在“你好,语义分割(一) ”中,我们介绍了语义分割的概念,数据的准备过程和模型设计,并且使用数据加载器对数据进行训练集,验证集和测试集的拆分。接下来,我们使用训练集对模型进行训练,用来学习理想的参数。
2.3. 训练(Train)
2.3.1. 学习准则(Criterion)
学习准则是模型学习效果的评估标准,对于有监督学习,给定模型推理结果和目标标签,学习准则通过计算损失值来得到一个梯度值,再通过反向传播(backward)执行梯度下降。学习准则把复杂的机器学习问题,转化成为一个机器善于处理的求解最优化问题。
常用的学习准则有Softmax, SVM , CrossEntropy。在语义分割等对象检测任务中,通常选择交叉熵损失函数作为其学习准则。
Pytorch提供的交叉熵损失函数接受两个输入参数:模型的打分结果和目标。打分是模型推理后的分数值,不能使用Softmax等函数转化后的概率值。目标可以是以下两种形式:
•标签值
目标的形状是打分结果的形状去除通道(C)维度之后的形状。比如对于(N, C, H, W)形状的打分结果, 标签值形式的的目标形状是(N, H, W),其中的数据是[0, C)范围内的标签值。
•概率值
目标的形状和打分结果的形状保持一致,其中的数据是[0, 1]范围的概率值。
在之前的数据处理中,由于标签数据使用了one-hot编码,在此处恰好可以匹配概率值形式的目标数据,可以直接作为学习准则的目标参数。
criterion = nn.CrossEntropyLoss()
…
# forward
score = model(input)
loss = criterion(score, target)
...
2.3.2. 优化(Optimizer)
优化是通过学习准则,优化模型参数,使得学习准则中的损失可以随着学习过程的进行而逐渐下降。常用的优化函数有SGD和Adam。代码中使用SGD作为优化函数,再配合动量来规避局部最优解。
在模型训练阶段,正向计算会计算计算图中标记requires_grad=true且is_leaf=true的张量的梯度值。之后在学习准则的backward方法中,通过反向传播,为计算图中的每一个标记requires_grad=true的张量计算梯度值。优化方法的optimizer.step方法则是根据学习率,动量值和节点的梯度值更新模型中的权重值。另外,在模型训练上,通常先使用一个较大的学习率,用以加快收敛速度,之后使用较小的学习率,在小范围内寻找最优值。为此我们使用了lr_scheduler,用以在训练过程中动态降低学习率。
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum)
scheduler = lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=gamma)
…
# forward
score = self.model(std_input)
loss = criterion(score, target)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
…
scheduler.step()
2.3.3. 模型训练
训练中的epoch和batch_size超参数
设计好的模型,需要通过模型训练学习合适的权重参数。一个完整的模型训练,通常需要经过多次epoch来完成。一个epoch代表训练集中的所有数据都参与了一次训练过程。epoch的大小,取决于模型在训练过程中的收敛速度。
数据集的batch_size,标识一次模型推理中,参与计算的数据的数量。在随机梯度下降过程中,这批数据也会一同计算梯度。batch_size最小为1, 最大为数据加载器中的数据大小。
太小的batch_size,会导致训练过程变得更长,而太大的batch_size,则会降低模型的泛化能力。
class Trainer(object):
def train(self, epochs=50, learning_rate=1e-3, momentum=0.7, step_size=5, gamma=0.5, verbose=True):
start_time = datetime.now()
logging.info(f'start training at {start_time}')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
optimizer = torch.optim.SGD(self.model.parameters(), lr=learning_rate, momentum=momentum)
scheduler = lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=gamma)
criterion = nn.CrossEntropyLoss()
self.model.to(device)
self.model.train()
for epoch in range(1, epochs + 1):
lr_current = optimizer.param_groups[0]['lr']
print(f'learning rate:{lr_current}')
for batch_index, data in enumerate(self.train_loader):
std_input = data[0].float()/255
if self.transform:
std_input = self.transform(std_input)
std_input = Variable(std_input.to(device))
target = data[1].float().to(device)
# forward
score = self.model(std_input)
loss = criterion(score, target)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
if verbose:
print(f'[train] epoch {epoch} / {epochs}: loss: {loss.item():.5f}')
...
