Elasticsearch实战-复杂数据结构及映射 Mapping操作
1.ElasticSearch 映射操作
基于文章 Elasticsearch实战(一)—安装及基本语法使用 前面的文章,我们已经基本使用了ES,但是我们对于底层知识还是不了解的,现在我们讲一下 底层结构
1.1 结构
| MYSQL |
Elasticsearch |
| 数据库DB |
索引 Index |
| 表table |
类型type _doc |
| 行 记录 record |
文档 Documents |
| 列 字段column |
字段 Fields |
逻辑设计:索引一篇文档时,通过顺序找到它:索引 -> 类型 -> 文档ID
1.2 映射
映射可以分为动态映射和显式映射
- 动态映射 (dynamic mapping)
在关系数据库中,需要事先创建数据库,然后在该数据库实例下创建数据表,然后才能在该数据表中插入数据。而 ElasticSearch中 不需要事先定义映射(Mapping),文档写入 ElasticSearch 时,会根据文档字段自动识别类型,这种机制称之为动态映射, 像我们前几篇文章中 直接操作 put /test/-doc/1 插入数据就是 动态映射,并没有提前建立映射,根据自动插入的内容去映射信息
# 插入数据
PUT /jzj/_doc/1
{
"name":"jzj",
"age":10,
"address":"湖北省武汉市"
}
查看映射
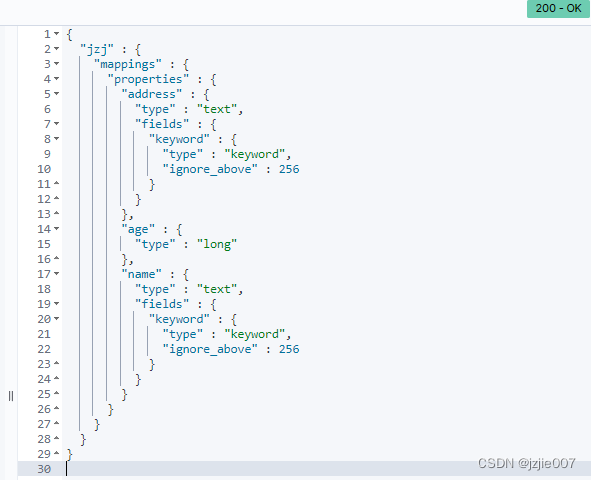
GET /jzj/_mapping
可以看到 address:type:text 类型文本, age:type:long 整数, name:type:text 文本
除 text 外其他类型不会进行分词 , 所以其他类型必须要进行精确查询
1.3 映射-显式映射
映射可以分为动态映射和显式映射
- 显式映射(explicit mappings)
在 ElasticSearch 中也可以事先定义好映射,包含文档的各个字段及其类型等,这种方式称之为显式映射。显示映射适用于事先直到结构,然后部分字段要定义使用其它分词器、是否分词、是否存储等
# 新建索引
PUT /jzjshow
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings" : {
"properties" : {
"address" : {
"type" : "text",
"analyzer": "standard",
"search_analyzer": "standard"
},
"addtime" : {
"type" : "date"
},
"age" : {
"type" : "long"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
新建显式索引
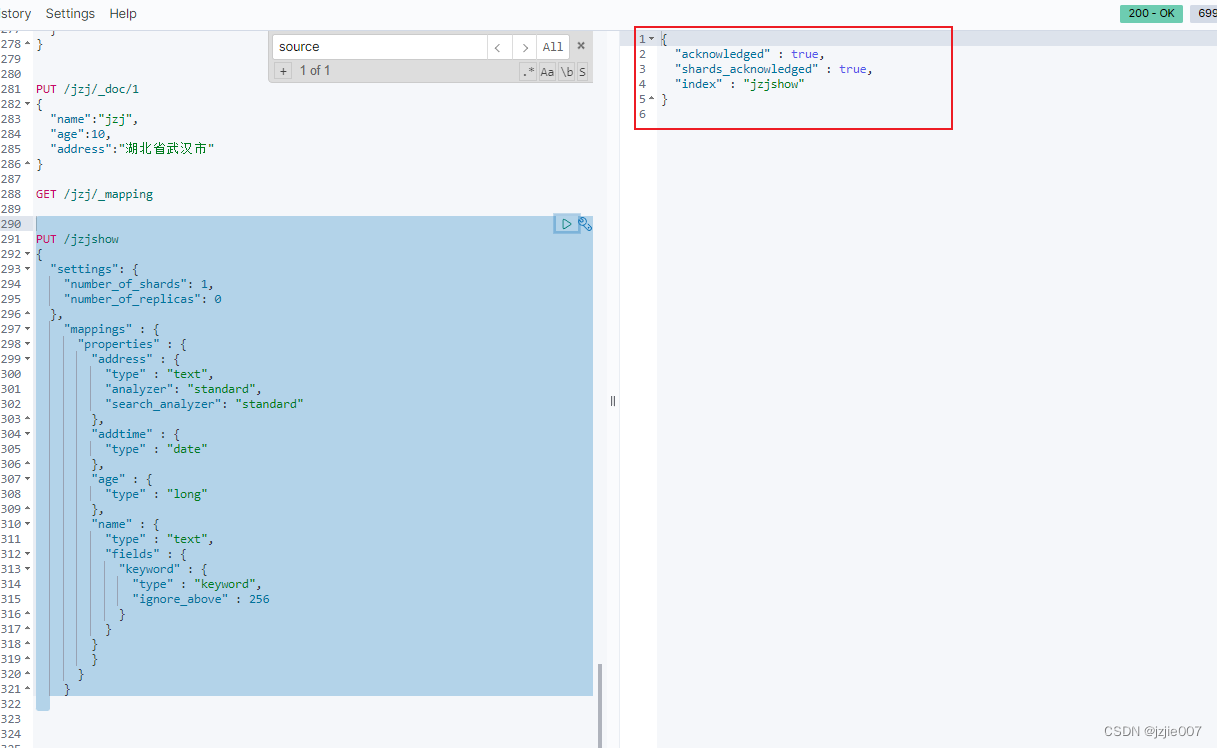
然后 插入数据
PUT /jzjshow/_doc/1
{
"address":"湖北省武汉市",
"addtime": "2022-05-01",
"age":20,
