
五、AlexNet
AlexNet 是 2012 年第 3届 ILSVRC(ImageNet Large Scale Visual Recognition Comprtition)图像分类任务中的冠军模型,伴随着比赛的成功,这篇发表在 NIPS(Neural Information Processing Systems) 上的论文1截止目前已有超过 4.5 万次引用量,是学习深度学习尤其是 CNN 网络架构中必读的论文之一。AlexNet 以 15.3% 的误差率大差距碾压亚冠团队,由此开启了 CNN 在图像分类任务中的霸主地位。下图 1 是前 6 名的误识别率排名,第一名为 SuperVision 团队,即 AlexNet 模型。
 【图 1】
【图 1】
5.1 ReLU 激活函数
在这之前,神经网络通常使用
t
a
n
h
tanh
tanh 激活函数或者
S
i
g
m
o
i
d
Sigmoid
Sigmoid 激活函数,从本质上讲,
t
a
n
h
tanh
tanh 与
S
i
g
m
o
i
d
Sigmoid
Sigmoid 都是 “S” 型激活函数,在反向传播计算过程中都难免达到饱和状态,导致严重的梯度消失问题。据此,这里引入可一种称之为修正线性单元的激活函数,即 ReLU(Rectified Linear Units),其表达式为
f
(
x
)
=
max
(
0
,
x
)
f(x)=\max(0, x)
f(x)=max(0,x),三者的函数曲线图及导数曲线图如下图所示:
 【图 2】
【图 2】
 【图 3】
【图 3】
由于 ReLU 激活函数本身并不是可微分函数,为了计算便利,我们强制性定义在 0 处的微分值为 0。根据图 2,我们可以看到,当激活值趋近于 1,
t
a
n
h
tanh
tanh 和
s
i
g
m
o
i
d
sigmoid
sigmoid 函数的导数值迅速趋于平缓接近于 0,而 ReLU 的导数却随着激活值的增大而增大,这很大程度上缓解了梯度消失的问题,也加速了网络的训练速度。图 3 展示了一个四层卷积网络在 CIFAR-10 数据集上同样当训练误差达到 25% 时,ReLU 激活函数比
t
a
n
h
tanh
tanh 激活函数快了 6 倍。(然而,在该数据集上实测发现
t
a
n
h
tanh
tanh 与 ReLU 效果相差不大,甚至
t
a
n
h
tanh
tanh 比 ReLU 略好,但总比均比
s
i
g
m
o
i
d
sigmoid
sigmoid 好很多。)
 【图 4】
【图 4】
5.2 局部响应正则化
 【图 5】
【图 5】
局部响应正则化(Local Response Normalization, LRN)是一种局部正则化技术,在 AlexNet 中,作者指出应用该技术可以在 top-1 和 top-5 误差率上分别降低 1.4% 和 1.2%。其理念来自于神经生物学中的侧抑制(lateral inhibitio)概念,侧抑制是指在某个神经元受到刺激而产生兴奋时,再刺激相近的神经元,则后者所发生的兴奋对前者产生的抑制作用。也就是说,侧抑制是指相邻的感受器之间能够互相抑制的现象。2而在 LRN 中,这种邻近神经元体现在不同通道的特征图上。具体的计算公式如下:
(1)
b
x
,
y
i
=
a
x
,
y
i
/
(
k
+
α
∑
j
=
max
(
0
,
i
−
n
/
2
)
min
(
N
−
1
,
i
+
n
/
2
)
(
a
x
,
j
j
)
2
)
β
b^i_{x,y}=a^i_{x, y}/\left(k+\alpha\sum^{\min (N-1, i+n/2)}_{j=\max(0,i-n/2)}(a^j_{x,j})^2\right)^{\beta} \tag{1}
bx,yi=ax,yi/⎝⎛k+αj=max(0,i−n/2)∑min(N−1,i+n/2)(ax,jj)2⎠⎞β(1)
其中
a
x
,
y
i
a^i_{x,y}
ax,yi 是第
i
i
i 个特征通道
x
,
y
x,y
x,y 位置的值,
b
x
,
y
i
b^i_{x,y}
bx,yi 是该通道经过 LRN 技术后的新值,
N
N
N 是指通道数,即卷积核的数量,
k
,
α
,
β
,
n
k, \alpha, \beta, n
k,α,β,n 均是超参数,
n
n
n 为深度半径,控制邻近神经元的抑制范围,
k
k
k 是为了防止除数为 0 添加的偏置项,
α
,
β
\alpha, \beta
α,β 控制彼此抑制程度。该计算的直观理解可参照图 4。
import tensorflow as tf
import numpy as np
import random
x = np.array([random.randint(1, 100) for _ in range(40)]).reshape([2,2,2,5])
y = tf.nn.local_response_normalization(
x,
depth_radius=5,
bias=2,
alpha=10e-4,
beta=0.75
)
with tf.Session() as sess:
print(x)
print(y.eval())
[[[[ 17 62 52 75 32]
[ 46 57 11 80 49]]
[[ 38 47 41 69 6]