scheduler.step()
end_time = datetime.now()
logging.info(f'end training at {end_time}. time elapse:{(end_time - start_time).seconds // 60 } min')
2.4. 验证(Validation)
使用验证数据来进行模型验证,可以用来规避模型的过拟合现象,也被用来辅助调整模型超参数。模型验证可以在模型进入评估前提前发现模型的问题并进行调整,是机器学习建模过程中非常重要的一个步骤。
当样本集规模较大时,用于验证的数据通常不在训练集中出现,当样本集合规模很小时,验证集数据也可以是训练集中出现过的数据。
2.4.1. 混淆矩阵(Confusion Matrix)
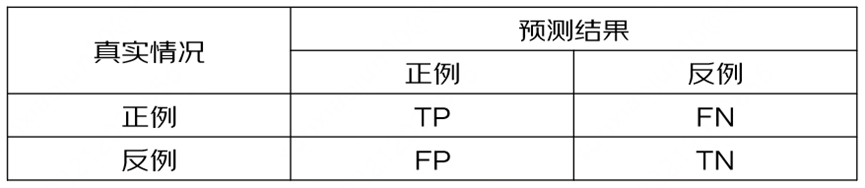
图7 二分类下的混淆矩阵
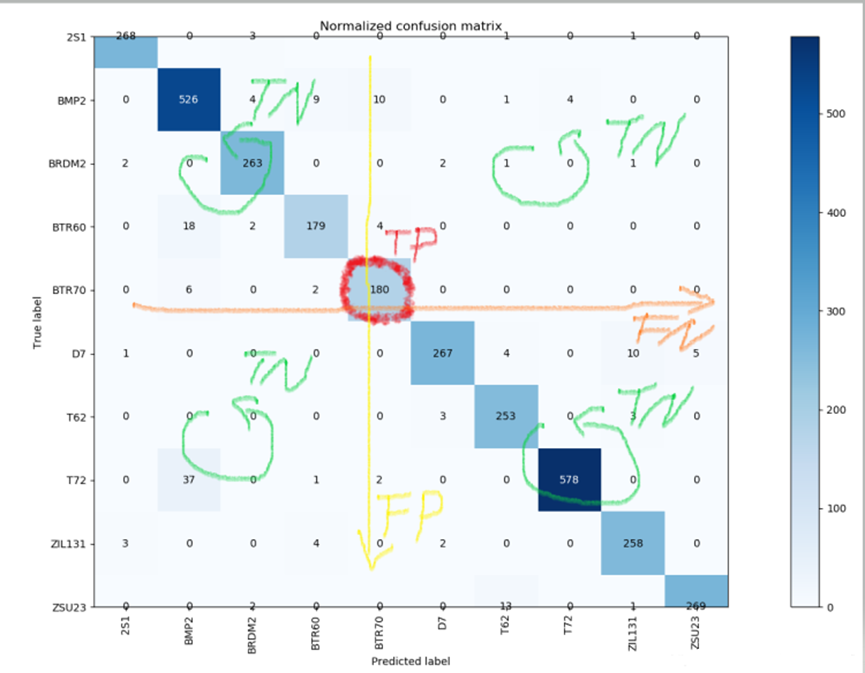
图8 多分类下的混淆矩阵
混淆矩阵(Confusion Matrix)是处理分类问题中非常常用的辅助工具,使用它可以计算诸如精确率,准确率,召回率,F值等一些列指标。混淆矩阵可以用于处理二分类问题,也可以用于处理多分类问题。
混淆矩阵根据真实值和预测值,将结果划分四个分类:
•TP(True Positive),称为真阳性。表示预测为真,且真实结果为真的数据。
•FP(False Positive),称为假阳性。表示预测为真,但真实结果为假的数据。
•FN(False Negative)称为假阴性。表示预测结果为假,但真实结果为真的数据。
•TN(Tue Negtive),称为真阴形。表示预测结果为假,且真实结果为假的数据。
@staticmethod
def confusion_matrix(target: Tensor, input: Tensor) -> Tensor:
if target.dim() != input.dim():
raise IOError('target and input must has same dimension')
if 3 == target.dim():
y_true = target.permute(1, 2, 0).flatten(0, 1)
y_pred = input.permute(1, 2, 0).flatten(0, 1)
elif 4 == target.dim():
y_true = target.permute(0, 2, 3, 1).flatten(0, 2)
y_pred = input.permute(0, 2, 3, 1).flatten(0, 2)
else:
raise IOError('target and input must be a 3D or 4D matrix')
cm = torch.zeros((y_true.shape[1], y_true.shape[1]))
for obs in range(0, len(y_pred[:, 0])):
j = y_pred[obs, :].argmax()
i = y_true[obs, :].argmax()
cm[i, j] += 1
return cm
2.4.2. 评价指标(Metrics)
评价指标,用来反馈结果是否理想。常见的指标有损失(Loss),精确率(Precision),召回率(Recall),F值(F1-score), 像素准确率(Pixel Accuracy), 平均准确率(Mean Accuracy), 平均IoU(Mean IoU)等。
基于混淆矩阵的常用的评价指标的计算方式如下:
准确率
Accuracy = (TN+ TP) / (TN + TP + FN + FP)
精确率
Precision = TP / (TP + FP)
召回率
