AlexNet论文精读以及代码复现
三遍读一篇论文的方法——李沐
1.标题 ——>摘要——>结论——>关键的图表
2.从标题开始读到最后(太过于细节部分可以先放一下),搞清楚重要的图标的细节
3.第三遍要弄清楚每句话在干嘛,搞清楚细节,并且在读论文的过程中在脑中脑补整个实验过程,看看自己能不能复现
一、AlexNet论文精读
1.abstract
1)在ImageNet中取得了很好的成绩
2)用了五个卷积层,一些池化层,三个全连接层,还使用了1000路softmax激活函数
3)使用了GPU和不饱和神经元,并且发现这样使得训练更快
4)使用了Dropout来降低过拟合
摘要主要讲这篇论文做了什么(what)
2.Introduction
1)相比过去,使用了更大的数据集
2)CNN拥有更少的连接和参数,使得更容易训练
3)使用GPU训练CNN,并且ImageNet的数据集足够大,使得过拟合不会太严重
4)作者认为:<1>我们训练了目前为止最大的神经网络并且以足够大的优势赢得了比赛
<2>编写了高度优化的2D卷积神经网络及其内部固有的其他操作的GPU实现
<3>我们的网络包含许多不寻常的新特性,使得能够降低训练时间,并且使用了新技术来防止过拟合
<3>我们使用了五个卷积层,三个全连接层,并且深度是非常重要的,移走一层卷积层,那么性能表现就会下降。
5)我们(GPU)硬件受限
Introduction大概讲的是做了什么(what)
3.The dataset
1)除了裁剪图像,没有做任何的预处理,使用原始的RGB值来训练网络
怎么做,对数据集做了什么处理(how)
4.The Architecture
1)ReLu Nonlinearity
<1>使用非饱和非线性的ReLU,比标准方式tanh,sigmoid更快
讲为什么使用ReLU,ReLU好在哪里(why,how),并且用Figure 1给出了使用ReLU达到25%的训练错误率的速度是tanh的六倍
2)Training on Multiple GPUs
<1>将模型放在两块GPU上进行训练,比使用单GPU上训练使得top-1,top-5的错误降低了1.7%,1.2%
<2>由于可以跨GPU并行,无需通过主存,因此在每个GPU上放一半的神经元
<3>在某些层的输入只能来自相同的GPU
讲了做了什么(what),好在哪里,怎么做的(how),并且给出了使用两块GPU更好的结果验证
3)Local Response Normalization(局部响应标准化)
<1>局部响应标准化有助于泛化
讲了怎样归一化并且归一化有什么好处(how)
4)Overlapping pooling(重叠池化)
<1>采用重叠池化,使得更不容易过拟合(步长要小于池化单元的大小)
讲了采用重叠池化的好处,并且如何取值(how)
5)Overall Architecture
<1>第2,4,5层的卷积层内核仅连接到位于同一GPU的上一层内核映射
<2>第三层的卷积层连接到第二层的所有内核映射
<3>全连接层连接到上一层的所有神经元
<4>响应归一化(LRN)跟在第一和第二卷积层之后
<5>ReLU应用于所有的卷积层和全连接层之后
<1>第一层卷积层使用了11 x3 x3,步长为4的96个核(过滤器)来过滤224 x224x 3的输入图像
<2>第二层使用5x 5x 48的256个内核过滤第一层的输出
<3>3,4,5层直接相连,没有任何池化层和归一层
<4>第三层有3x3x256的384个内核连接到被归一化,池化的第二层的输出
<5>第四层有3x3x192,384个卷积核,第五层3x3x192的256个卷积核,全连接层共4096个神经元
介绍了神经网络的结构
5.Reduce overfitting(两种对抗过拟合的方式)
