目录
一、Jedis
1)获取Jedis
2)Jedis的基本使用
3)Jedis连接池使用
4)Jedis中Pipeline使用
5)Jedis的Lua脚本使用
二、Redisson
1、在SpringBoot中快速集成
2、增删改查操作
3、Redisson作为消息中间件
1)实战生产端代码
2)实战消费端代码
4、布隆过滤器
5、限流器
6、分布式锁
1)立即获取锁
2)可重入特性
3)等待放弃获取锁机制
4)自动释放锁
5)宕机情况
7、分布式集合
1)分布式集合列表RList
2)分布式集合映射RMap
3)RLocalCachedMap本地缓存映射
4)MapCache映射缓存
5)MultiMap多值映射
8、Remote Service分布式远程服务
Java有很多优秀的Redis客户端,这里介绍使用较为广泛的客户端Jedis和Redisson:
概念:
Jedis:是老牌的Redis的Java实现客户端,提供了比较全面的Redis命令的支持,
Redisson:实现了分布式和可扩展的Java数据结构。
优点:
Jedis:比较全面的提供了Redis的操作特性
Redisson:促使使用者对Redis的关注分离,提供很多分布式相关操作服务,例如:分布式锁,分布式集合,可通过Redis支持延迟队列
可伸缩:
Jedis:使用阻塞的I/O,且其方法调用都是同步的,程序流需要等到sockets处理完I/O才能执行,不支持异步。Jedis客户端实例不是线程安全的,所以需要通过连接池来使用Jedis。
Redisson:基于Netty框架的事件驱动的通信层,其方法调用是异步的。Redisson的API是线程安全的,所以可以操作单个Redisson连接来完成各种操作;
比较:
jedis 是直连 redis server,如果在多线程环境下是非线程安全的,这个时候只有使用连接池,为每个jedis实例增加物理连接 ;
Redisson 实现了分布式 和 可扩展的Java数据结构,和 Jedis 相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等Redis特性。Redisson 的宗旨是促进使用者对Redis的关注分离,从而让使用者能够将精力更集中地放在处理业务逻辑上。
一、Jedis
1)获取Jedis
Maven项目为例,在项目中加入下面的依赖即可,引入版本选择比较稳定的版本,选择更新活跃的第三方开发包,例如Redis有了Redis Cluster新特性,但是如果使用的客户端一直不支持,并且维护的人也比较少,这种就谨慎选择。
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.8.2</version>
</dependency>
2)Jedis的基本使用
代码实现:
# 1. 生成一个Jedis对象,这个对象负责和指定Redis实例进行通信
Jedis jedis = new Jedis("127.0.0.1", 6379);
# 2. jedis执行set操作
jedis.set("hello", "world");
# 3. jedis执行get操作, value="world"
String value = jedis.get("hello");
我们可以看到初始化Jedis需要两个参数:Redis实例的IP和端口,除了这两个参数外,还有一个包含了四个参数的构造函数是比较常用的:
Jedis(final String host, final int port, final int connectionTimeout, final int
soTimeout)
·host:Redis实例的所在机器的IP
·port:Redis实例的端口
·connectionTimeout:客户端连接超时
·soTimeout:客户端读写超时
我们在实际项目中比较推荐使用try catch finally(或者用try catch 语法糖)的形式来进行代码的书写:一方面可以在Jedis出现异常的时候(本身是网络操作),将异常进行捕获或者抛出;另一个方面无论执行成功或者失败,将Jedis连接关闭掉,在开发中及时关闭不用的连接资源,想了解异常处理机制的可以参考:http://t.csdn.cn/Opbpc;
例如:
Jedis jedis = null;
try {
jedis = new Jedis("127.0.0.1", 6379);
jedis.get("hello");
} catch (Exception e) {
logger.error(e.getMessage(),e);
} finally {
if (jedis != null) {
jedis.close();
}
}
Jedis对于Redis五种数据结构的操作:
// 1.string 输出结果:OK
jedis.set("hello", "world");
// 输出结果:world
jedis.get("hello");
// 输出结果:1
jedis.incr("counter");
// 2.hash
jedis.hset("myhash", "f1", "v1");
jedis.hset("myhash", "f2", "v2");
// 输出结果:{f1=v1, f2=v2}
jedis.hgetAll("myhash");
// 3.list
jedis.rpush("mylist", "1");
jedis.rpush("mylist", "2");
jedis.rpush("mylist", "3");
// 输出结果:[1, 2, 3]
jedis.lrange("mylist", 0, -1);
// 4.set
jedis.sadd("myset", "a");
jedis.sadd("myset", "b");
jedis.sadd("myset", "a");
// 输出结果:[b, a]
jedis.smembers("myset");
// 5.zset
jedis.zadd("myzset", 99, "tom");
jedis.zadd("myzset", 66, "peter");
jedis.zadd("myzset", 33, "james");
// 输出结果:[[["james"],33.0], [["peter"],66.0], [["tom"],99.0]]
jedis.zrangeWithScores("myzset", 0, -1);
Jedis还提供了字节数组的参数:
public String set(final String key, String value)
public String set(final byte[] key, final byte[] value)
public byte[] get(final byte[] key)
public String get(final String key)
通过这些API的支持将Java对象序列化为二进制,当应用需要获取Java对象时,使用get(final byte[]key)函数将字节数组取出, 然后反序列化为Java对象即可。Jedis本身没有提供序列化的工具开发者需要自己引入序列化的工具。序列化的工具有很多例如XML、Json;
3)Jedis连接池使用
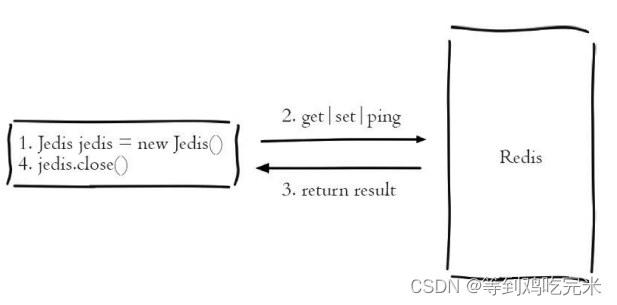
上面介绍的是Jedis的直连方式,所谓直连是指Jedis每次都会新建 TCP连接,使用后再断开连接,对于频繁访问Redis的场景显然不是高效的使用方式;因此生产环境中一般使用连接池的方式对Jedis连接进行管理,所有Jedis对象预先放在池子中(JedisPool),每次要连接Redis,只需要在池子中借,用完了在归还给池子。
Jedis连接池使用方式:
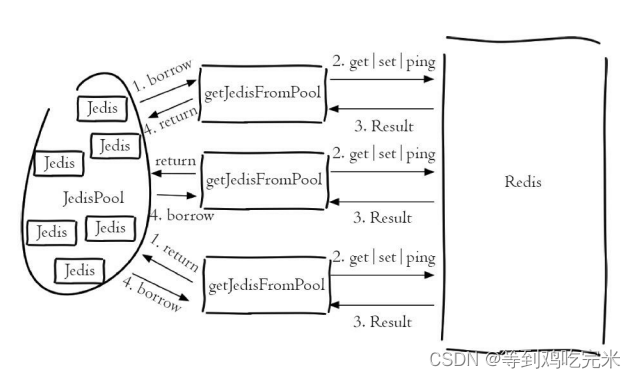
客户端连接Redis使用的是TCP协议,直连的方式每次需要建立TCP 连接,而连接池的方式是可以预先初始化好Jedis连接,所以每次只需要从Jedis连接池借用即可,而借用和归还操作是在本地进行的,只有少量的并发同步开销,远远小于新建TCP连接的开销。另外直连的方式无法限制Jedis对象的个数,在极端情况下可能会造成连接泄露,而连接池的形式可以有效的保护和控制资源的使用。
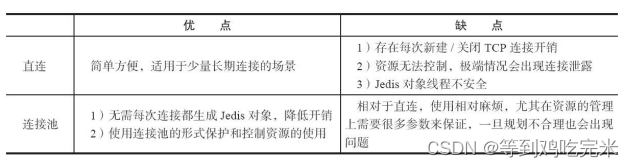
Jedis提供了JedisPool这个类作为对Jedis的连接池,同时使用了 Apache的通用对象池工具common-pool作为资源的管理工具,下面是使用JedisPool操作Redis的代码示例:
1)Jedis连接池(通常JedisPool是单例的):
// common-pool连接池配置,这里使用默认配置,后面小节会介绍具体配置说明
GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig();
// 初始化
Jedis连接池
JedisPool jedisPool = new JedisPool(poolConfig, "127.0.0.1", 6379);
2)获取Jedis对象不再是直接生成一个Jedis对象进行直连,而是从
连接池直接获取,代码如下:
Jedis jedis = null;
try {
// 1. 从连接池获取
jedis对象
jedis = jedisPool.getResource();
// 2. 执行操作
jedis.get("hello");
} catch (Exception e) {
logger.error(e.getMessage(),e);
} finally {
if (jedis != null) {
// 如果使用
JedisPool,
close操作不是关闭连接,代表归还连接池
jedis.close();
}
}
可以看到在finally中依然是jedis.close()操作,Jedis的close()实 现方式如下:
public void close() {
// 使用
Jedis连接池
if (dataSource != null) {
if (client.isBroken()) {
this.dataSource.returnBrokenResource(this);
} else {
this.dataSource.returnResource(this);
}
// 直连
} else {
client.close();
}
}
·dataSource!=null代表使用的是连接池,所以jedis.close()代表归
还连接给连接池,而且Jedis会判断当前连接是否已经断开。
·dataSource=null代表直连,jedis.close()代表关闭连接。
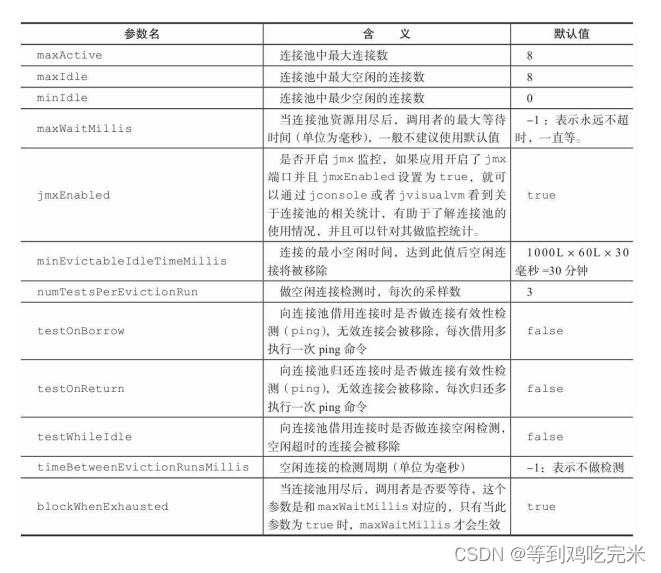
前面GenericObjectPoolConfig使用的是默认配置,实际它提供有很 多参数,例如池子中最大连接数、最大空闲连接数、最小空闲连接数、 连接活性检测:
GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig();
// 设置最大连接数为默认值的5倍
poolConfig.setMaxTotal(GenericObjectPoolConfig.DEFAULT_MAX_TOTAL * 5);
// 设置最大空闲连接数为默认值的3倍
poolConfig.setMaxIdle(GenericObjectPoolConfig.DEFAULT_MAX_IDLE * 3);
// 设置最小空闲连接数为默认值的2倍
poolConfig.setMinIdle(GenericObjectPoolConfig.DEFAULT_MIN_IDLE * 2);
// 设置开启jmx功能
poolConfig.setJmxEnabled(true);
// 设置连接池没有连接后客户端的最大等待时间(单位为毫秒)
poolConfig.setMaxWaitMillis(3000);
4)Jedis中Pipeline使用
Jedis支持Pipeline特性,我们知道 Redis提供了mget、mset方法,但是并没有提供mdel方法,如果想实现这 个功能,可以借助Pipeline来模拟批量删除,虽然不会像mget和mset那样 是一个原子命令,但是在绝大数场景下可以使用。下面代码是mdel删除 的实现过程。
public void mdel(List<String> keys) {
Jedis jedis = new Jedis("127.0.0.1");
// 1)生成
pipeline对象
Pipeline pipeline = jedis.pipelined();
// 2)pipeline执行命令,注意此时命令并未真正执行
for (String key : keys) {
pipeline.del(key);
}
// 3)执行命令
pipeline.sync();
}
·利用jedis对象生成一个pipeline对象,直接可以调用
jedis.pipelined()。
·将del命令封装到pipeline中,可以调用pipeline.del(String key),
这个方法和jedis.del(String key)的写法是完全一致的,只不过此时不
会真正的执行命令。
·使用pipeline.sync()完成此次pipeline对象的调用。
除了pipeline.sync(),还可以使用pipeline.syncAndReturnAll()
将pipeline的命令进行返回,例如下面代码将set和incr做了一次pipeline操
作,并顺序打印了两个命令的结果:
Jedis jedis = new Jedis("127.0.0.1");
Pipeline pipeline = jedis.pipelined();
pipeline.set("hello", "world");
pipeline.incr("counter");
List<Object> resultList = pipeline.syncAndReturnAll();
for (Object object : resultList) {
System.out.println(object);
}
输出结果为:
OK
1
5)Jedis的Lua脚本使用
Jedis中执行Lua脚本和redis-cli十分类似,Jedis提供了三个重要的函 数实现Lua脚本的执行:
Object eval(String script, int keyCount, String... params)
Object evalsha(String sha1, int keyCount, String... params)
String scriptLoad(String script)
eval函数有三个参数,分别是:
- ·script:Lua脚本内容。
- ·keyCount:键的个数。
- ·params:相关参数KEYS和ARGV。
//以一个最简单的Lua脚本为例子进行说明:
return redis.call('get',KEYS[1])
//在redis-cli中执行上面的Lua脚本,方法如下:
127.0.0.1:6379> eval "return redis.call('get',KEYS[1])" 1 hello "world"
//在Jedis中执行,方法如下:
String key = "hello";
String script = "return redis.call('get',KEYS[1])";
Object result = jedis.eval(script, 1, key);
// 打印结果为 world
System.out.println(result)
//scriptLoad和evalsha函数要一起使用,首先使用scriptLoad将脚本加载到Redis中,代码如下:
String scriptSha = jedis.scriptLoad(script);
evalsha函数用来执行脚本的SHA1校验和,它需要三个参数:
- ·scriptSha:脚本的SHA1。
- ·keyCount:键的个数。
- ·params:相关参数KEYS和ARGV。
Stirng key = "hello";
Object result = jedis.evalsha(scriptSha, 1, key);
// 打印结果为 world
System.out.println(result);
redis客户端使用总结:
1)Jedis操作放在try catch finally里更加合理。
2)区分直连和连接池两种实现方式优缺点。
3)jedis.close()方法的两种实现方式。
4)Jedis依赖了common-pool,有关common-pool的参数需要根据不 同的使用场景,各不相同,需要具体问题具体分析。
5)如果key和value涉及了字节数组,需要自己选择适合的序列化方法。
二、Redisson
Redisson的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。
1、在SpringBoot中快速集成
(1)导入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.8.2</version>
</dependency>
(2)在SpringBoot中增加RedisClient配置类。我这里是单机部署的方法,集群配置方式以及更多属性的配置
@Configuration
@Component
public class RedissonConfig {
private static final Logger LOGGER = LoggerFactory.getLogger(RedissonConfig.class);
/**
* https://github.com/redisson/redisson/wiki/
*/
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer().setAddress("yourRedisUrl:port");
//.setPassword("yourRedisPwd");
RedissonClient redisson = Redisson.create(config);
return redisson;
}
}
2、增删改查操作
创建一个比较简单的Controller。User对象以及UserMapper自己生成一下,User有两三个简单的属性,UserMapper就是对User对象对应的数据库表进行的增删改查操作。
@RestController
@RequestMapping(value = "redisson")
public class BaseController {
private static final Logger LOGGER = LoggerFactory.getLogger(BaseController.class);
private static final String USER_BUCKET_KEY = "USER_BUCKET_KEY::";
@Autowired
private MUserMapper userMapper;
@Autowired
private RedissonClient redisson;
}
每个Redisson对象实例都会有一个与之对应的Redis数据实例。Redisson的分布式RBucket对象是一种通用对象桶可以用来存放任类型的对象。
先来写新增和查询。先通过redisson对象通过getBucket方法,在Redis中创建一个字符串类型的对象。这个对象的引用就是下面的bucket,它可以存放任意的MUser对象实体。RBucket桶的神奇功能是:可直接存储MUser对象,省略了我们的MUser对象转为JSON字符串的过程。RBucket对象可以视为Redis中的 String类型,每个RBucket对象对应着一个值。
- 先插入数据库,操作成功后,将MUser对象通过RBucket存放到Redis中。
- 查询的时候,通过KEY找到桶。再通过get() 方法取出缓存在Redis中的 指定的KEY的VALUE。
- 修改就是通过KEY找到这个桶RBucket,然后重新SET一下。
- 删除更简单了,找到这个桶,调用delete相关方法即可。
@PostMapping("/addUser")
public Integer insert(@RequestBody MUser user) {
user.setId(null);
int res = userMapper.insertSelective(user);
if (res > 0) {
RBucket<MUser> bucket = redisson.getBucket(USER_BUCKET_KEY + user.getId());
//塞入缓存
bucket.set(user);
}
return user.getId();
}
@GetMapping("/getUser")
public MUser insert(@RequestParam Integer userId) {
RBucket<MUser> bucket = redisson.getBucket(USER_BUCKET_KEY + userId);
if (bucket != null) {
return bucket.get();
}
return null;
}
@PostMapping("/updateUser")
public Integer update(@RequestBody MUser user) {
int res = userMapper.updateByPrimaryKeySelective(user);
if (res > 0) {
RBucket<MUser> bucket = redisson.getBucket(USER_BUCKET_KEY + user.getId());
//更新缓存
bucket.set(user);
}
return user.getId();
