【翻译 adaltas.com中Aida NGOM所写的《Comparaison of different file formats in Big Data》】
在数据处理中,有不同类型的文件格式来存储您的数据集。每种格式都有自己的优缺点,具体取决于用例,并且存在用于一个或多个目的。在选择特定格式类型时,了解并利用它们的特性非常重要。
某些格式与某些用途或处理更相关,例如在商业智能、网络通信、Web 应用程序、批处理或流处理中。例如,CSV格式非常容易理解,虽然每个人都批评其缺乏形式主义,但它仍然被广泛使用。在 Web 通信的情况下,即使在某些情况下 XML 可能会做同样的工作,JSON也是特权并涵盖了世界上大部分的通信。最新的格式受益于庞大的工具生态系统,并在企业界广泛使用。在流处理方面,AVRO和Protocol Buffers是一种特权格式。此外,protocol buffers 是gRPC的基础(RPC 代表远程过程调用)依赖于Kubernetes生态系统。最后,ORC和Parquet提供的列存储显着提升了数据分析的性能。
选择文件格式时要考虑的因素
描述了最流行和最具代表性的文件格式,并在选择一种格式而不是另一种格式时要牢记各种注意事项。但首先,让我们回顾一下它们在存储、查询类型、批处理与流使用等方面的主要特征……
文本 VS 二进制
基于文本的文件格式更易于使用。最终用户可以读取它们,他们也可以使用文本编辑器修改文件内容。这些格式通常被压缩以减少它们的存储空间。二进制文件格式需要创建和使用工具或库,但它们通过优化数据序列化提供更好的性能。
数据类型
某些格式不允许声明多种类型的数据。类型分为 2 类。标量类型保存一个“单一”值(例如整数、布尔值、字符串、空值……)。复杂类型是标量类型(例如数组、对象等)的组合。声明值的类型提供了一些优势。消费者可以区分例如数字与字符串或空值与字符串“null”。一旦以二进制形式编码,存储增益就非常显着。例如,字符串"1234"使用 4 个字节的存储空间,而布尔值1234只需要 2 个字节。
模式强制
模式可以与数据相关联,也可以留给假定知道并理解如何解释数据的消费者。它可以与数据一起提供或单独提供。模式的使用保证数据集有效并提供额外的信息,例如值的类型和格式。模式还用于二进制文件格式来加密和解密内容。
支持模式演变
模式存储每个属性及其类型的定义。除非您的数据保证永远不会改变(例如档案)或本质上是不可变的(例如日志),否则您需要考虑模式演变,以便确定您的数据模式是否会随时间发生变化。换句话说,模式演化允许更新用于写入新数据的模式,同时保持与旧数据模式的向后兼容性。
行列存储,OLTP 与 OLAP
在基于行的存储中,数据是逐行存储的,这样行的第一列将紧挨着前一行的最后一列。这种架构适用于轻松快速地添加数据。它也适用于需要同时访问或处理整行数据的情况。这通常用于在线事务处理 (OLTP)。OLTP 系统通常在记录级别处理 CRUD 查询(读取、插入、更新和删除)。OLTP 事务通常在它们执行的任务中非常具体,并且通常涉及单个记录或一小部分记录。OLTP 系统的主要重点是在多访问环境中维护数据完整性,以及通过每秒事务数衡量的有效性。
