ES高可用及集群管理
Elasticsearch 是一个分布式、高扩展、高实时、RESTful 风格的搜索与数据分析引擎。
- 服务可用性:允许有节点停止服务
- 数据可用性:部分节点丢失,不会丢失数据
- 水平扩展
- 集群容错
一、分片
1、什么是分片及其作用
节点:一个运行中的ES实例成为一个节点;
集群:由一个或者多个拥有相同cluster.name配置的节点组成;
分片:分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一部分。
一个索引可以存储超出单个节点硬件限制的大量数据,会出现索引数据量大,响应慢等问题;ES把一个索引划分成了多份,每个分片都是功能完善且独立的索引,这些分片分配到集群中的各个节点上。
分片分为主分片和副本分片,对文档的新建、索引、删除等写操作,必须在主分片上完成之后才能被复制到相关的副本分片; 副本分片是主分片的一个副本,防止硬件故障导致数据丢失;提供读请求;当主分片异常,副本分片可以升级成主分片提供服务;高可用的一个保障;
主分片和副本分片不会在同一个节点上,防止单点故障。如果其中一个节点宕机,任然可以从剩余节点中获取到一个索引的完整数据
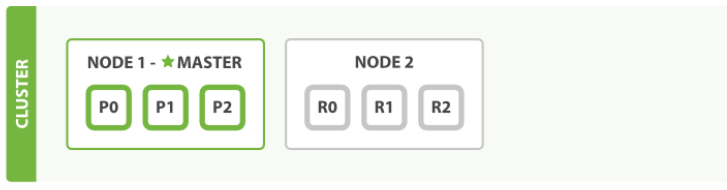
//创建索引的时候指定分片数
PUT /my_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
主分片数定义好后不能修改:shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。
数据写入流程:

2、分片负载均衡
Shard会被均衡的分配到每个节点上,且主分片和副本分片不会在同一个节点上。
master节点根据现在各个数据节点上的主分片分布情况来安排哪些节点来接收新的索引的主分片,根据各个数据节点上的总分片的分布情况来安排哪些节点来接收新的索引的副本分片。本着集群各数据节点总体均衡的策略来安排节点。
水平扩容:新增机器,会自动集群发现加入集群,同时自动分片负载均衡,进行分片迁移
添加第三个节点,为了分散负载对分片进行重新分配

(1)如果需要修改主分片数该怎么做
通过reindex
就是创建一个新的索引,将原来索引的数据迁移到新的索引里面去,以达到修改的目的。
-
创建一个新的索引,设置副本数为0(使用零副本进行索引,然后在提取完成时启用副本,则恢复过程本质上是逐字节的网络传输。 这比复制索引过程更有效。)
-
增加refresh间隔,再导入期间何以设置为-1来禁用刷新。
PUT /my_index/_settings
{ "refresh_interval": -1 }
-
数据迁移
POST _reindex?slices=auto&wait_for_completion=false
{
"source": {
"index": "old_index",
"size": 5000,
},
"dest": {
"index": "new_index"
}
}
//slices:切片,表示查询的并行数,一般设置为auto,表示和索引的分片数相等
//size:一次scroll查询的数量,默认是1000,可以适当调大,根据cpu和内存使用情况调整到最优设置,批量大小取决于数据、分析和集群配置,但一个好的起点是每批处理5-15 MB。
//wait_for_completion:是否等待完成,一般如果删除数据的时间大于30秒(socket超时时间)的时候,kibana会显示超时,并且不会返回结果。这里设置为false,表示直接返回,不等待执行结果,这里会返回一个taskId,可以查看任务的执行情况和结果
//根据taskId查询执行情况
GET _tasks/dCNYPIg4RHm3ymBqyEjMwA:59386193
(2)集群节点临时重启需要注意
节点停止后,当前节点的分片会自动分配到其他节点上,本节点启动后需要等其他节点RECOVERING(恢复)后才会RELOCATING(迁移),也就是分片在其他节点恢复后又转移回来,浪费大量时间。
集群节点重启前要先临时禁用自动分配,设置cluster.routing.allocation.enable为none
cluster.routing.allocation.enable,启用或禁用特定种类的分片分配
- all- (默认值)允许为所有类型的分片分配分片。
- primaries - 仅允许分配主分片的分片。
- new_primaries - 仅允许为新索引的主分片分配分片。
- none - 任何索引都不允许任何类型的分片。
PUT _cluster/settings
{
"transient" :
{
"cluster.routing.rebalance.enable": "none"
}
}
二、持久化变更
buffer->refresh->flush
因为lucene索引过程中,数据会首先据缓存在内存中,直到达到一个量(文档数或是占用空间大小)才会写入到磁盘。这就会带来一个风险,如果在写入磁盘前系统崩溃,那么这些缓存数据就会丢失,为了保证数据的可靠性,ES 引入了 Translog.