1)Data Augmentation
<1>第一种数据增强的方式是生成图像转换和水平翻转
从256x256的图片中随机提取224x224的图片(包含翻转了的),使得训练规模增大了2048倍,测试时从四个角和中间提取5张224X224的图片以及翻转后的图片共10张
改变训练图像中RGB通道的强度,对ImageNet训练集的RGN像素值集合使用PCA主成分分析法,将添加多个找到的主成分到每张训练图片
<2>dropout
在每轮前馈,反馈传播中,每层神经炎有一定比例失活,50%几率降低过拟合
讲做了什么,怎么做,有什么效果,为什么这么做来对抗过拟合
6.Detials of learning
1)优化器为SGD,batch_size为128,momentun为0.9,weight decay为0.0005,使用均值为0,标准差为0.01的高斯分布来初始化多层权重,用常量1来初始化2,4,5层和全连接层的偏置,用常量0来初始化其它层的偏置
2)每层的学习率相同并在训练中手动调整,学习率lr初始化为0.01,验证集错误率不随当前学习率而变化时,将学习率除以10,并且在训练停止前减少三次
3)120万张图像训练了90轮
7.Result
用两张图表表明在比赛中的成果,总的来说就是AlexNet这个模型比别的模型好,并且体现了各种改变模型结构后对最后结果的影响。
1)Qualitative Evaluation
<1>GPU1上学到的是与颜色无关的特征,GPU2上学到特征与颜色相关,且这种情况与任何特定的随机权重无关
(最后一个隐藏层中生成的特征向量是具有最小的欧氏距离的特征向量,若产生最小的欧氏距离分离的特征激活向量,则高层神经网络认为它们相似,训练编码器将向量压缩为二进制编码来提高计算欧式距离的效率。)*
8.Discussion
模型的深度很重要,希望能在video上用很大,很深的CNN,因为时间序列中有很重要的信息
二、代码实现
目标:尽量将整个流程清晰简明的表达出来,并且对细节处进行标注
整个代码实现分为四个板块,分别是:
(1)构建网络模型(net.py)
(2)将数据集分类为训练集验证集和测试集(data_split.py)
(3)训练(train.py) (4)测试(test.py)
在这之前要在网上下载了猫狗数据集,每一个类别大概一万四千张图片
一、构建神经网络(net.py)
import torch
import torchvision.transforms as transforms
import torch.utils.data
import matplotlib.pyplot as plt
import os
from PIL import Image
import torch.nn.functional as f
from torchvision.datasets import ImageFolder
import torch.optim as optim
import torch.nn as nn
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
EPOCH = 30
BATCH_SIZE = 256
class MyAlexNet(nn.Module):
#原双GPU 此处构建模型按照单GPU构造
def __init__(self): #num_classes指的只有两个类别
super(MyAlexNet,self).__init__()
self.features = nn.Sequential(
#第一层
nn.Conv2d(3,48,kernel_size=11,stride=4,padding=2), #input[3,65,65],output[48,55,55]