}
@PostMapping("/deleteUser")
public MUser delete(@RequestParam Long id) {
int res = userMapper.deleteByPrimaryKey(id);
MUser user = null;
if (res > 0) {
RBucket<MUser> bucket = redisson.getBucket(USER_BUCKET_KEY + id);
//删除并获取
user = bucket.getAndDelete();
}
return user;
}
3、Redisson作为消息中间件
1)实战生产端代码
技术参考文档。
RTopic topic = redisson.getTopic("anyTopic");
topic.addListener(SomeObject.class, new MessageListener<SomeObject>() {
@Override
public void onMessage(String channel, SomeObject message) {
//...
}
});
// 在其他线程或JVM节点
RTopic topic = redisson.getTopic("anyTopic");
long clientsReceivedMessage = topic.publish(new SomeObject());
核心代码TopicService。方法上接受一个用户对象。然后通过Redisson客户端的getTopic方法获取RTopic对象。最后把我们需要推送的MUser对象,使用RTopic对象的publish方法加入到消息队列中。可参考上面的文档。
@Service
public class TopicService {
@Autowired
private RedissonClient redisson;
public void sendEmail(MUser user) {
if (user != null && StringUtils.isNotBlank(user.getEmail())) {
RTopic<MUser> topic = redisson.getTopic(Constant.REDISSON_EMAIL);
topic.publish(user);
}
}
}
2)实战消费端代码
技术参考文档:
RTopic topic = redisson.getTopic("anyTopic");
topic.addListener(SomeObject.class, new MessageListener<SomeObject>() {
@Override
public void onMessage(String channel, SomeObject message) {
//...
}
});
为了让我们有一个类似监听器的对象,我们可以实现一个叫做ApplicationRunner接口,然后这个实现类就会一直在内存中。实现Ordered接口为其制定顺序,因为可能有多个ApplicationRunner接口的实现类。
@Service
public class TopicListener implements ApplicationRunner, Ordered {
private static final Logger LOGGER = LoggerFactory.getLogger(TopicListener.class);
@Autowired
private RedissonClient redisson;
@Override
public void run(ApplicationArguments applicationArguments) throws Exception {
RTopic<MUser> topic = redisson.getTopic(Constant.REDISSON_EMAIL);
topic.addListener(new MessageListener<MUser>() {
@Override
public void onMessage(CharSequence charSequence, MUser user) {
LOGGER.info("Redisson监听器收到消息:{}", user);
}
});
}
@Override
public int getOrder() {
return 1;
}
}
4、布隆过滤器
Redisson利用Redis实现了Java分布式的布隆过滤器。因此,在多个JVM节点上或者是其他进程里面,Redisson可以通过同一个KEY获取到布隆过滤器。布隆过滤器的主要功能就是判断某个元素在不在容器里面。因此,布隆过滤器非常适合缓存穿透的场景,就是查询一个肯定不存在于DB中的数据。另外一个业务场景也很简单,就是可以判断是否重复。 一言以蔽之,可以用布隆过滤器来解决缓存穿透问题,也可以使用布隆过滤器来检查数据是否重复。
技术参考文档:
RBloomFilter<SomeObject> bloomFilter = redisson.getBloomFilter("sample");
// 初始化布隆过滤器,预计统计元素数量为55000000,期望误差率为0.03
bloomFilter.tryInit(55000000L, 0.03);
bloomFilter.add(new SomeObject("field1Value", "field2Value"));
bloomFilter.add(new SomeObject("field5Value", "field8Value"));
bloomFilter.contains(new SomeObject("field1Value", "field8Value"));
如果真的要在生产环境里面用布隆过滤器,那么得单独开一个定时任务初始化布隆过滤器的数据。删除、更新的时候,都要重新刷新布隆过滤器,如此看来,好像确实不太好用。不如用Redis的Set类型。
@PostMapping("/addUser")
public Integer insert(@RequestBody MUser user) {
RBloomFilter<String> bloomFilter
= redisson.getBloomFilter(Constant.REDISSON_BLOOMFILTER_USER);
//布隆过滤器计算的正确率为97%,初始化布隆过滤器容量为50000L
bloomFilter.tryInit(500000L,0.03);
if (bloomFilter.contains(user.getName())) {
throw new InvalidArgumentException("用户名:" + user.getName() + "已经存在");
}
user.setId(null);
int res = userMapper.insertSelective(user);
if (res > 0) {
//加入布隆过滤器
bloomFilter.add(user.getName());
}
return user.getId();
}
5、限流器
基于Redis的分布式限流器RateLimiter可以用来在分布式环境下现在请求方的调用频率。既适用于不同Redisson实例下的多线程限流,也适用于相同Redisson实例下的多线程限流。
RateLimter主要作用就是可以限制调用接口的次数。主要原理就是调用接口之前,需要拥有指定个令牌。限流器每秒会产生X个令牌放入令牌桶,调用接口需要去令牌桶里面拿令牌。如果令牌被其它请求拿完了,那么自然而然,当前请求就调用不到指定的接口。
技术参考文档:
RRateLimiter rateLimiter = redisson.getRateLimiter("myRateLimiter");
// 初始化
// 最大流速 = 每10秒钟产生1个令牌
rateLimiter.trySetRate(RateType.OVERALL, 1, 10, RateIntervalUnit.SECONDS);
//需要1个令牌
if(rateLimiter.tryAcquire(1)){
//TODO:Do something
}
主要使用业务场景:(1)单机或分布式情况下的缓存击穿(2)接口需要限制调用次数
当前业务就是,向指定手机号发送短信。但是有每10秒只允许发送1次的限制。完全可以使用Redisson限流器来完成。
/**
* @author zhoutianyu
* @date 2020/3/15
* @time 18:55
*/
@Service
public class RateLimiterService {
private static final Logger LOGGER = LoggerFactory.getLogger(RateLimiterService.class);
@Autowired
private RedissonClient redisson;
public void sendMsg(String phone) {
if (StringUtils.isNotBlank(phone)) {
RRateLimiter rateLimiter =
redisson.getRateLimiter(Constant.REDISSON_RATE_LIMITER + phone);
//每10秒产生1个令牌
rateLimiter.trySetRate(RateType.OVERALL, 1, 10,
RateIntervalUnit.SECONDS);
if (rateLimiter.tryAcquire(1)) {
LOGGER.info("向手机:{}发送短信", phone);
}
}
}
}
模拟调用者:
@PostMapping("/send_msg")
public void sendMsg(@RequestParam String phone) {
while(true){
rateLimiterService.sendMsg(phone);
}
}
6、分布式锁
1)立即获取锁
Redisson提供了一种非常便捷的分布式锁
//获取锁
RLock lock = redisson.getLock("anyLock");
// 最常见的使用方法
lock.lock();
//释放锁
lock.unlock();
我部署了两个节点,分别是8081端口与8082端口。访问其中的任意一个节点,我们按照上述文档的代码,获取锁。方法上接收的参数是锁的名字。
首先请求8081端口的方法,URL是 localhost:8081/lock?lockName=myLock,同步锁名称传 'myLock'。业务代码如下,模拟执行业务20秒。
再从8082端口请求相同的URL,localhost:8082/lock?lockName=myLock。因为lockName的值是相同的,所以在8082节点拿到的是同一把锁。8082在调用tryLock()方法的时候,如果8081端口的20秒业务没有处理完的话,那么tryLock ()方法将会返回false。
