1、multiply
例子:
x1=[1,2,3];x2=[4,5,6]
print multiply(x1,x2)
输出:
[ 4 10 18]
multiply函数得到的结果是对应位置上面的元素进行相乘。
2、std 标准方差 ,var 方差
例子:
b=[1,3,5,6]
print var(b)
print power(std(b),2)
ll=[[1,2,3,4,5,6],[3,4,5,6,7,8]]
print var(ll[0])
print var(ll,0)#第二个参数为0,表示按列求方差
print var(ll,1)#第二个参数为1,表示按行求方差
输出:
3.6875
3.6875
2.91666666667
[ 1. 1. 1. 1. 1. 1.]
[ 2.91666667 2.91666667]
var输出向量的方差,std输出向量的标准方差。
3、mean
例子:
b=[1,3,5,6]
print mean(b)
print mean(ll) #全部元素求均值
print mean(ll,0)#按列求均值
print mean(ll,1)#按行求均值
结果:
3.75
4.5
[ 2. 3. 4. 5. 6. 7.]
[ 3.5 5.5]
mean函数得到向量的均值。
4、sum
求和
例子
x=[[0, 1, 2],[2, 1, 0]]
b=[1,3,5,6]
print sum(b)
print sum(x)
输出:
15
6
sum求向量的和。也可以求矩阵所有元素的和
5、cov()
例子:
b=[1,3,5,6]
print cov(b)
print sum((multiply(b,b))-mean(b)*mean(b))/3
输出:
4.91666666667
4.91666666667
cov求的是样本协方差
公式如下:
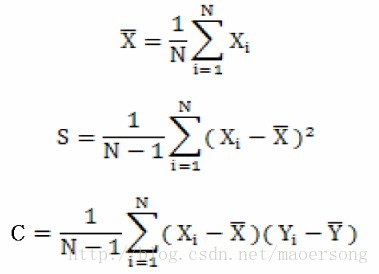
公式一是样本均值
公式二是样本方差
公式三是样本协方差。
上面的函数cov就是使用样本协方差求得的。
例子:
x=[[0, 1, 2],[2, 1, 0]]
print cov(x)
print sum((multiply(x[0],x[1]))-mean(x[0])*mean(x[1]))/2
输出结果:
[[ 1. -1.]
[-1. 1.]]
-1.0
cov的参数是矩阵,输出结果也是矩阵!输出的矩阵为协方差矩阵!
计算过程如下:

截图来源维基百科:协方差矩阵
6、corrcoef
该函数得到相关系数矩阵。
例子:
vc=[1,2,39,0,8]
vb=[1,2,38,0,8]
print mean(multiply((vc-mean(vc)),(vb-mean(vb))))/(std(vb)*std(vc))
#corrcoef得到相关系数矩阵(向量的相似程度)
print corrcoef(vc,vb)
输出结果:
0.999986231331
[[ 1. 0.99998623]
[ 0.99998623 1. ]]
相关系数公式:

对应着公式理解上面的代码,应该是很容易的。
7、vdot 向量的点积
例子:
#vdot 返回两向量的点积
l1=[1,2,3]
l2=[4,5,6]
print vdot(l1,l2)
结果:
32
点积没什么说的,对应位置相乘求和。
8、mat
例子:
l1=[1,2,3]
l2=[4,5,6]
ll=[l1,l2]
print vdot(l1,l2)
print mat(l1)*mat(l2).T
print mat(ll)
结果:
32
[[32]]
[[1 2 3]
[4 5 6]]
mat函数把列表转换成矩阵形式。这在矩阵运算中不可缺少。
9、shape
例子:
#矩阵有一个shape属性,是一个(行,列)形式的元组
a = array([[1,2,3],[4,5,6]])
print a.shape
结果:
(2, 3)
shape返回矩阵的行列数
10、ones
例子:
#返回按要求的矩阵
ones = ones((2,1))
print ones
结果:
[[ 1.]