[ 32 27 36 69 61]]]
[[[ 57 40 48 27 100]
[ 90 85 45 37 82]]
[[ 52 44 32 64 30]
[ 57 2 9 54 93]]]]
[[[[ 2.1776824 7.942136 6.661146 9.607422 4.099167 ]
[ 5.673838 7.030626 1.3567874 9.867545 6.0438714 ]]
[[ 5.846031 7.2306175 6.30756 10.615162 0.92305756]
[ 4.535786 3.8270695 5.1027594 9.780289 8.646342 ]]]
[[[ 6.0538244 4.2482977 5.0979576 2.867601 10.620745 ]
[ 7.5061765 7.0891666 3.7530882 3.0858727 6.838961 ]]
[[ 7.747794 6.5558257 4.7678733 9.535747 4.469881 ]
[ 6.8387866 0.23995742 1.0798084 6.4788504 11.15802 ]]]]
该技术在网络发展的后期使用较少,逐渐被 Batch Normalization(BN) 等其他技术取代。
5.3 数据增强
数据增强是一种很实用的通过增大数据集以缓解过拟合的低成本技术。数据增强主要通过一些诸如图片平移、镜像翻转、倾斜、扭曲以及裁剪、通道变化等手段对原始数据集进行扩张。
另外,作者还提出了中通过调整图片 RGB 各颜色通道的光照强度,近似模拟自然图像的一个重要特性,即光照的颜色和强度发生变化时,目标本身不变。
需要注意的是,数据增强只发生在训练阶段、验证集和测试集不需要数据增强。
import tensorflow as tf
from tensorflow.keras.preprocessing import image
import matplotlib.pyplot as plt
datagen = image.ImageDataGenerator(rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
img = image.load_img("demo.jpg")
x = image.img_to_array(img)
x = x.reshape((1,) + x.shape)
results = np.zeros((4*441+15, 4*700+15, 3), dtype=np.int32)
for i in range(4): # iterate over the rows of our results grid
for j in range(4): # iterate over the columns of our results grid
horizontal_start = i * 441 + i * 5
horizontal_end = horizontal_start + 441
vertical_start = j * 700 + j * 5
vertical_end = vertical_start + 700
results[horizontal_start: horizontal_end, vertical_start: vertical_end, :] = datagen.flow(x, batch_size=1)[0][0]
plt.figure(figsize=(20, 20))
plt.imshow(results)
 【图 6】
【图 6】
5.4 Dropout
Dropout 是另一种非常有效的降低过拟合风险的策略。作者 Geoffrey HInton 提到,他是受到了银行中防欺诈的启发而发明的3。
我去银行的时候经常发现柜员一直在换,我询问了这么做的原因,但却没人知道。后来我想明白了,如果想要成功地进行银行欺诈往往需要内部员工的配合,这使我意识到如果对每个样本随机丢弃一部分不同的神经元,这样就能阻止“阴谋”的发生,进而减少过拟合。
 【图 7】
【图 7】
Dropout 的核心思想就是在训练阶段,每一批量的训练样本上,网络都会以一定的概率随机丢弃一部分神经元,被丢弃的神经元实际输入与输出值均为 0,如上图所示。这样实际整个训练过程中,学习到了很多不同的网络架构,但是不同网络间的权重是共享的,这有点类似于组合机器学习策略。然而这样的策略并没有严谨的数学证明其理论的精准性,但是却是工程实践上很成功的策略。因此 Dropout 也有其较为直观的理解方式。通过 Dropout 随机丢弃部分神经元,可以打破神经元之间复杂的相互适应性,迫使每个神经元都去学习更加鲁棒的特征。如同在工作中,一项工作的进行不会因为某个人的请假、离职而中断,而是由替代者接替,这样可以迫使每个员工都可以学到更多的内容,也不会形成相互适应性,例如某些员工只负责某些事情,而某些员工即使消极怠工也不会影响正常工作。
假设网络以
p
=
0.5
p=0.5
p=0.5 的概率随机丢弃网络中神经元,在测试阶段,我们需要“组合”网络,即在测试阶段不使用 Dropout,然而直观上测试阶段不使用 Dropout 的网络规模是训练阶段使用 Dropout 网络规模的二倍,因此,在测试阶段网络的输出需要除以 2.