"name":"测试人员"
}
查询结果
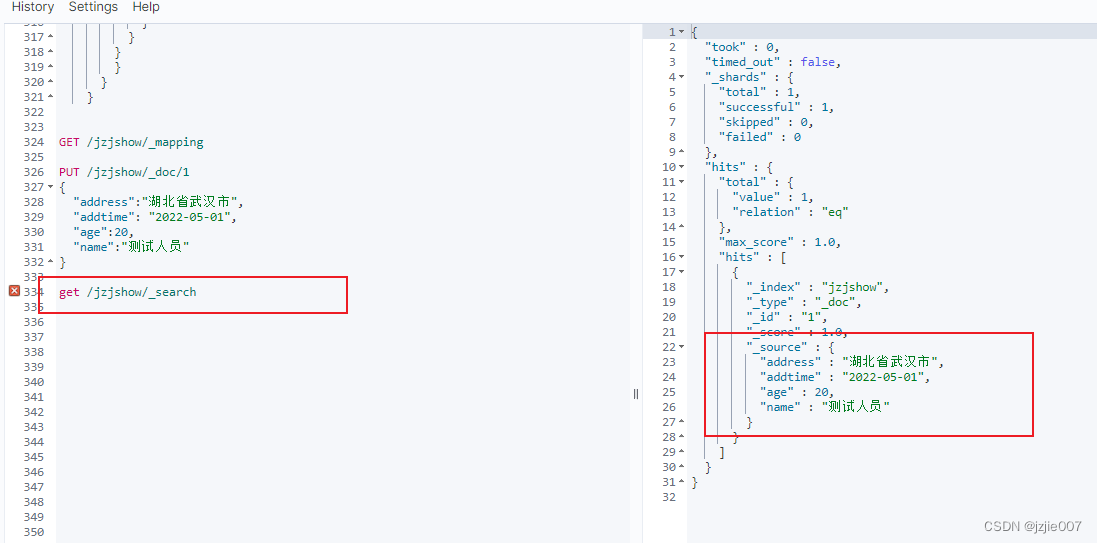
2.ElasticSearch 数据类型
2.1 基本数据类型
-
字符串:text 。
text:当一个字段是要被全文搜索的,比如 Email 内容、产品描述,应该使用 text 类型。设置 text 类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。text 类型的字段不能排序,很少用于聚合
-
字符串:keyword
keyword:该类型不需要进行分词,可以被用来检索过滤、排序和聚合,keyword 类型的字段只能通过精确匹配
-
整数:byte, short, integer, long
-
浮点数:float, double
-
布尔:boolean
-
日期:date,JSON 本身并没有日期数据类型
ES 中的日期类型可以是: 2015-01-01 or 2015/01/01 12:10:30 的字符串
long 类型的毫秒级别的时间戳
int 类型的秒级别的时间戳
-
二进制型:`binary``,二进制类型以 Base64 编码方式接收一个二进制值,二进制类型字段默认不存储,也不可搜索。
简单操作 插入 日期,boolean,整数 类型的字段, 依次插入四条数据
PUT /jzjshow/_doc/1
{
"address":"湖北省武汉市",
"addtime": "2022-05-01",
"age":20,
"name":"测试人员"
}
PUT /jzjshow/_doc/2
{
"address":"湖北省武汉市",
"addtime": "2021-04-14T21:16:42.000Z",
"age":20,
"name":"测试人员"
}
PUT /jzjshow/_doc/3
{
"address":"湖北省武汉市",
"addtime": "2021-04-14",
"age":20,
"name":"测试人员"
}
PUT /jzjshow/_doc/4
{
"address":"湖北省武汉市",
"addtime": "1654413037",
"age":20,
"name":"测试人员"
}
PUT /jzjshow/_doc/4
{
"address":"湖北省武汉市",
"addtime": "1654413037000",
"age":20,
"name":"测试人员"
}
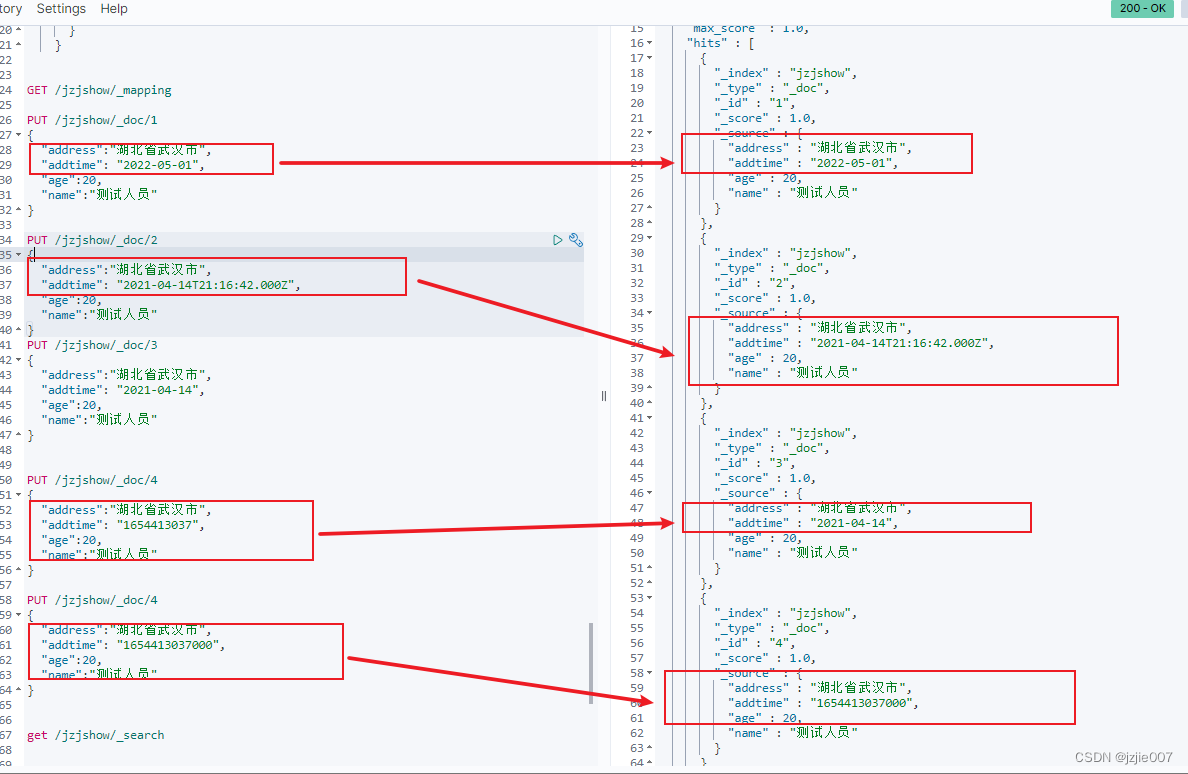
可以看到查询结果, 数据成功插入, 查询结果如下
第一条 yyyy-mm-dd, 数据存储也是 yyyy-mm-dd
第二条 UTC时间 , 数据存储也是 UTC时间
第三条 是Integer 时间戳 秒, 数据存储转换成了 yyyy-mm-dd
第四条是 Long 毫秒, 数据存储依旧是 Long毫秒
2.2 复杂数据类型 - 数组
在 ElasticSearch 中,没有专门的数组(Array)数据类型, 不需要进行任何配置,就可以直接使用。
在默认情况下,任意一个字段都可以包含 0 或多个值,这意味着每个字段默认都是数组类型,只不过,数组类型的各个元素值的数据类型必须相同:
