项目地址:https://gitee.com/jyq_18792721831/studyspark.git
sbt 配置
sbt 使用ivy作为自己的依赖库,类似maven的.m2文件夹,里面存储了sbt的缓存等信息。
sbt本身有一些配置,但是这些配置在官网文档中没有说明,不过我们可以在sbtopts文件中查看相关的配置信息
sbtopts文件在/sbt/conf文件夹下
首先是仓库信息,配置的仓库决定了我们下载依赖的包的速度,我们可以选择国内的镜像,这样下载速度会比较快。
首先在/sbt/conf文件夹下创建repo.properties文件,里面是我们配置的镜像的地址
[repositories]
local
huaweicloud-maven: https://repo.huaweicloud.com/repository/maven/
maven-central: https://repo1.maven.org/maven2/
sbt-plugin-repo: https://repo.scala-sbt.org/scalasbt/sbt-plugin-releases, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext]
接着需要在/sbt/conf/sbtconfig.txt中指定我们需要使用自己定义的镜像
-Dsbt.log.format=true
-Dsbt.override.build.repos=true
-Dsbt.repository.config=E:\sbt\conf\repo.properties
-Dconsold.encoding=GBK
接着创建.ivy,boot,.sbt目录
这些配置在sbtopts文件中有,但是在sbtconfig.txt中配置,需要转为Java的-D参数
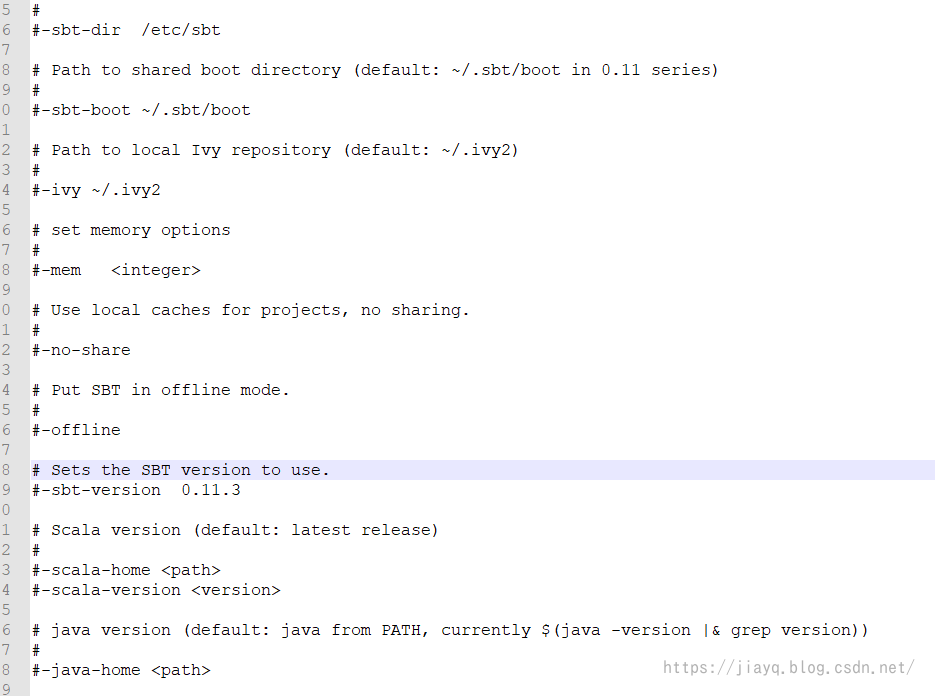
完整的sbtconfig.txt如下
-Dsbt.log.format=true
-Dsbt.override.build.repos=true
-Dsbt.repository.config=E:\sbt\conf\repo.properties
-Dconsold.encoding=UTF-8
-Dsbt.ivy.home=E:\sbt\.ivy\
-Dsbt.log.format=true
-Dsbt.boot.directory=E:\sbt\boot\
-Dsbt.global.base=E:\sbt\.sbt\
相关的目录结构如下

.sbt是sbt一些元数据的存储目录,而.ivy则是sbt使用的ivy依赖管理工具的目录,而真正存储相关的依赖的目录则是boot目录
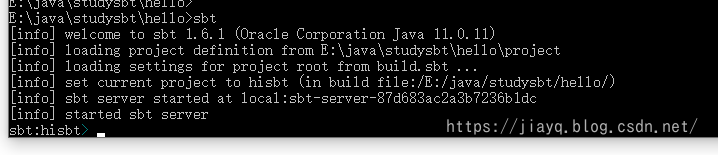
我们启动sbt,就会发现在上述三个目录中会生成一些文件
在boot目录下会存储依赖
第一次启动会比较慢
sbt 单项目构建
在之前的例子上继续进行sbt入门_a18792721831的博客-CSDN博客
我们在build.sbt中配置hello项目
lazy val root = (project in file("."))
.settings(
name := "hello",
version := "1.0",
scalaVersion := "2.12.15",
sbtVersion := "1.6.1"
)
因为build.sbt中默认引入了sbt._,Keys._,所以很多隐式变量我们可以直接使用,比如project等,
需要注意的是 :=是scala语法中的操作,表示在原有的基础上增加或者替换指定键的值。
在sbt的设计中,每个key对应的是一个列表,当我们在项目定义中对一个key进行多个配置的时候,sbt会按照key进行分组,然后进行替换或者配置,或者增加属性等等操作,以此来将整个构建过程并行化。
所以:=实际上是scala中对原有列表增加或替换元素,并返回新的列表的操作。
而一般情况下,:=左边的key都是Keys._中定义的隐式变量。
接着我们重新加载
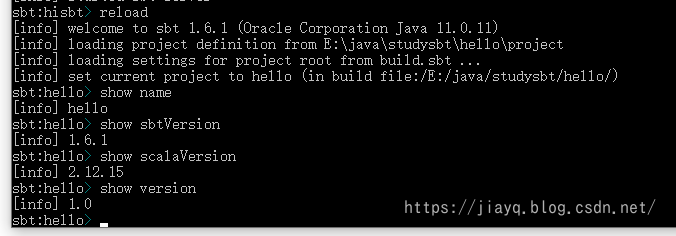
设置根目录为com.study.sbt.hello
lazy val root = (project in file("."))