Recall = TP / (TP + FN)
F值
F1-score = 2 * Precision * Recall / (Precision + Recall)
不同的评价指标,用于不同的业务场景需求。比如推荐系统,需要尽可能保障为用户推荐的商品的正确的商品,所以可以用精确率来衡量模型优劣。而如果业务场景是核酸检测,需要尽可能找到所有疑似的患者,那么使用召回率来衡量就更合理。
在目标检测和语义分割领域,常用的指标是mean IoU(Intersection over Union)。IoU又被称为Jaccard指数,用来衡量预测物体和实际物体重叠的比率。计算公式为:
IoU = TP / (TP + FP + FN) = I(X) / U(X)
代码中,需要使用混淆矩阵来计算多个分类的指标。代码使用pytorch的矢量化计算的方式,一次性计算了所有分类的指标。其中IoU的计算为混淆矩阵中所有行维度的张量和所有列维度的张量之和减去对角线中重复计算的部分,一次性计算所有分类的IoU指标。
acc = torch.diag(cm).sum().item() / torch.sum(cm).item()
iu = torch.diag(cm) / (cm.sum(dim=1) + cm.sum(dim=0) - torch.diag(cm))
2.4.3. 检查点与模型保存
•检查点(checkpoint)
对于一个复杂的深度学习网络,拟合模型通常需要大量的时间。在这个过程中,难免发生机器故障,导致训练失败。我们需要在非代码原因引起的训练失败后,能够从最近的训练中恢复,继续训练,而不是从新开始训练。这需要我们在训练过程中,使用检查点保存模型的参数,以便训练失败后,能够从最近的检查点开始恢复训练。
•模型保存
当训练集的指标满足需求,并且模型在验证集上指标表现良好时,我们需要保存模型。随着epoch的迭代,我们对比模型在验证集上的当前指标和上一次模型保存时的指标,如果指标上有所改善,那么可以覆盖之前保存的模型。最终我们得到一个在验证集上表现最出色的模型。
def save_checkpoint(self, epoch, acc):
torch.save(self.model.state_dict(), os.path.join(self.checkpoints_dir, f'fcn8s_ckpt_{epoch}.pth'))
logging.info(f'Checkpoint {epoch} saved!')
def resume_checkpoint(self, checkpoint_num):
saved_checkpoint = os.path.join(self.checkpoints_dir, f'fcn8s_ckpt_{epoch}.pth')
if not os.path.exists(saved_checkpoint):
return
checkpoint = torch.load(saved_checkpoint)
self.model.load_state_dict(checkpoint)
logging.info(f'Checkpoint {checkpoint_num} resumed!')
def save_model(self):
torch.save(self.model, os.path.join(self.save_dir, 'fcn8s.pth'))
print('model fcn8s saved!')
def load_model(self):
saved_model = os.path.join(self.save_dir, 'fcn8s.pth')
if not os.path.exists(saved_model):
return
self.model = torch.load(saved_model)
print('model fcn8s loaded!')