- 字符串数组: [ “one”, “two” ]
- 整型数组: [ 1, 2 ]
- 数组数组: [ 1, [ 2, 3 ]] which is the equivalent of [ 1, 2, 3 ]
- 对象数组: [ { “name”: “Mary”, “age”: 12 }, { “name”: “John”, “age”: 10 }]
注意:
动态添加数据时,数组的第一个值的类型决定整个数组的类型
混合数组类型是不支持的,比如:[1,”abc”]
数组可以包含 null 值,空数组 [ ] 会被当做 missing field 对待
数组存储结构会被扁平化处理
put /jzjarr/_doc/1
{
"title":"人员列表"
,
"person":[
{
"name":"joy",
"age":20,
"address":"湖北省"
},
{
"name":"zhangsan",
"age":40,
"address":"河北省"
},
{
"name":"lisi",
"age":30,
"address":"河南省"
}
]
}
对于ES来说 会把数组扁平化处理成 , 查询的时候 对于array数组内部的元素就要用 person.name来处理
title:[“人”,“员”,“列“,”表”]
person.name:["joy", "zhangsan", "lisi"]
peson.age:[20,40,30]
person.address:[“湖北省”,“河北省”,“河南省”]
这样的数据, 就会导致 {“name”:“joy”, “age”:20, “address”:“湖北省” } 没了关联性
比如要查询 age=20 且 address=“河南省” 的信息 , 期望是查不到的,因为 person中不包含这样的信息
get /jzjarr/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"person.age": "20"
}
},
{
"match": {
"person.address": "河南省"
}
}
]
}
}
}
查询结果, 出现了不匹配的情况, 明明是查询 age=20 且 address=河南省, 没有这种记录,但是搜到了其他的记录 
这种问题 后面用 复杂结构Nested来处理 即可
2.3 复杂数据类型 -对象Object
JSON 文档是有层次结构的,一个文档可能包含其他文档,如果一个文档包含其他文档,那么该文档值是对象类型,其数据类型是对象,ES 默认把文档的属性 type设置为 object,即 “type”:“object”。
比如我现在有个嵌套文档 say 下面有三种语言, 可以看到 name 及 say 字段都是嵌套的 Json对象,say下面还有子对象 {chinese:你好 }, 如果没有明确给出 type类型,默认类型就是 type:Object对象类型
# 插入数据
put /jzjsay/_doc/1
{
"name":{
"first":"joy",
"last":"boy"
},
"age":20,
"say":{
"chinese":"你好",
