尽管diffusion model在各类任务中都有着优秀的表现,它仍还有自己的缺点,并有诸多研究对diffusion model进行了改善。为了系统地阐明diffusion model的研究进展,我们总结了原始扩散模型的三个主要缺点,采样速度慢,最大化似然差、数据泛化能力弱,并提出将的diffusion models改进研究分为对应的三类:采样速度提升、最大似然增强和数据泛化增强。我们首先说明改善的动机,再根据方法的特性将每个改进方向的研究进一步细化分类,从而清楚的展现方法之间的联系与区别。在此我们仅选取部分重要方法为例, 我们的工作中对每类方法都做了详细的介绍,内容如图所示:
二. 扩散模型基础
生成式建模的一个核心问题是模型的灵活性和可计算性之间的权衡。扩散模型的基本思想是正向扩散过程来系统地扰动数据中的分布,然后通过学习反向扩散过程恢复数据的分布,这样就了产生一个高度灵活且易于计算的生成模型。
A. Denoising Diffusion Probabilistic Models(DDPM) 去噪扩散概率模型
一个DDPM由两个参数化马尔可夫链组成,并使用变分推断以在有限时间后生成与原始数据分布一致的样本。前向链的作用是扰动数据,它根据预先设计的噪声进度向数据逐渐加入高斯噪声,直到数据的分布趋于先验分布,即标准高斯分布。反向链从给定的先验开始并使用参数化的高斯转换核,学习逐步恢复原数据分布。用 x0 ~ q(x0)  表示原始数据及其分布,则前向链的分布是可由下式表达:
表示原始数据及其分布,则前向链的分布是可由下式表达:

这说明前向链是马尔可夫过程, xt 是加入t步噪音后的样本, βt 是事先给定的控制噪声进度的参数。当 ∏t1−βt 趋于1时, xT 可以近似认为服从标准高斯分布。当 βt 很小时,逆向过程的转移核可以近似认为也是高斯的:
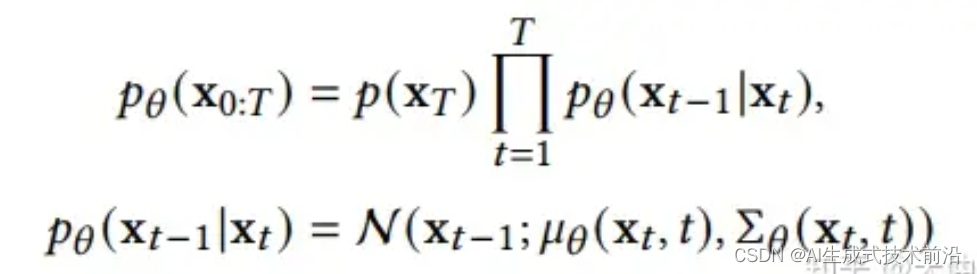
B. Score-Based Generative Models(SGM)
上述DDPM可以视作SGM的离散形式。SGM构造一个随机微分方程(SDE)来平滑的扰乱数据分布,将原始数据分布转化到已知的先验分布: