到GPU的技术,以及将计算与数据传输重叠的技术,这可以显着隐藏数据传输开销。该函数测量在 CUDA 流中遇到这两个事件之间的时间。cudaEventElapsedTime
使用上一节开头的代码示例运行此示例并查看分析输出。要分析应用程序,请将推理启动包装在函数中,simpleONNX_2.cpp。此示例包括一个更新的函数调用。doInference
launchInference(context, stream, inputTensor, outputTensor, bindings, batchSize);
//Wait until the work is finished
cudaStreamSynchronize(stream);
doInference(context.get(), stream, inputTensor, outputTensor, bindings, batchSize);
按如下方式计算延迟:doInference
// Number of times to run inference and calculate average timeconstexpr int ITERATIONS = 10;
...
void doInference(IExecutionContext* context, cudaStream_t stream, vector<float> const& inputTensor, vector<float>& outputTensor, void** bindings, int batchSize)
{
CudaEvent start;
CudaEvent end;
double totalTime = 0.0;
for (int i = 0; i < ITERATIONS; ++i)
{
float elapsedTime;
// Measure time that it takes to copy input to GPU, run inference, and move output back to CPU
cudaEventRecord(start, stream);
launchInference(context, stream, inputTensor, outputTensor, bindings, batchSize);
cudaEventRecord(end, stream);
// Wait until the work is finished
cudaStreamSynchronize(stream);
cudaEventElapsedTime(&elapsedTime, start, end);
totalTime += elapsedTime;
}
cout << "Inference batch size " << batchSize << " average over " << ITERATIONS << " runs is " << totalTime / ITERATIONS << "ms" << endl;
}
许多应用程序对大量累积和批处理的输入数据执行推理,以便进行离线处理。每秒可能的最大推理数(称为吞吐量)是这些应用程序的宝贵指标。
您可以通过为更大的特定批大小生成优化引擎来测量吞吐量,运行推理并测量每秒可处理的批数。使用每秒的批数和批大小来计算每秒的推理数,但这超出了本文的范围。
优化您的应用程序
现在您已经知道如何批量运行推理并分析应用程序,请对其进行优化。TensorRT的主要优势在于其灵活性和多种技术的使用,包括混合精度,所有GPU平台上的有效优化以及跨各种模型类型进行优化的能力。
在本节中,我们将介绍一些提高吞吐量和减少应用程序延迟的技术。有关详细信息,请参阅 TensorRT 性能的最佳做法。
以下是一些常用技术:
- 使用混合精度计算
- 更改工作区大小
- 重用 TensorRT 引擎
使用混合精度计算
默认情况下,TensorRT 使用 FP32 算法执行推理,以获得尽可能高的推理精度。但是,在许多情况下,您可以使用FP16和INT8精度进行推理,同时对结果准确性的影响最小。
使用降低的精度来表示模型使您能够在内存中拟合更大的模型,并在较低的数据传输要求下获得更高的性能,从而降低精度。您还可以将 FP32 和 FP16 精度的计算与 TensorRT(称为混合精度)混合,或者将 INT8 量化精度用于权重、激活和执行层。
通过将参数设置为 true 来启用 FP16 内核,适用于支持快速 FP16 数学运算的设备。setFp16Mode
builder->setFp16Mode(builder->platformHasFastFp16());
该参数向生成器指示较低的精度对于计算是可以接受的。TensorRT 使用 FP16 优化的内核,如果它们在所选配置和目标平台上表现更好。setFp16Mode
打开此模式后,可以在FP16或FP32中指定权重,并自动转换为用于计算的适当精度。您还可以灵活地为输入和输出张量指定 16 位浮点数据类型,这超出了本文的范围。
更改工作区大小
TensorRT 允许您在引擎构建阶段使用该函数增加 GPU 内存占用量。增加限制可能会影响可以同时共享 GPU 的应用程序数。将此限制设置得太低可能会过滤掉几种算法并创建次优引擎。TensorRT 只分配所需的内存,即使设置的内存量要高得多。因此,应用程序应该允许TensorRT构建器尽可能多地工作空间。TensorRT分配的不多于此,通常更少。setMaxWorkspaceSize``IBuilder::setMaxWorkspaceSize
此示例使用 1 GB,这允许 TensorRT 选择任何可用的算法。
// Allow TensorRT to use up to 1 GB of GPU memory for tactic selectionconstexpr size_t MAX_WORKSPACE_SIZE = 1ULL << 30; // 1 GB worked well for this example
...