2.4.4. 混合训练与验证
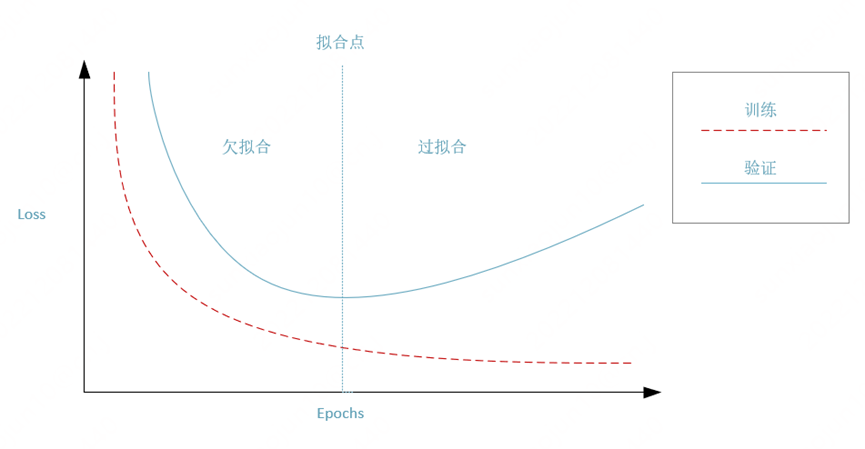
图9 混合训练与验证
模型验证和训练的不同点在于验证阶段不需要进行优化,没有反向传播,梯度下降等优化操作。模型验证的作用是用来评估训练的结果是否存在过拟合现象。
在每一个epoch完成后,我们对模型的训练结果进行验证,并完成一次检查点的保存。当验证当前模型参数拥有更好的泛化能力时,我们保存整个模型。混合训练与验证,就是在训练指标和验证指标中,找到合适的拟合点,避免发生过拟合或欠拟合现象。
def train(self, epochs=50, learning_rate=1e-3, momentum=0.7, step_size=5, gamma=0.5, verbose=True):
start_time = datetime.now()
logging.info(f'start training at {start_time}')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
optimizer = torch.optim.SGD(self.model.parameters(), lr=learning_rate, momentum=momentum)
scheduler = lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=gamma)
criterion = nn.CrossEntropyLoss()
self.model.to(device)
self.model.train()
for epoch in range(1, epochs + 1):
lr_current = optimizer.param_groups[0]['lr']
print(f'learning rate:{lr_current}')
for batch_index, data in enumerate(self.train_loader):
...
if epoch % self.checkpoint_interval == 0:
self.save_checkpoint(epoch)
val_loss, val_acc, mean_iou = self.validate()
logging.info(f'[validate] epoch {epoch} / {epochs}: loss: {val_loss:.5f}, accuracy:{val_acc:.5f}, mean IOU:{mean_iou:.5f}')
if val_acc > self.acc_thresholds and mean_iou > self.best_mean_iou:
self.save_model()
self.best_mean_iou = mean_iou
scheduler.step()
end_time = datetime.now()