.settings(
name := "hello",
version := "1.0",
scalaVersion := "2.12.15",
sbtVersion := "1.6.1",
organization := "com.study.sbt.hello"
)
配置依赖
libraryDependencies += groupID % artifactID % revision
这里面用到了+=,这也是scala的语法,因为可能存在多个依赖,所以更加强调追加,而:=则表示如果key没有值,那么增加,否则替换。
当然也可以使用++=一次性增加多个依赖
libraryDependencies ++= Seq(
groupID % artifactID % revision,
groupID % otherID % otherRevision
)
因为scala的sdk的二进制不兼容,所以就会导致使用scala编写的jar会有多个scala的sdk版本的包,我们一般引入依赖的时候,需要非常注意引入匹配scala的sdk的包。因为这个原因,sbt支持自动匹配scala的sdk版本的包
如果你用是 groupID %% artifactID % revision 而不是 groupID % artifactID % revision(区别在于 groupID 后面是 %%),sbt 会在 工件名称中加上项目的 Scala 版本号。 这只是一种快捷方法
配置其他的镜像
就像maven中可以在pom.xml中指定仓库地址,sbt也支持,其key为resolvers
需要注意的是我们需要使用at方法将字符串转为resolvers的类型
resolvers += name at location
比如
resolvers += "Sonatype OSS Snapshots" at "https://oss.sonatype.org/content/repositories/snapshots"
依赖作用域
在maven中可以指定某些依赖在开发的某个阶段使用,比如lombok,大多数我们只是在开发阶段使用lombok插件,在编译后,lombok就会生成相应的class字节码,在后续的环节中,lombok的作用域就没有了
sbt也支持给依赖指定作用域,比如
libraryDependencies += "org.apache.derby" % "derby" % "10.4.1.3" % Test
就是在依赖后面再加%指定作用域
本地依赖
如果你想加载本地依赖,那么你只需要将本地的jar包放在项目的lib目录下,sbt就会把lib目录下的jar包加载到classpath中
当然,你也可以使用其他的文件夹名字
如果使用其他的名字,需要在build.sbt中配置,像这样
unmanagedBase := baseDirectory.value / "custom_lib"
在项目的project目录下有一个build.properties文件,在build.sbt中的配置也可以在build.properties中配置,只不过优先级可能比较低一些。
sbt 多项目构建
一个项目中可能有多个模块,就类似于微服务那样。在sbt中是工程,但是没有层级关系,只是简单的组合关系。
为了更好的管理项目,可以在一个build.sbt文件中定义多个项目。
区别就是多个project的定义
比如我们在hello文件夹下创建两个文件夹test1,test2,并且把.scala文件分别拷贝进去,分别打印hello,test1,test2
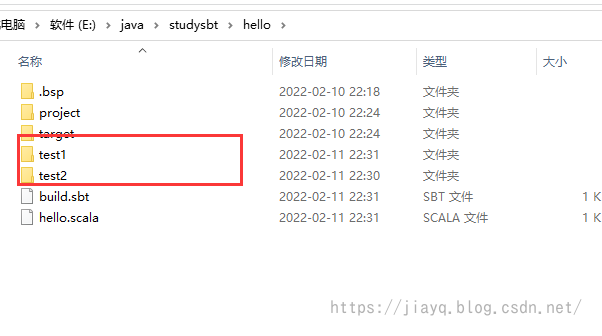
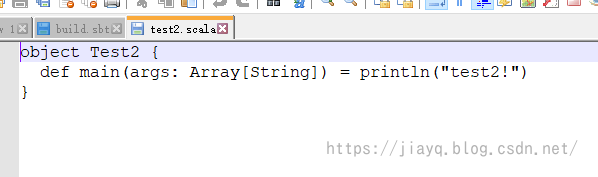
而我们的build.sbt文件内容如下所示:
lazy val commonSettings = Seq(
version := "1.0",
scalaVersion := "2.12.15",
sbtVersion := "1.6.1",
)
lazy val hello = (project in file("."))
.settings(
commonSettings,
name := "hello",
organization := "com.study.sbt.hello"
)
lazy val test1 = (project in file("test1"))
.settings(
commonSettings,
name := "test1",
organization := "com.study.sbt.test1"
)
lazy val test2 = (project in file("test2"))
.settings(
commonSettings,
name := "test2",
organization := "com.study.sbt.test2"
)
我们抽取了公共的配置,然后在指定的时候,将公共的配置配置给项目
在cmd中重新加载项目,然后使用projects命令查看全部的项目
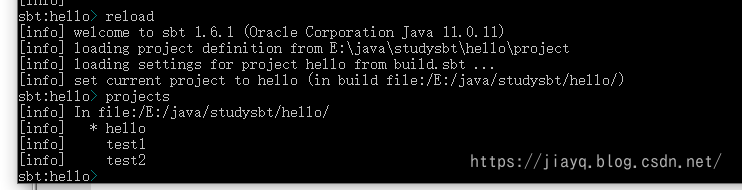
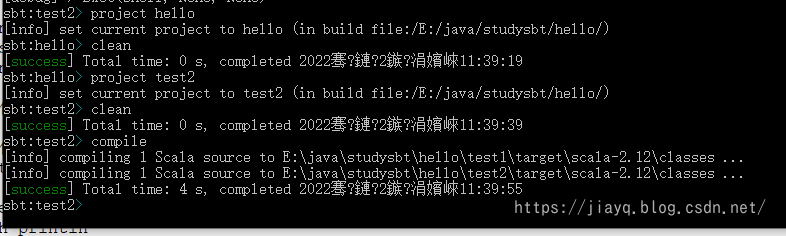
需要注意的是,目前这三个项目是完全相互独立的,我们可以使用project name切换项目
比如我们切换到test2并编译执行
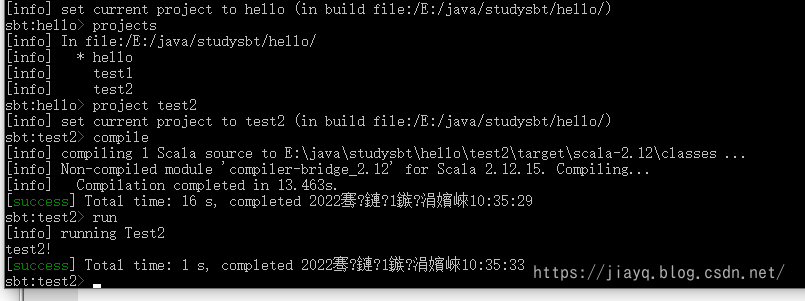
项目关联
当我们需要给多个项目做相同的操作的时候,这种方式就变得非常麻烦了,好在sbt支持将项目进行关联,关联后,我们只需要在顶层项目执行,则关联的子项目也会执行相同的命令
.aggregate(test1)
比如我们将hello项目和test1项目进行关联
我们只需要在hello的项目定义中增加上面的aggregate的方法调用即可
完整的build.sbt如下
lazy val commonSettings = Seq(
version := "1.0",
scalaVersion := "2.12.15",
sbtVersion := "1.6.1",
)
lazy val hello = (project in file(".")).aggregate(test1)
.settings(
commonSettings,
name := "hello",
organization := "com.study.sbt.hello"
)
lazy val test1 = (project in file("test1"))
.settings(
commonSettings,
name := "test1",
organization := "com.study.sbt.test1"
)
lazy val test2 = (project in file("test2"))
.settings(
commonSettings,
name := "test2",
organization := "com.study.sbt.test2"
)
我们重新加载,并切换到hello项目进行编译执行
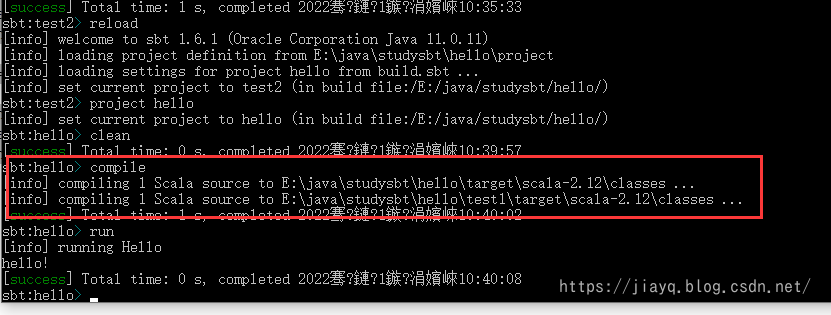
可以看出,我们执行的compile命令在两个项目中都执行了,但是run却只在当前目录执行了,这是为什么呢?