相反,在基于列的存储中,数据的存储方式是,列的每一行都将与同一列的其他行相邻。这在执行只需要在非常大的数据集上检查列的子集的分析查询时最有用。这种处理数据的方式通常称为OLAP(OnLine Analytical Processing)询问。OLAP 是一种旨在快速回答涉及多个维度的分析查询的方法。这种方法在商业智能分析中发挥了关键作用,尤其是在大数据方面。通过忽略不适用于特定查询的所有数据,将数据存储在列中可以避免在数据集中读取无关信息的处理时间过长。它还通过对齐相同类型的数据和优化null稀疏列的值来提供更大的压缩率。
下面是一个示例,用于找出人口超过 100 万的城市的平均人口密度。对于面向行的存储,您的查询会遍历表中的每条记录(即其所有字段),以从三个相关列(即city name、density和population)中获取必要的信息。这将涉及大量不必要的磁盘搜索和读取,从而影响性能。列数据库通过减少从磁盘读取的数据量来优化该过程。
按颜色对记录分组的示例
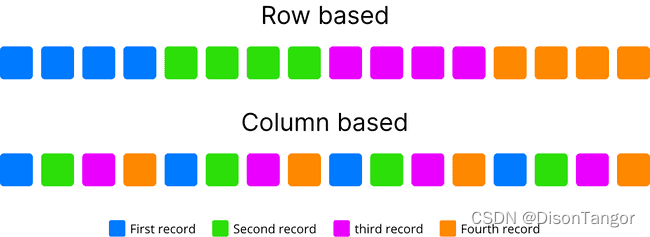
按颜色分组属性的示例
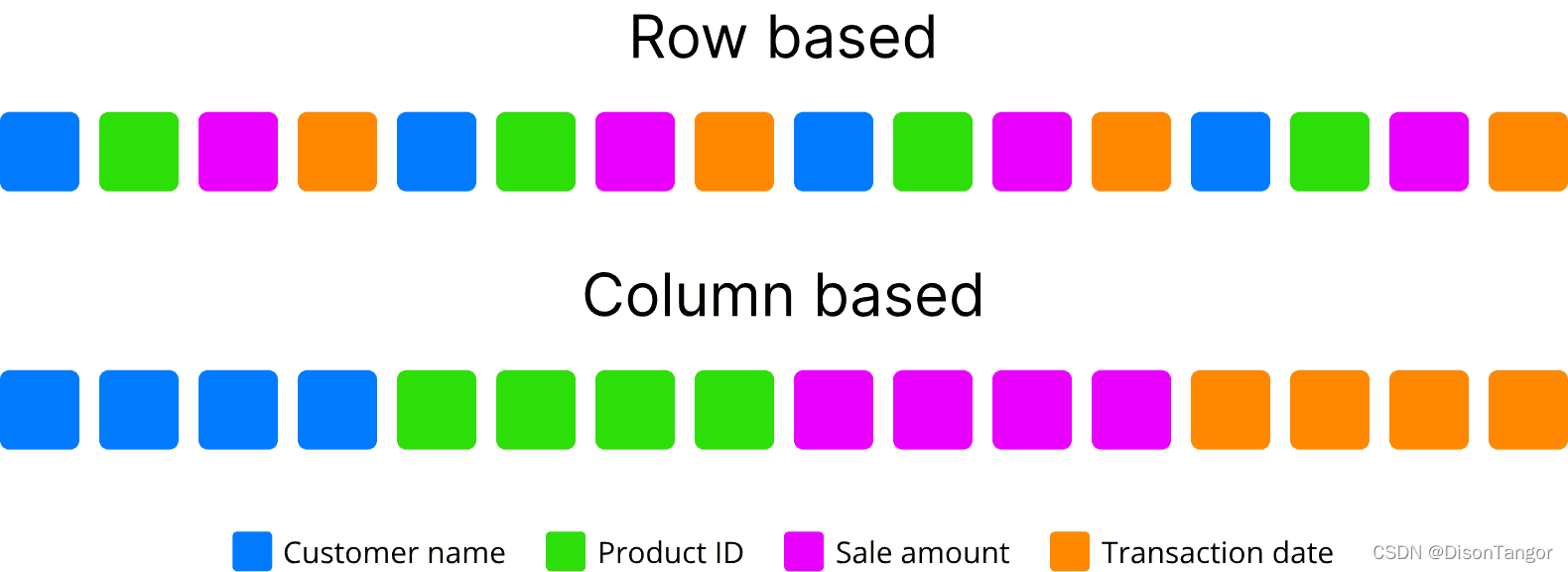
可拆分
在像Hadoop HDFS这样的分布式文件系统中,拥有一个可以分成几个部分的文件很重要。在 Hadoop 中,HDFS 文件系统将数据存储在块中,数据处理最初是根据这些块进行分配的。能够在文件中的任何一点开始读取数据有助于充分利用 Hadoop 分布式处理的优势。当文件格式不可拆分时,用户有责任将他的数据分成几个文件以启用并行性。
压缩(Bzip2、LZO、Sappy……)
一个系统的速度很慢,因为它的组件最慢,而且在大多数情况下,最慢的组件是磁盘。使用压缩可以减少存储的数据集的大小,从而减少要执行的读取 IO 量。它还可以加快网络上的文件传输速度。与基于行的存储相比,基于列的存储带来更高的压缩率和更好的性能,因为类似的数据存储在一起。如前所述,它对包含多个null值的稀疏列特别有效。
此外,压缩主要适用于文本文件格式,除非二进制文件格式在其定义中包含压缩。尝试压缩二进制文件通常会导致生成的文件与其原始文件相比更重。此外,在比较压缩率时,我们还必须考虑原始文件的大小。如果我们不考虑 XML 最初比其对应的 JSON 大,那么比较 JSON 和 XML 的压缩率就没什么意义了。
有很多种压缩算法,它们根据压缩率、速度、性能、可拆分等而有所不同……
批处理和流媒体
批处理一次读取、分析和转换多个记录。相反,流处理实时工作并在记录到达时对其进行处理。有时,同一个数据集可能会以流媒体和批处理的方式进行处理。让我们考虑在系统内收到的金融交易。数据到达 Streaming 并可以立即处理以检测欺诈检测。补充,一旦数据被存储,一个作业可以定期批量运行以准备一些报告。在这种情况下,我们可能会依赖一种或两种文件格式,即通过线路到达的数据格式和存储在我们的数据仓库或数据湖中的数据格式。
生态系统
在多种替代方案之间进行选择时,尊重生态系统的使用和文化通常被认为是一种很好的做法。例如,在 Parquet 或 ORC 与 Hive 之间进行选择时,建议在 Cloudera 平台上使用前者,在 Hortonworks 平台上使用后者。很有可能集成会更顺利,并且来自社区的文档和支持会很有帮助。
流行的文件格式
CSV文件
CSV 是一种文本格式,它使用换行符作为带有可选标题的记录分隔符。手动编辑很容易,从人的角度来看也很容易理解。CSV 不支持模式演变,即使有时标题被认为是数据的模式。在其复杂的形式中,它不可拆分,因为它不包含特定字符,您可以根据该字符在保持相关性的同时拆分文本。