logging.info(f'end training at {end_time}. time elapse:{(end_time - start_time).seconds // 60 } min')
2.5. 评估(Evaluate)
我们通过建模过程得到的表现良好的模型,不一定能够在真实的数据下还能够完美匹配。我们需要通过测试数据对模型进行评估,用以预演模型在真实数据下的预测解结果。
模型评估通常用来做最终的模型选定,在验证集上表现良好,却在测试集上评估效果不佳的模型,需要被淘汰掉,未能通过评估的模型,不能通过调整超参数进行再次评估。
注意无论样本集规模大小,用于评估模型的测试集中的数据,都不能出现在训练和验证数据中。
2.5.1. ROC曲线
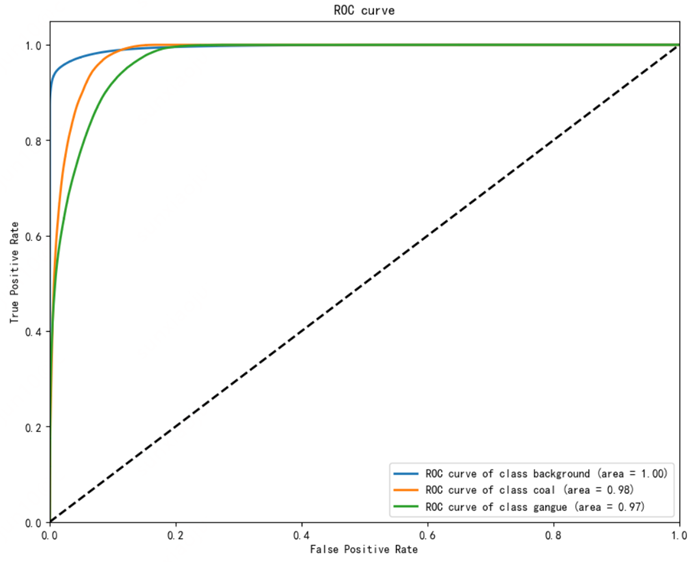
图10 ROC曲线
ROC(Receiver Operating Characteristic)曲线,称为受试者工作特征曲线,用于反馈敏感度和特性值之间的权衡和联系。在机器学习中,ROC指标的横坐标FPR(False Positive Rate),也称为误报率,是所有实际为假的样本中被错误地预测为阳性的比例。计算公式为:
FPR = FP / (FP + TN)
纵坐标TPR(True Positive Rate)也称为召回率,查全率。是所有实际为真的样本中,被正确地预测为阳性的比例。计算公式为:
TPR = TP / (TP + FN)
ROC曲线基于预测结果的打分或概率,选定若干个阈值,在不同阈值下的混淆矩阵,对应的TPR和FPR,即构成了一幅ROC曲线图。
ROC曲线和横坐标围成的部分的面积,称为AUC(Area Under Curve),取值介于0和1之间。ROC曲线的左下到右上的对角线是随机猜测线,AUC值越大,说明预测准确率越高,如果AUC取值小于0.5,说明模型预测的准确率低于随机猜测。
在多分类语义分割中,预测的结果y_pred只能使用概率,不能直接使用one_hot等编码后的结果,否则会由于计算某一分类时,没有参考其它分类的打分,导致ROC曲线与实际情况不符。
def draw_roc_auc(self, y_true: Tensor, y_pred: Tensor, title, x_label="False Positive Rate", y_label="True Positive Rate"):
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(self.n_classes):
y_true_np = y_true[:, i, :, :].reshape(-1).cpu().numpy()
y_pred_np = y_pred[:, i, :, :].reshape(-1).cpu().numpy()
fpr[i], tpr[i], _ = roc_curve(y_true_np, y_pred_np)
roc_auc[i] = auc(fpr[i], tpr[i])