我们使用inspect tree查看compile和run有什么不同

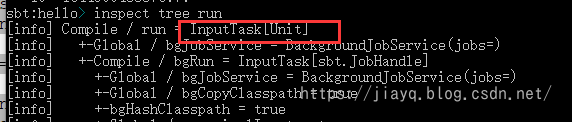
可以看出,使用aggregate关联的项目,只会传播执行Task,而InputTask却不会传播执行。
需要注意的是,传播的task在哪个项目中执行的顺序是不确定的。
项目依赖
如果test1项目需要使用到test2项目中的代码,就像增加的第三方依赖一样,那么我们需要使用dependsOn来将项目在Classpath中进行关联。
需要注意的是,项目依赖的配置是单项的,比如lazy val A = project dependsOn B,那么只能在A中使用B的代码,对于B来说,是无法使用A的代码的。
看到这里,就不得不注意循环依赖的避免,如果A依赖B,B也依赖A,那么需要将A和B被依赖的内容抽取为C,然后A和B都依赖C.
比如我们现在有三个项目hello,test1,test2,在上面我们让hello和test1进行关联,现在要让test2依赖test1
lazy val test2 = (project in file("test2")).dependsOn(test1)
.settings(
commonSettings,
name := "test2",
organization := "com.study.sbt.test2"
)
不仅仅可以进行代码依赖,还可以进行configuration依赖,比如A项目的test依赖B项目的test,也就是说在执行A项目的test命令前会自动执行B项目的test
lazy val A = project dependsOn(B % "test->test") // A 项目 conf -> B 项目 conf
lazy val A = project dependsOn(B % "test->test;test->compile") // 多个conf用分号分割
比如我们执行test2的compile前执行test1的compile
lazy val test2 = (project in file("test2")).dependsOn(test1 % "compile->compile")
.settings(
commonSettings,
name := "test2",
organization := "com.study.sbt.test2"
)
再验证的时候需要先在hello项目下执行clean,然后切换到test2项目下执行clean,因为test1已经与hello关联了,hello执行了clean,test1也会执行clean,然后切换到test2执行compile,此时就会先执行test1的compile然后执行test2的compile,而hello的compile则不会执行
每个子项目都有资格使用自己的build.sbt,但是不能有自己的project目录。
如果创建配置项目的时候,没有指定顶级项目,会自动创建顶级项目,并且顶级项目会自动将其他项目聚合起来(注意不是依赖)
sbt 配置定义
实际上,到了这里,对于基本的sbt项目构建和管理,问题就不大了,至少使用上是没有问题的,但是想要深入,说真的,真难。
在前面的项目定义中,settings方法的左边是key,右边是值。
而允许的值有三种:SettingKey[T],TaskKey[T],InputKey[T]
- SettingKey[T]:是配置key,在加载项目的时候只会执行计算一次,结算结果一直保存着
- TaskKey[T]:是操作key,每次调用都会执行,而且可能执行计算多次,每次都会重新计算
- InputTaskKey[T]:也是操作key,区别在于可以接收参数
一般情况下,内置的key就足够我们使用了,全部的内置key的列表在这里https://www.scala-sbt.org/1.x/api/sbt/Keys$.html
像前面我们抽取的公共的项目配置,就是SettingKey[T],SettingKey[T]只支持固定的值,不能包含代码操作
而且在sbt定义中,提倡使用lazy 定义,这样可以避免加载顺序的问题
比如
lazy val commonSettings = Seq(
version := "1.0",
scalaVersion := "2.12.15",
sbtVersion := "1.6.1",
)
sbt 任务定义
而TaskKey[T]和InputTaskKey[T]允许我们写一些操作
比如
lazy val hello = taskKey[Unit]("一个 task 示例")
我们定义了TaskKey[T]后,就可以在配置的时候使用了