[ 1.]]
ones返回指定行列数的全一矩阵
11、xrange
例子:
for i in xrange(3):
print i
test=[1,2,3,4]
print test[:]
print test[2:3]
for i in xrange(2,5):
print i
结果:
0
1
2
[1, 2, 3, 4]
[3]
2
3
4
xrange用于循环中,参数为一个整数的话,可循环遍历小于该参数的值。两个参数,则循环遍历两个整数之间的值。
test[:]则表示获取test列表中的所有元素。
test[2:3]则表示获取从第2个位置到第三个位置间的元素。
12、strptime
例子:
import time
from datetime import datetime,date
dd = datetime.strptime('2014-04-03T10:53:49.875Z', "%Y-%m-%dT%H:%M:%S.%fZ")
print time.mktime(dd.timetuple())#1396493629.0
结果:
1396493629.0
strptime把时间按照指定的格式转换。处理时间的时候会用到这个函数。
13、tuple和数组转换成字符串
例子:
tuple =(1,2,3)
print tuple[len(tuple)-1]
print tuple[-1]
print 9.99.__repr__()
print str(9.99)
结果:
3
3
9.99
9.99
上面的示例中tuple是一个元组,访问元素的时候,可以通过[index]这种方式访问。
访问最后一个元素的时候,可以通过[-1]访问.
那么访问倒数第二个元素:
print tuple[-2]
输出结果:2
另外,数字转换成字符串有两种方式:
_ _ repr _ _()
str()
14、transpose和.T
例子:
aa =[[1],[2],[3]]
aa= mat(aa)#将列表转换成矩阵,并存放在aa中
print aa
print aa.transpose()#将矩阵进行转置
print aa #transpose()进行矩阵的转置,aa并没有改变
print '*'*20
print aa.T
print aa #T转置矩阵,也没有发生改变
输出结果:
[[1]
[2]
[3]]
[[1 2 3]]
[[1]
[2]
[3]]
********************
[[1 2 3]]
[[1]
[2]
[3]]
有两种方式实现矩阵的转置。
15、zeros() ones()
例子:
print zeros((2,1))
print ones((2,3))#参数指明了矩阵的行列数
结果:
[[ 0.]
[ 0.]]
[[ 1. 1. 1.]
[ 1. 1. 1.]]
zeros返回指定行列全零矩阵
ones返回指定行列的全一矩阵
16、列表 数组 linspace
例子:
#列表和数组的区别:
#列表: [1, 2, 3, 4]
#数组: [1 2 3 4]
print '*'*20
ll =[1,2,3,4]
print '列表:',ll
arr = array(ll)
print '数组:',arr
print '*'*20
print linspace(0,3,6) #返回的是数组
输出结果:
********************
列表: [1, 2, 3, 4]
数组: [1 2 3 4]
********************
[ 0. 0.6 1.2 1.8 2.4 3. ]
数组中间元素没有分隔符。列表逗号分割。
linspace返回的是指定的开始结束位置的指定个数的数。
linspace(0,3,6)返回0到3之间6个数字,且间隔均匀
17、argsort 排序索引
例子:
print '**************数组排序问题****************'
#数组的构建问题,初始化使用array()
ary=array(zeros(4))
ary[0]=0.1
ary[1]= 0.6
ary[2]= 0.5
ary[3]= 0.7
#有-号,降序排列
#无-号,升序排列
sortindex = argsort(ary)
for id in sortindex:
print '索引:',id
for i in ary:
print i
结果:
**************数组排序问题****************
索引: 0
索引: 2
索引: 1
索引: 3
0.1
0.6
0.5
0.7
argsort函数返回数组按照从小到大排序的位置的索引。
sortindex = argsort(-ary)
for id in sortindex:
print ‘索引:’,id
for i in sortindex:
print ary[i]
输出结果:
索引: 1
索引: 2
索引: 0
0.7
0.6
0.5
0.1
18、 [:,:]矩阵元素切片
#矩阵元素的获取