for i, color in zip(range(self.n_classes), self.class_colors):
plt.plot(
fpr[i],
tpr[i],
lw=2,
label="ROC curve of class {0} (area = {1:0.2f})".format(self.class_names[i], roc_auc[i]),
)
plt.plot([0, 1], [0, 1], "k--", lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.title(title)
plt.legend(loc="lower right")
plt.show()
ROC曲线的局限性
如果分类业务中,真正例的价值不重要,或者样本不均衡,存在大量的负样本。那么按照ROC曲线的计算公式来看,此时AUC的值不能很好地反馈模型的业务价值。
2.5.2. PR曲线
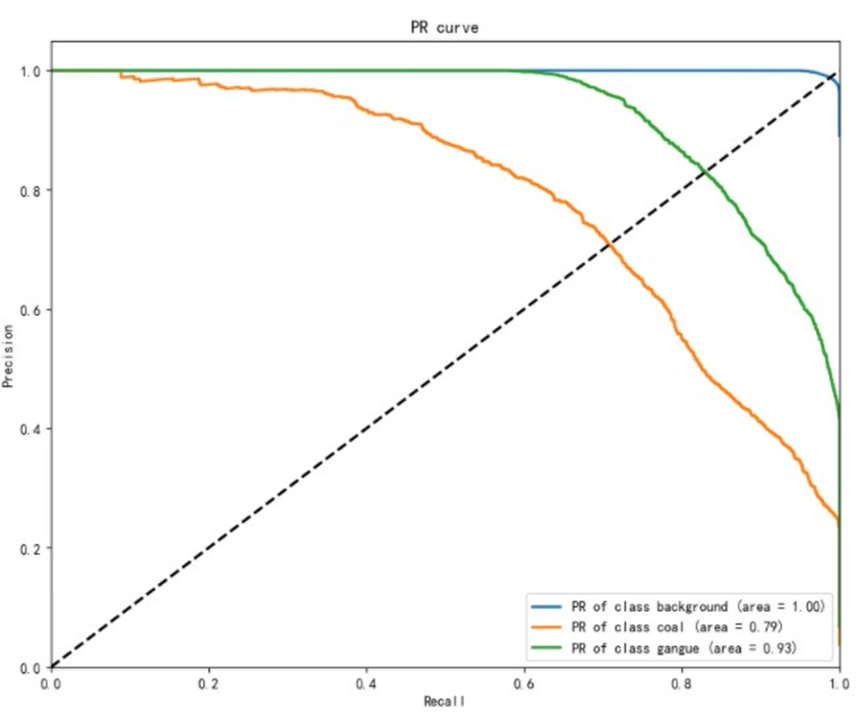
图11 PR曲线
PR(Precision Recall)曲线,是精确率(Precision)和召回率(Recall)两个指标的组合。其中横坐标是召回率(Recall),和ROC中的TPR的概念是一致的,表示真的样本中,预测为阳性的比例。纵坐标是精确率(Precision),也称为查准率。是所有预测为阳性的样本中,实际为真的比例。
PR曲线主要聚焦于正例,这解决了ROC曲线中同时兼顾整理和负例,导致的样本数据失衡时,曲线敏感度不足的问题。
在PR曲线中,曲线和对角线相交的点称为平衡点。平衡点的数值越大,说明分类的效果越好。
def draw_pr(self, y_true: Tensor, y_pred: Tensor, title, x_label="Recall", y_label="Precision"):
precision = dict()
recall = dict()
aps = dict()
for i in range(self.n_classes):
y_true_np = y_true[:, i, :, :].reshape(-1).cpu().numpy()
y_pred_np = y_pred[:, i, :, :].reshape(-1).cpu().numpy()
precision[i], recall[i], thresholds = precision_recall_curve(y_true_np, y_pred_np)
aps[i] = average_precision_score(y_true_np, y_pred_np)
for i, color in zip(range(self.n_classes), self.class_colors):
plt.plot(
recall[i],
precision[i],
lw=2,