完整的build.sbt如下
lazy val commonSettings = Seq(
version := "1.0",
scalaVersion := "2.12.15",
sbtVersion := "1.6.1",
)
lazy val hello = (project in file(".")).aggregate(test1)
.settings(
commonSettings,
name := "hello",
organization := "com.study.sbt.hello",
myTask := {println("hello task key")}
)
lazy val test1 = (project in file("test1"))
.settings(
commonSettings,
name := "test1",
organization := "com.study.sbt.test1"
)
lazy val test2 = (project in file("test2"))
.settings(
commonSettings,
name := "test2",
organization := "com.study.sbt.test2"
)
lazy val myTask = taskKey[Unit]("myTask")
我们重新加载后调用myTask

带有参数的Task
上面说的是没有参数的task,我们还可以创建带有参数的task,也就是InputTask
因为参数的输入存在不确定性,所以我们需要自己定义参数解析器,好在sbt提供了一些默认的参数解析器,当然也提供了一些用于创建解析器的方法,用于辅助我们定义自己的解析器。
我们使用默认的参数解析器,默认的参数解析器是以空格分割参数的
需要将默认的参数解析器导入
完整的build.sbt如下
// 导入默认的参数解析器
import complete.DefaultParsers._
lazy val commonSettings = Seq(
version := "1.0",
scalaVersion := "2.12.15",
sbtVersion := "1.6.1",
)
lazy val hello = (project in file(".")).aggregate(test1)
.settings(
commonSettings,
name := "hello",
organization := "com.study.sbt.hello",
myTask := {println("hello task key")}
)
lazy val test1 = (project in file("test1"))
.settings(
commonSettings,
name := "test1",
organization := "com.study.sbt.test1"
)
lazy val test2 = (project in file("test2"))
.settings(
commonSettings,
name := "test2",
organization := "com.study.sbt.test2"
)
// 定义无参数的任务
lazy val myTask = taskKey[Unit]("myTask")
// 定义有参数的任务,使用默认的空格的参数解析器
lazy val myInput = inputKey[Unit]("myInputTask")
myInput := {
val args: Seq[String] = spaceDelimited("<arg>").parsed
args foreach println
}
我们重新加载sbt,并执行我们的带有参数的任务
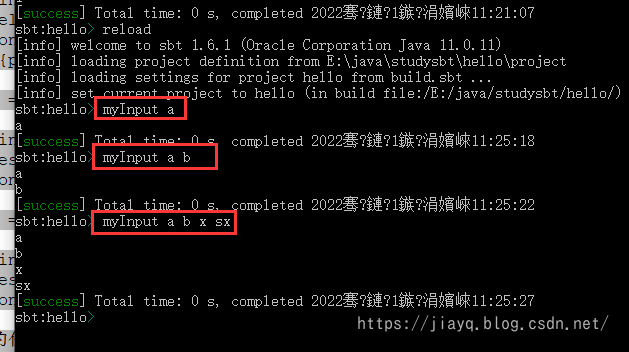
我们可以限定只能是指定的参数,比如我们只能输入test作为参数
// 定义只能接受指定参数
lazy val separator: Parser[String] = "test"
lazy val myInput2 = inputKey[Unit]("myInput2")
myInput2 := {
val args = separator.parsed
args foreach println
}
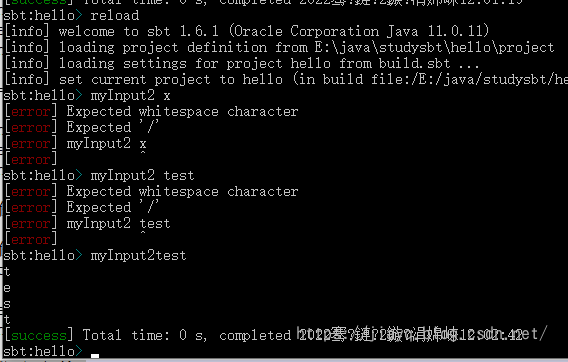
理论上默认的空格分割基本上就足够了。
sbt 作用域
在sbt中作用域有四种:Projects,Configurations,Tasks以及默认的全局Global