一般在大数据中,CSV 似乎是用来处理的,但严格来说,它更接近于TSV格式。该差异这两个格式之间的微妙。
CSV 格式不是完全标准化的格式。例如,它的字段分隔符可以是冒号或分号。当字段本身也可能包含这些类型的引号甚至嵌入的换行符时,解析就变得困难了。此外,字段数据可以用引号括起来。这些引用有时会引发与识别句子开头或结尾甚至空值的数据无关的结构。与 TSV 不同,CSV在其数据中包含一个转义字符 (\)。因此,所有这些不同的考虑使得解析变得复杂。然而,TSV 通常由制表或逗号分隔,它不支持转义字符。这允许轻松区分每个字段并最终有助于比 CSV 更容易解析。这就是它主要用于大数据案例的原因。
- 优势
- 弊端
- 不支持空值,等同于空值
- 没有可拆分的保证,也没有模式演化支持
- 非标准格式,每个人都有自己的解释
- 生态系统
CSV格式的案例
Player Name;Position;Nicknames;Years Active
Skippy Peterson;First Base;"""Blue Dog"", ""The Magician""";1908-1913
Bud Grimsby;Center Field;"""The Reaper"", ""Longneck""";1910-1917
Vic Crumb;Shortstop;"""Fat Vic"", ""Icy Hot""";1911-1912
JSON(JavaScript 对象表示法)
JSON 是一种包含记录的文本格式,记录可能有多种形式(字符串、整数、布尔值、数组、对象、键值、嵌套数据……)。由于人类和机器可读,JSON 是相对轻量级的格式,并且在 Web 应用程序中享有特权。它被许多软件广泛支持,并且在多种语言中实现起来相对简单。JSON 本身支持序列化和反序列化过程。
它的主要不便在于不可拆分。在这种情况下,替代使用的格式通常是JSON 行。这一行包含多行,其中每一行都是一个有效的 JSON 对象,由换行符\n分隔。由于 JSON 保证在被序列化的数据中不存在换行符,我们可以使用这些字符的存在将数据集拆分为多个块。
- 优势
- JSON 是一个简单的语法,它可以被任何文本编辑器打开
- 有许多工具对验证这个模式有效
- JSON可被压缩并用作数据交换的格式
- 它支持批处理和流处理
- 它将元数据与数据一起存储并支持模式演化
- 与 XML 相比,JSON 是基于文本的轻量级格式
- 弊端
- JSON 不可拆分,并且像许多文本格式一样缺乏索引
- 生态系统
- 它是 Web 应用程序的特权格式
- JSON 是一种广泛用于 NoSQL 数据库(例如 MongoDB、Couchbase 和 Azure Cosmos DB)的文件格式。或者例如,在MongoDB 中,使用 BSON 代替标准格式。MongoDB 的这种架构比结构化数据库更容易修改,因为Postgres需要提取整个文档进行更改。确实,BSON 是类 JSON 文档的二进制编码。它被索引并允许比标准 JSON 更快地被解析。但是,这并不意味着您不能将 MongoDB 视为 JSON 数据库。