@Autowired
private RedissonClient redisson;
@GetMapping(value = "/lock")
public void addLock(String lockName) {
//从Redisson获取分布式锁
RLock lock = redisson.getLock(lockName);
//尝试获取锁
if (lock.tryLock()) {
try {
LOGGER.info("执行业务20秒");
Thread.sleep(20000);
} catch (Exception e) {
LOGGER.error("an exception was occurred ,
caused by :{}", e.getMessage());
} finally {
lock.unlock();
}
}
System.out.println("执行结束");
}
如果lock.tryLock()返回false,说明8081端口的业务没有处理完,8082就会直接跳过执行业务代码。如果lock.tryLock()返回true,说明8081的业务处理完毕,8082则可以获取到同步锁,因此可以执行规定的业务代码。
2)可重入特性
如果有两个同步方法,它们的同步锁对象是相同的。我们假设这两个方法分别叫A方法与B方法。如果A方法的内部执行了B方法,或者B方法的内部执行了A方法,那么它们的调用是畅通无阻的。说的比较高端一点: 在已经获得锁的同步方法或同步代码块内部可以调用锁定对象的其他同步方法。
代码示例:
@Autowired
private RedissonClient redisson;
@GetMapping(value = "/lock")
public void addLock(String lockName) {
RLock lock = redisson.getLock(lockName);
if (lock.tryLock()) {
try {
LOGGER.info("执行业务20秒");
//可重入性测试
this.reMethod(lockName);
Thread.sleep(20000);
} catch (Exception e) {
LOGGER.error("an exception was occurred , caused by :{}",
e.getMessage());
} finally {
lock.unlock();
}
}
System.out.println("执行结束");
}
private void reMethod(String lockName) {
RLock lock = redisson.getLock(lockName);
if (lock.tryLock()) {
try {
LOGGER.info("可重入任务");
} catch (Exception e) {
LOGGER.error("an exception was occurred , caused by :{}", e.getMessage());
} finally {
lock.unlock();
}
}
}
addLock()方法里又执行了reMehod()方法。reMethod()方法的业务里面的需要获取到同步锁才能执行。因为addLock()方法会把锁的名称传到reMethod()方法里,所以reMethod()方法与addLock()方法获取到的是同一把锁,因此reMethod()方法的lock.tryLock()会返回true。所以reMethod()方法的业务得以立即被执行。
3)等待放弃获取锁机制
如果某个请求需要同步锁,但是同步锁此刻被其他的线程占用了,但是当前线程又不想立即放弃操作。尝试在指定时间内获取同步锁,如果在指定时间内没有获取到锁,才最终放弃获取锁。Redisson的RLock类实现了Lock接口,因此就具备在指定时间内放弃锁的功能。
@GetMapping(value = "/lock")
public void addLock(String lockName) throws InterruptedException {
RLock lock = redisson.getLock(lockName);
//4秒内如果没有拿到同步锁,返回false
if (lock.tryLock(4, TimeUnit.SECONDS)) {
try {
LOGGER.info("执行业务20秒");
Thread.sleep(20000);
} catch (Exception e) {
} finally {
lock.unlock();
}
}
System.out.println("执行结束");
}
4)自动释放锁
Redisson还通过加锁的方法提供了leaseTime的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
// 加锁以后10秒钟自动解锁
// 无需调用unlock方法手动解锁
lock.lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}
5)宕机情况
如果负责储存这个分布式锁的Redisson节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是30秒钟,也可以通过修改Config.lockWatchdogTimeout来另行指定。
Redisson为每个RLock提供了看门狗进行30秒的倒计时。如果想修改这个倒计时时间,在SpringBoot中像这样配置:
@Bean
public RedissonClient redissonClient() {
LOGGER.error(url);
Config config = new Config();
//设置看门狗时间为60秒
config.setLockWatchdogTimeout(60 * 1000);
config.useSingleServer().setAddress(url).setPassword(password);
RedissonClient redisson = Redisson.create(config);
return redisson;
}
7、分布式集合
1)分布式集合列表RList
基于Redis的Redisson分布式列表(List)结构的RList Java对象实现了java.util.List接口。Redisson的RList相当于一个Redis的List类型的数据结构。因为其的底层实现就是Redis的List,所以其核心使用心法就是用于存储一对多的热点数据。
技术参考文档:
RList<SomeObject> list = redisson.getList("anyList");
list.add(new SomeObject());
list.get(0);
list.remove(new SomeObject());
需求:现在的需求是记录用户的操作日志。数据库里存放两个字段,一个是用户账号,一个是操作时间;示例代码如下:
package com.tyzhou.redisson.service;
import com.tyzhou.Constant;
import com.tyzhou.redisson.mapper.LogMapper;
import com.tyzhou.redisson.model.LogDO;
import com.tyzhou.utils.CollectionUtils;
import org.redisson.api.RList;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* Redisson List 作为访问记录日志缓存
*
* @author zhoutianyu
* @date 2020/3/19
* @time 19:19
*/
@Service
public class LogService {
@Autowired
private LogMapper logMapper;
@Autowired
private RedissonClient redisson;
public void insertLog(String userAccount) {
LogDO log = new LogDO(userAccount);
//插入日志到数据库
logMapper.insertLog(log);
if (log.getId() > 0) {
//同时从Redis获取日志缓存,将本次日志加入进去
RList<LogDO> logList = redisson.getList(Constant.REDISSON_LOG);
logList.add(log);
}
}
//通过账号查询这个人的操作记录缓存
public List<LogDO> getLogCache(String userAccount) {
//从Redis缓存中取数据
RList<LogDO> logList = redisson.getList(Constant.REDISSON_LOG);
if (CollectionUtils.isNotEmpty(logList)) {
return logList;
}
//如果缓存中没有数据,则从数据库的日志表中查询操作日志
return logMapper.selectAll(userAccount);
}
}
package com.tyzhou.redisson.model;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Date;
@Data
@NoArgsConstructor
public class LogDO {
private Integer id;
private String userAccount;
private Date operationTime;
public LogDO(String userAccount) {
this.userAccount = userAccount;
this.operationTime = new Date();
}
}
为了保证日志与数据库中一致,所以还要添加一个定时任务,定时将日志记录加入到缓存:
package com.tyzhou.redisson.schedule;
import com.tyzhou.Constant;
import com.tyzhou.redisson.mapper.LogMapper;
import com.tyzhou.redisson.model.LogDO;
import com.tyzhou.utils.CollectionUtils;
import org.redisson.api.RList;
import org.redisson.api.RedissonClient;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Async;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.util.List;