首先我们来看看在sbt中如何查看作用域
使用inspect name查看项目中name的作用域
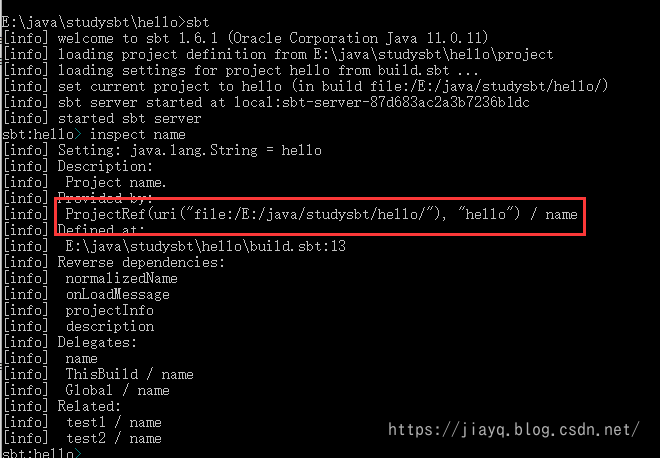
注意红色框中的内容就是name的作用域的描述,遵循以下格式
{<build-uri>}<project-id>/config:intask::key
-
{<build-uri>}/<project-id> 标识 project 轴。如果 project 轴有构建全局 scope,将没有 <project-id> 部分。
-
config 标识 configuration 轴。
-
intask 标识 task 轴。
-
key 标识 scope 下的 key。
我们可以看出,name的作用域是project级别的,而且属于hello项目
我们切换到test1项目,查看test1的name的作用域
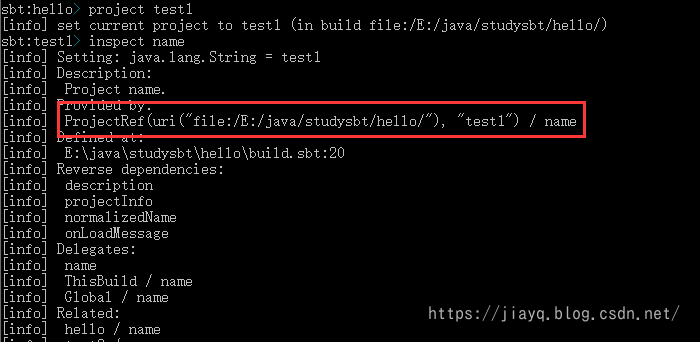
发现是test1项目下的
我们在看看compile的作用域
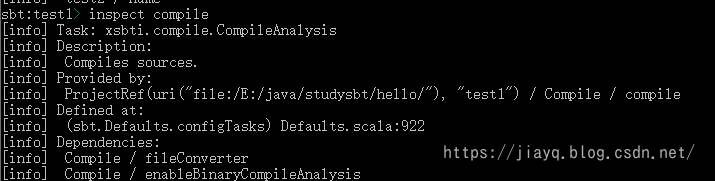
发现compile是configuration中的Compile作用域
如何指定作用域
在build.sbt中可以使用/指定作用域,同时/等价于in方法
比如我们创建一个基于compile的version
Compile / version := "2.0"
我们重新加载,并查看作用域
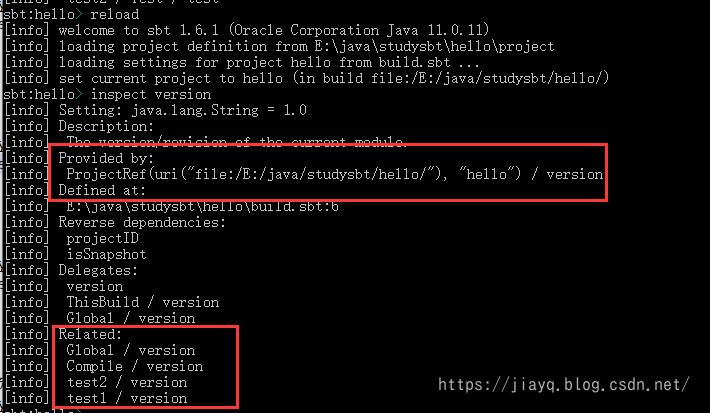
发现我们查看的依然是project作用域的version,这是因为我们在配置project的时候就配置了一个version
但是在下面也展示了,我们还有Compile级别的version
我们可以使用inspect Compile/version来查看Compile作用域下的version
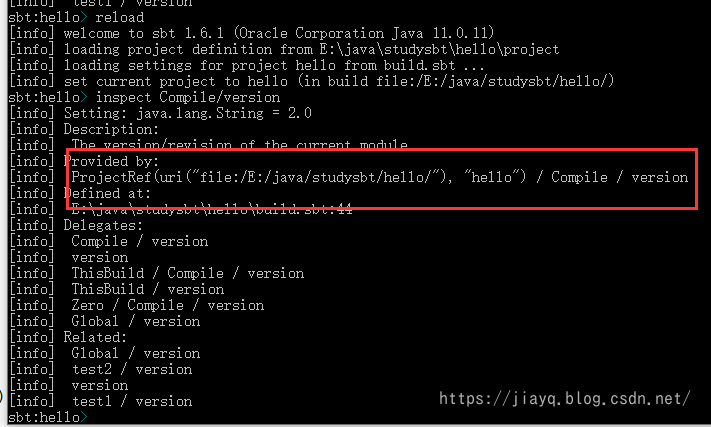
当然,我们还可以通过Global设置全局的作用域
Global / version := "3.0"
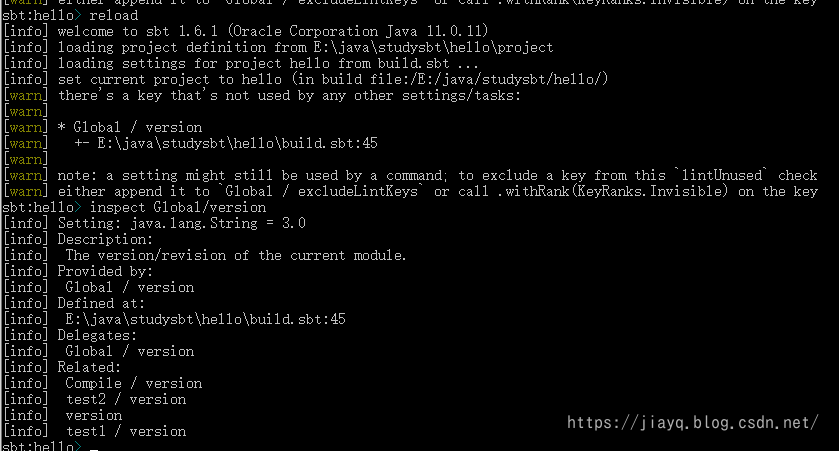
再比如我们设置一个Task的作用域
myTask / version := "4.0"
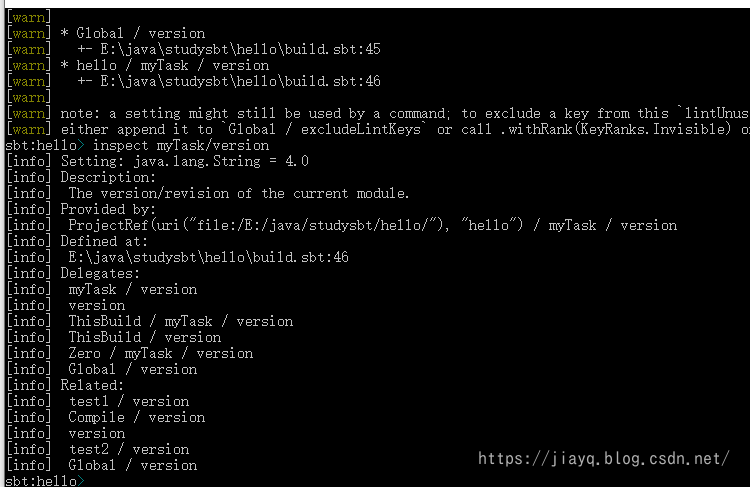
如何使用
我们在上面设置了不同作用域下的version值,那么我们在使用的时候,如何指定我们需要使用哪一个呢?
还记得我们前面说的inputTask吗,尝试一下
// 定义 conf 作用域的 version
Compile / version := "2.0"
// global 作用域
Global / version := "3.0"
// task 作用域
myTask / version := "4.0"
// 定义一个 inputTask
lazy val specPrint = inputKey[Unit]("specPrint")
// 限定 specPrint 这个 inputTask 只能接受 以下的参数
lazy val partners: List[Parser[String]] = List(" global", " task", " pro", " conf")
// 将参数使用 | 选择方法整合
lazy val specSeparator = partners.reduce(_ | _)
specPrint := {
// 使用整合后的解析器解析输入的参数,然后进行模式匹配
specSeparator.parsed match {
// 匹配后使用 / 的方式限定作用域,然后使用 value 获取值,最后使用 println 输出
case " global" => println((Global / version).value)
case " task" => println((myTask / version).value)
case " pro" => println(version.value)
case " conf" => println((Compile / version).value)
}
}
别忘记空格哦
重新加载后,我们首先获取pro级别的,期望输出 1.0,conf级别期望输出2.0,global级别期望输出3.0,task级别期望输出4.0
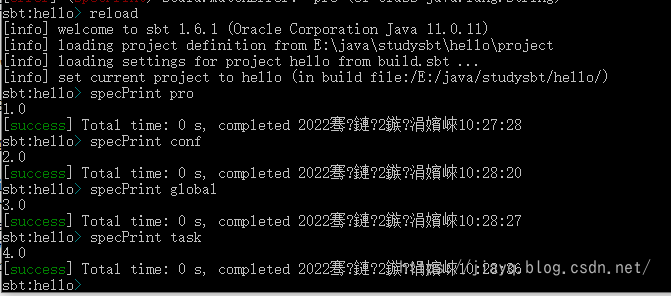
完全符合我们的预期。
sbt 插件
什么是插件?