// Set the builder flag
builder->setMaxWorkspaceSize(MAX_WORKSPACE_SIZE);
重用 TensorRT 引擎
构建引擎时,构建器对象会为所选平台和配置选择优化最多的内核。从网络定义文件构建引擎可能非常耗时,除非模型、平台或配置发生更改,否则不应在每次执行推理时重复此操作。
图 3 显示,您可以在生成后转换引擎的格式,并将其存储在磁盘上以供以后重用,这称为序列化引擎。当您将引擎从磁盘加载到内存中并继续使用它进行推理时,将发生反序列化。
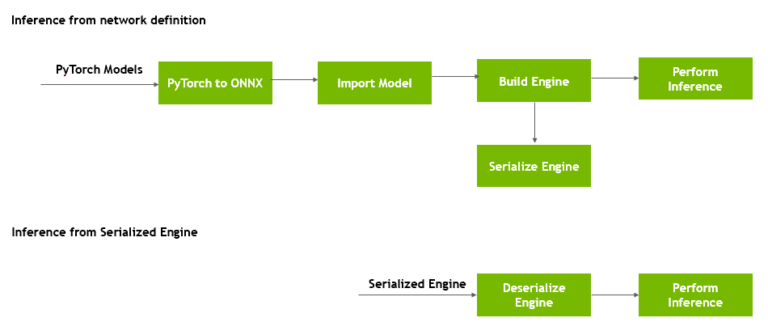
图 3.序列化和反序列化 TensorRT 引擎。
运行时对象反序列化引擎。
simpleOnnx.cpp 不是每次都创建引擎,而是包含加载和使用引擎(如果存在)的函数。如果该引擎不可用,它将创建该引擎并将其保存在当前目录中,名称为 unet_batch4.engine。在此示例尝试生成新引擎之前,如果此引擎在当前目录中可用,它将选取该引擎。getCudaEngine
若要强制使用更新的配置和参数生成新引擎,请在重新运行代码示例之前,使用 make clean_engines 命令删除存储在磁盘上的所有现有序列化引擎。
engine.reset(createCudaEngine(onnxModelPath, batchSize))engine.reset(getCudaEngine(onnxModelPath, batchSize));
ICudaEngine* getCudaEngine(string const& onnxModelPath)
{
string enginePath{getBasename(onnxModelPath) + ".engine"};
ICudaEngine* engine{nullptr};
string buffer = readBuffer(enginePath);
if (buffer.size())
{
// Try to deserialize the engine
unique_ptr<IRuntime, Destroy<IRuntime>> runtime{createInferRuntime(gLogger)};
engine = runtime->deserializeCudaEngine(buffer.data(), buffer.size(), nullptr);
}
if (!engine)
{
// Fall back to creating the engine from scratch
engine = createCudaEngine(onnxModelPath);
if (engine)
{
unique_ptr<IHostMemory, Destroy<IHostMemory>> engine_plan{engine->serialize()};
// Try to save the engine for future uses
writeBuffer(engine_plan->data(), engine_plan->size(), enginePath);
}
}
return engine;
}
将此保存的引擎与不同的批大小一起使用。下面的代码示例获取输入数据,重复其次数与批大小变量一样多,然后将此追加的输入传递给示例。第一次运行创建引擎,第二次运行尝试反序列化引擎。
>> for x in seq {1..4} ; do echo path/to/unet/test_data_set_0/input_0.pb ; done | xargs ./simpleOnnx path/to/unet/unet.onnx...
: Tactic: 0 is the only option, timing skipped
: Fastest Tactic: 0 Time: 0
: Formats and tactics selection completed in 2.3837 seconds.
: After reformat layers: 32 layers
: Block size 1073741824
: Block size 536870912
...
: Total Activation Memory: 2248146944
Inference batch size 4 average over 10 runs is 6.86188ms
>> for x in seq {1 4}; do echo unet/test_data_set_0/input_0.pb ; done | xargs ./simpleOnnx unet/unet.onnx
: Deserialize required 1400284 microseconds.
Inference batch size 4 average over 10 runs is 6.80197ms
OK
现在,您已经学习了如何使用 TensorRT 加快简单应用程序的推理速度。我们测量了早期在带有TensorRT 7的NVIDIA TITAN V GPU上的性能。
今后的步骤
实际应用程序的计算需求要高得多,具有更大的深度学习模型、更多的数据处理需求和更严格的延迟限制。TensorRT为计算密集型深度学习应用程序提供高性能优化,是推理的宝贵工具。
希望这篇文章已经让您熟悉了使用TensorRT获得惊人性能所需的关键概念。以下是一些想法,用于应用您学到的知识,使用其他模型,并通过更改本文中介绍的参数来探索设计和性能权衡的影响。
-
TensorRT 支持矩阵提供了 TensorRT API、解析器和层支持的功能和软件。虽然此示例C++使用,但 TensorRT 同时提供了 C++ 和 Python API。若要运行本文中包含的示例应用程序,请参阅 TensorRT 开发人员指南中的 API 和 Python C++代码示例。
- 使用参数 setFp16Mode 将模型的允许精度更改为 true/false,并对应用程序进行分析以查看性能差异。
- 更改运行时用于推理的批大小,并查看这对模型和数据集的性能(延迟、吞吐量)有何影响。
- 将 maxbatchsize 参数从 64 更改为 4,并查看不同的内核在前五名中被选中。使用 nvprof 查看性能分析结果中的内核。
本文中未涉及的一个主题是在 TensorRT 中以 INT8 精度准确执行推理。TensorRT 自动转换 FP32 网络以进行部署,同时降低 INT8 的精度,同时最大限度地减少精度损失。为了实现这一目标,TensorRT使用校准过程,当使用有限的8位整数表示近似FP32网络时,该过程可最大限度地减少信息丢失。有关更多信息,请参阅使用 TensorRT 3 的自动驾驶汽车的快速 INT8 推理。
有许多资源可帮助加速图像/视频、语音应用和推荐系统的应用程序。其中包括代码示例、自定进度的深度学习研究所实验室和教程,以及用于分析和调试应用程序的开发人员工具。
如果在使用TensorRT时遇到问题,请查看NVIDIA TensorRT开发者论坛,看看TensorRT社区的其他成员是否有解决方案。NVIDIA 注册开发者还可以在开发者计划页面上提交错误。