在es中我们可能会有这么一种需求,即有时需要批量向es中插入或更新或删除数据,如果一条一条数据的操作,那么速度必然很慢,那么es的bulk api就可以派上用场。
delete 删除操作,只需要写一个json即可
create 创建操作,如果需要创建的文档已经存在,那么创建失败
index 创建或替换操作,如果要创建的文档不存在则执行创建操作,如果已经存在则执行替换操作
update 更新操作 执行文档的更新
需求:
1、使用create创建编号为21、22、23的文档
2、使用create再次创建编号为22的文档,此时会失败,因为编号为22的文档已经存在
3、使用index创建编号为24、25的文档
4、使用index替换编号为25的文档
5、修改编号为21的文档的数据
6、删除编号为23的文档
curl -XPOST "http://192.168.99.1:9200/_bulk" -d'
{"create":{"_index":"productindex","_type":"product","_id":21}}
{"name":"21 name","price":21}
{"create":{"_index":"productindex","_type":"product","_id":22}}
{"name":"22 name","price":22}
{"create":{"_index":"productindex","_type":"product","_id":23}}
{"name":"23 name","price":23}
{"create":{"_index":"productindex","_type":"product","_id":22}}
{"name":"id为22的文档已经存在,创建失败","price":22}
{"index":{"_index":"productindex","_type":"product","_id":24}}
{"name":"文档不存在,被创建","price":24}
{"index":{"_index":"productindex","_type":"product","_id":25}}
{"name":"21 name","price":25}
{"index":{"_index":"productindex","_type":"product","_id":25}}
{"name":"由于编号为25的文档已经存在,执行替换操作,price字段的值没有了"}
{"update":{"_index":"productindex","_type":"product","_id":21}}
{"doc":{"name":"修改编号为21的文档的数据,price字段的值还在"}}
{"delete":{"_index":"productindex","_type":"product","_id":23}}
'
执行结果,部分。
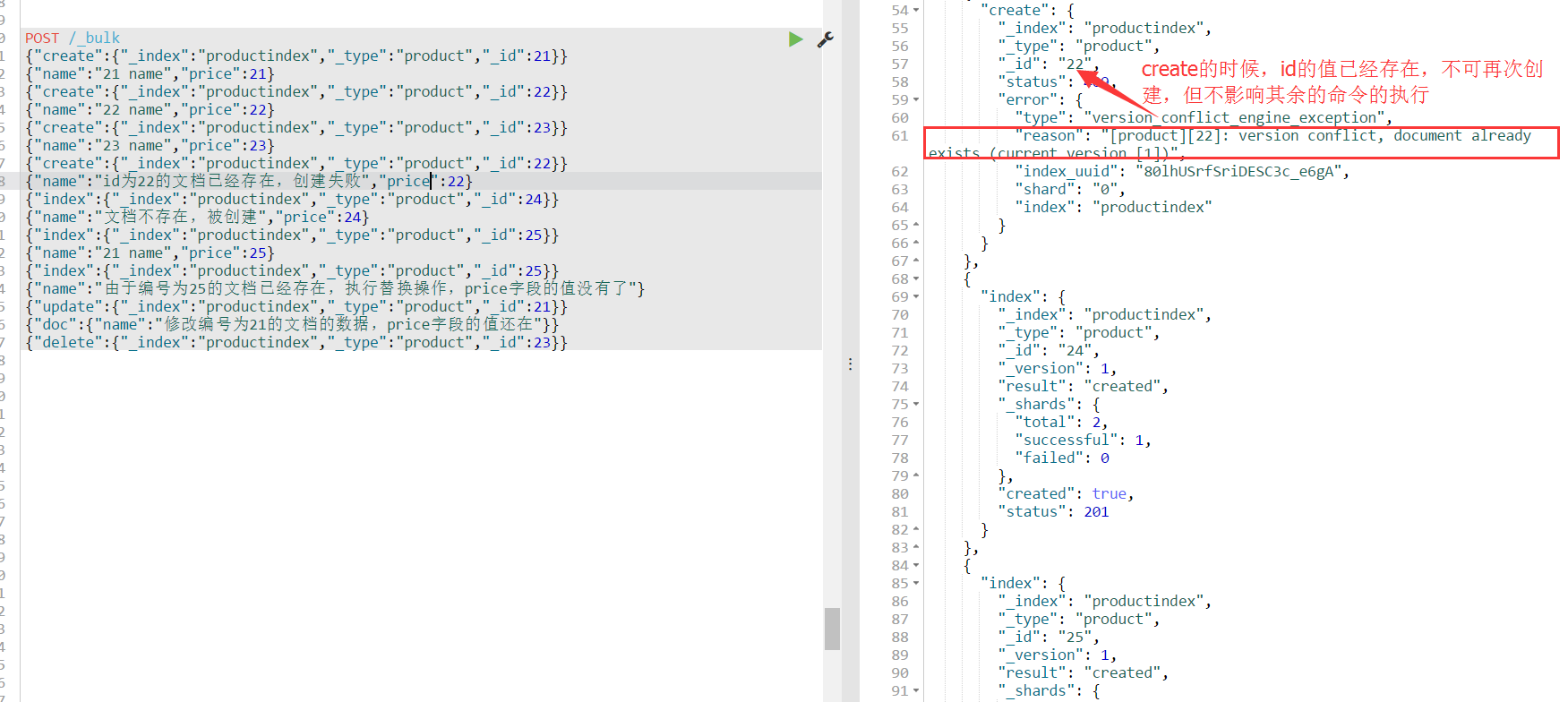
批量执行完成之后,es会返回每个命令的执行的结果,其中一个命令报错,是不会影响其余的命令继续往下执行的。
在批量执行api下,每个json串需要占据一行,不可将json字符串格式化,否则执行不了。
bulk请求的请求体不建议太大,太大会影响性能。建议不要超过几十兆。如果出现索引队列不够用的时候,就需要调整threadpool.index.queue_size 的值。