nn.ReLU(),
nn.MaxPool2d(2),
#第二层
nn.Conv2d(48,128,kernel_size=5,padding=2,stride=1), #output[128,27,27]
nn.ReLU(),
nn.MaxPool2d(2), # output[128,13,13]
#第三层
nn.Conv2d(128,192,kernel_size=3,padding=1,stride=1), #output[192,13,13]
nn.ReLU(),
#第四层
nn.Conv2d(192,192,kernel_size=3,padding=1,stride=1), #output[192,13,13]
nn.ReLU(),
#第五层
nn.Conv2d(192,128,kernel_size=3,padding=1,stride=1), #output[128,13,13]
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2), #output[128,6,6]
)
#三层全连接层
self.classifer = nn.Sequential(
#在第一二层全连接层使用Dropout
nn.Linear(4608, 2048), #[128 * 6 * 6]
nn.Dropout(p=0.5),
nn.ReLU(),
nn.Linear(2048,2048),
nn.Dropout(p=0.5),
nn.ReLU(),
nn.Linear(2048,1000),
nn.Linear(1000,2)
)
def forward(self,x):
x = self.features(x)
x = torch.flatten(x,start_dim=1)
x = self.classifer(x)
return x
总结: 构建神经网络按照论文中的图像对照构造就可以,在最开始令我疑惑的是最后一层卷积层到第一层全连接层的4608是如何来的,后面发现最快的方法是运行后看报错:RuntimeError: mat1 and mat2 shapes cannot be multiplied (32x4608 and 460x2048),说明我们应该把460改为4608。
二、将数据集分开为验证集训练集测试集(split_data.py)
import os
import random
from shutil import copy
def mkfile(file):
if not os.path.exists(file):
os.makedirs(file)
#获取指定目录下的所有文件夹名
file_path = '/Users/ropha/code学习/AlexNet/data_name'
list_class = [cla for cla in os.listdir(file_path)] #listdir返回指定文件夹的‘文件名’
#list_class中根据listdir存储了文件名(Cat,Dog),如果不存在则添加AlexNet/train/Cat or Dog
mkfile('AlexNet/train')
for cla in list_class:
mkfile('AlexNet/train/'+ cla)
#同上,创建验证集val的文件夹及其子目录
mkfile('AlexNet/val')
for cla in list_class:
mkfile('AlexNet/val/'+cla)
#划分数据集验证集
split_rate = 0.2
for cla in list_class:
cla_path = file_path + '/' + cla + '/' #访问某一类别的子目录
