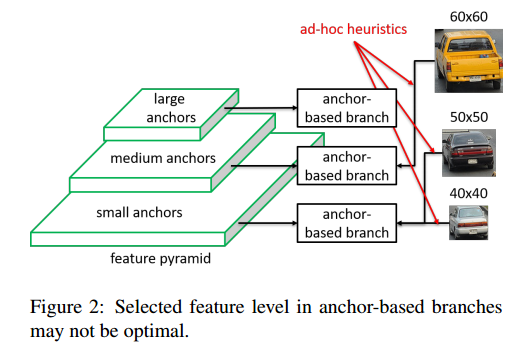
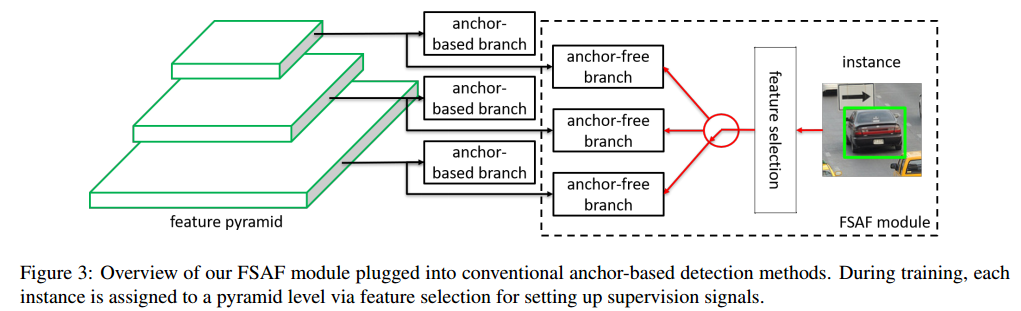
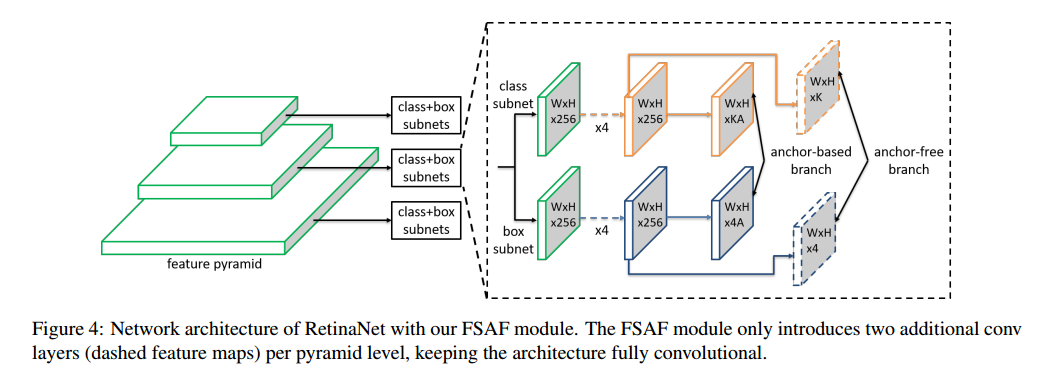
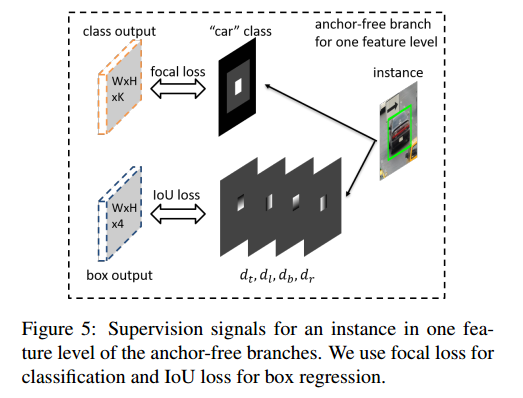
给定目标实例,我们已知其类别
k
k
k 和 b-box 坐标
b
=
[
x
,
y
,
w
,
h
]
b=[x,y,w,h]
b=[x,y,w,h],其中
(
x
,
y
)
(x,y)
(x,y)为box的中心,
w
,
h
w,h
w,h 为box的宽和高。
实例可以在训练过程中分配给任意特征层
P
l
P_l
Pl
定义投影的box
b
p
l
=
[
x
p
l
,
y
p
l
,
w
p
l
,
h
p
l
]
b_p^l=[x_p^l, y_p^l, w_p^l, h_p^l]
bpl=[xpl,ypl,wpl,hpl] 作为
b
b
b 在特征金字塔
P
l
P_l
Pl上的投影,
b
p
l
=
b
/
2
l
b_p^l = b / 2^l
bpl=b/2l。
同样将有效box定义为
b
e
l
=
[
x
e
l
,
y
e
l
,
w
e
l
,
h
e
l
]
b_e^l=[x_e^l, y_e^l, w_e^l, h_e^l]
bel=[xel,yel,wel,hel] ,占
b
p
l
b_p^l
bpl 的
ϵ
e
\epsilon_e
ϵe
将可忽略的box区域定义为
b
i
l
=
[
x
i
l
,
y
i
l
,
w
i
l
,
h
i
l
]
b_i^l=[x_i^l, y_i^l, w_i^l, h_i^l]
bil=[xil,yil,wil,hil] 占
b
p
l
b_p^l
bpl 的
ϵ
i
\epsilon_i
ϵi
即:
x
e
l
=
x
p
l
,
y
e
l
=
y
p
l
,
w
e
l
=
ϵ
e
w
p
l
,
h
e
l
=
ϵ
e
h
p
l
x_e^l=x_p^l, y_e^l=y_p^l, w_e^l=\epsilon_e w_p^l, h_e^l=\epsilon_e h_p^l
xel=xpl,yel=ypl,wel=ϵewpl,hel=ϵehpl