在官方文档的解释中,第一句就是插件继承了构建,其实看到这里就足够了,我们可以人为插件就是封装后的构建配置,可以是配置值,也可以是一些操作,一些task等等。
所以插件就是将为了实现某个目的而封装的通用的构建定义。
可能不太准确
如何添加插件
使用addSbtPlugin方法
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "1.1.0")
需要注意的是,我们必须在project目录下创建一个.sbt文件,然后将上面的内容放进去,直接放在build.sbt中是不会生效的
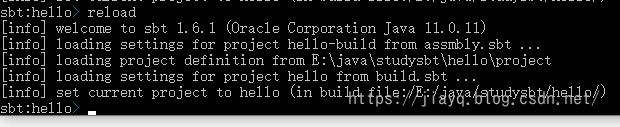
特别需要注意的是,有些插件是放在maven仓库中的或者是默认的插件仓库中,比如上面的sbt-assembly插件,直接使用maven的仓库就能下载
如果你有多个插件,也没有必要每个插件都创建一个.sbt文件,可以把多个插件在一个.sbt文件中添加
还记得sbt的仓库配置吗?
[repositories]
local
huaweicloud-maven: https://repo.huaweicloud.com/repository/maven/
maven-central: https://repo1.maven.org/maven2/
sbt-plugin-repo: https://repo.scala-sbt.org/scalasbt/sbt-plugin-releases, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext]
而有些插件则不在上述仓库中,比如sbt-site,它是在typesafe仓库中,你添加仓库后,会导致长时间无法下载的
你可以把typesafe的仓库也加入到配置中,比如
[repositories]
local
huaweicloud-maven: https://repo.huaweicloud.com/repository/maven/
maven-central: https://repo1.maven.org/maven2/
sbt-plugin-repo: https://repo.scala-sbt.org/scalasbt/sbt-plugin-releases, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext]
typesafe: https://dl.bintray.com/typesafe/ivy-releases/ , [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly
需要注意的是在高版本的sbt中仓库必须是https协议的,否则就会异常
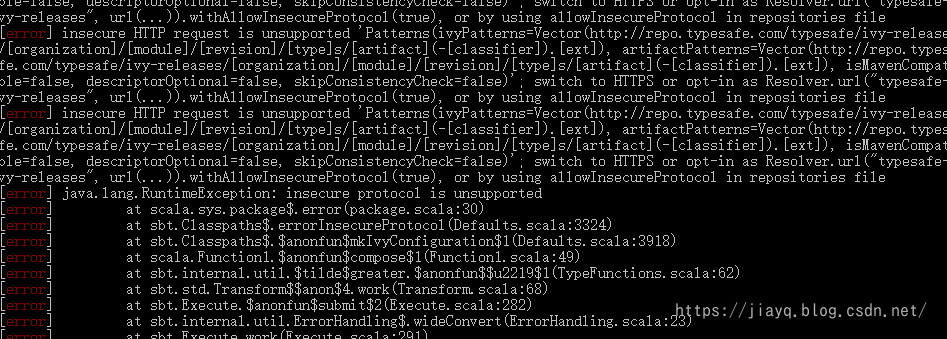
如果你的仓库地址是http开头的,不放换成https开头。
太新的插件也可能面临仓库中没有的问题
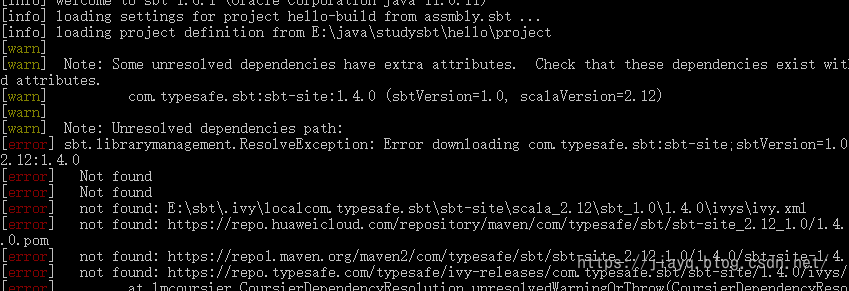
你可以设置多个仓库源,只需要保证仓库源的名字不重复即可,比如
[repositories]
local
huaweicloud-maven: https://repo.huaweicloud.com/repository/maven/
maven-central: https://repo1.maven.org/maven2/