- JSON 也是GraphQL 中使用的一种语言,它依赖于完全类型化的数据。GraphQL 是一种 API 查询语言。您可以发送查询以在一个请求中准确获取您正在寻找的数据,而不是使用严格的服务器定义的端点。
分别显示 JSON 格式和 JSON Lines 格式的示例
{
"fruits": [{
"kiwis": 3,
"mangues": 4,
"pommes": null
},
{
"panier": true
}],
"legumes": {
"patates": "amandine",
"poireaux": false
},
"viandes": [
"poisson","poulet","boeuf"
]
}
{"id":1,"father":"Mark","mother":"Charlotte","children":["Tom"]}
{"id":2,"father":"John","mother":"Ann","children":["Jessika","Antony","Jack"]}
{"id":3,"father":"Bob","mother":"Monika","children":["Jerry","Karol"]}
XML
XML 是W3C创建的一种标记语言,用于定义对人类和机器可读的文档进行编码的语法。XML 允许定义越来越复杂的语言。它还能够建立用于在应用程序之间交换的标准文件格式。
与 JSON 一样,XML 也用于序列化和封装数据。相对于其他替代“基于文本”的格式,它的语法很冗长,尤其是对于人类读者。
- 优势
- 支持批处理/流处理。
- 沿数据存储元数据并支持模式演变。
- 作为一种冗长的格式,与 JSON 文件或其他文本文件格式相比,它提供了良好的压缩率。
- 弊端
- 不可拆分,因为 XML 在开头有一个开始标签,在结尾有一个结束标签。您不能在这些标签中间的任何一点开始处理。
- 当数据量很大时,语法的冗余性会导致更高的存储和传输成本。
- XML 名称空间使用起来有问题。命名空间的支持很难在 XML 解析器中正确实现。
- 解析困难,需要选择和使用适当的 DOM 或 SAX 解析器。
- 生态系统
XML 示例
<?xml version="1.0" encoding="UTF-8"?>
<scientists>
<!-- Some important physicists -->
<scientist id="phys0">
<name firtname="Galileo" lastname="Galilei" />
<dates birth="1564-02-15" death="1642-01-08" />
<contributions>Relativity of movement & heliocentric system</contributions>
</scientist>
</scientists>
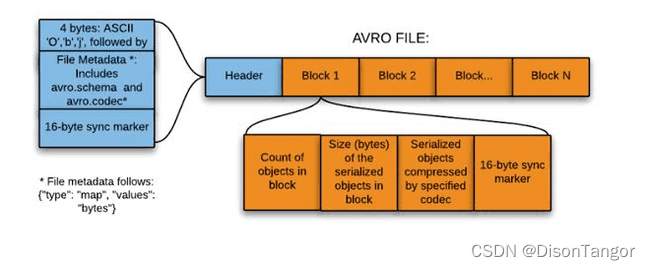
Avro
Avro 是在Apache 的 Hadoop 项目中开发的框架。它是一种基于行的存储格式,被广泛用作序列化过程。AVRO 以 JSON 格式存储其架构,使其易于被任何程序读取和解释。数据本身以二进制格式存储,使其紧凑且高效。AVRO 的一个关键特性与它可以轻松处理模式演化这一事实有关。它将元数据附加到每个记录中的数据中。
- 优势
- Avro 是一个数据序列化系统。
