Python
Java
PHP
IOS
Android
Nodejs
JavaScript
Html5
Windows
Ubuntu
Linux
Hudi学习3:数据湖主流架构
2023-11-02
delta Lake
Iceberg
iceberg表可以扩展
Hudi
支持flink,并且支持快速upsert/ delete
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)
hudi
数据湖
Hudi学习3:数据湖主流架构 的相关文章
阿里资深架构师答疑:数据湖概相关念、特征、架构与案例
写在前面 最近 数据湖的概念非常热 许多前线的同学都在讨论数据湖应该怎么建 阿里云有没有成熟的数据湖解决方案 阿里云的数据湖解决方案到底有没有实际落地的案例 怎么理解数据湖 数据湖和大数据平台有什么不同 头部的云计算玩家都各自推出了什么样的
Hudi:初识Hudi
是什么 Hudi是什么 可以说Hudi是一个数据湖或是数据库 但它又不是数据湖或是数据库 笔者理解为Hudi是除开计算引擎的Hive 众所周知 Hive是一个计算框架 但是现在我们更多的是使用Spark基于Hive对HDFS中文件提供的Sc
Hudi学习1:概述
Hudi 概念 Hudi跟hive很像 不存储数据 只是管理hdfs数据 1 小文件处理 2 增加支持update delete等操作 3 实时数据写入 以下是官方点介绍 Apache Hudi 是一个支持插入 更新 删除的增量数据湖处理框
一文讲清数据集市、数据湖、数据网格、数据编织
本文介绍数据仓库 数据集市 数据湖 数据网格和数据编织相关概念和使用案例 帮助你选择并利用好数据的力量来完成明智的决策 微信搜索关注 Java学研大本营 在今天的数字时代 企业每天都在应对来自四面八方的海量数据 随着对强大的数据管理和分析需
Data Lake数据湖详解2.0
一 什么是数据湖 数据湖是目前比较热的一个概念 许多企业都在构建或者计划构建自己的数据湖 但是在计划构建数据湖之前 搞清楚什么是数据湖 明确一个数据湖项目的基本组成 进而设计数据湖的基本架构 对于数据湖的构建至关重要 关于什么是数据湖 有不
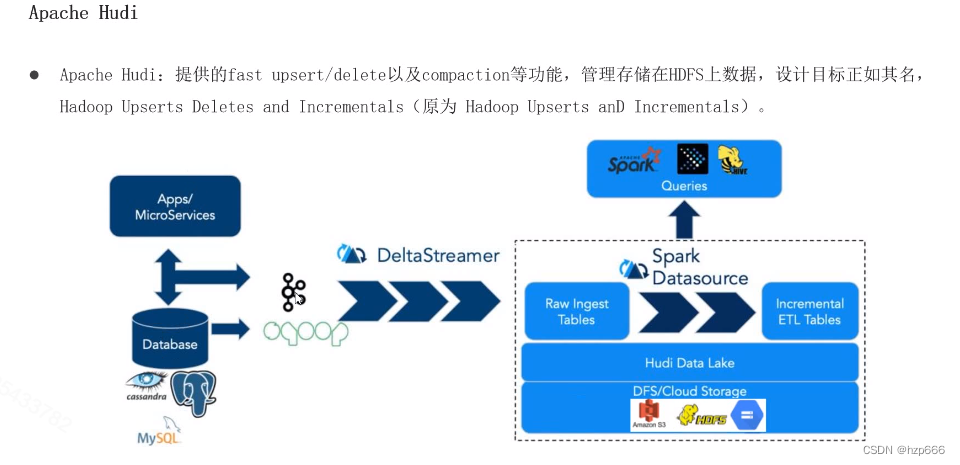
1、Apache Hudi简介
1 Hudi简介 Hudi是Hadoop Updates and Incrementals的缩写 用于管理HDFS上的大型分析数据集存储 主要目的是高效的减少入库延时 Hudi是一个开源Spark三方库 支持在Hadoop上执行upsert
用户画像技术干货
1 用户画像是什么 在互联网步入大数据时代后 用户行为给企业的产品和服务带来了一系列的改变和重塑 其中最大的变化在于 用户的一切行为在企业面前是可 追溯 分析 的 企业内保存了大量的原始数据和各种业务数据 这是企业经营活动的真实记录 如何更
Hudi学习3:数据湖主流架构
delta Lake Iceberg iceberg表可以扩展 Hudi 支持flink 并且支持快速upsert delete
数据导入hudi报错,错将字段写到hdfs路径上
报错信息 Error trying to save partition metadata this is okay as long as atleast 1 of these succced file qiche hudi table 冬天
【2】数据湖架构中 Iceberg 的核心特性
在业界的数据湖方案中有 Hudi Iceberg 和 Delta 三个关键组件可供选择 一 Iceberg 是什么 Iceberg 官网中是这样定义的 Apache Iceberg is an open table format for h
基于Apache Hudi + MinIO 构建流式数据湖
Apache Hudi 是一个流式数据湖平台 将核心仓库和数据库功能直接引入数据湖 Hudi 不满足于将自己称为 Delta 或 Apache Iceberg 之类的开放文件格式 它提供表 事务 更新 删除 高级索引 流式摄取服务 数据聚簇
余老师带你学习大数据框架全栈第十三章Hudi第一节核心技术
1 前言 1 1为什么产生数据湖 数据量比较大 越来越不满足处理结构化的数据 比如说数仓 数仓就是处理结构化数据 什么是结构化数据 就是数据成数据库来的 传统型的数据库有 MySQL数据库 Oracle SQLserver 从这些库里面过来
Flink1.13.0 + Hudi 0.11.1 + Hive2.1.1 + presto0.273.3 + yanagishima 18.0
摘要 flink1 13 0 整合 Hudi 0 11 1 通过FlinkSQL程序 FlinkSQL命令行对Hudi的MOR及COW进行批量写 流式写 流式读取 批量读取 通过flink sql cdc flink sql kafka f
如何保障数仓数据质量?