ll = [[1,2,3],[4,5,6],[7,8,9]]
#获取第二行第0个元素
print mat(ll)[2,0]
#第一个冒号代表获取行的起止行号
#第二个冒号代表获取列的起止行号
print mat(ll)[:,:]
结果:
7
[[1 2 3]
[4 5 6]
[7 8 9]]
19、diag
例子:
#构建对角矩阵
#diag()参数为列表即可
dd = [1,2,3]
dilogg = diag(dd)
print 'diag=',dilogg
结果:
diag= [[1 0 0]
[0 2 0]
[0 0 3]]
diag构建对角矩阵
20、linalg.inv和.I 求逆矩阵
例子:
dd = [1,2,3]
dilogg = diag(dd)
print 'diag=',dilogg
print 'dd:',linalg.inv(dilogg)
print 'I=',mat(dilogg).I
ll = [[1,2,3],[4,5,6],[7,8,9]]
#求逆矩阵
lv = linalg.inv(mat(ll))
print 'inv:',lv
print 'I:',mat(ll).I
结果:
diag= [[1 0 0]
[0 2 0]
[0 0 3]]
dd: [[ 1. 0. 0. ]
[ 0. 0.5 0. ]
[ 0. 0. 0.33333333]]
I= [[ 1. 0. 0. ]
[ 0. 0.5 0. ]
[ 0. 0. 0.33333333]]
inv: [[ -4.50359963e+15 9.00719925e+15 -4.50359963e+15]
[ 9.00719925e+15 -1.80143985e+16 9.00719925e+15]
[ -4.50359963e+15 9.00719925e+15 -4.50359963e+15]]
I: [[ -4.50359963e+15 9.00719925e+15 -4.50359963e+15]
[ 9.00719925e+15 -1.80143985e+16 9.00719925e+15]
[ -4.50359963e+15 9.00719925e+15 -4.50359963e+15]]
上面求逆矩阵有两种方式。
linalg.inv()和 矩阵.I
两种方式均可。
21、dot矩阵点积
例子:
ll = [[1,2,3],[4,5,6],[7,8,9]]
ld = dot(ll,ll)
print 'dot:',ld
print mat(ll)*mat(ll)
结果:
dot: [[ 30 36 42]
[ 66 81 96]
[102 126 150]]
[[ 30 36 42]
[ 66 81 96]
[102 126 150]]
22、eye 单元矩阵
例子:
print 'eye:',eye(2)#单元矩阵
结果:
eye: [[ 1. 0.]
[ 0. 1.]]
23 eig 矩阵的特征值和特征向量
例子:
A=mat([[1,0,0,0,2],[0,0,3,0,0],[0,0,0,0,0],[0,4,0,0,0]])
U =A*A.T
lamda,hU=linalg.eig(U)
print 'hU:',hU
print lamda
结果:
hU: [[ 1. 0. 0. 0.]
[ 0. 1. 0. 0.]
[ 0. 0. 1. 0.]
[ 0. 0. 0. 1.]]
[ 5. 9. 0. 16.]
24 sorted 排序
例子:
ll=[8,0,3,6,1,0,5,3,8,9]
print sorted(ll,reverse=True) #降序
print sorted(ll,reverse=False) #升序
结果:
[9, 8, 8, 6, 5, 3, 3, 1, 0, 0]
[0, 0, 1, 3, 3, 5, 6, 8, 8, 9]
25、linalg.svd 奇异值分解
例子:
A=mat([[1,0,0,0,2],[0,0,3,0,0],[0,0,0,0,0],[0,4,0,0,0]])
U,S,VT =linalg.svd(A)
print 'U:',U
print 'V:',VT
print 's:',S
print '===',U*(mat(diag(S))*eye(4,5))*VT
结果:
U: [[ 0. 0. 1. 0.]
[ 0. 1. 0. 0.]
[ 0. 0. 0. -1.]
[ 1. 0. 0. 0.]]
V: [[ 0. 1. -0. -0. -0. ]
[ 0. 0. 1. -0. -0. ]
[ 0.4472136 0. -0. -0. 0.89442719]
[ 0. 0. -0. 1. -0. ]
[-0.89442719 0. -0. -0. 0.4472136 ]]
s: [ 4. 3. 2.23606798 0. ]
=== [[ 1. 0. 0. 0. 2.]
[ 0. 0. 3. 0. 0.]
[ 0. 0. 0. 0. 0.]
[ 0. 4. 0. 0. 0.]]