typesafe: https://dl.bintray.com/typesafe/ivy-releases/ , [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly
typesafe-ivy-releases: https://repo.typesafe.com/typesafe/ivy-releases/, [organization]/[module]/[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly
sbt-plugin-repo: https://repo.scala-sbt.org/scalasbt/sbt-plugin-releases, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext]
而且在下载插件或者依赖失败的时候,不妨多update几次,或许有一次就成功了
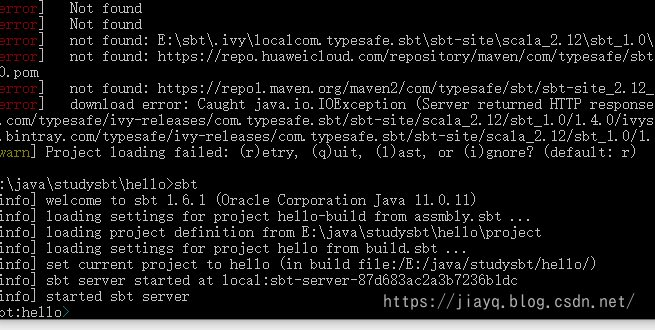
上面修改仓库是针对sbt做的修改,如果你不想配置全部项目都使用的仓库,那么可以在.sbt文件中使用resolvers += "Example Plugin Repository" at "https://example.org/repo/"为项目设置仓库地址
这个使用方式和依赖的仓库配置是相同的,但是需要保证仓库名字不重复。
查看添加的插件
使用plugins可以查看项目中添加的插件
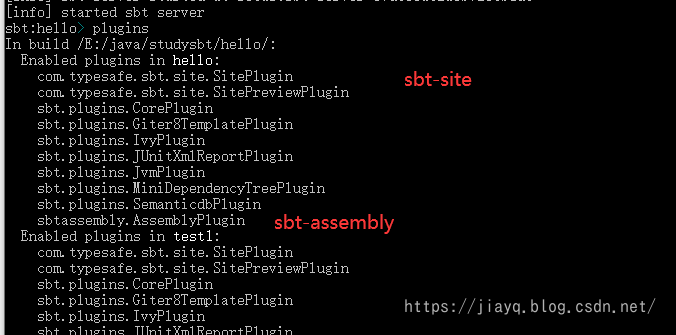
给插件设置作用域
现在查看插件,全部的插件都会被加入
比如我只想给test1项目增加插件sbt-alldocs
非常遗憾的是sbt并不支持给单独的某个项目添加插件,但是支持某个插件在某个项目中是否启用
我们在project目录下的.sbt文件中加入sbt-allDocs插件,并在build.sbt文件中启用或者禁用(大部分插件是默认启用的)
lazy val hello = (project in file(".")).aggregate(test1)
.disablePlugins(AllDocsPlugin)
.settings(
commonSettings,
name := "hello",
organization := "com.study.sbt.hello",
myTask := {println("hello task key")}
)
lazy val test1 = (project in file("test1"))
.enablePlugins(AllDocsPlugin)
.settings(
commonSettings,
name := "test1",
organization := "com.study.sbt.test1"
)
lazy val test2 = (project in file("test2")).dependsOn(test1 % "compile->compile")
.disablePlugins(AllDocsPlugin)
.settings(
commonSettings,
name := "test2",
organization := "com.study.sbt.test2"
)
启用enablePlugins,禁用disablePlugins
