1.概述
最近看到一句话,感觉很扎心,这句话是”任何一个男孩子小时候的梦想,绝对不是买套房“。
其实,刚从象牙塔步入社会的时候,不曾想过房的事情。记得2016年房价猛涨,方才对房有了一些认知而已。直到随着年龄的增长,房子的故事便不得不需要展开了。
北上广深如今的房价又到了什么样惊人的数值呢?从贝壳找房最新的贝壳指数来看:北京是6.13万,上海5.62万,广州2.86万,深圳7.05万。
今天,我们从贝壳找房 爬取了 8万+二手房源信息,看看在北京的二手房都是什么样的存在。
通过本篇,大家可以在了解北京二手房多维度信息的同时学习Python的re正则表达式、pandas数据处理以及绘图库(pyecharts、seaborn)柱状图+饼图+直方图+箱线图+map+热力图+堆叠图和高德api的使用等。
数据说明:
数据来源:贝壳找房-二手房
数据日期:2020年12月28日
数据量级:82,346(含车位,数据处理阶段清洗)
工具环境
Python 3.8.5
| 库 |
用途 |
| requests |
爬虫请求网站数据 |
| re |
正则解析网页数据及数据清洗 |
| pandas |
数据清洗及统分 |
| pyecharts |
绘图 |
| matplotlib |
绘图 |
| seaborn |
绘图 |
2.数据采集
贝壳找房的数据爬取比较简单,简单的翻页规律和HTML网页文本解析。我们编写for循环,用requests请求数据,再用re正则表达式进行房源数据解析即可。
鉴于整个爬虫过程并不复杂,这里亦不细说,后续专题介绍如何获取全部数据。
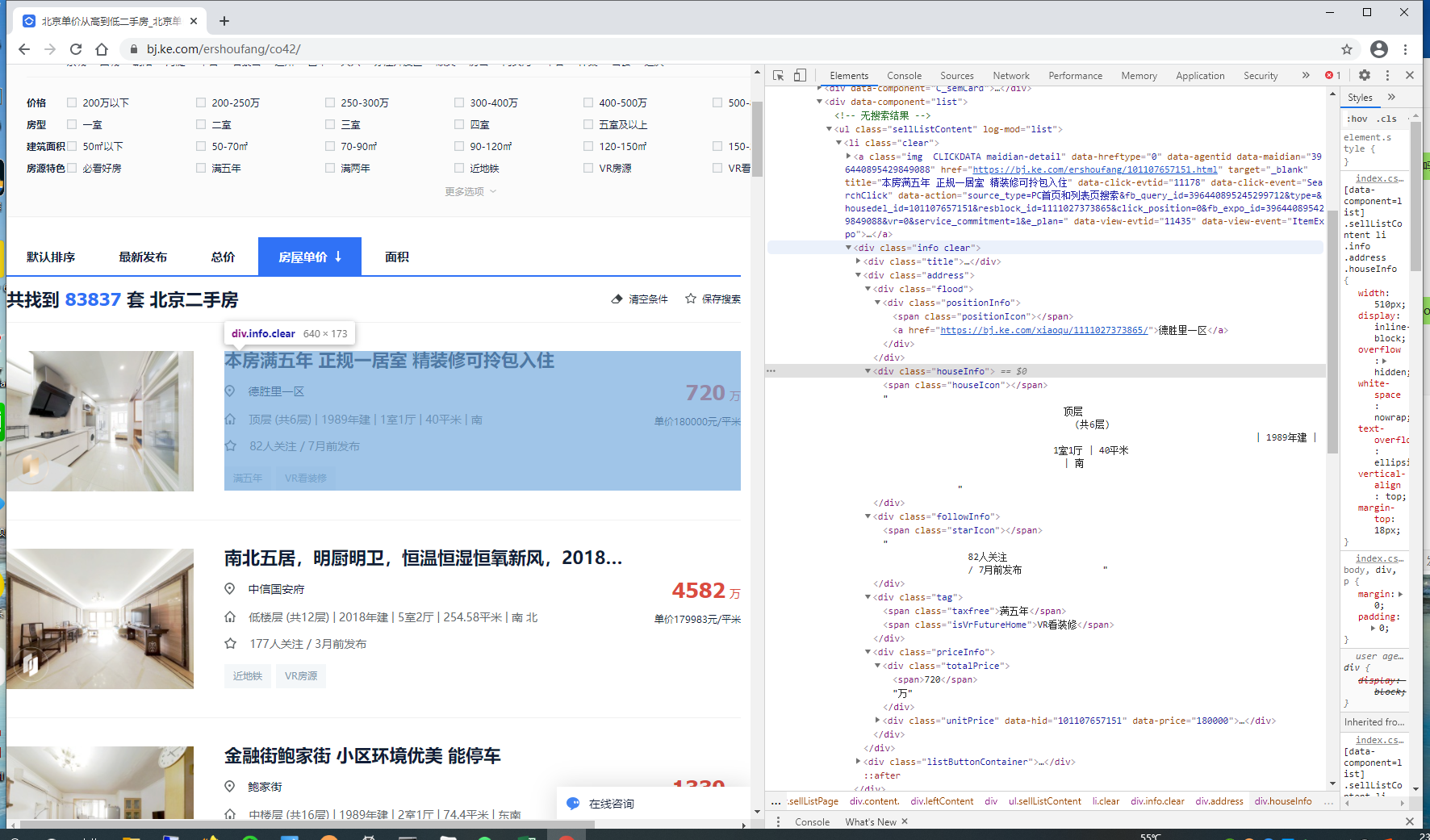
房源数据解析代码如下:
# 请求网页数据函数
def get_html(url, proxies):
try:
rep = requests.get(url, headers= header, proxies= proxies, timeout=6)
except Exception as e :
print(e)
proxies = get_proxies()
rep = requests.get(url, headers= header, proxies= proxies, timeout=6)
while rep.status_code != 200:
proxies = get_proxies()
rep = requests.get(url, headers= header, proxies= proxies, timeout=6)
html = rep.text
html = re.sub('\s', '', html) # 将html文本中非字符数据去掉
return html,proxies
# 循环请求每页数据
num = 0
for page in range(1,pages+1):