关于什么是奇异值分解,请参考奇异值分解
26、random.rand
例子:
A=mat([[1,0,0,0,2],[0,0,3,0,0],[0,0,0,0,0],[0,4,0,0,0]])
print A[:,1]
#获取3*3个0-1之间的数字
rr=random.rand(3,3)
print rr
print (rr-0.5)
print 2.0*(rr-0.5)
结果:
[[0]
[0]
[0]
[4]]
[[ 0.30446153 0.40653841 0.40143809]
[ 0.77970727 0.57491894 0.85801586]
[ 0.33509491 0.64652856 0.48276137]]
[[-0.19553847 -0.09346159 -0.09856191]
[ 0.27970727 0.07491894 0.35801586]
[-0.16490509 0.14652856 -0.01723863]]
[[-0.39107693 -0.18692318 -0.19712383]
[ 0.55941453 0.14983789 0.71603172]
[-0.32981018 0.29305712 -0.03447726]]
random.rand(3,3)随机获取3*3个0-1之间的数字
27、arange
例子:
delta = 0.25
x = arange(-3.0, 3.0, delta)
print x
结果:
[-3. -2.75 -2.5 -2.25 -2. -1.75 -1.5 -1.25 -1. -0.75 -0.5 -0.25
0. 0.25 0.5 0.75 1. 1.25 1.5 1.75 2. 2.25 2.5 2.75]
arange获取指定起始位置,指定步长的一系列数。
28、nonzero()
例子:
x =[[1,0,0,0,2],[0,0,3,0,0]]
print x
nz=nonzero(x)
print nz
print nz[0]
结果:
[[1, 0, 0, 0, 2], [0, 0, 3, 0, 0]]
(array([0, 0, 1]), array([0, 4, 2]))
[0 0 1]
nonzero()函数返回矩阵中非0元素的位置
nz的返回值意义如下:
第一行是所有非零数所在行值
第二行是所有非零值所在列值
29、获取指定位置的元素
例子:
A=mat([[1,0,0,0,2],[0,0,3,0,0],[0,0,0,0,0],[0,4,0,0,0]])
sample =A[0,:]
print sample
print sample[0]
ll=mat([3,4,5])
for i in range(5):
if sum(ll==i):
print i
结果:
[[1 0 0 0 2]]
[[1 0 0 0 2]]
3
4
A[0,:]的意义是获取第0行的所有元素
if sum(ll==i):的意义是只要i存在ll矩阵中,if就是True
ll必须是mat转换的矩阵。列表好像不行。并且还是单行的矩阵。
第二个例子:
A=mat([[1,0,0,0,2],[0,0,3,0,0],[0,0,0,0,0],[0,4,0,0,0]])
#根据ind序列索引获取矩阵A中的数据
ind=[2,1,3,0]
print A[ind,0]
结果:
[[0]
[0]
[0]
[1]]
30、zip
例子:
ll=[1,2,3,4,5,6]
#可以互换指定区域的位置
print ll[3:6]+ll[0:3]
#成对获取x、y的值
l1=[1,2,3]
l2=[4,5,6]
for x,y in zip(l1,l2):
print x,y
结果:
[4, 5, 6, 1, 2, 3]
1 4
2 5
3 6
print ll[3:6]+ll[0:3]这行代码实现指定位置的元素进行交换。
31、chr函数,获取指定的字符
例子:
#获取指定的字符
for i in range(65,70):
print str(chr(i))
结果:
A
B
C
D
E
32、random.shuffle
例子:
ll=range(9)#返回列表
print ll
#shuffle函数随机打乱列表中的元素顺序
print random.shuffle(ll)
print ll
结果:
[0, 1, 2, 3, 4, 5, 6, 7, 8]
None
[8, 5, 1, 4, 2, 6, 0, 3, 7]
shuffle函数随机打乱列表中的元素顺序
33、vdot 点积
例子:
#vdot 返回两向量的点积
l1=[1,2,3]
l2=[4,5,6]
ll=[l1,l2]
print vdot(l1,l2)
print dot(l1,l2)
print mat(l1)*mat(l2).T
print mat(ll)
结果:
32
32
[[32]]
[[1 2 3]
[4 5 6]]
vdot 和 dot都可以获取向量的点积。
区别:
ll=[[1,2,3],[4,5,6],[1,2,3]]
print dot(mat(ll),mat(ll).T)
print vdot(mat(ll),mat(ll))
结果:
[[14 32 14]
[32 77 32]
[14 32 14]]
[[105]]
总结:对于向量来说,vdot dot向量的点积结果相同。
对于矩阵来说,dot是矩阵的点积。
而vdot是对应位置的元素乘积求和。
结果中的105=1^2+2^2+3^3+4^2+5^2+6^2+1^2+2^2+3^3
34、次方计算**
例子:
print 3*2**2
print 3*2**0.5
print (3*2)**2
print (3*2)**0.5
结果:
12
4.24264068712
36
2.44948974278
可见 **次方计算优先级要高!