"english":"hello",
"japan":"hai"
}
}
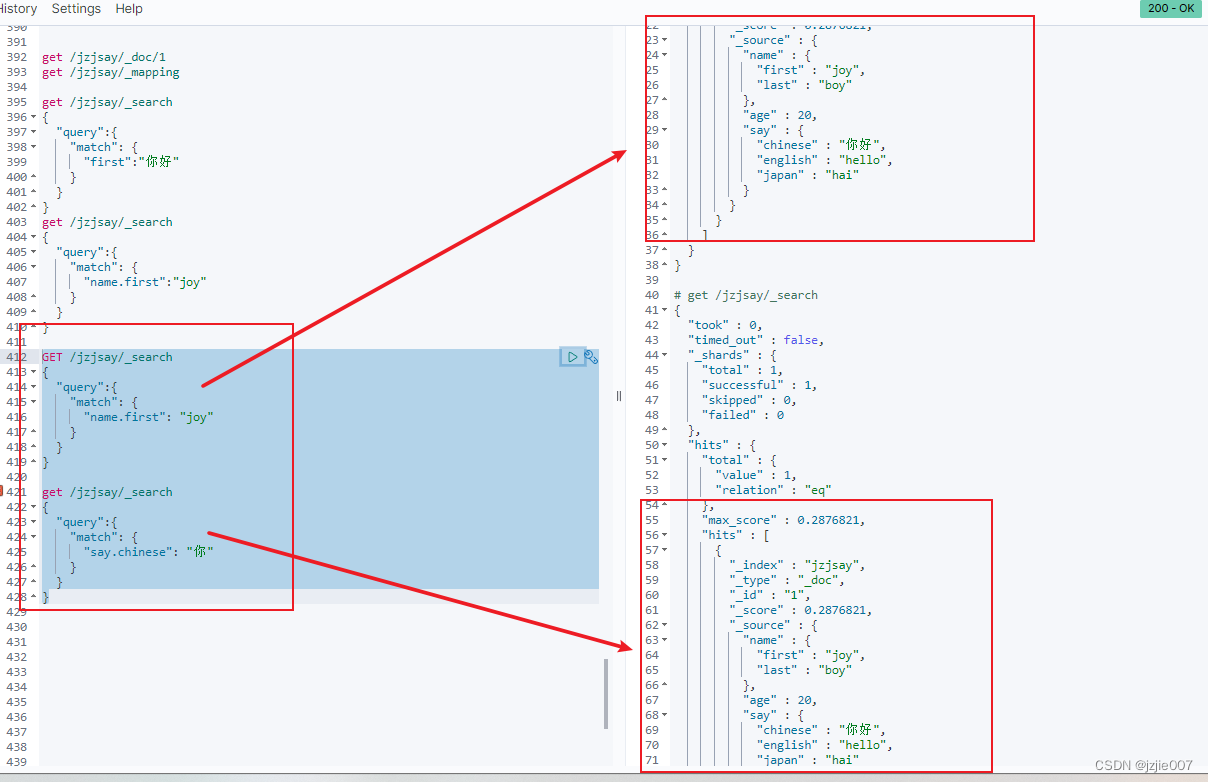
对于Object对象 我们要如何进行查询?
通过对象类型Object来存储二级文档,因为 Lucene 并没有内部对象的概念,ES 会将原 JSON 文档扁平化
上面的对象类型,ES在索引时将其转换为"name.first", “say.chinese” 这样扁平的key,用这样的扁平key作为域来进行查询
如果采用 name 或者 first 单独查询是无法查询的

必须使用 扁平化索引 eg name.first 或者 say.chinese 来实现
#扁平化索引 name.first
GET /jzjsay/_search
{
"query":{
"match": {
"name.first": "joy"
}
}
}
#扁平化索引 say.chinese
get /jzjsay/_search
{
"query":{
"match": {
"say.chinese": "你"
}
}
}
2.4 Object 对象类型 存在的问题
我们上面看了Object 存储这样的结构,看似没问题,可以通过索引去查询出来想要的结构 因为 底层是扁平化存储的数据
- name.first, name.last
- say.chinese, say.english, say.japan
但是我们看 下下面的场景, 先插入1 条比较复杂的数据
有一个 张三的同学, 三个人给了他评论
评论人 one, age=20 ,评价 good job
评论人 two, age=30, 评价 bad job
评论人 three,age=40, 评价 normal job
put /jzjcomment/_doc/1
{
"name":"张三",
"tags":["优秀", "好"],
"comments":[
{
"name":"one",
"age":20,
"say":"good job"
},
{
"name":"two",
"age":30,
"say":"bad job"
}
,
{
"name":"three",
"age":40,
"say":"normal job"
}
]
}
我现在想 查询 评价人是 one 的, 且 One的 年龄是30岁的 记录信息
按道理说是 找不到的, 因为 第一个评价人 One的年龄是 20, 查询语句应该查不到,我们试一下
# 查询 评价人年龄是30岁 且 评价人名字是 one的 那条记录
# bool 过滤, must And操作 "comments.age": 30 且 "comments.name": "one"
GET /jzjcomment/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"comments.age": 30
}
},
{
"match": {
"comments.name": "one"
}
}
]
}
}
}
查询结果, 出现一条,明明 评价人 One的年龄是20 岁, 我的 must And操作是 姓名=one 且 年龄是30岁, 为什么能把这条记录查出来?