x
i
l
=
x
p
l
,
y
i
l
=
y
p
l
,
w
i
l
=
ϵ
i
w
p
l
,
h
i
l
=
ϵ
e
h
p
l
x_i^l=x_p^l,y_i^l=y_p^l, w_i^l=\epsilon_i w_p^l, h_i^l=\epsilon_e h_p^l
xil=xpl,yil=ypl,wil=ϵiwpl,hil=ϵehpl
且设定
ϵ
e
=
0.2
,
ϵ
i
=
0.5
\epsilon_e=0.2, \epsilon_i=0.5
ϵe=0.2,ϵi=0.5
对
b
e
l
b_e^l
bel内的所有位置
(
i
,
j
)
(i,j)
(i,j) ,我们将投影框
b
p
l
b_p^l
bpl 表示为一个四维向量
d
i
,
j
l
=
[
d
t
i
,
j
l
,
d
l
i
,
j
l
,
d
b
i
,
j
l
,
d
r
i
,
j
l
]
d_{i,j}^l=[d_{t_{i,j}}^l, d_{l_{i,j}}^l, d_{b_{i,j}}^l, d_{r_{i,j}}^l]
di,jl=[dti,jl,dli,jl,dbi,jl,dri,jl] ,其中,
d
t
l
,
d
l
l
,
d
b
l
,
d
r
l
d_t^l, d_l^l, d_b^l, d_r^l
dtl,dll,dbl,drl 分别表示目前位置
(
i
,
j
)
(i,j)
(i,j)和
b
p
l
b_p^l
bpl 的上下左右的距离。
之后,在
(
i
,
j
)
(i,j)
(i,j)位置上的跨越四个偏移映射的四维向量设置为
d
i
,
j
/
S
d_{i,j}/S
di,j/S ,每个映射对应一个维度。
S
S
S 是标准化常数,设置为4。将
d
i
,
j
/
S
d_{i,j}/S
di,j/S 作为输出结果。
在有效框之外的位置都被设置为灰色区域,其梯度被忽略
IoU loss[36]被用来优化
anchor-free分支对一幅图像的回归总损失是,所有有效框区域的IoU损失的均值
推理阶段: 直接对分类和回归输出预测的框进行解码
对每个像素位置
(
i
,
j
)
(i,j)
(i,j),假设预测的偏移是
[
o
^
t
i
,
j
,
o
^
l
i
,
j
,
o
^
b
i
,
j