35、max函数
例子:
ll=[3,4,6,2,89,9,3,2]
print max(ll)
l2=[[3,4,6,2,89,9,3,2],[3,6,7,8,983,3,5,6]]
print max(l2[0])
print max(l2)
结果:
89
89
[3, 6, 7, 8, 983, 3, 5, 6]
对于矩阵的最大值的求法,还不知道怎么搞。稍后更新一下。
36、mgrid函数
#开始值,结束值,步长。如果步长为虚数,表示产生的个数长度
print mgrid[-5:5:3j] #结果:[-5. 0. 5.]
print mgrid[-5:5:3] #结果:[-5 -2 1 4]
print '*'*20
print mgrid[-5:5:3j,-5:5:3j]
print '*'*20
print mgrid[-5:5:3,-5:5:3]
结果:
[-5. 0. 5.]
[-5 -2 1 4]
********************
[[[-5. -5. -5.]
[ 0. 0. 0.]
[ 5. 5. 5.]]
[[-5. 0. 5.]
[-5. 0. 5.]
[-5. 0. 5.]]]
********************
[[[-5 -5 -5 -5]
[-2 -2 -2 -2]
[ 1 1 1 1]
[ 4 4 4 4]]
[[-5 -2 1 4]
[-5 -2 1 4]
[-5 -2 1 4]
[-5 -2 1 4]]]
mgrid函数说明:开始值,结束值,步长。如果步长为虚数,表示产生的个数长度。
对照结果即可知道函数的功能。
37、ogrid函数
例子:
print ogrid[-5:5:3j]
print ogrid[-5:5:3]
print ogrid[-5:5:3j,-5:5:3j]
print ogrid[-5:5:3,-5:5:3]
结果:
[-5. 0. 5.]
[-5 -2 1 4]
[array([[-5.],
[ 0.],
[ 5.]]), array([[-5., 0., 5.]])]
[array([[-5],
[-2],
[ 1],
[ 4]]), array([[-5, -2, 1, 4]])]
ogrid跟mgrid一样。不同的是,一个数矩阵,一个数组形式。第三个擦数如果是实数,说明是步长。如果是虚数,说明是个数。
ogrid[-5:5:3,-5:5:3]第一部分产生多行一列,第二部分产生一行多列。这与mgrid不同。
38、random函数
print random.seed(1)
#要每次产生随机数相同就要设置种子,相同种子数的Random对象,相同次数生成的随机数字是完全相同的
#用于生成一个指定范围内的随机符点数
print random.uniform(-1,1,5)
#结果:[ 0.40254497 -0.42350395 -0.67640645 -0.54075394 -0.99584028]
#均匀分布
#用于生成一个0到1的随机符点数: 0 <= n < 1.0
print random.random()
print random.random(5)
print random.rand(2,3)#2行3列
结果:
None
0.417022004703
[ 7.20324493e-01 1.14374817e-04 3.02332573e-01 1.46755891e-01
9.23385948e-02]
[[ 0.18626021 0.34556073 0.39676747]
[ 0.53881673 0.41919451 0.6852195 ]]
#用于生成一个指定范围内的整数。其中参数a是下限,参数b是上限,生成的随机数n: a <= n <= b
print random.randint(5, 10)
print random.randint(5,10,size=(5,5))
结果:
None
8
[[9 5 6 8 5]
[5 6 9 9 6]
[7 9 7 9 8]
[9 7 9 7 9]
[6 6 5 6 6]]
更多关于random的函数的解析,请参看这篇文章:http://blog.csdn.net/pipisorry/article/details/39086463
39、tofile、fromfile
例子:
a =arange(0,12)
a.shape = 3,4
print a
a.tofile("a.bin")
b = fromfile("a.bin", dtype=float) # 按照float类型读入数据
print b # 读入的数据是错误的
print a.dtype # 查看a的dtype
b = fromfile("a.bin", dtype=int32) # 按照int32类型读入数据
print b # 数据是一维的
b.shape = 3, 4 # 按照a的shape修改b的shape
print b
结果:
None
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[ 2.12199579e-314 6.36598737e-314 1.06099790e-313 1.48539705e-313
1.90979621e-313 2.33419537e-313]
int32
[ 0 1 2 3 4 5 6 7 8 9 10 11]
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
使用数组的方法函数tofile可以方便地将数组中数据以二进制的格式写进文件。tofile输出的数据没有格式,因此用numpy.fromfile读回来的时候需要自己格式化数据。