有赞数据报表中心为商家提供了丰富的数据指标 包括30 页面 100 数据报表以及400 不同类型的数据指标 它们帮助商家更合理 科学地运营店铺 同时也直接提供分析决策方法供商家使用 并且 每天在跑的底层任务和涉及的数据表已经达到千级别 面对
hudi 编译
编译hudi 下载hudi git clone https github com apache incubator hudi git cd incubator hudi 编译 mvn clean install DskipTests Dsk
Hudi 0.12.0 搭建——集成 Hive3.1 与 Spark3.2
Hudi 搭建 https blog csdn net weixin 46389691 article details 128276527 环境准备 一 安装 Maven 1 解压 2 配置环境变量 3 修改 Maven 下载源 二 安装
数据湖架构之Hudi编译篇
前言 说起编译hudi 从第一遍过之后 再回过头来看 发现就是第一遍不熟悉 出现的一切问题可以总结为maven仓库没配置好 一开始我只是配置了阿里云仓库 但是后面不断报错 然后百度谷歌找原因 再调整配置 再编译 最后就成功了 所以整体来说编
数据湖--概念、特征、架构与案例概述
一 什么是数据湖 数据湖是目前比较热的一个概念 许多企业都在构建或者计划构建自己的数据湖 但是在计划构建数据湖之前 搞清楚什么是数据湖 明确一个数据湖项目的基本组成 进而设计数据湖的基本架构 对于数据湖的构建至关重要 关于什么是数据湖 有如
hudi-hive-sync
hudi hive sync Syncing to Hive 有两种方式 在hudi 写时同步 使用run sync tool sh 脚本进行同步 1 代码同步 改方法最终会同步元数据 但是会抛出异常 val spark SparkSess
机器学习之迁移学习(Transfer Learning)
概念 迁移学习 Transfer Learning 是一种机器学习方法 其核心思想是将从一个任务中学到的知识应用到另一个相关任务中 传统的机器学习模型通常是从头开始训练 使用特定于任务的数据集 而迁移学习则通过利用已经在一个任务上学到的知识
随机推荐
PCL 4PCS算法实现点云配准
4PCS算法 一 算法原理 1 算法流程 2 参考文献 二 代码实现 1 主要参数 2 完整代码 三 结果展示 四 相关链接 一 算法原理 1 算法流程 4PCS算法是计算机图形学中一种流行的配准工具 给定两个点集 P Q P Q
Android系统运动传感器
转自 https blog csdn net liang123l article details 53992197 Android平台提供了多种感应器 让你监控设备的运动 传感器的架构因传感器类型而异 重力 线性加速度 旋转矢量 重要运动
Windows 10 安装安卓子系统 WSA(Magisk/KernelSU)使用 WSA 工具箱安装 APK
from https blog zhjh top archives XokySA7Rc1pkVvnxAEP5E 前提是系统为 Windows 10 22H2 10 0 19045 2311 或更高版本 尽量新 步骤 使用 WSAPatch
android真机和模拟器(emulator)的判断
最近收到领导需求要判断真机和模拟器 先前项目里是有的 可能当时能用 但现在都不能用了 然后 baidu上能够找到的其实都不能用了 包括说使用cache来区分cpu架构是哈佛结构还是冯诺伊曼结构来判断的 这个其实是最不靠谱的 因为硬件结构是会
C语言函数大全-- p 开头的函数
p 开头的函数 1 perror 1 1 函数说明 1 2 演示示例 1 3 运行结果 2 pieslice 2 1 函数说明 2 2 演示示例 2 3 运行结果 3 pow powf powl 3 1 函数说明 3 2 演示示例 3 3
数据结构-冒泡排序,选择排序,插入排序,快速排序,希尔排序,堆排序
冒泡排序 冒泡排序的思想 从头开始数据两两比较 将大的放到后面小的放到前面 经过一轮比较后就找到了该序列的最大数且将它放到了最后 再循环上述步骤找出第二大的数 第三大的数 int maoapo int a int len a为数组的首地址
期货开户顺大市而逆小市
期货的行情 有人愿意以更高的价来买入 就会涨 有人买意以更低的价格卖出 就会跌 现货市场上 一个馒头5角钱的时候 在期货市场上 如果有很多人争着买 这个馒头可能会涨到5块 或者50块 也是可能的 在这个馒头5块钱一个的时候 你感觉这个馒头太
ShiroFilter设计原理与实现