- 它是可拆分的(AVRO 有一个同步标记来分隔块)并且可压缩。
- Avro 是用于数据交换的良好文件格式。它具有非常紧凑、快速且高效的数据存储,可用于分析。
- 它高度支持模式演化(在不同时间和独立)。
- 它支持批处理并且与流媒体非常相关。
- 以 JSON 定义的 Avro 模式,易于阅读和解析。
- 数据总是伴随着模式,允许对数据进行全面处理。
- 弊端
- 生态系统
- 广泛用于许多应用程序(Kafka、Spark 等)。
- Avro 是一个远程过程调用 ( RPC )。
Protocol Buffers
Protocol Buffers 由 Google 开发并于 2008 年开源。它是语言中立的,是一种序列化结构化数据的可扩展方式。它用于通信协议、数据存储等。它很容易被人类阅读和理解。与 Avro 不同,模式需要解释数据
- 优势
- 数据是完全类型化的。
- Protobuf 支持模式演化和批处理/流处理。
- 主要用于序列化数据,如AVRO。
- 拥有预定义和更大的数据类型集,在 Protobuf 上序列化的消息可以由负责交换它们的代码自动验证。
- 弊端
- 不可拆分且不可压缩。
- 没有 Map Reduce 支持。
- 需要带有架构的参考文件。
- 不是为处理大消息而设计的。由于它不支持随机访问,即使您只想访问特定项目,您也必须阅读整个文件。
- 生态系统
- 工具可用于大多数编程语言,如 JavaScript、Java、PHP、C#、Ruby、Objective C、Python、C++ 和 Go。
- 在Kubernetes生态系统中广泛使用的gRPC 的基础。
-
ProfaneDB是 Protocol Buffers 对象的数据库。
syntax = "proto3";
message dog {
required string name = 1;
int32 weight = 2;
repeated string toys = 4;
}
Parquet
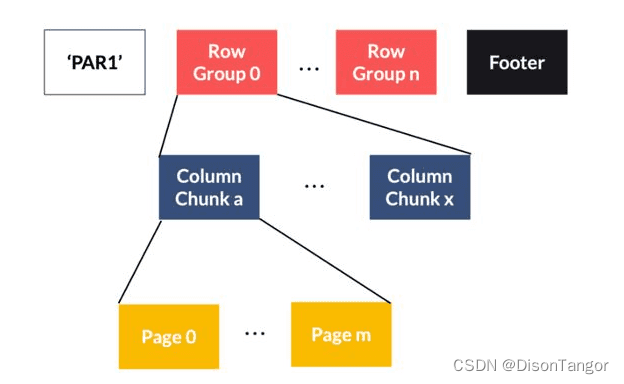
Parquet 是 Hadoop 生态系统的开源文件格式。它的设计是 Twitter 和Cloudera 的共同努力,用于高效的分析数据存储。Parquet 像 ORC 格式一样按列存储数据。它提供了高效的数据压缩和编码方案,并具有增强的性能来处理大量复杂数据。Parquet 是一个二进制文件,包含有关其内容的元数据。列元数据存储在文件的末尾,这样可以进行快速的一次性写入。Parquet 针对一次写入多次读取 (WORM) 的范例进行了优化。
- 优势
- 可拆分的文件。
- 按列组织,允许更好的压缩,因为数据更均匀。
- OLAP 工作负载的高效率。
- 支持模式演化。
- 仅限于批处理。
- 弊端
- 不是人类可读的。
- 除非您删除并重新创建,否则很难应用更新。
- 生态系统
- BI(商业智能)的高效分析。
- 对于 Spark 等处理引擎,读取速度非常快。
- 通常与 Spark、Impala、Arrow 和 Drill 一起使用。
Parquet格式的结构
ORC(优化行列式)
ORC 格式由Hortonworks与 Facebook 合作创建并开源。它是一种类似于 Parquet 的面向列的数据存储格式。ORC 文件包含称为条带的行数据组,以及文件页脚中的辅助信息。在文件的末尾,附言包含压缩参数和压缩页脚的大小。默认条带大小为 250 MB。大条带大小支持从 HDFS 进行大量高效读取。