@Component
@EnableScheduling
@EnableAsync
public class LogSchedule {
private static final Logger LOGGER = LoggerFactory.getLogger(LogSchedule.class);
@Autowired
private LogMapper logMapper;
@Autowired
private RedissonClient redisClient;
//10分钟同步一次(开发测试可增加频率)
@Scheduled(cron = "* */10 * * * ?")
@Async
public void selectLogCache() {
LOGGER.info("同步日志缓存");
RList<LogDO> logCacheList = redisClient.getList(Constant.REDISSON_LOG);
//清空所有
logCacheList.delete();
List<LogDO> logList = logMapper.selectAll("");
if(CollectionUtils.isNotEmpty(logList)){
logCacheList.addAll(logList);
}
}
}
2)分布式集合映射RMap
这里的分布式RMap类型,主要功能就是:1.实现了JavaSE的Map接口,方便操作;2.具有Redis的Map类型的缓存记忆功能。其底层数据类型就是Redis的hash数据类型。
与RBucket对象桶的区别,RMap可以把多个对象存放到Map中,而RBucket只能存放一个对象。 与RList集合的区别。RList就是一个集合,类似于Java中的List,存放的是单列集合。而RMap类似于双列集合,能够存放 key - value 类型的数据。
示例代码:
package com.tyzhou.redisson.controller;
import com.tyzhou.Constant;
import com.tyzhou.mail.mapper.MUserMapper;
import com.tyzhou.mail.modol.MUser;
import org.redisson.api.RMap;
import org.redisson.api.RedissonClient;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
/**
* @author zhoutianyu
* @date 2020/3/22
* @time 19:44
*/
@RestController
@RequestMapping(value = "redisson/map")
public class MapController {
private static final Logger LOGGER = LoggerFactory.getLogger(MapController.class);
@Autowired
private MUserMapper userMapper;
@Autowired
private RedissonClient redisson;
@PostMapping("/addUser")
public Integer insert(@RequestBody MUser user) {
user.setId(null);
int res = userMapper.insertSelective(user);
if (res > 0) {
RMap<Integer, MUser> map = redisson.getMap(Constant.REDISSON_MAP);
map.put(user.getId(), user);
}
return user.getId();
}
@GetMapping("/getUser")
public MUser insert(@RequestParam Integer userId) {
MUser user;
RMap<Integer, MUser> map = redisson.getMap(Constant.REDISSON_MAP);
user = map.get(userId);
if (user != null) {
return user;
}
return userMapper.selectByPrimaryKey(userId.longValue());
}
@PostMapping("/updateUser")
public Integer update(@RequestBody MUser user) {
int res = userMapper.updateByPrimaryKeySelective(user);
if (res > 0) {
RMap<Integer, MUser> map = redisson.getMap(Constant.REDISSON_MAP);
map.put(user.getId(), user);
}
return user.getId();
}
@PostMapping("/deleteUser")
public MUser delete(@RequestParam Long id) {
int res = userMapper.deleteByPrimaryKey(id);
if (res > 0) {
RMap<Integer, MUser> map = redisson.getMap(Constant.REDISSON_MAP);
return map.remove(id.intValue());
}
return null;
}
}
加锁:
既然是分布式的Map,那么就一定会有这种可能:其他客户端或者线程也在同一时刻操作相同的Map。那么这样的话,那么RMap就有可能出现线程安全方面的问题。RMap提供了两种字段锁。一种是常见的Lock锁,一种是进阶版的读写锁。
官方技术参考文档:
RMap<MyKey, MyValue> map = redisson.getMap("anyMap");
//Lock锁
MyKey k = new MyKey();
RLock keyLock = map.getLock(k);
keyLock.lock();
try {
MyValue v = map.get(k);
// 其他业务逻辑
} finally {
keyLock.unlock();
}
//读写锁
RReadWriteLock rwLock = map.getReadWriteLock(k);
rwLock.readLock().lock();
try {
MyValue v = map.get(k);
// 其他业务逻辑
} finally {
keyLock.readLock().unlock();
}
实例代码1:使用RLock锁,做更新用户与查询用户互斥锁
我们为更新用户使用加锁操作。根据官方提供的文档,分布式Map "RMap"拥有加锁的能力,只要调用RMap#getLock 方法就能获得一把 RLock锁。
如下代码,在更新用户的操作上增加睡眠10秒钟,模拟更新业务的其他业务,例如消息推送、日志记录。最后就是使用finally语句释放锁。不用担心死锁问题,因为Redisson有"看门狗"机制,它在指定时间后会自动释放锁。
@PostMapping("/updateUser")
public Integer update(@RequestBody MUser user) {
int res = userMapper.updateByPrimaryKeySelective(user);
if (res > 0) {
RMap<Integer, MUser> map = redisson.getMap(Constant.REDISSON_MAP);
//更新与查询互斥
RLock rLock = map.getLock(user.getId());
rLock.lock();
try {
LOGGER.info("更新用户:{}开始", user.getId());
map.put(user.getId(), user);
Thread.sleep(10000);
LOGGER.info("更新用户:{}结束", user.getId());
} catch (Exception e) {
LOGGER.error("an exception was occurred , caused by :{}", e.getMessage());
} finally {
rLock.unlock();
}
}
return user.getId();
}
获取用户的接口代码,同样的通过RMap#getLock获取一把相同的RLock 锁。调用RLock#lock方法,如果没有获取到锁,那么就会一直阻塞。当然了,这里有待商榷,在实际中可以使用Lock#tryLock防止获取锁时间过长而阻塞的问题。
@GetMapping("/getUser")
public MUser insert(@RequestParam Integer userId) {
MUser user;
RMap<Integer, MUser> map = redisson.getMap(Constant.REDISSON_MAP);
RLock rLock = map.getLock(userId);
LOGGER.info("查询用户:{}开始", userId);
rLock.lock();
try {
user = map.get(userId);
if (user != null) {
LOGGER.info("查询用户:{}结束", userId);
return user;
}
} catch (Exception e) {
LOGGER.error("an exception was occurred , caused by :{}", e.getMessage());
} finally {
rLock.unlock();
}
LOGGER.info("查询用户:{}结束", userId);
return userMapper.selectByPrimaryKey(userId.longValue());
}
实例代码2:使用读写锁,做更新用户与查询用户互斥锁
读写锁内部有两把锁,一把读锁,一把写锁。我们从操作的角度来思考问题。如果操作是查询,也就是查询数据库,多个线程之间不会出现相互影响,那么就可以在同一时刻允许多个读线程访问。如果操作互不影响,那么锁就可以被分离。这就是锁分离的思想。
下面是RMap使用读锁的代码;首先通过Redisson#getMap拿到RMap,然后通过RMap#getReadWriteLock,拿到读写锁。读写锁里面有两把锁,一把读锁,一把写锁。我们这里先读锁,RReadWriteLock#readLock。使用lock加锁并使用unlock解锁。业务代码里面增加一个睡眠时间5秒,方便验证。