images = os.listdir(cla_path) #images中存储每一张图片的名称
num = len(images)
eval_index = random.sample(images,k=int(num * split_rate)) #images列表中随机抽取k个图像名称
#eval_index中保存验证集val的图像名称
for index,image in enumerate(images):
# mac在访问图片时会访问到.DS_Store的隐藏文件导致报错,加如下语句
if image == ".DS_Store":
pass
elif image in eval_index:
image_path = cla_path + image
new_path = 'AlexNet/val/' + cla
copy(image_path,new_path)
else:
image_path = cla_path + image
new_path = 'AlexNet/train/' + cla
copy(image_path,new_path)
print("\r[{}] processing [{}/{}]".format(cla,index+1,num),end=" ")
print("\tProcessing Done!")
总结:这里我遇到的最大问题就是mac在访问图片时为访问到一个名叫 .DS_Store的隐藏文件夹导致报错,只需要在在开始访问图像的for循环后加上 if image == ".DS_Store": pass,则不会报错。
三、训练(train.py)
import torch
from torch import nn
from net import MyAlexNet
import numpy as np
from torch.optim import lr_scheduler
import os
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
ROOT_val = '/Users/ropha/code学习/AlexNet/train'
ROOT_test ='/Users/ropha/code学习/AlexNet/val'
#将图像的像素值归一化到[-1,1]之间
normalize = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
train_transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.RandomVerticalFlip(), #数据随机垂直旋转
transforms.ToTensor(),
normalize
])
val_transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
normalize
])
#从链接中加载数据集并接受转换后的图像
train_dataset = ImageFolder(ROOT_val,transform=train_transform)
val_dataset = ImageFolder(ROOT_test,transform=val_transform)
#对图像分组并打乱
train_dataloader = DataLoader(train_dataset,batch_size=32,shuffle=True)