- 优势
- 高度可压缩,将原始数据的大小减少多达 75%。
- OLAP 比 OLTP 查询更有效。
- 仅限于批处理。
- 弊端
- 无法添加数据而无需重新创建文件。
- 不支持模式演化。
- Impala目前不支持 ORC 格式。
- 生态系统
- 对商业智能工作负载的有效分析。
- ORC 提高了 Hive 中读取、写入和处理的性能。
ORC格式的结构

结论
适当文件格式的选择与与每种文件格式的属性相关的查询类型(用例)有关。通常,面向行的数据库非常适合类似 OLTP 的工作负载,而面向列的系统非常适合 OLAP 查询。由于其列存储类型在每列中包含一个统一类型,因此与基于行的存储相比,列格式在压缩方面会更好。
在比较方面,如果您希望使用文本格式,那么当您控制数据类型(没有带有特殊字符的文本)时,JSON 行和最终的 CSV 是不错的选择。除非数据源强加它,否则避免选择 XML。它实际上不用于数据处理,因为它的高复杂性通常需要自定义解析器。在流处理和数据交换中,如果你想要灵活而强大的格式,请选择Avro。它还为模式演化提供了很好的支持。虽然 Protocol Buffers 在流式处理工作负载方面很高效,但它不可拆分且不可压缩,这使得它对静态数据的存储吸引力较小。最后,ORC 和镶木地板格式针对商业智能分析进行了优化。
总之,要记住的主要考虑因素是选择文件格式取决于用例。
概述
| 类型 |
CSV文件 |
JSON |
XML |
Avro |
Protocol Buffers |
Parquent |
ORC |
| 文本VS二进制 |
文本 |
文本 |
文本 |
JSON 元数据,二进制数据 |
文本 |
二进制 |
二进制 |
| 数据类型 |
no |
yes |
no |
yes |
yes |
yes |
yes |
| 模式强制 |
no(最小带标题) |
外部验证 |
外部验证 |
yes |
yes |
yes |
yes |
| 模式演变 |
non |
yes |
yes |
yes |
non |
yes |
non |
| 存储类型 |
row |
row |
row |
row |
row |
column |
column |
| OLAP/OLTP |
OLTP |
OLTP |
OLTP |
OLTP |
OLTP |
OLAP |
OLAP |
| 可拆分 |
Yes,最简单的形式 |
Yes,带有 JSON 行 |
non |
yes |
non |
yes |
yes |
| 压缩 |
yes |
yes |
yes |
yes |
yes |
yes |
yes |
| 批处理 |
yes |
yes |
yes |
yes |
yes |
yes |
yes |
| 流处理 |
yes |
yes |
non |
yes |
yes |
non |
non |
| 输入数据 |
non |
non |
non |
non |
yes |
non |
non |
| 生态系统 |
因其简单性而广受欢迎 |
API和网络 |
企业 |
大数据和流媒体 |
RPC 和 Kubernetes |
大数据和商业智能 |
大数据和商业智能 |