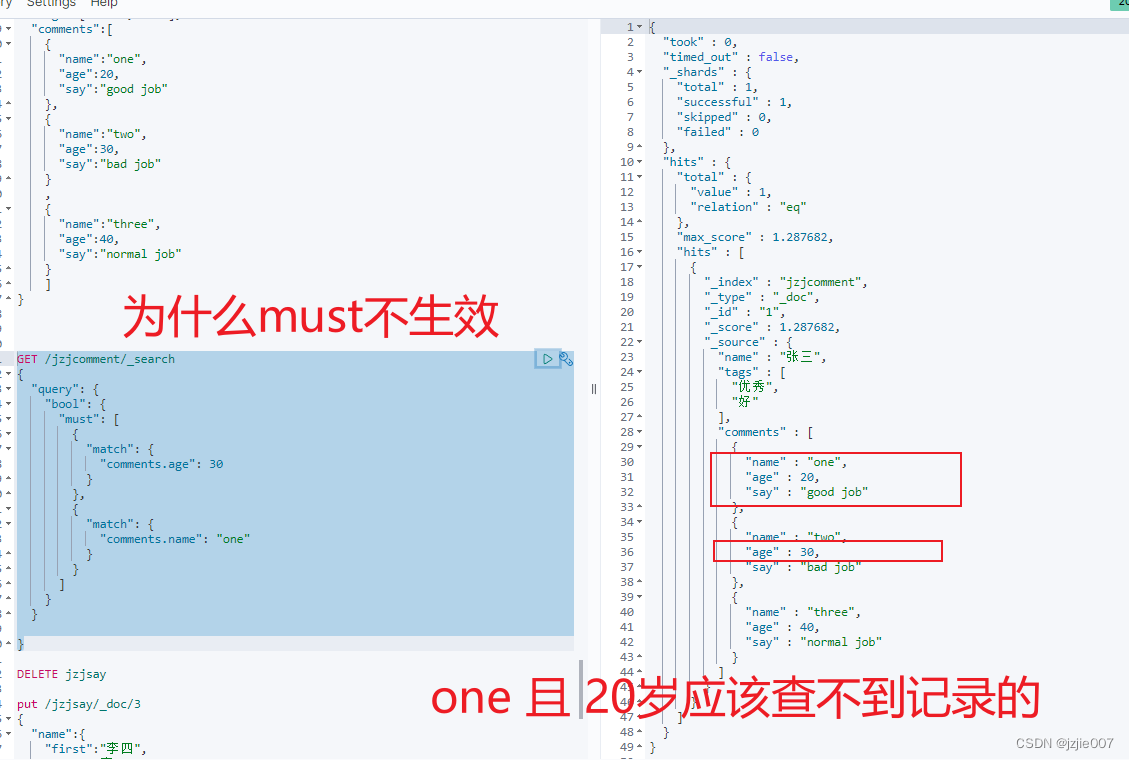
因为Object 存储结构的问题
Object结构 的 JSON 文档在 Lucene 底层会被打平成一个简单的键值格式,就像这样:
{
“name”: [“张”, “三”],
“tags”: [“优秀”, “好”],
“comments.name”: [“one”,“two”,“three”],
“comments.age”: [20, 30,40],
“comments.say”: [“good job”, “bad job”, “normal job”]
}
这样 底层查询就是 one in comments.name , age=30 in commemts.age 已经没有顺序性了,没有了 one 打了 20分, 评语是 goodjob 这一条记录的关联性丢失了
所以 Object结构是有缺陷的,所以 才有了Nested结构
2.5 复杂结构类型 -Nested
针对上面的 记录 Nested 是如何存储的?每一个 comments 都是一个单独的Document来处理, 如下
{
“name”: [“张”, “三”],
“tags”: [“优秀”, “好”],
{
“comments.name”: [“one”],
“comments.age”: [20],
“comments.say”: [“good” ,“job”]
},
{
“comments.name”: [“two”],
“comments.age”: [30],
“comments.say”: [“bad” ,“job”]
},
{
“comments.name”: [“three”],
“comments.age”: [40],
“comments.say”: [“normal” ,“job”]
}
}
在查询的时候将根文档 和 nested 文档拼接是很快的。
这些额外的 nested objects 文档是隐藏的,为了更新、增加或者移除一个 nested 对象,必须重新插入整个文档。
查询请求返回的结果不仅仅包括 nested 对象,而是整个文档
重新插入 Nested结构的文档
# 插入 Nested结构的文档 comments type:nested
put /jzjcommentnested
{
"mappings" : {
"properties" : {
"comments" : {
"type":"nested",
"properties" : {
"age" : {
"type" : "long"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"say" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"tags" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