val_dataloader = DataLoader(val_dataset,batch_size=32,shuffle=True)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = MyAlexNet().to(device)
#定义一个损失函数,优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(),lr=0.01,momentum=0.9)
#学习率每10轮变为原来的0.5
lr_scheduler = lr_scheduler.StepLR(optimizer,step_size=10,gamma=0.5)
#定义训练函数
def train(dataloader,model,loss_fn,optimizer):
model.train()
loss, current,n = 0.0,0.0,0
for batch,(x,y) in enumerate(dataloader): #x(图片数据),y(真实标签)
image, y = x.to(device), y.to(device)
output = model(image) #output为预测值
cur_loss = loss_fn(output,y)
_,pred = torch.max(output,1)
cur_acc = torch.sum(y == pred) / output.shape[0]
#反向传播
optimizer.zero_grad()
cur_loss.backward()
optimizer.step()
#计算每一批次的总损失值和准确率
loss = loss + cur_loss.item()
current = current + cur_acc.item()
n = n + 1
#每一批次的平均loss
train_loss = loss / n
train_acc = current/ n
print('train_loss: '+ str(train_loss))
print('train_acc : '+ str(train_acc))
return train_loss,train_acc
#定义验证函数
def val(dataloader,model,loss_fn):
model.eval()
loss, current,n = 0.0,0.0,0
with torch.no_grad():
for batch,(x,y) in enumerate(dataloader): #x(图片数据),y(真实标签)
image, y = x.to(device), y.to(device)
output = model(image) #output为预测值
cur_loss = loss_fn(output,y)
_,pred = torch.max(output,1)
cur_acc = torch.sum(y == pred) / output.shape[0]
loss = loss + cur_loss.item()
current = current + cur_acc.item()
n = n + 1
#每一批次的平均loss
val_loss = loss / n
val_acc = current/ n
print('val_loss: '+ str(val_loss))
print('val_acc : '+ str(val_acc))
return val_loss,val_acc
#定义画图函数
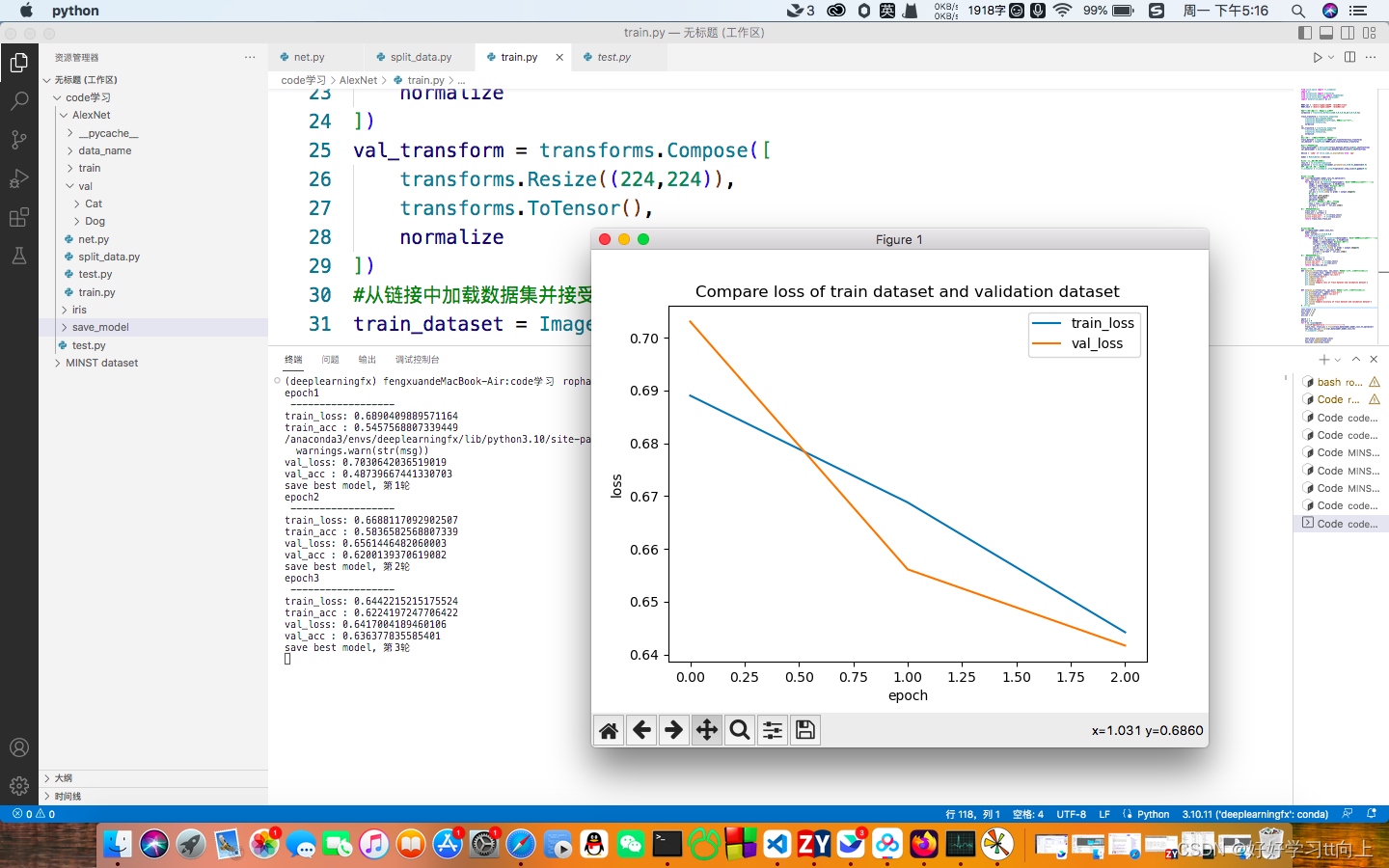
def matplot_loss(train_loss, val_loss): #判断训练集和验证集哪个效果好
plt.plot(train_loss, label='train_loss')