多个请求获取相同的读锁,读锁之间不会出现互斥现象;
@GetMapping("/getUser")
public MUser getUser(@RequestParam Integer userId) {
MUser user;
RMap<Integer, MUser> map = redisson.getMap(Constant.REDISSON_MAP);
//获取读锁
RReadWriteLock rLock = map.getReadWriteLock(userId);
RLock readLock = rLock.readLock();
readLock.lock();
try {
LOGGER.info("查询用户:{}开始", userId);
user = map.get(userId);
Thread.sleep(5000);
if (user != null) {
LOGGER.info("查询用户:{}结束", userId);
return user;
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
readLock.unlock();
}
LOGGER.info("查询用户:{}结束", userId);
return userMapper.selectByPrimaryKey(userId.longValue());
}
读锁与写锁之间互斥,即拿到了写锁以后,同一把读写锁的读锁就不能进入同步代码块。道理很简单,我还在操作过程中,其它线程就应该被阻塞,不然就会出现比如脏读的现象。
如下代码,先获取到读写锁RMap#getReadWriteLock。然后拿这把读写锁的写锁,ReadWriteLock#writeLock。读写锁的特性就是读写互斥,写写互斥。拿到写锁以后,开始更新用户更新成功后将最新的用户对象存放到缓存RMap中。
读请求必须要等到写请求释放写锁后才能请求到同步代码;
@PostMapping("/updateUser")
public Integer update(@RequestBody MUser user) {
int res = userMapper.updateByPrimaryKeySelective(user);
if (res > 0) {
RMap<Integer, MUser> map = redisson.getMap(Constant.REDISSON_MAP);
//获取写锁
RReadWriteLock rLock = map.getReadWriteLock(user.getId());
RLock writeLock = rLock.writeLock();
try {
writeLock.lock();
LOGGER.info("更新用户:{}开始", user.getId());
map.put(user.getId(), user);
Thread.sleep(10000);
LOGGER.info("更新用户:{}结束", user.getId());
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
writeLock.unlock();
}
}
return user.getId();
}
@GetMapping("/getUser")
public MUser getUser(@RequestParam Integer userId) {
MUser user;
RMap<Integer, MUser> map = redisson.getMap(Constant.REDISSON_MAP);
//获取读锁
RReadWriteLock rLock = map.getReadWriteLock(userId);
RLock readLock = rLock.readLock();
readLock.lock();
try {
LOGGER.info("查询用户:{}开始", userId);
user = map.get(userId);
if (user != null) {
LOGGER.info("查询用户:{}结束-----", userId);
return user;
}
} finally {
readLock.unlock();
}
LOGGER.info("查询用户:{}结束", userId);
return userMapper.selectByPrimaryKey(userId.longValue());
}
3)RLocalCachedMap本地缓存映射
我们知道,热点数据绝大多数的情况都是查询,例如经典的查询字典表,也就是系统里的下拉框。我们完全可以把字典表的所有数据加入到缓存中,下次下拉框查询就直接查询缓存,不用再去查询数据库。我们只需要增加一个定时任务,定期把字典表的最新数据刷入缓存就可以了。
既然都是查询,那么查询当然是越快越好。之前的缓存数据在RMap中,现在可以优化成使用本地缓存映射(RLocalCachedMap)。本地缓存映射的查询速度是RMap的45倍。一句话,本地缓存映射(RLocalCachedMap)的查询速度比映射(RMap)快的多。
在特定的场景下,映射(RMap)上的高度频繁的读取操作,使网络通信都被视为瓶颈时,使用Redisson提供的带有本地缓存功能的分布式本地缓存映射RLocalCachedMapJava对象会是一个很好的选择。它同时实现了java.util.concurrent.ConcurrentMap和java.util.Map两个接口。本地缓存功能充分的利用了JVM的自身内存空间,对部分常用的元素实行就地缓存,这样的设计让读取操作的性能较分布式映射相比提高最多 45倍 。
官方示例:
RLocalCachedMap<String, Integer> map = redisson.getLocalCachedMap("test", options);
String prevObject = map.put("123", 1);
String currentObject = map.putIfAbsent("323", 2);
String obj = map.remove("123");
实例代码:现有如下字典表,mapper把这几条数据全部查询出来,按照type类型进行分组

先从数据库中将这6条数据全部查询出来,封装这6条数据到List<Parameter>中。然后对这6条数据根据type属性进行分组,会得到两个组,结果封装到Map<String,List<Parameter>>中。然后通过redisson#getLocalCacheMap拿到本地缓存映射(RLocalCachedMap),最后把分组结果加入到缓存中。
@RestController
@RequestMapping(value = "/redisson/map/parameter/")
public class RLocalCacheMapController {
private static final Logger LOGGER = LoggerFactory.getLogger(RLocalCacheMapController.class);
@Autowired
private RedissonClient redisson;
@Autowired
private ParameterMapper mapper;
@GetMapping(value = "/syn_cache")
public List<Parameter> synCache() {
LOGGER.info("同步缓存");
List<Parameter> allParameter = mapper.getAll();
if (CollectionUtils.isEmpty(allParameter)) {
return CollectionUtils.emptyList();
}
//通过type进行分组
Map<String, List<Parameter>> parameterGroupByType =
allParameter.stream().collect(Collectors.groupingBy(Parameter::getType));
//通过Redisson获取 本地映射缓存RLocalCachedMap
RLocalCachedMap<String, List<Parameter>> localCacheMap =
redisson.getLocalCachedMap(Constant.REDISSON_LOCAL_CACHE_MAP,
LocalCachedMapOptions.defaults());
//将分组的结果加入缓存
LOGGER.info("分组结果加入本地缓存映射");
localCacheMap.clear();
localCacheMap.putAll(parameterGroupByType);
return allParameter;
}
}
查询通过type类型从本地缓存映射(RLocalCachedMap)中取数据:
@GetMapping(value = "/get")
public List<Parameter> get(@RequestParam String type) {
//获取本地缓存映射
RLocalCachedMap<String, List<Parameter>> localCachedMap =
redisson.getLocalCachedMap(Constant.REDISSON_LOCAL_CACHE_MAP,
LocalCachedMapOptions.defaults());
if (localCachedMap != null) {
LOGGER.info("查询本地缓存映射");
return localCachedMap.get(type);
} else {
LOGGER.info("本地缓存没有查询到数据,从数据库查询");
return mapper.getAll();
}
}
4)MapCache映射缓存
Redisson的分布式的RMapCache Java对象在基于RMap的前提下实现了针对单个元素的淘汰机制。同时映射缓存(MapCache)它能够保留插入元素的顺序,并且可以指明每个元素的过期时间(元素淘汰机制)。另外还为每个元素提供了监听器,提供了4种不同类型的监听器:添加、过期、删除、更新四大事件。
示例代码:做一个模拟发送邮件的功能
现有如下m_email邮箱表,主要记录发送邮件的基础信息,以及判断是否延迟发送与其应该发送邮件的时间。
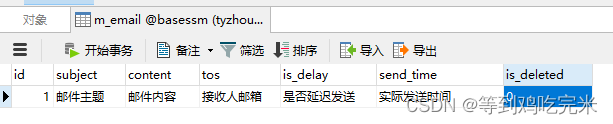
生成延迟发送邮件:
首先判断用户希望的是延迟发送还是立即发送,重点看延迟发送的分支代码。首先通过用户希望发送邮件的时间,计算这个发送时间与当前时间的差值,作为映射缓存(MapCache)的此封邮件的过期时间。
@Service
public class MailService ...