label="PR of class {0} (area = {1:0.2f})".format(self.class_names[i], aps[i]),
)
plt.plot([0, 1], [0, 1], "k--", lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.title(title)
plt.legend(loc="lower right")
plt.show()
PR曲线的局限性
如果分类业务中,正例和反例的重要性相当,PR曲线中平衡点的值,由于无法兼顾模型对反例的预测结果,使得在PR曲线中,平衡点值不能很好地反馈模型的业务价值。
2.5.3. 绘制测试结果
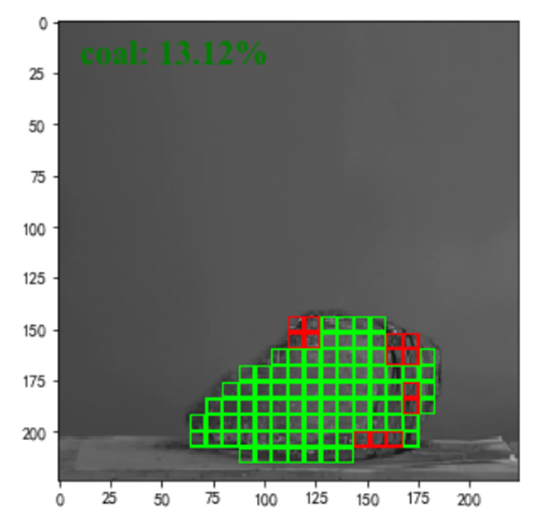
图12 可视化的测试结果
基于测试结果,我们可以根据测试结果在原图或者标签图的基础上做二次处理,用以反馈预测结果在原图上的效果。这里我们使用网格的方式,在原图之上标注分类的网格区域,并标注了预测的矿石中煤的成分所占的比重。
def draw_overlay_grid(self, img: Tensor, overlay_classes, overlay_colors, y_pred: Tensor, label):
font = {'color': 'green',
'size': 20,
'family': 'Times New Roman'}
grid = torch.tensor([
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 1, 1, 1, 1, 1, 1, 0],
[0, 1, 1, 1, 1, 1, 1, 0],
[0, 1, 1, 1, 1, 1, 1, 0],
[0, 1, 1, 1, 1, 1, 1, 0],
[0, 1, 1, 1, 1, 1, 1, 0],
[0, 1, 1, 1, 1, 1, 1, 0],
[0, 0, 0, 0, 0, 0, 0, 0]
])
w, h = img.shape[1:]
k_size = grid.shape[0]
left, top = 0, 0
while top < h:
left = 0
bottom = min(top + k_size, h)
while left < w:
right = min(left + k_size, w)
sum_pred = torch.sum(y_pred[:, top:bottom, left:right].flatten(1, 2), dim=1)
klass = sum_pred.argmax()
if klass in overlay_classes:
overlay_index = overlay_classes.index(klass)
img[:, top:bottom, left:right] = torch.mul(