plt.plot(val_loss, label='val_loss')
plt.legend(loc='best')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.title('Compare loss of train dataset and validation dataset')
plt.show()
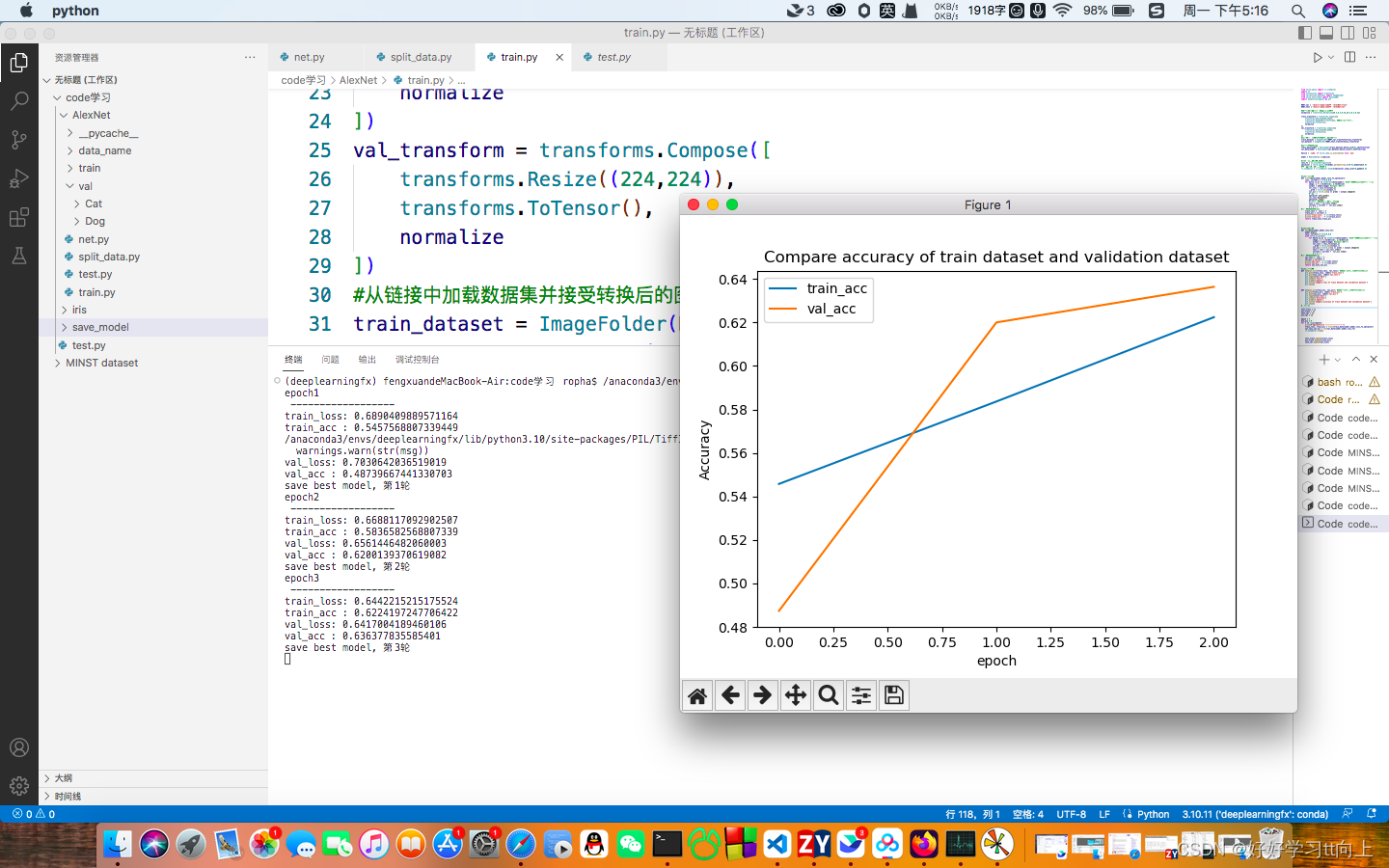
def matplot_acc(train_acc, val_acc): #判断训练集和验证集哪个效果好
plt.plot(train_acc, label='train_acc')
plt.plot(val_acc, label='val_acc')
plt.legend(loc='best')
plt.ylabel('Accuracy')
plt.xlabel('epoch')
plt.title('Compare accuracy of train dataset and validation dataset')
plt.show()
#开始训练
loss_train = []
acc_train = []
loss_val = []
acc_val = []
epoch = 3
min_acc = 0
for t in range(epoch):
print(f"epoch{t+1}\n ------------------")
train_loss, train_acc = train(train_dataloader,model,loss_fn,optimizer)
val_loss,val_acc = val(val_dataloader,model,loss_fn)
lr_scheduler.step()
loss_train.append(train_loss)
acc_train.append(train_acc)
loss_val.append(val_loss)
acc_val.append(val_acc) #画图准备
#保存最好的模型权重
if val_acc > min_acc:
folder = 'save_model'
if not os.path.exists(folder):
os.mkdir('save_model')
min_acc = val_acc
print(f"save best model, 第{t+1}轮")
torch.save(model.state_dict(),'save_model/best_model.pth') #state_dict()中保存了权重和偏置
#保存最后一轮的权重文件
if t == epoch-1:
torch.save(model.state_dict(),'save_model/last_model.pth')
matplot_loss(loss_train,loss_val)
matplot_acc(acc_train,acc_val)
print("---------Done!---------")
总结:这一部分是核心,包含归一化,分组,优化,训练,验证,对图片进行数据增强并且加载数据集,权重衰减,画图,保存最好模型等。需要注意的细节很多,需要逐行推敲。
四、测试(test.py)
import torch
from net import MyAlexNet
from torch.autograd import Variable
from torchvision import datasets,transforms
from torchvision.transforms import ToTensor