@Autowired
private RedissonClient redisson;
public void sendMail(Mail mail) throws ParseException {
mail.setId(null);
//是否延迟发送。0:立即发送,1:立即发送
if (mail.getIsDelay().equals("1") && StringUtils.isNotBlank(mail.getSendTime())) {
//解析发送时间成毫秒
Long sendTime = DateTransformTools.dateStrToMillis(mail.getSendTime(), null);
//计算出 未来发送的时间 与当前时间的 差值,作为元素的TTL过期时间
Long diffTime = sendTime - System.currentTimeMillis();
if (diffTime <= 0) {
LOGGER.error("发送时间必须大于当前时间");
throw new RuntimeException("发送时间必须大于当前时间");
}
//邮件对象入库
mailMapper.insertMail(mail);
//邮件对象入缓存
if (mail.getId() > 0) {
//缓存映射存放 邮件ID--发送者
RMapCache<Long, String> rMapCache = redisson.getMapCache(Constant.REDISSON_MAP_CACHE_EMAIL);
//通过缓存映射,为元素设定有效时间
rMapCache.put(mail.getId(), mail.getTos(), diffTime, TimeUnit.MILLISECONDS);
}
} else {
mailMapper.insertMail(mail);
LOGGER.info("立即发送邮件成功,发送ID:{}", mail.getId());
}
}
完成邮件延迟发送:
刚才为延迟发送的邮件计算出来它的过期时间,一旦此邮件过期,这就代表这封邮件应该在过期的那一刻发送,从而达到延迟发送邮件的目的。怎么发送呢?缓存映射(MapCache)为每个元素提供了过期事件。因此,需要为邮件增加过期事件监听器。
package com.tyzhou.mail.listener;
import com.tyzhou.Constant;
import com.tyzhou.mail.mapper.MailMapper;
import com.tyzhou.mail.modol.Mail;
import org.redisson.api.RMapCache;
import org.redisson.api.RedissonClient;
import org.redisson.api.map.event.EntryEvent;
import org.redisson.api.map.event.EntryExpiredListener;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;
import org.springframework.core.Ordered;
import org.springframework.stereotype.Component;
@Component
public class MailListener implements ApplicationRunner, Ordered {
private static final Logger LOGGER = LoggerFactory.getLogger(MailListener.class);
@Autowired
private RedissonClient redisson;
@Autowired
private MailMapper mailMapper;
@Override
public void run(ApplicationArguments applicationArguments) throws Exception {
LOGGER.info("缓存映射MapCache延迟发送邮件启动");
sendMail();
}
@Override
public int getOrder() {
return 2;
}
private void sendMail() {
RMapCache<Long, String> rMapCache = redisson.getMapCache(Constant.REDISSON_MAP_CACHE_EMAIL);
rMapCache.addListener(new EntryExpiredListener<Long, String>() {
@Override
public void onExpired(EntryEvent<Long, String> event) {
/**
* 缓存映射缓存的是邮件对象的主键ID与邮箱接收人
* rMapCache.put(mail.getId(), mail.getTos(),diffTime, TimeUnit.MILLISECONDS);
*/
Long emailId = event.getKey();
Mail mail = mailMapper.selectByPrimaryKey(emailId);
if (mail != null) {
LOGGER.info("发送邮件主题:{},内容:{},接收人:{}", mail.getSubject(),
mail.getContent(), mail.getTos());
}
}
});
}
}
取消延迟邮件发送:
延迟发送的邮件不想发送了,需要删除数据库里的邮件,然后再从缓存映射(MapCache)中清除此邮件的缓存。
public void delete(Long id) {
//删库
int res = mailMapper.delete(id);
if (res > 0) {
RMapCache<Long, String> rMapCache =
redisson.getMapCache(Constant.REDISSON_MAP_CACHE_EMAIL);
rMapCache.remove(id);
}
}
5)MultiMap多值映射
基于Redis的Redisson的分布式RMultimap Java对象允许Map中的一个字段值包含多个元素。多值映射就是它的一个Key,能够存放多个值。RMutiMap<String,String>这样的泛型实际的效果类似于Map<String,List<String>>。
基于列表(List)的多值映射(RListMultimap),它是在保持插入顺序的同时允许一个字段下包含重复的元素。基于集合(Set)的多值映射(RSetMultimap),它是不允许一个字段值包含有重复的元素。
还可以为上述两种多值映射提供淘汰机制,RListMultimapCache与RSetMultimapCache为具体的某个元素提供过期时间。
示例代码:使用RListMultimap缓存某个人的日志
import com.tyzhou.Constant;
import com.tyzhou.redisson.model.LogDO;
import org.redisson.api.RList;
import org.redisson.api.RListMultimap;
import org.redisson.api.RedissonClient;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping(value = "redisson/map/multi")
public class MultiMapController {
private static final Logger LOGGER = LoggerFactory.getLogger(MultiMapController.class);
@Autowired
private RedissonClient redisson;
@GetMapping(value = "/add")
public void add(@RequestParam String userAccount) {
//缓存某个人的日志
RListMultimap<String, LogDO> rListMultimap =
redisson.getListMultimap(Constant.REDISSON_MAP_MULTI_LIST_LOG);
LogDO log = new LogDO(userAccount);
//存放的数据类型实际上是【String --- List<LogDO>】
rListMultimap.put(userAccount, log);
}
@GetMapping(value = "/get")
public List<LogDO> get(@RequestParam String userAccount) {
//获取某个人的日志
RListMultimap<String, LogDO> rListMultimap =
redisson.getListMultimap(Constant.REDISSON_MAP_MULTI_LIST_LOG);
RList<LogDO> logList = rListMultimap.get(userAccount);
return logList;
}
@GetMapping(value = "/clear")
public void clear(@RequestParam String userAccount) {
//清除某个人的日志
RListMultimap<String, LogDO> rListMultimap =
redisson.getListMultimap(Constant.REDISSON_MAP_MULTI_LIST_LOG);
rListMultimap.removeAll(userAccount);
}
}
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Date;
@Data
@NoArgsConstructor
public class LogDO {
private Integer id;
private String userAccount;
private Date operationTime;
public LogDO(String userAccount) {
this.userAccount = userAccount;
this.operationTime = new Date();
}
}
示例代码:使用RSetMultimap模拟为某个班级增加学生
RSetMultimap多值映射不允许一个字段值包含有重复的元素;模拟为某个班级增加学生。学号不能相同,如果添加的学号相同,那么无效。
既然是RSetMultimap多值映射实现了Set接口,那么为了辨别出是同一个学生,需要重写学生对象的hashcode与equals方法。如下,如果学生对象的userAccount属性是一样的,那么认为是同一个对象。
package com.tyzhou.redisson.model;
import com.google.common.base.Objects;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class StudentDO {
private String userAccount;
private String name;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