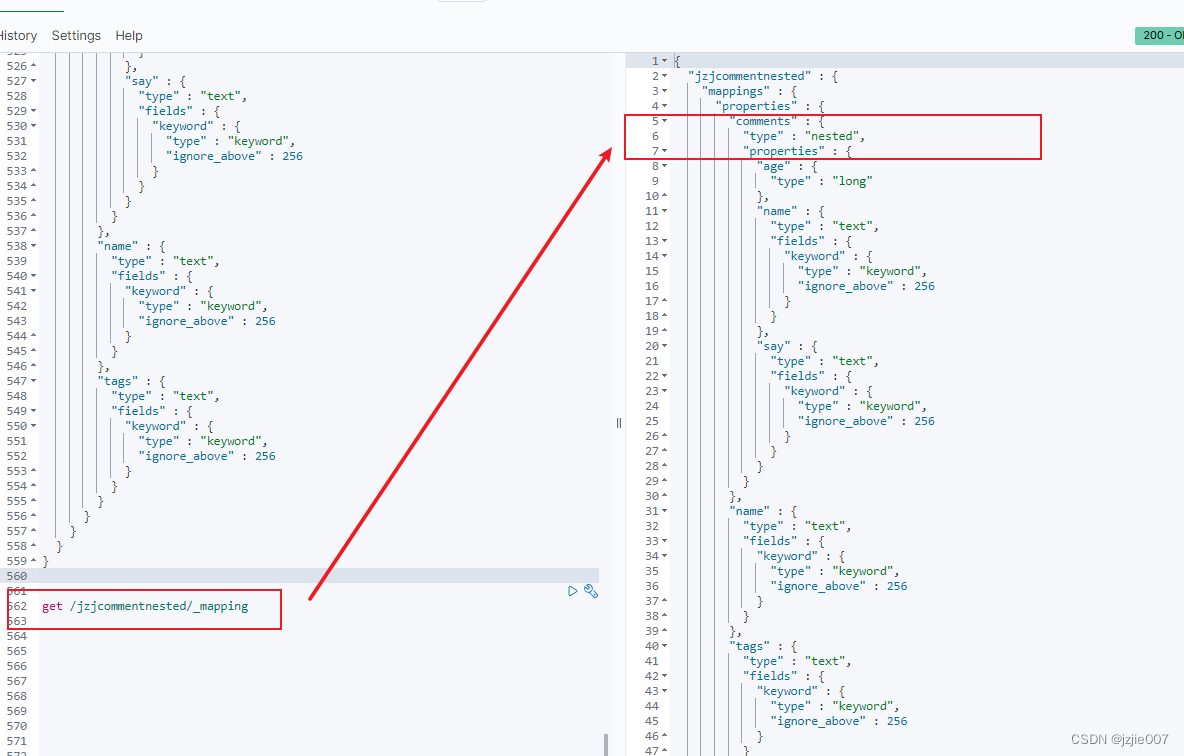
查看一下 mapping 映射结构
get /jzjcommentnested/_mapping
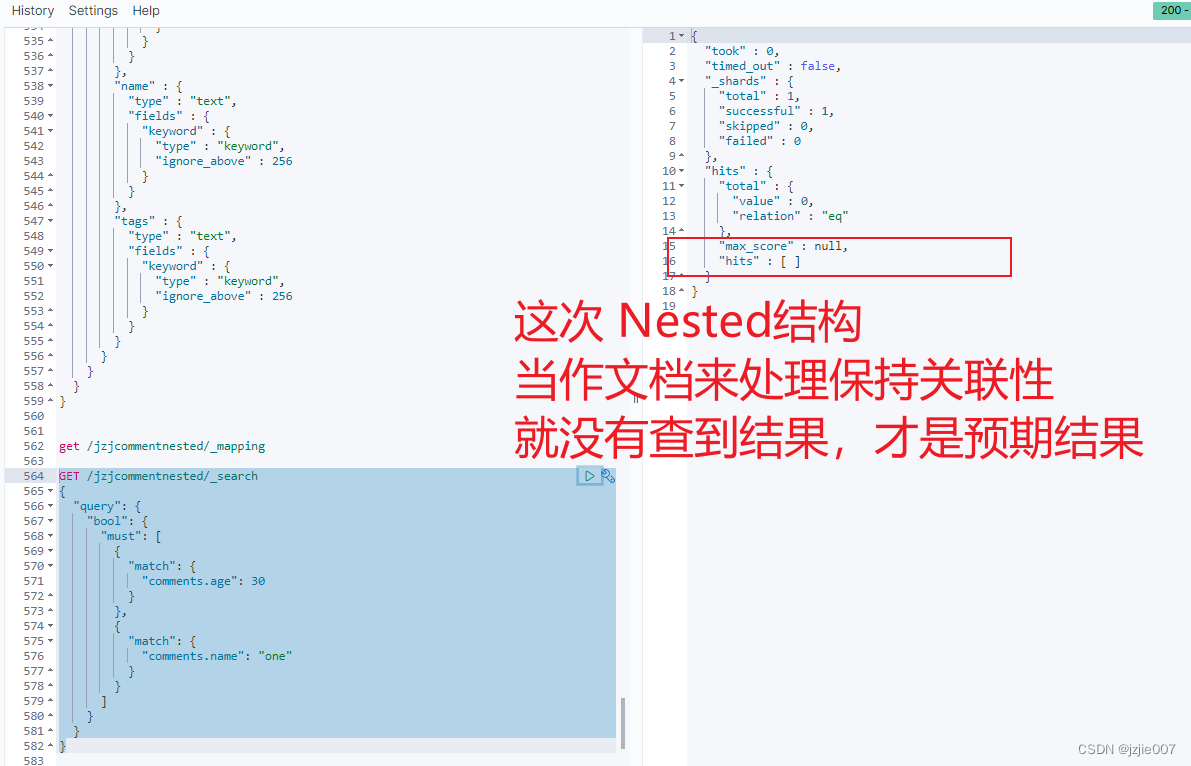
再用刚才的 查询语句 查一下, 查询 评论人 one 且 年龄是30 岁 的 记录
# 查询 评价人年龄是30岁 且 评价人名字是 one的 那条记录
# bool 过滤, must And操作 "comments.age": 30 且 "comments.name": "one"
GET /jzjcommentnested/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"comments.age": 30
}
},
{
"match": {
"comments.name": "one"
}
}
]
}
}
}
同样的语句, 不一样的结果, 查不到 评论人 one 且年龄是30岁 的记录, 这才是我们预期结果
2.6 Nested 类型搜索 nested:{path:“”}
nested 作为一个独立隐藏文档单独建索引,因此,我们不能直接查询它们。所以 我们必须使用 nested 查询或者 nested filter 来获取 整个文档信息
对于刚才结构 jzjcommentnested, 再插入3条数据
put /jzjcommentnested/_doc/1
{
"name":"张三",
"tags":["优秀", "好"],
"comments":[
{
"name":"one",
"age":20,
"say":"good job"
},
{
"name":"two",
"age":30,
"say":"bad job"
}
,
{
"name":"three",
"age":40,
"say":"normal job"
}
]
}
put /jzjcommentnested/_doc/2
{
"name":"李四",
"tags":["完美", "好"],
"comments":[
{
"name":"one",
"age":20,
"say":"bad job"
},
{
"name":"two",
"age":30,
"say":"bad job"
}
,
{
"name":"three",
"age":40,
"say":"good job"
}
]
}
put /jzjcommentnested/_doc/3
{
"name":"王五",
"tags":["一般", "良好"],
"comments":[
{
"name":"one",
"age":60,
"say":"normal job"
},
{
"name":"two",
"age":30,
"say":"bad job"
}
,
{
"name":"three",
"age":40,
"say":"good job"
}
]
}
查询结果 3条