,
o
^
r
i
,
j
]
[ \hat{o}_{t_{i,j}}, \hat{o}_{l_{i,j}}, \hat{o}_{b_{i,j}}, \hat{o}_{r_{i,j}}]
[o^ti,j,o^li,j,o^bi,j,o^ri,j] ,则预测的距离是
[
S
o
^
t
i
,
j
,
S
o
^
l
i
,
j
,
S
o
^
b
i
,
j
,
S
o
^
r
i
,
j
]
[ S_{\hat{o}_{t_{i,j}}}, S_{\hat{o}_{l_{i,j}}}, S_{\hat{o}_{b_{i,j}}}, S_{\hat{o}_{r_{i,j}}}]
[So^ti,j,So^li,j,So^bi,j,So^ri,j] 。
预测的投影框的左上角和右下角分别为:
(
i
−
S
o
^
t
i
,
j
,
j
−
S
o
^
l
i
,
j
)
(i-S_{\hat{o}_{t_{i,j}}}, j-S_{\hat{o}_{l_{i,j}}})
(i−So^ti,j,j−So^li,j)和
(
i
+
S
o
^
b
i
,
j
,
j
+
S
o
^
r
i
,
j
)
(i+S_{\hat{o}_{b_{i,j}}}, j+S_{\hat{o}_{r_{i,j}}})
(i+So^bi,j,j+So^ri,j)
进一步,使用
2
l
2^l
2l对投影框进行缩放来获得图像的最终框
box的置信分数和分类可以由分类输出映射中的最大分数和对应的类别来决定
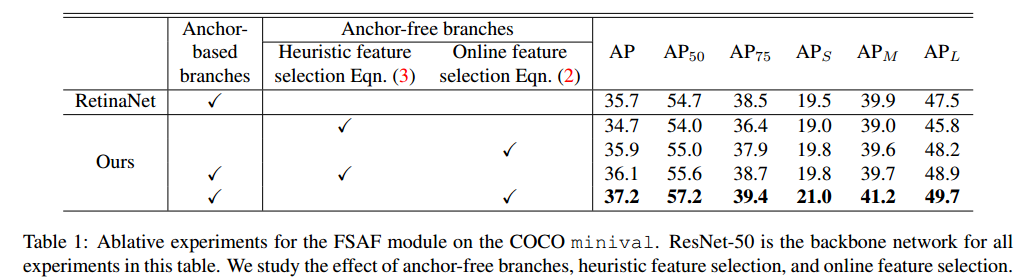
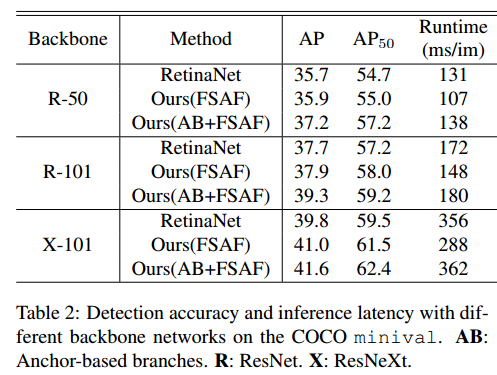
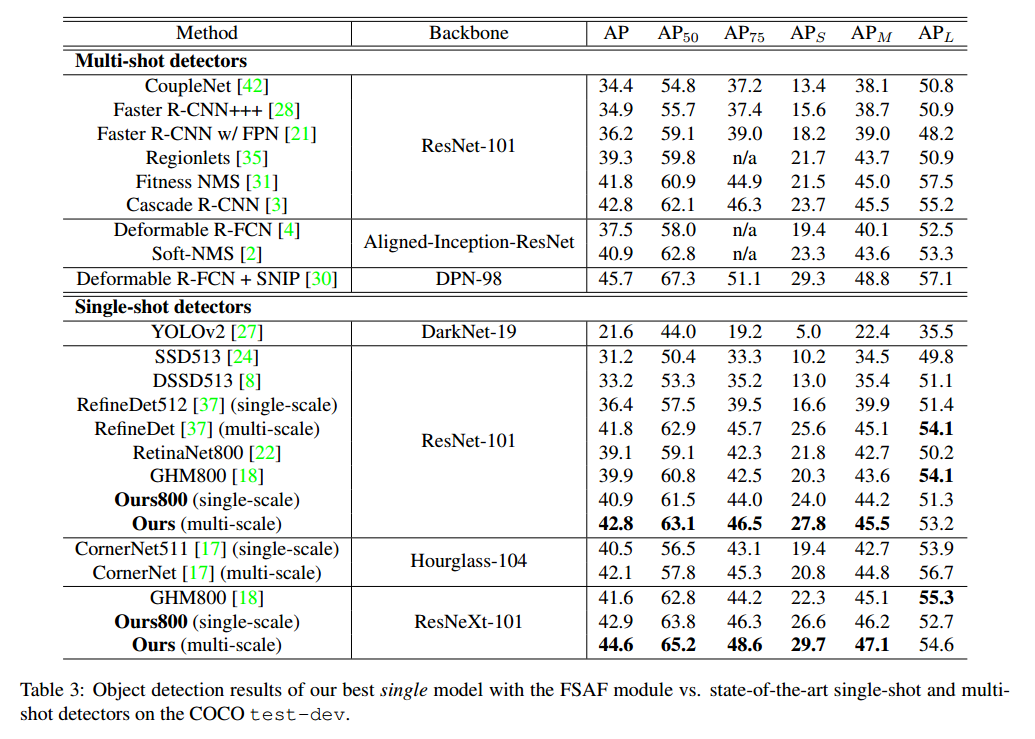
3.3 在线特征选择
anchor-free分支的设计允许我们使用人员金字塔层
P
l
P^l
Pl 的特征,为了选择最优特征层,FSAF模型基于实例内容选择最优的
P
l
P^l
Pl ,而不是例如anchor-based方法中使用的实例框的大小来选择。
给定一个实例
I
I
I ,定义在
P
l
P^l
Pl 上的分类损失和回归损失为
L
F
L
I
(
l
)
L^I_{FL}(l)
LFLI(l) 和
L
I
o