if (!super.equals(o)) return false;
StudentDO studentDO = (StudentDO) o;
return Objects.equal(userAccount, studentDO.userAccount);
}
@Override
public int hashCode() {
return Objects.hashCode(super.hashCode(), userAccount);
}
}
@GetMapping(value = "/add")
public void add(@RequestParam String className,
@RequestParam String userAccount, @RequestParam String stuName) {
//添加一个学生,userAccount学号相同则认为是同一个人
RSetMultimap<String, StudentDO> setMultimap =
redisson.getSetMultimap(Constant.REDISSON_MAP_MULTI_SET_STU);
//为指定班级添加学生【同理,判断是否是同一个元素的条件是:】
setMultimap.put(className,
new StudentDO(userAccount, stuName));
}
@GetMapping(value = "/get")
public Set<StudentDO> get(@RequestParam String className) {
//获取指定班级的学生
RSetMultimap<String, StudentDO> setMultiMap =
redisson.getSetMultimap(Constant.REDISSON_MAP_MULTI_SET_STU);
return setMultiMap.get(className);
}
@GetMapping(value = "/clear")
public void clear(@RequestParam String className) {
RSetMultimap<String, StudentDO> setMultiMap =
redisson.getSetMultimap(Constant.REDISSON_MAP_MULTI_SET_STU);
setMultiMap.removeAll(className);
}
8、Remote Service分布式远程服务
当前有两台服务器连接的是同一个Redisson中间件,这两台服务器叫它们A节点与B节点吧。A节点可以发布一些API接口,也实现了它们,并向Redisson服务中心注册。B节点向Redisson注册中心订阅这些API接口,因此它可以向Redisson服务器发送这些请求,这些请求最终会被注册中心转发到A节点。这样,B节点就能够通过Redisson注册中心与A节点通信,从而实现远程服务调用功能。
分布式远程服务(Remote Service)提供了两种类型的RRemoteService实例;
服务端(远端)实例 - 用来执行远程方法(工作者实例即worker instance):
RRemoteService remoteService = redisson.getRemoteService();
SomeServiceImpl someServiceImpl = new SomeServiceImpl();
// 在调用远程方法以前,应该首先注册远程服务
// 只注册了一个服务端工作者实例,只能同时执行一个并发调用
remoteService.register(SomeServiceInterface.class, someServiceImpl);
// 注册了12个服务端工作者实例,可以同时执行12个并发调用
remoteService.register(SomeServiceInterface.class, someServiceImpl, 12);
客户端(本地)实例 - 用来请求远程方法:
RRemoteService remoteService = redisson.getRemoteService();
SomeServiceInterface service = remoteService.get(SomeServiceInterface.class);
String result = service.doSomeStuff(1L, "secondParam", new AnyParam());
示例代码:服务端(生产端)
(1)首先服务器端会定义一个接口IMailService,并实现它IMailServiceImpl。这里注意的是,IMailService与MailDto都是在API模块里面的,方便打包并发布。MailDto需要实现序列化接口,因为需要存放在Redis
public interface IMailService {
MailDto queryMail(Long id);
}
@Service
public class IMailServiceImpl implements IMailService {
@Autowired
private MailMapper mailMapper;
@Override
public MailDto queryMail(Long id) {
Mail mail = mailMapper.selectByPrimaryKey(id);
MailDto dto = new MailDto();
if (mail != null) {
BeanUtils.copyProperties(mail, dto);
}
return dto;
}
}
(2)向Redisson注册中心发布API。CommandLineRunner接口的功能是在SpringBoot项目启动的时候执行相关的功能。
@Component
public class RemoteServiceInit implements CommandLineRunner {
private static final Logger LOGGER =
LoggerFactory.getLogger(RemoteServiceInit.class);
@Autowired
private RedissonClient redisson;
@Autowired
private IMailService iMailService;
@Override
public void run(String... strings) throws Exception {
LOGGER.info("初始化Redisson远程调度");
RRemoteService remoteService = redisson.getRemoteService();
//初始化5个并发实例
remoteService.register(IMailService.class, iMailService, 5);
}
}
示例代码:客户端(消费端)
生产端的IMailService与MailDto最好定义在API模块,方便打包发布。打包成jar以后,导入到消费端项目B中。消费端项目B需要与生产端连接相同的Redisson服务器。
@Service
public class RemoteMailService {
@Autowired
private RedissonClient redisson;
public MailDto queryMail(Long id) {
//获取Redisson远程服务
RRemoteService remoteService = redisson.getRemoteService();
//应答回执超时1秒钟,远程执行超时30秒钟
RemoteInvocationOptions options = RemoteInvocationOptions.defaults();
//拿到生产端的接口
IMailService iMailService = remoteService.get(IMailService.class,options);
//调用
return iMailService.queryMail(id);
}
}
响应模式附录:
// 应答回执超时1秒钟,远程执行超时30秒钟
RemoteInvocationOptions options = RemoteInvocationOptions.defaults();
// 无需应答回执,远程执行超时30秒钟
RemoteInvocationOptions options = RemoteInvocationOptions.defaults().noAck();
// 应答回执超时1秒钟,不等待执行结果
RemoteInvocationOptions options = RemoteInvocationOptions.defaults().noResult();
// 应答回执超时1分钟,不等待执行结果
RemoteInvocationOptions options = RemoteInvocationOptions.defaults().
expectAckWithin(1, TimeUnit.MINUTES).noResult();
// 发送即不管(Fire-and-Forget)模式,无需应答回执,不等待结果
RemoteInvocationOptions options = RemoteInvocationOptions.defaults().noAck().noResult();
RRemoteService remoteService = redisson.getRemoteService();
YourService service = remoteService.get(YourService.class, options);
代码实测:
public MailDto queryMail(Long id) {
RRemoteService remoteService = redisson.getRemoteService();
//应答回执超过5秒钟,不等待执行结果
RemoteInvocationOptions options = RemoteInvocationOptions.defaults().
expectResultWithin(15, TimeUnit.SECONDS).expectAckWithin(10,TimeUnit.SECONDS);
Long start = System.currentTimeMillis();
IMailService iMailService = remoteService.get(IMailService.class,options);
MailDto result = null;
try {
result = iMailService.queryMail(id);
}catch (Exception e){
System.out.println(e.getMessage());
}
Long end = System.currentTimeMillis();
System.out.println(end - start);
return result;
}
expectResultWithin(15,TimeUnit.SECONDS)表示,如果生产端服务器能够接通的话,在15秒之内需要返回数据,否则报异常No response after 15000ms for request。
expectAckWithin(10,TimeUnit.SECONDS)表示,生产端服务器需要在10秒内有响应,否则报异常No ACK response after 10000ms for request。
原文链接:http://t.csdn.cn/hCoq9