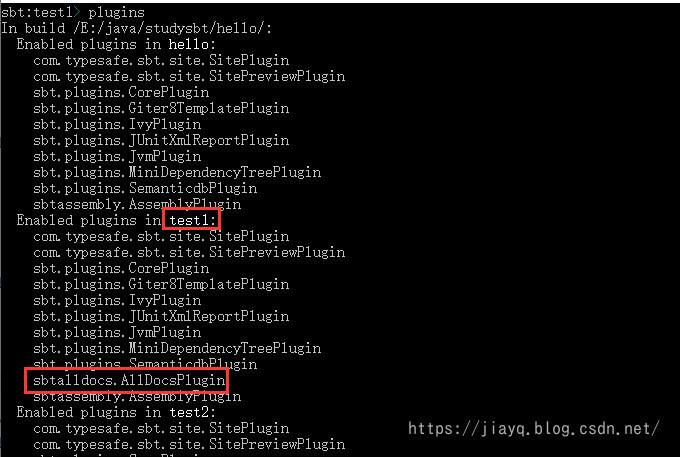
此时虽然在test1中加入了sbt-allDocs插件,但是正如插件名字一样,这是一个自动插件,不管在哪个项目中都可以使用。
只有一些不是自动插件,需要手动加入项目的插件,才不能在项目中使用。
但是考虑到插件本身的定义就是通用,这种需要手动加入的非自动的插件一般都是旧的插件。一个典型的例子是sbt-site.
插件列表
说了这么多,有哪些插件可以使用呢?
可以在sbt 参考手册 — 社区插件 (scala-sbt.org)查看全部的插件。
说到这里不得不吐槽一下sbt官方文档了,之前认为sbt文档有中文版很好,但是没想到中文版的文档是阉割的
中文文档目录
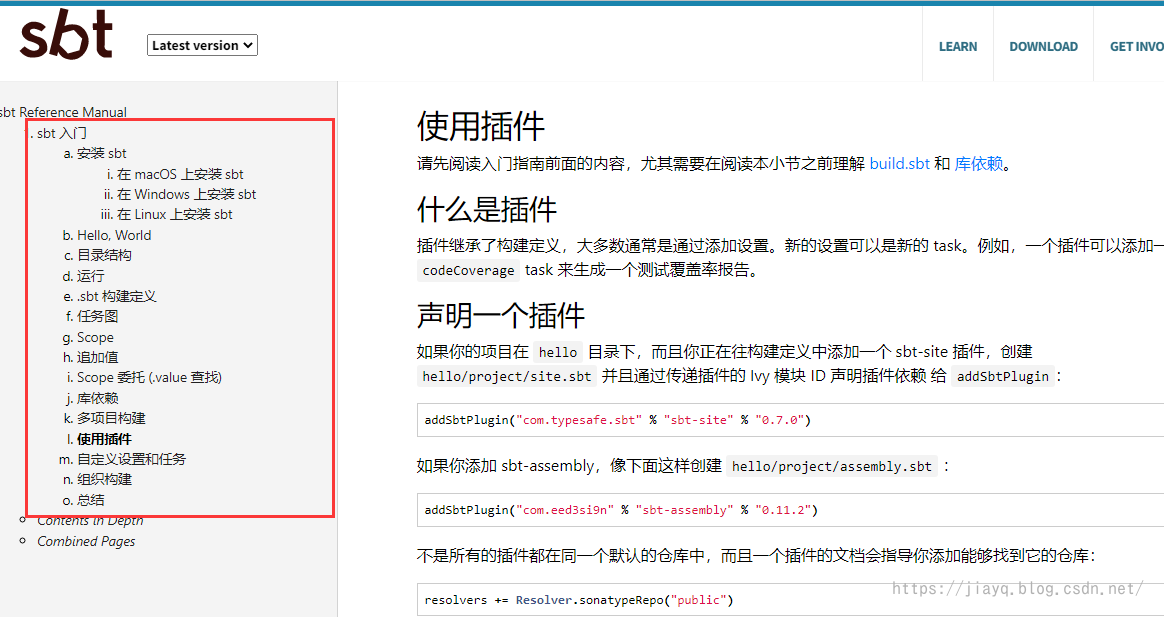
英文文档的目录
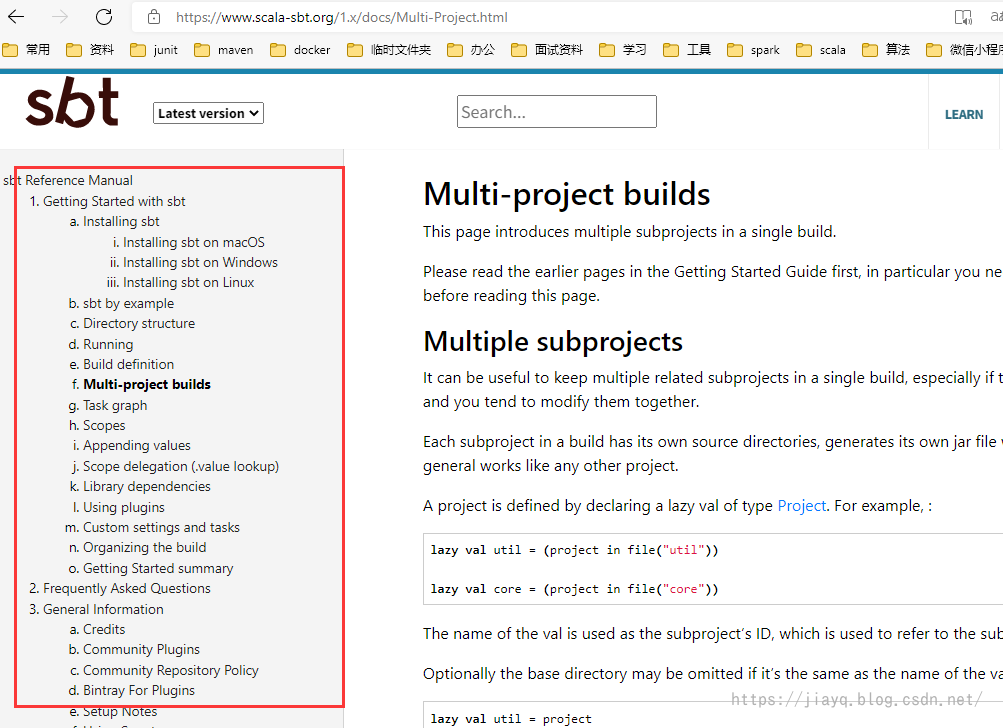
可以看到中文文档只包含了第一块内容,剩余的都没有。这就导致在中文文档中你想点击超链接查看更详细的信息的时候,一般是跳转不了的。你只能在英文文档中点击跳转。
相比之下,日文文档比中文文档多,但是也有缺失
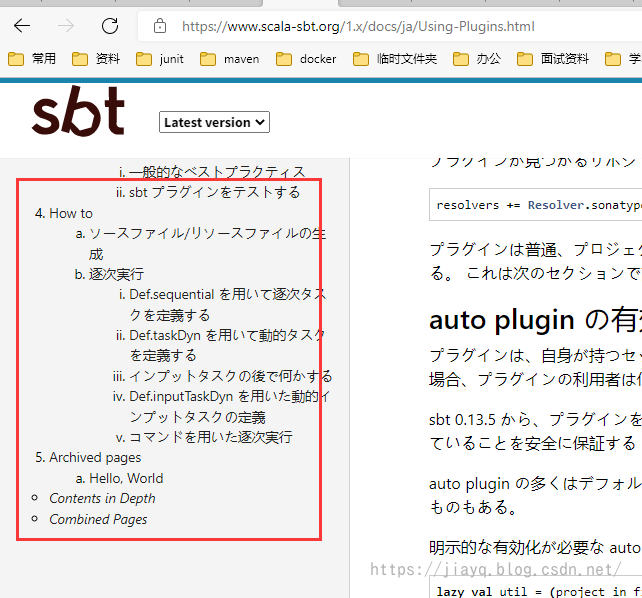
英文文档可以有八大块内容呢

期待各位翻译其他内容,补全缺失的中文内容。
插件使用
一般在插件列表界面中可以点击插件跳转到插件自己的页面,比如sbt-allDocs
sbt-alldocs/build.sbt at master · glngn/sbt-alldocs · GitHub
一般都是github项目,说到这里,与maven相比,sbt的插件较少,官方开发的插件没有maven插件那么多
怎么使用在插件自己的界面中会有
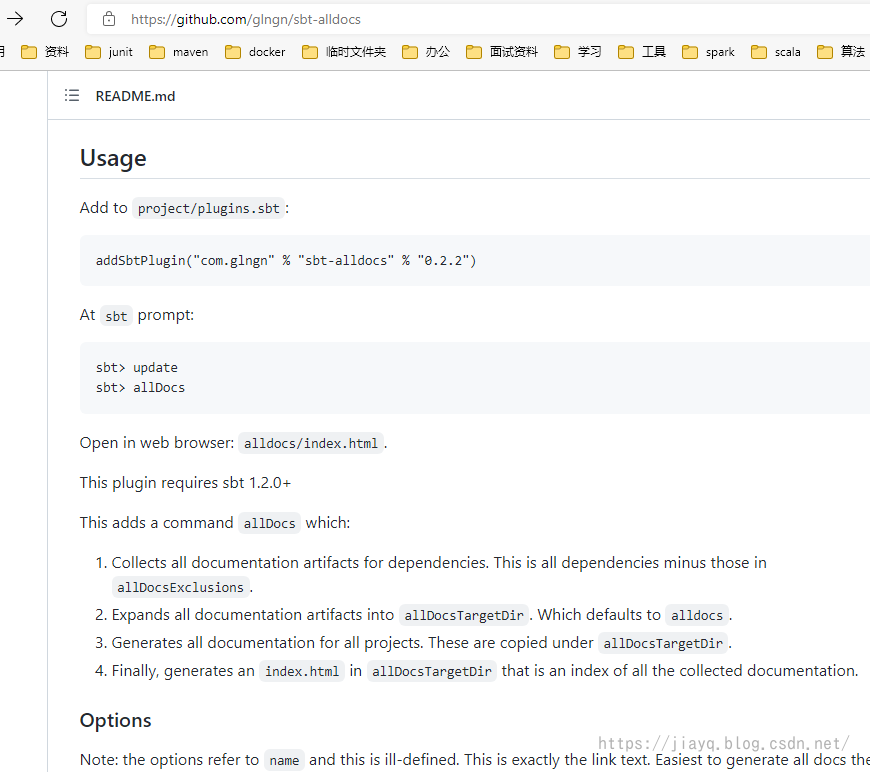
当然用的更多,更经典的可能是sbt-assembly插件,其插件自己的文档也是说的非常明白。
说真的,sbt-assembly插件还是很强大的,后面有机会得好好研究研究使用。
总结
刚开始接触sbt,觉得sbt好难啊,网上相关的资料也比较少,尝试在慕课网找相关的付费课程,也没有找到。
而官网的中文文档,翻译水平不怎么样,和网页自动翻译插件翻译水平不相上下,加上中文文档缺失较多,看起来比较费劲的。比如作用域的理解,配置理解,任务理解等等。
当然sbt入门还是很简单的,但是真正的想达到类似maven一样使用,还是有一定的难度的。
sbt东西还是不少的,加上sbt基于scala编写,入门学习的难度真的不小,特别是我这种不太了解scala语法的,有时候更是看不明白。
当我慢慢学习sbt后,竟然觉得sbt比maven要简洁的多,在maven中要实现多项目管理等,与sbt相比,还是稍微有点繁琐。当然这个繁琐不能认为是maven的问题,而是maven采用了xml进行配置,而sbt使用增强的scala进行配置,所以显得简洁。
然而sbt的社区确实没有maven那么活跃,从网上资料,从插件数量上可见一斑。
再就是sbt本身是scala开发的,所以不知道怎么滴也继承了scala的特点,sbt有两个大的分支,0.x和1.x,比如0.13.18和1.6.1
我个人猜测是因为使用不同的scala编写的,因为scala的二进制不兼容导致sbt不得不维护两个大的版本。这个猜测没有依据,也可能不是scala的原因呢。
不要被sbt吓到,尝试理解sbt后,你会慢慢的改变对它的看法的,相信我。