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision.transforms import ToPILImage
ROOT_val = '/Users/ropha/code学习/AlexNet/train'
ROOT_test ='/Users/ropha/code学习/AlexNet/val'
#将图像的像素值归一化到[-1,1]之间
normalize = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
# train_transform = transforms.Compose([
# transforms.Resize((224,224)),
# transforms.RandomVerticalFlip(), #数据随机垂直旋转
# transforms.ToTensor(),
# normalize
# ])
val_transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
normalize
])
#从链接中加载数据集并接受转换后的图像
# train_dataset = ImageFolder(ROOT_val,transform=train_transform)
val_dataset = ImageFolder(ROOT_test,transform=val_transform)
#对图像分组并打乱
# train_dataloader = DataLoader(train_dataset,batch_size=32,shuffle=True)
val_dataloader = DataLoader(val_dataset,batch_size=32,shuffle=True)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = MyAlexNet().to(device)
#加载模型
model.load_state_dict(torch.load("/Users/ropha/code学习/save_model/best_model.pth"))
#获取预测结果
classes = [
"cat",
"dog",
]
#把张量转化为照片格式,方便可视化
show = ToPILImage()
#进入验证阶段
model.eval()
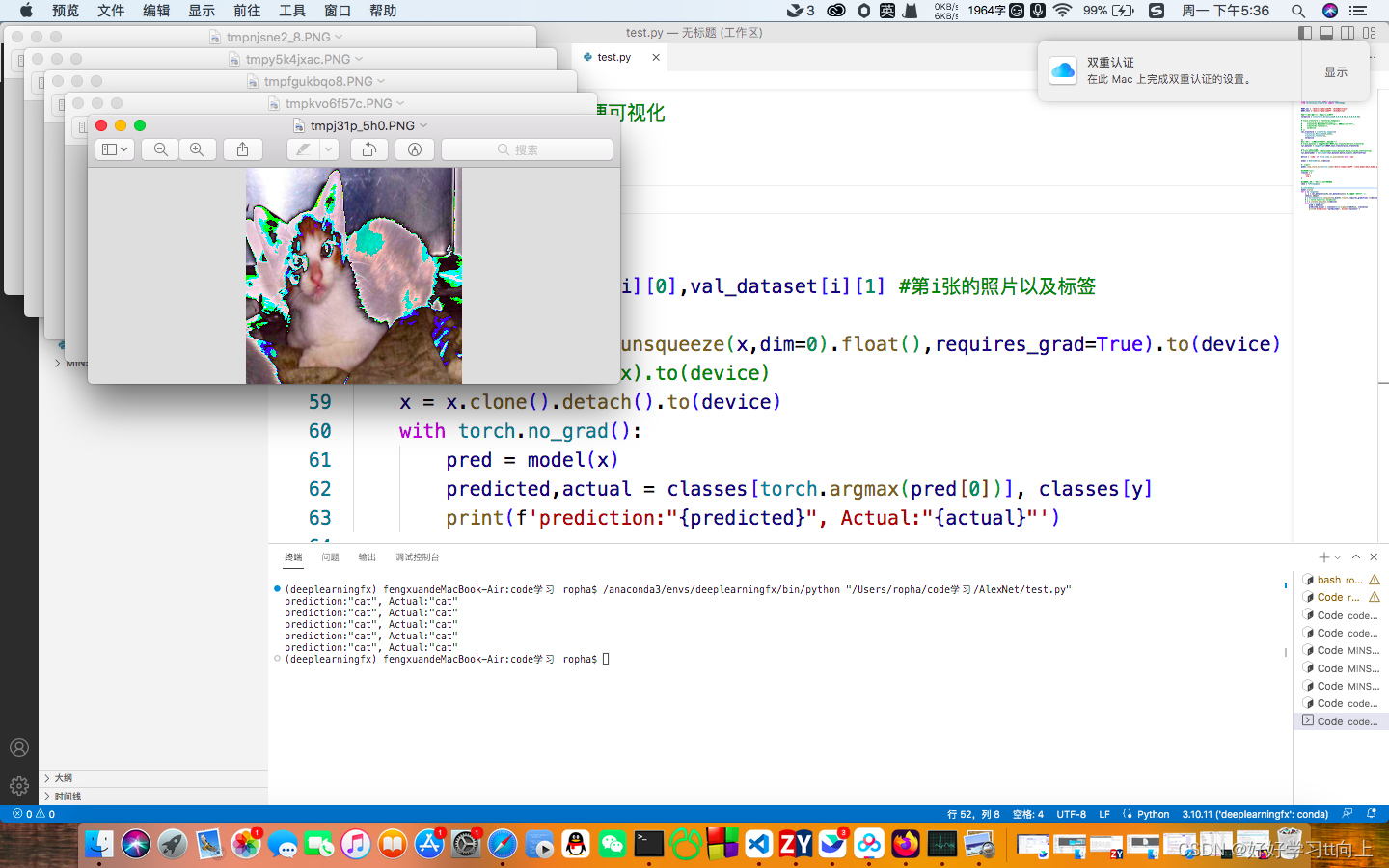
for i in range(5):
x, y = val_dataset[i][0],val_dataset[i][1] #第i张的照片以及标签
show(x).show()
x = Variable(torch.unsqueeze(x,dim=0).float(),requires_grad=True).to(device)
# x = torch.tensor(x).to(device)
x = x.clone().detach().to(device)
with torch.no_grad():
pred = model(x)
predicted,actual = classes[torch.argmax(pred[0])], classes[y]
print(f'prediction:"{predicted}", Actual:"{actual}"')

总结:测试阶段和验证阶段差不多,但是不再需要更新梯度权重等,测试阶段只需要拿出测试集真实图片标签与预测标签进行对比并输出。

由于设备限制,只训练了三轮(光这三轮就用了一个多小时。。。)
附上结果