items = []
time.sleep(random.random())
info_url = f'{url}/pg{page}'
try:
info_html, proxies = get_html(info_url, proxies)
except Exception as e:
print(e)
continue
sellListContent = re.findall(r'<ulclass="sellListContent"log-mod="list">(.*?)</ul>', info_html)[0]
Lists = re.findall(r'<liclass="clear">(.*?)</li>', sellListContent)
for List in Lists:
try:
# 获取房屋信息
item = {}
item['标题'] = re.findall(r'detail"title="(.*?)"data-hreftype=', List)[0]
item['房子ID'] = re.findall(r'housedel_id=(\d+)&', List)[0]
item['地址'] = re.findall(r'<ahref="(.*?)">(.*)</a>', List)[0][1]
item['详情页'] = re.findall(r'<ahref="(.*?)">(.*)</a>', List)[0][0]
item['详情'] = re.findall(r'<spanclass="houseIcon"></span>(.*?)</div>', List)[0]
item['总价'] = re.findall(r'<divclass="totalPrice"><span>(\d+\.?\d*)</span>(.*?)</div>', List)[0][0]
item['总价单位'] = re.findall(r'<divclass="totalPrice"><span>(\d+\.?\d*)</span>(.*?)</div>', List)[0][1]
item['均价'] = re.findall(r'<divclass="unitPrice".*<span>(.*?)</span></div></div></div>', List)[0]
item['关注人数'] = re.findall(r'<spanclass="starIcon"></span>(.*?)</div>', List)[0]
item['地区'] = areaName
item['价格区间'] = priceRange
item['户型'] = layout
items.append(item)
num = num+1
print(f'{num}个房子信息已经采集!')