get /jzjcommentnested/_search
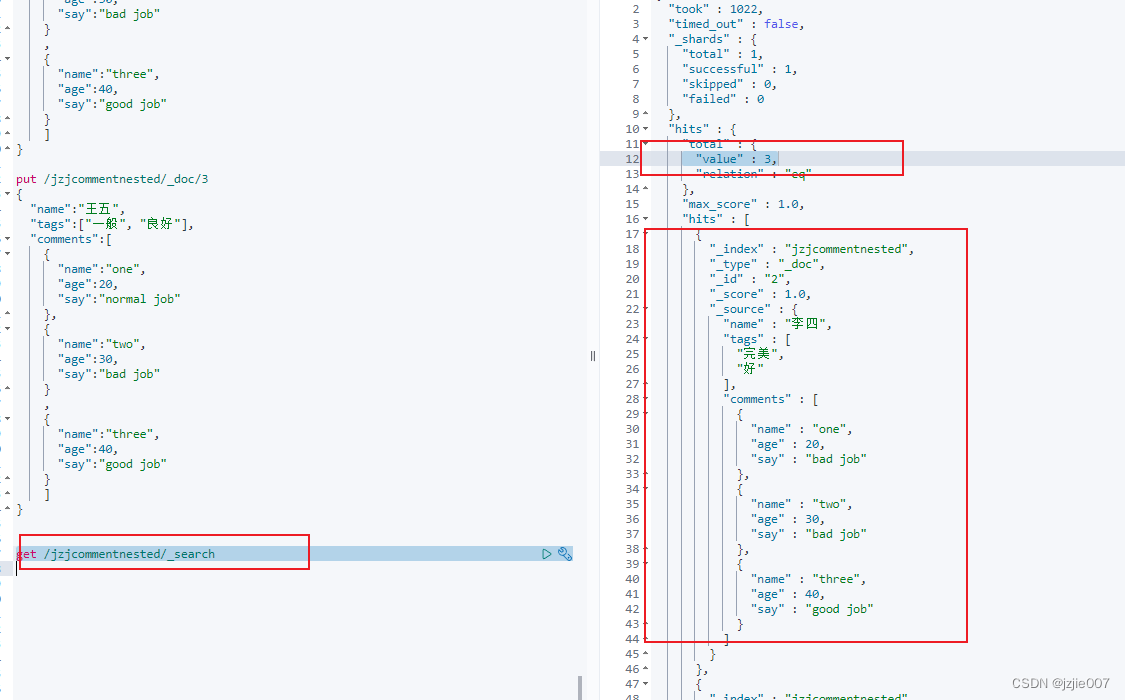
如何用Nested 来进行查询? 需要指定 path
# 原来的方式 是查不到 隐藏文档的 错误的查询方式
get /jzjcommentnested/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"comments.age": 60
}
},
{
"match": {
"comments.name": "one"
}
}
]
}
}
}
必须使用 嵌套 Nested path 路径
# 查询 nested 嵌套 文档 comments 下面的 age 及 name信息
get /jzjcommentnested/_search
{
"query":{
"bool": {
"must": [
{
"nested": {
"path": "comments",
"query": {
"bool": {
"must": [
{
"match": {
"comments.age": "20"
}
},
{
"match": {
"comments.name": "one"
}
}
]
}
}
}
}
]
}
}
}
查询结果 也是正确的, 把嵌套的nested文档 张三 和 李四 两条结果查询出来
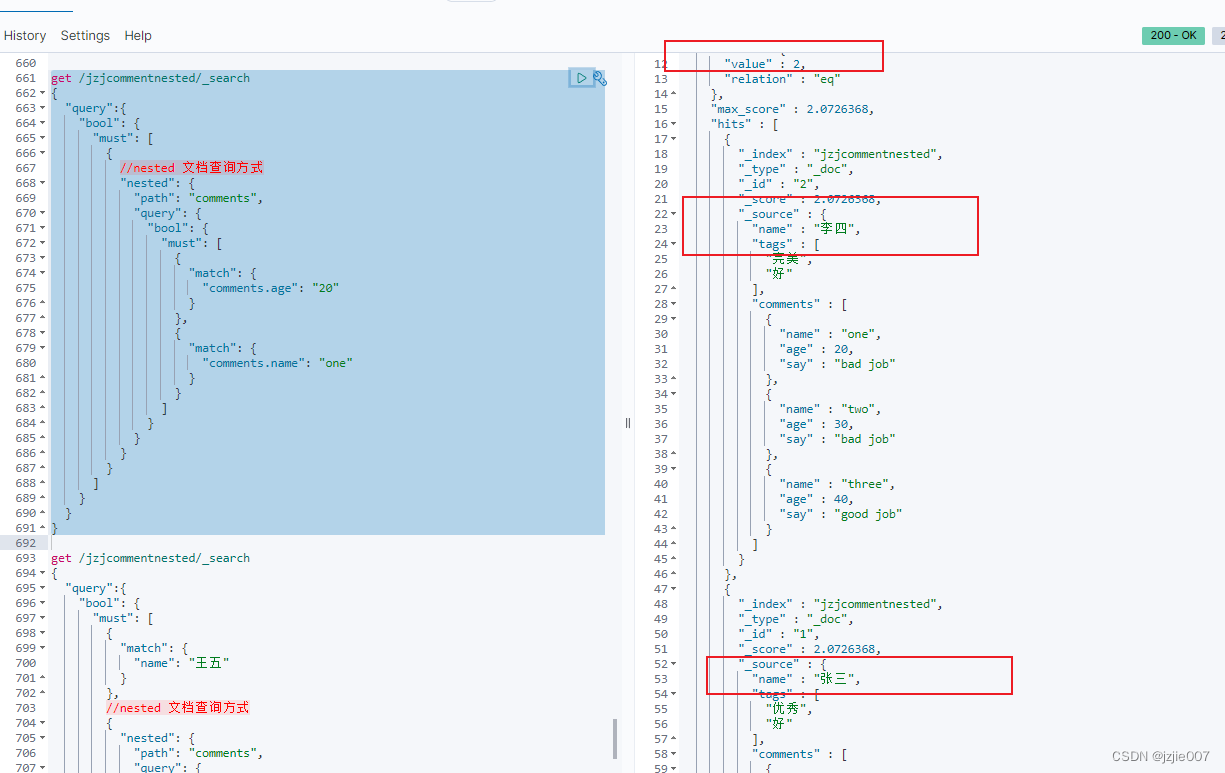
如果 需要关联 父 层的 结构 该如何查询, 比如 我要查 name=张三的 且 comments 内层 age=20, name = one的 记录
# 关联 父结构的 字段 name=张三
get /jzjcommentnested/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"name": "张三"
}
},
//nested 文档查询方式
{
"nested": {
"path": "comments",
"query": {
"bool": {
"must": [
{
"match": {
"comments.age": "20"
}
},
{
"match": {
"comments.name": "one"
}
}
]
}
}
}
}
]
}
}
}
查询结果 只有1条 张三这一条 且 匹配 嵌套 comments 内层 age=20, name = one的 记录
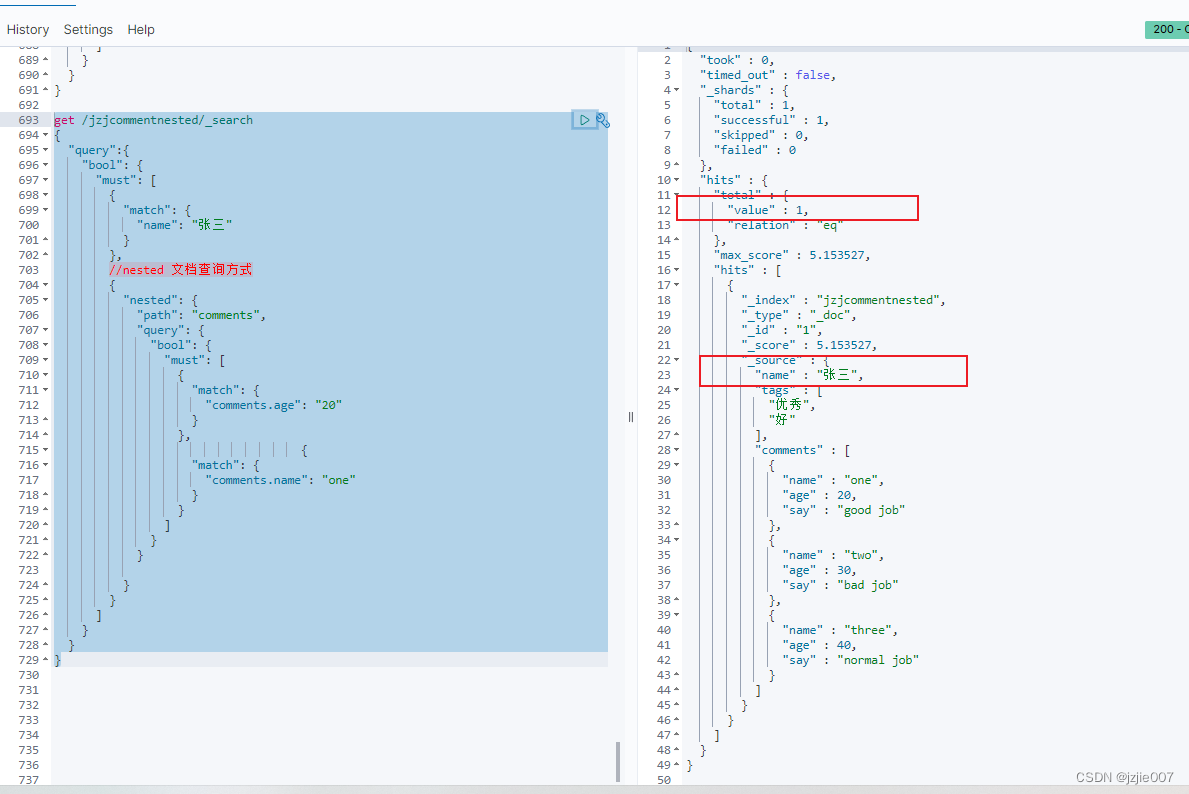
2.7 Nested 嵌套查询 sort排序
如果要基于Nested 中的文档排序,该如何实现? 我们看下官网的例子
先创建索引
"mappings" : {
"properties" : {
"body" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"comments" : {
