一。基本概念
1.频数表是将数据集按照某个特定列分类(分组)时观察每个类/组中数据出现次数的表;
2.列联表是观测数据按两个或更多属性/定性变量分类时所列出的频数分布表,是由两个以上的变量进行交叉分类的频数分布表;
3.频数也称“次数”,对样本数据按某些属性进行分组,统计出各个组内含个体的个数,就是频数;
4.一维列联表就是频数分布表;
5.列联表分析的基本问题是:观察各属性之间是否独立,做简单的描述性统计。
二。创建频数表
频数表用于探索类别型变量,常用table()和 xtabs()来创建频数表:
1.table()使用N个类别变量(因子)创建一个N维列联表
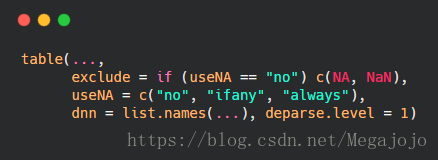
- ...:一个或多个可以被解释为factor的对象
- exclude:如果数据中不包括NA,切useNA未指定,则useNA="ifany"(有疑惑)
- useNA:table()默认忽略NA,要在频数统计中将NA视为一个有效类别,设定useNA="ifany"
- dnn:在结果中给维度的命名,向量形式
- deparse.level:取值为0(dnn名称为空),1(以dnn命名),2(deparse the argument)
2.xtabs()根据一个公式(~var1+var2+...+varN)创建一个N维列联表。
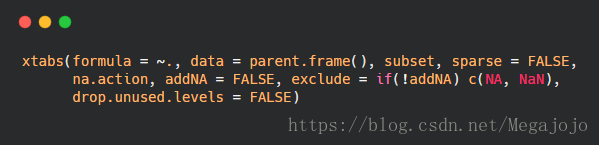
- formula:公式,要进行交叉分类的变量应出现在公式的右侧,即 ~ 符号的右方,以+ 作为分割符。
- data:包括有公式中变量名的矩阵或数据框
- subset:指定data中观测的子集
- sparse:指定结果是否为sparse matrix
- na.action:一个函数,指定当包括NA时发生什么。若未指定且addNA为TRUE,则结果为na.pass
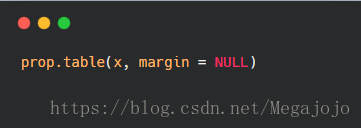
prop.table()以列联表作为参数,以margins定义的边际把列联表中的频数表示为比例关系。
margin.table()以列联表作为参数,以margins定义的边际列表来计算频数