except Exception as e:
print(e)
print(item)
continue
说明:
由于翻页最多支持100页,每页约30个房源数据,如果我们想获取全部的数据,需要注意两点:
- 可以通过进行更细颗粒度的筛选后再进行url的组合,一般来说可以通过 区域 和 价格区间 和 户型 进行组合即可,我这边即是采用这种组合策略;
- 由于网站对同IP的访问频率和次数是有限制的,因此需要用到代理IP,购买付费的代理IP就可满足学习需求了,在requests.get()函数中加上proxies参数即可。
3.数据清洗
这部分我们用到pandas和re,主要是过滤非住宅房源的车位数据信息,解析房源更多有用信息。
3.1.读取数据
import pandas as pd
import re
df = pd.read_excel('贝壳在售二手房数据20201228.xlsx')
df.sort_values(by='总价')

我们可以看到,在原始数据中 详情包含的信息较多,比如楼层、户型、面积、建筑年份和朝向等等,对于地下室和底层的部分大多数都是车位,索性就不考虑这部分数据,这部分我们后续进行清洗。同时,在均价和关注人数中也都包含更多信息需要我们解析出来。
3.2.去掉车位(地下室)数据
# 车位条件,不一定严谨
mask = ((df['详情'].str.contains('地下室'))
# & (df['详情'].str.contains('1室'))
# &(~df['详情'].str.contains(r'地下室\(共[2-9]|[1-9]\d+层\)'))
)|((df['详情'].str.contains('底层')) & (df['详情'].str.contains('1室'))
&(~df['详情'].str.contains(r'底层\(共[2-9]|[1-9]\d+层\)'))
)
# 房子
house = df[~mask]
# 车位
carport = df[mask]
carport.sort_values(by='总价')
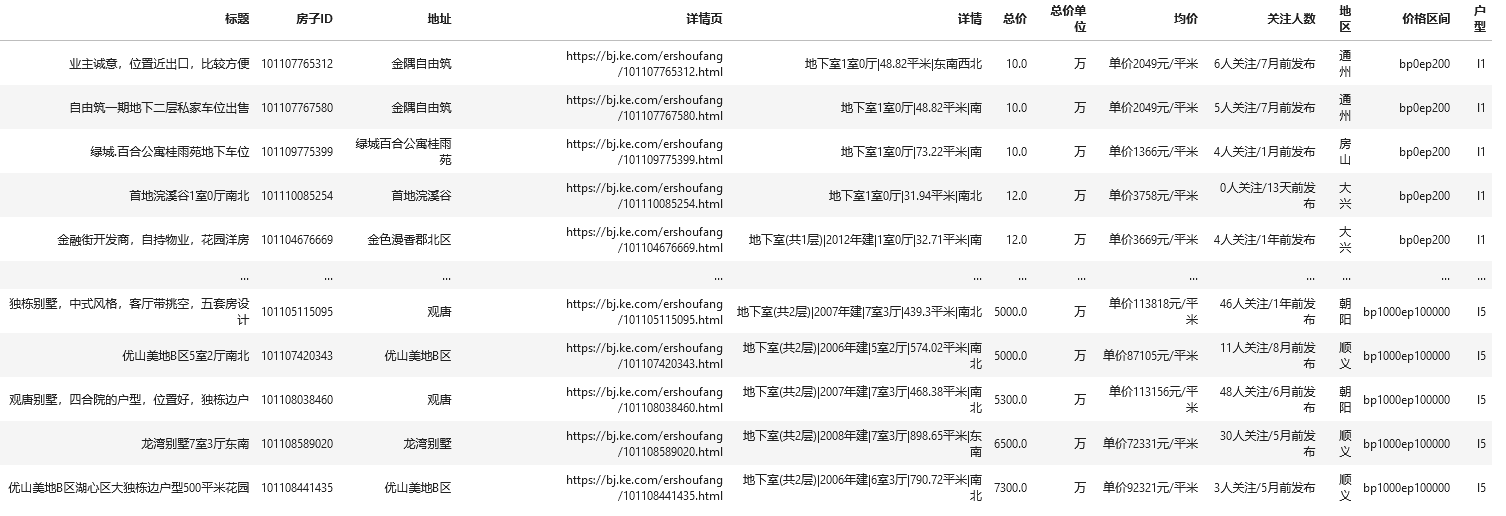
哈哈,有点尴尬,部分别墅被误处理了。不过没事,别墅咱们就先不考虑,毕竟更买不起!
3.3.房源信息解析
# 详情信息解析
s = '中楼层(共9层)|2007年建|1室1厅|24.78平米|北'
# s = '地下室|2014年建|1室0厅|39.52平米|东'
# s = '底层(共2层)5室3厅|326.56平米|东南西北'
# s = '地下室1室0厅|11.9平米|南'
# re.split(r'(.+?)(\(共(.*)层\))*(\|((.*)年建)*\|)*?(\d+室.*?)\|(.*)平米\|(.*)',s)
re.split(r'(.+?)(?:\(共(.*)层\))?(?:\|(.*)年建\|)*?(\d+室.*?)\|(.*)平米\|(.*)',s)
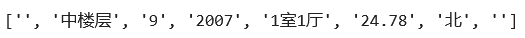
我在操作的时候用的是注释掉的正则表达式部分,后来在交流群里询问大佬明神后知道了**?
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)