由于 Dropout 技术直观上可以打破神经元之间的弱连接关系,强迫神经元学习强连接,因此它不仅可以学到更鲁棒的特征,提高泛化能力,而且也提高了反向传播的计算效率,加快网络收敛速度。
5.5 网络整体架构
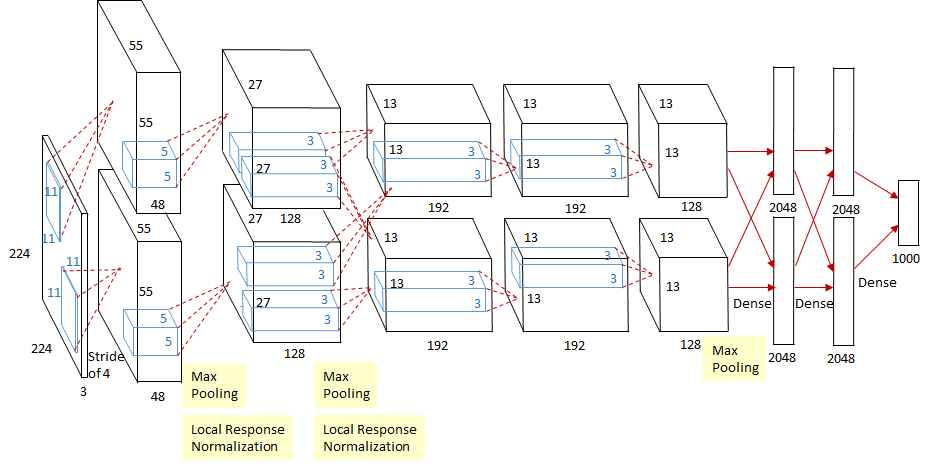 【图 7】
【图 7】
网络在训练过程中使用了 2 块 GPU,因此网络架构中中间部分出现了 2 个完全一致的分支,然而作者指出,之所以使用 2 块 GPU,主要是解决显存不足的问题,本质上并没有加速网络的训练速度(尽管快了一点)。
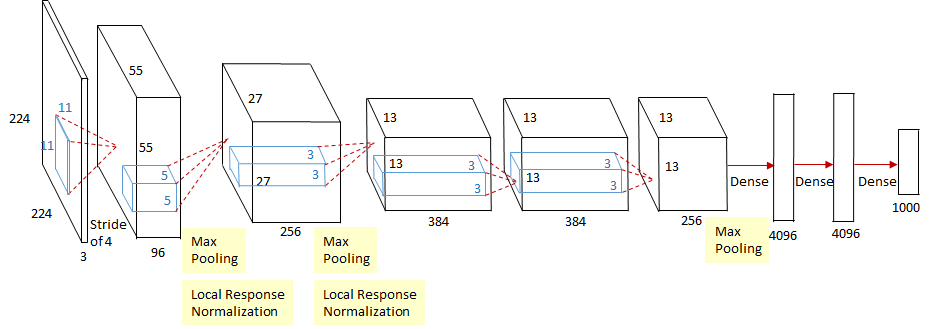 【图 8】
【图 8】
CaffeNet 是单 GPU 版的 AlexNet,具体网络架构如图 8 所示。
AlexNet 网络结构如下表所示:
| 模块 |
卷积层 |
池化、正则 |
| CONV1 |
[11×11 ~ 4 | 3→96] |
MAXPOOL[3×3 ~ 2]→LRN |
| CONV2 |
[5×5 ~ 1 | 96→256] |
MAXPOOL[3×3 ~ 2]→LRN |
| CONV3 |
[3×3 ~ 1 | 256→384] |
→LRN |
| CONV4 |
[3×3 ~ 1 | 384→384] |
→LRN |
| CONV5 |
[3×3 ~ 1 | 384→256] |
MAXPOOL[3×3 ~ 2]→LRN |
| FC1 |
[12544→4096] |
DROPOUT 50% |
| FC2 |
[4096→4096] |
DROPOUT 50% |
| Softmax |
[4096→1000] |
|
5.6 小结
AlexNet 的成功从真正意义上点燃了深度学习这把尘封已久的火炬,其技术实现上也取得非常大的突破。例如 ReLU 激活函数的成功运用,数据增强,Dropout 等降低过拟合风险的策略,如今这些技巧已成为深度学习中的标配组件。然而随着技术的进步,也有许多技术逐步被新技术取代或进一步改进,以寻求更强大的性能。
- GPU 加速,现在主流机器学习框架如 TensoFlow 等完全支持 GPU 以及 TPU 硬件加速,甚至支持多机多卡分布式训练策略,极大的加快网络训练速度;
- LRN 技术目前已基本被 BN 技术取代;
- 在本文中的池化原指重叠池化(Overlapping Pooling),目前一般采用常规 Max-Pooling。
- 在数据增强过程中,作者给出的第一种增强思路是从原图的四个角落及中心位置截取图片并通过水平翻转获得 10 张
224
×
224
224 \times 224
224×224 的子图,该图像的预测结果值为这 10 张子图的 softmax 输出层结果的平均值。而目前的数据增强是完全增强,作为独立图片使用。