Shiro提供了与Web集成的支持 其通过一个ShiroFilter入口来拦截需要安全控制的URL 然后进行相应的控制 ShiroFilter类似于如Strut2 SpringMVC这种web框架的前端控制器 其是安全控制的入口点 其负责读
Postgre 还原导入sql文件
postgresql 如何导入sql文件 打开sql shell 执行如下操作 密码不显示 直接输入完成后按回车键 i C Users fulong Desktop trest3 sql 注意路径不要使用 不支持这种写法
Linux Kernel SMP (Symmetric Multi-Processors) 開機流程解析 Part(3) Linux 多核心啟動流程從rest_init到kernel_init與CPU
http loda hala01 com 2011 08 android E7 AD 86 E8 A8 98 linux kernel smp symmetric multi processors E9 96 8B E6 A9 9F E6
Java-IO流篇-DataOutputStream
DataOutputStream DataOutputStreams是OutputStream的子类 是数据输出流 此类继承自FillterOutputStream类 同时实现DataOutput接口 在DataOutput接口定义了一系列
更新k8s证书(续签)
下载 kubeadm x86 md5 7951a9348655b4f508b84ced66fcf371kubeadm arm md5 b11c4ce93722b07f96c2acdeaaa07e74 cd etc kubernetes cp
iframe的基本介绍与使用
一 介绍 iframe 内嵌框架 是 HTML 中一种用于将一个网页嵌入到另一个网页中的标签 它可以在一个页面中显示来自其他页面的内容 在网页中 使用标签可以将一个网页嵌套在另一个网页中 实现网页间的互联互通 二 使用 标签的基本用法如下
MapReduce过程中setPartitionerClass、setSortComparatorClass和setGroupingComparatorClass三者关系
Map首先将输出写到环形缓存当中 开始spill过程 job setPartitionerClass PartitionClass class 按key分区 map阶段最后调用 对key取hash值 或其它处理 指定进入哪一个reduce
【测试开发】Junit 框架
目录 一 认识 Junit 二 Junit 的常用注解 1 Test 2 Disabled 3 BeforeAll 4 AfterAll 5 BeforeEach 6 AfterEach 7 执行测试 三 参数化 1 引入依赖 2 单参数
分析key原理
总结 key是虚拟dom对象的标识 当数据发生变化时 vue会根据新数据生成新的虚拟dom 随后vue进行新虚拟dom与旧虚拟dom的差异比较 比较规则 旧虚拟dom中找到了与新虚拟dom相同的key 若虚拟dom中的内容没变 直接使用之前
将一列具有相同数据的行合并到同一行
如何将第一列具有相同数据的行合并到同一行 但要保护重复内容 将重复内容依次填充到重复行中第一行后面 首列相同的 将后面对应列各单元格内容合并到重复行中第一行后对应的单元格内 并且用 连接 对应列只有一个单元格有内容 则不添加 符号 若为空
【sql】mysql索引问题笔记
q 使用了索引就会有优化 a 然而并不是这样 一下情况都是没有作用的 1 索引字段并没有在查询条件中使用 2 条件查询的过滤结果占比过多 既索引字段为可重复的字段 常固发生此情况 3 对小表查询 此处指索引建立在小表上 联查到数据多的表的时
Android(java方法)上实现mp4的分割和拼接 (二)
http blog csdn net banking17173 article details 20646251 这节谈一下如何在Android上实现mp4文件的高效率切割 业务需求举例 把一段2分钟的mp4文件切割出00 42 至 01
Hudi学习3:数据湖主流架构
delta Lake Iceberg iceberg表可以扩展 Hudi 支持flink 并且支持快速upsert delete
热门标签
泣神曲服务器维护
搭建环境相关
hg使用
hg 学习
http状态码
http请求方法
http报文
语言python
unity知识点
打Bug升级的程序猿
分布式记账
热门框架的使用
苹果证书
苹果签名
301跳转
ibatsi
动态库文件
多项目
分模块打包