U
I
(
l
)
L^I_{IoU}(l)
LIoUI(l),通过对有效框区域
b
e
l
b^l_e
bel 的focal loss和IoU loss分别进行平均而获得:
L
F
L
I
(
l
)
=
1
N
(
b
e
l
)
∑
i
,
j
∈
b
e
l
F
L
(
l
,
i
,
j
)
L^I_{FL}(l)=\frac{1}{N(b^l_e)} \sum _{i,j \in b_e^l} FL(l,i,j)
LFLI(l)=N(bel)1i,j∈bel∑FL(l,i,j)
L
I
o
U
I
(
l
)
=
1
N
(
b
e
l
)
∑
i
,
j
∈
b
e
l
I
o
U
(
l
,
i
,
j
)
L^I_{IoU}(l)=\frac{1}{N(b^l_e)} \sum _{i,j \in b_e^l} IoU(l,i,j)
LIoUI(l)=N(bel)1i,j∈bel∑IoU(l,i,j)
其中,
N
(
b
e
l
)
N(b^l_e)
N(bel) 是
b
e
l
b_e^l
bel区域内的所有像素点的和,
F
L
(
l
,
i
,
j
)
FL(l,i,j)
FL(l,i,j) 和
I
o
U
(
l
,
i
,
j
)
IoU(l,i,j)
IoU(l,i,j) 是在
P
l
P_l
Pl 上的
(
i
,
j
)
(i,j)
(i,j)位置上的 focal loss 和 IoU loss。
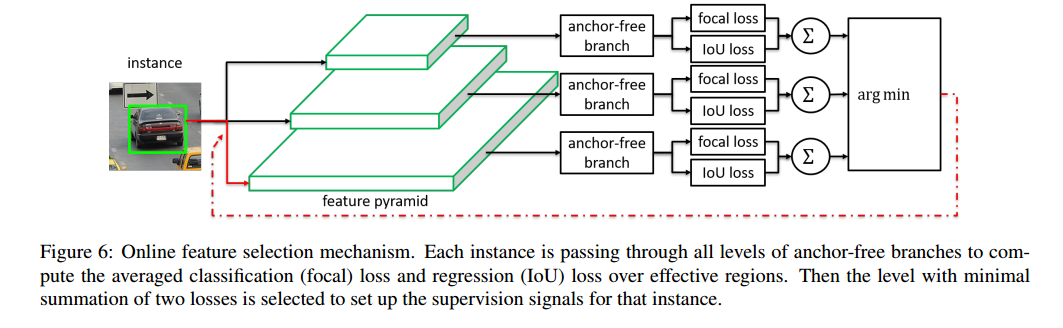
Fig.6 表示了我们的在线特征选择过程,首先对实例
I
I
I在金字塔的每个层进行前向传播。 之后对所有anchor-free分支上利用公式(1)计算
L
F
L
I
(
l
)
L^I_{FL}(l)
LFLI(l) 和
L
I
o
U
I
(
l
)
L^I_{IoU}(l)
LIoUI(l) 的和。
最后,产生的损失之和最小的也就是最优的金字塔层
P
l
∗
P_{l^*}
Pl∗ 被用来学习实例:
l
∗
=
a
r
g
m
i
n
l
L
F
L
I
(
l
)
+
L
I
o
U
I
(
l
)
l^*=argmin_lL^I_{FL}(l)+L^I_{IoU}(l)
l∗=argminlLFLI(l)+LIoUI(l)