img[:, top:bottom, left:right], grid[0:bottom-top,0:right-left]) + torch.mul(overlay_colors[overlay_index][:,None, None], grid ^ 1)
left = right
top = bottom
plt.figure(figsize=(12, 5))
plt.imshow(img.permute(1, 2, 0))
if label:
plt.text(10, 20, label, fontdict=font)
plt.show()
3. 语义分割应用
语义分割是计算机视觉中的基础应用,可以用来从给定的数据中识别出数据中的对象并进行后续处理,在机器理解图片和视频方面,发挥着重要的作用。在实际生产和生活中,语义分割有着广泛的应用空间。
3.1. 自动驾驶
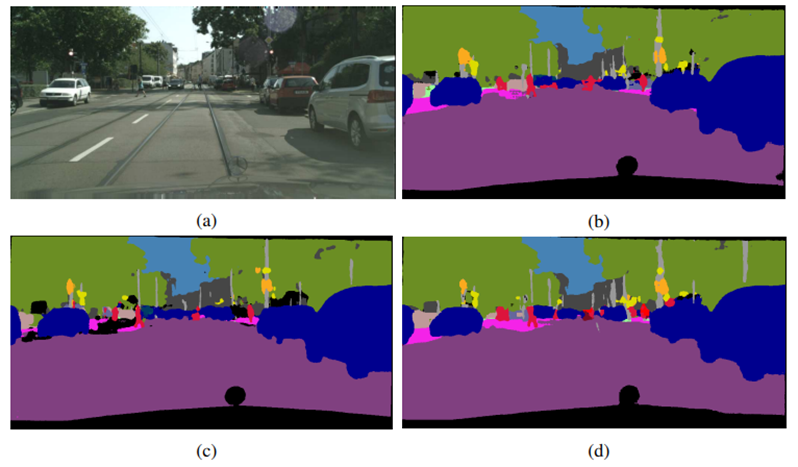
自动驾驶是语义分割的经典应用。汽车在自动驾驶行驶的过程中,需要对周围的环境进行感知,以便控制汽车按预期的方式来行驶。语义分割通过对汽车摄像设备捕捉到的图片进行分析,帮助识别车道,交通标识,行人,障碍等关键数据,为自动驾驶的决策和控制提供重要信息。
3.2. 零售分析

使用语义分割,可以帮助零售商了解货架上商品的整体情况。借助一些算法分析,可以识别出商品缺货,商品摆放不规则等业务场景。智能决策系统可以根据分析的结果,决定后续的处理,比如告警,或者触发供应链的后续补货等流程。
3.3. 照片处理

在现代的手机拍照功能中,面部特效,附加卡通人物,隐藏人个别人像,更换背景,背景模糊等功能需要对照片中的人脸,人像,背景等信息进行识别。使用语义分割,可以对照片中的特定部分内容进行识别,以便后续的算法对照片中的特定部分来进行后续处理。
3.4. 医学影像分析
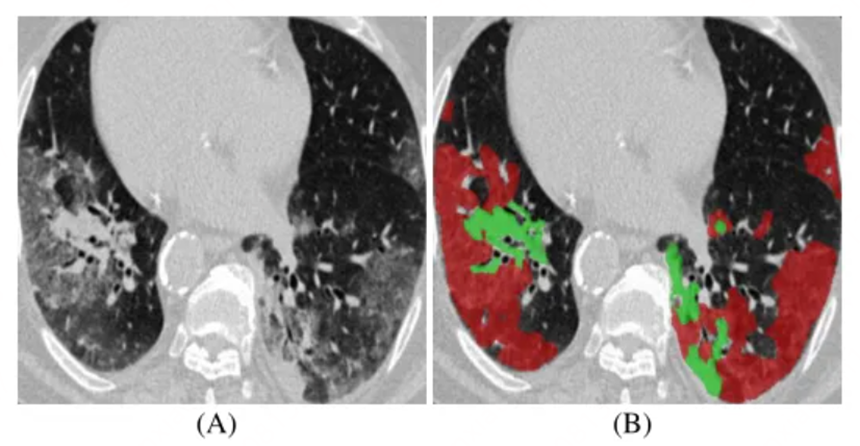
语义分割通过对CT扫面影像的分析,可以用来识别器官组织是否正常,已经可能发生的症状。通过语义分析,可以辅助医学工作者更好地识别疾病或早期病灶,配合适当的算法,可以智能地提供用药建议,护理建议等决策。
3.5. 地质检测

根据卫星或航拍等影像图,语义分割可以识别图片中的地质情况,土地上覆盖的作物,建筑等信息。这些信息可以用于监控森林砍伐,沙漠化,城市规划,交通管控等一系列功能。
3.6. 虚拟试衣
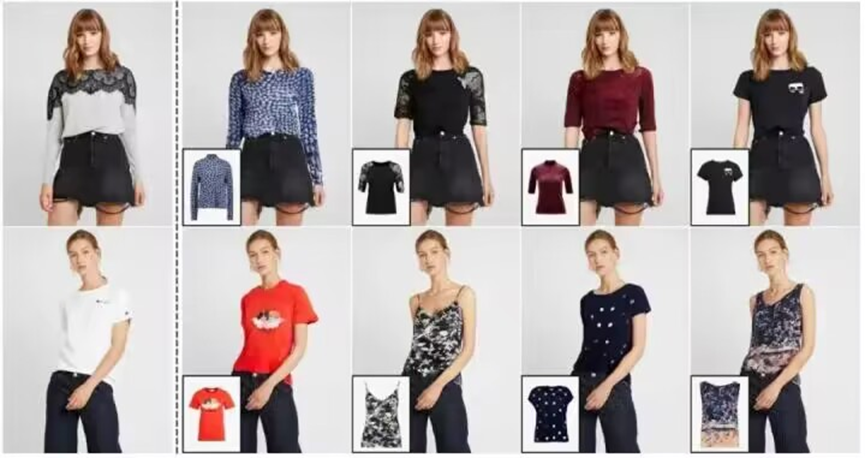
虚拟试衣,可以把目标衣服图像替换人体的着装部分,生成更换服装的效果。通过分割人像中的特定部分,可以实现服装的更换,不同服装的搭配效果,提升用户在服装消费上的体验和匹配。
参考文献
[1] Long, Jonathan, Evan Shelhamer, and Trevor Darrell. "Fully convolutional networks for semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.