"properties" : {
"age" : {
"type" : "long"
},
"comment" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"date" : {
"type" : "date"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"stars" : {
"type" : "long"
}
}
},
"tags" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
然后 插入 文档 1, 文档 2
PUT /blog/_doc/1
{
"title":"Nest eggs",
"body":"Making your money work...",
"tags":[
"cash",
"shares"
],
"comments":[
{
"name":"John Smith",
"comment":"Great article",
"age":28,
"stars":4,
"date":"2014-09-01"
},
{
"name":"Alice White",
"comment":"More like this please",
"age":31,
"stars":5,
"date":"2014-10-22"
}
]
}
PUT /blog/_doc/2
{
"title":"Nest eggs2",
"body":"2Making your money work...",
"tags":[
"cash2",
"shares2"
],
"comments":[
{
"name":"John Smith2",
"comment":"Great article",
"age":28,
"stars":3,
"date":"2014-09-01"
},
{
"name":"Alice White2",
"comment":"More like this please",
"age":31,
"stars":2,
"date":"2014-10-22"
}
]
}
然后 执行 sort语句
GET /blog/_search
{
"query": {
"nested": {
"path": "comments",
"query": {
"range": {
"comments.date": {
"gte": "2014-10-01",
"lt": "2014-11-01"
}
}
}
}
},
"sort": {
"comments.stars": {
"order": "asc",
"mode": "min"
}
}
}
不管是 order asc 还是desc 都是这个顺序 这个让我疑问很大,不知道哪里出了问题
至此 我们复杂的结构已经介绍完毕, 并且基本的查询也已经介绍完毕, 下一篇 ,我们介绍下Nested聚合的使用场景