Note:
1. 读入的时候设置正确的dtype和shape才能保证数据一致。
并且tofile函数不管数组的排列顺序是C语言格式的还是Fortran语言格式的,统一使用C语言格式输出。
2. sep关键字参数:此外如果fromfile和tofile函数调用时指定了sep关键字参数的话,
数组将以文本格式输入输出。{这样就可以通过notepad++打开查看, 不过数据是一行显示,不便于查看}
user_item_mat.tofile(user_item_mat_filename, sep=’ ‘)
40、numpy.load和numpy.save
例子:
a =arange(0,12)
a.shape = 3,4
print a
save('a.npy',a)
c=load('a.npy')
print c
结果:
None
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
numpy.load和numpy.save函数(推荐在不需要查看保存数据的情况下使用)
以NumPy专用的二进制类型保存数据,这两个函数会自动处理元素类型和shape等信息,
使用它们读写数组就方便多了,但是numpy.save输出的文件很难和其它语言编写的程序读入。
Note:
1. 文件要保存为.npy文件类型,否则会出错
2. 保存为numpy专用二进制格式后,就不能用notepad++打开(乱码)看了,这是相对tofile内建函数不好的一点
numpy.savez函数
如果你想将多个数组保存到一个文件中的话,可以使用numpy.savez函数。savez函数的第一个参数是文件名,其后的参数都是需要保存的数组,也可以使用关键字参数为数组起一个名字,非关键字参数传递的数组会自动起名为arr_0, arr_1, …。savez函数输出的是一个压缩文件(扩展名为npz),其中每个文件都是一个save函数保存的npy文件,文件名对应于数组名。load函数自动识别npz文件,并且返回一个类似于字典的对象,可以通过数组名作为关键字获取数组的内容:
如果你用解压软件打开result.npz文件的话,会发现其中有三个文件:arr_0.npy, arr_1.npy, sin_array.npy,其中分别保存着数组a, b, c的内容。
a = array([[1,2,3],[4,5,6]])
b = arange(0, 1.0, 0.1)
c = sin(b)
savez("result.npz", a, b, sin_array = c)
r =load("result.npz")
print r["arr_0"] # 数组a
print r["arr_1"] # 数组b
print r["sin_array"] # 数组c
结果:
None
[[1 2 3]
[4 5 6]]
[ 0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9]
[ 0. 0.09983342 0.19866933 0.29552021 0.38941834 0.47942554
0.56464247 0.64421769 0.71735609 0.78332691]
numpy.savetxt和numpy.loadtxt(推荐需要查看保存数据时使用)
Note:savetxt缺省按照’%.18e’格式保存数据, 可以修改保存格式为‘%.8f’(小数点后保留8位的浮点数), ’%d’(整数)等等
总结:
载入txt文件:numpy.loadtxt()/numpy.savetxt()
智能导入文本/csv文件:numpy.genfromtxt()/numpy.recfromcsv()
高速,有效率但numpy特有的二进制格式:numpy.save()/numpy.load()
39、40部分来源:http://blog.csdn.net/pipisorry/article/details/39088003。详细内容请参看这个链接。
41、permutation函数
例子:
#混淆位置。如果是多维数组,则混淆一维的。例如下面的arr.
print random.permutation(10)
print random.permutation([1, 4, 9, 12, 15])
arr=arange(9).reshape((3,3))
print arr
print random.permutation(arr)
结果:
None
[2 9 6 4 0 3 1 7 8 5]
[12 1 4 9 15]
[[0 1 2]
[3 4 5]
[6 7 8]]
permutation混淆位置。如果是多维数组,则混淆一维的。例如下面的arr.
42、complex构造复数
例子:
print complex(0,100)#结果:100j
43、norm求范数
例子:
from scipy.linalg.misc import norm
print norm([8,6,10])
结果:
14.1421356237
默认情况下,求二范数。也就是各个元素的平方和再开平方。
当然,也可以求取其他范数。例如p范数、无穷范数等。
我这里import写的是scipy。其实numpy里面也有这个函数。详细的其他范数的求法请参考官网http://docs.scipy.org/doc/numpy-1.10.0/reference/generated/numpy.linalg.norm.html内容的介绍。对于求二范数的结果,我这里介绍的就够用了。
待续。。。。!!