(1)新的文档被添加到内存缓冲区并且被追加到了事务日志
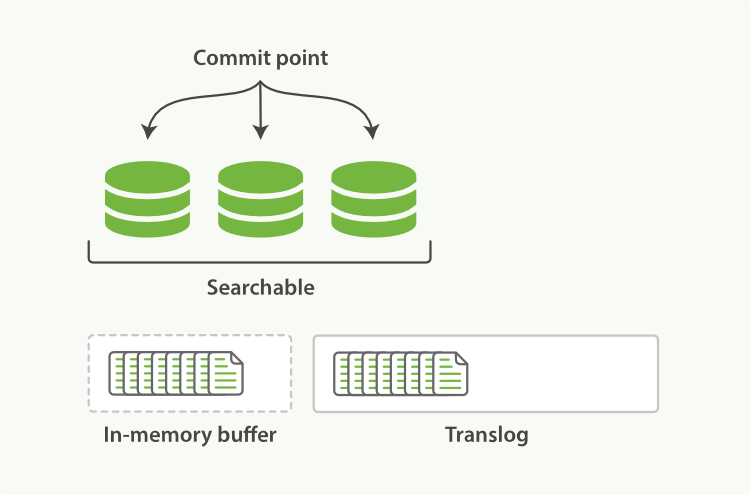
(2)刷新(refresh)完成后, 缓存被清空但是事务日志不会
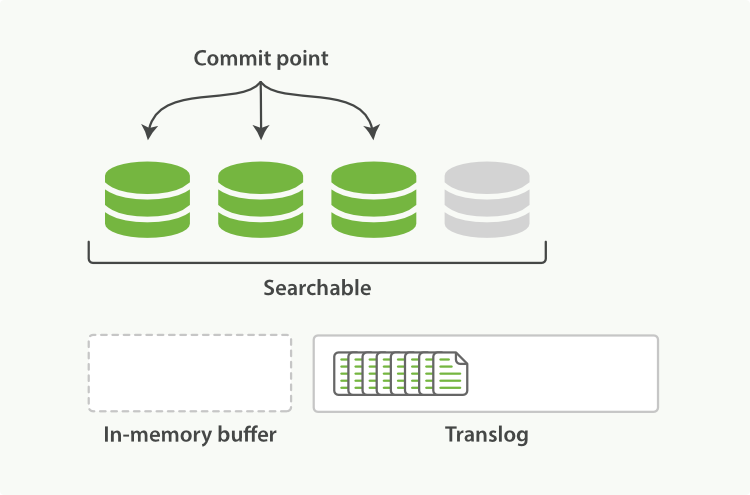
(3)在刷新(flush)之后,段被全量提交,并且事务日志被清空(是否马上删除,可以通过配置)
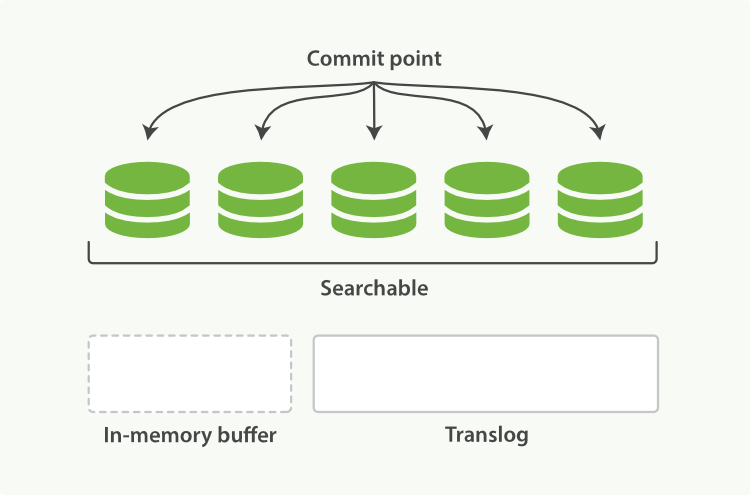
Elasticsearch提供了几个参数配置来控制Translog的同步:
-
index.translog.durability
该参数控制如何同步Translog数据。有两个选项:
-
request(默认):每次请求(包括index、delete、update、bulk)都会执行fsync,将Translog的数据同步到磁盘中。
-
async:异步提交Translog数据。和下面的index.translog.sync_interval参数配合使用,每隔sync_interval的时间将Translog数据提交到磁盘,这样一来性能会有所提升,但是在间隔时间内的数据就会有丢失的风险。
-
index.translog.sync_interval:该参数控制Translog的同步时间间隔。默认为5秒。
-
index.translog.flush_threshold_size:该参数控制Translog的大小阈值,默认为512MB。防止过大的Translog影响数据恢复所消耗的时间。一旦达到了这个大小就会触发flush操作,生成一个新的提交点,日志是否删除还要根据保留时长和保留大小而定。
-
index.translog.retention.size:日志保留大小,默认512MB。
-
index.translog.retention.age:日志保留时长,默认12h。
三、集群发现机制
ES是一种peer to peer点对点分布式系统架构,集群上每个节点是直接和其他节点通信的。
ES各节点想组成一个集群有两个条件:
-
cluster.name 必须一致
默认情况下,es进程会绑定在自己的本地地址上,也就是127.0.0.1,然后扫描本机上的9300~9305端口,尝试跟那些端口上启动的其他es进程进行通信,然后组成一个集群。
-
通过discovery.zen.ping.unicast.hosts (ES7以后版本改为 discovery.seed_hosts)
可以相互关联起来,discovery.seed_hosts 列表中的IP列表称为种子节点,该配置项代表集群中初始结点的主机列表。每个主机由名字(或者IP地址)加端口或者端口范围组成。
Elasticsearch采用单播的通讯机制和列表中的节点通讯,单播也就是点对点的数据传输,数据的发送和接收只在两个节点完成。
//单播
ddiscovery.seed_hosts: ["node1","node2:8080", "node3[9000-9005]]
//例如
discovery.seed_hosts: ["192.168.31.163:9300","192.168.31.160:9300","192.168.31.161:9300","192.168.31.162:9300"]
// port如果未设置则返回transport.tcp.port
这个列表不需要配置上集群中的所有节点,因为一个节点连接到集群中的一个节点之后,这个连接信息就会被发送到集群中的所有其它节点。
某个节点通过发现机制找到其他节点是使用 Ping 的方式,依赖transport模块实现。注意port默认应该是9300,不是9200。
四、集群选举
(1)集群中节点角色:
Master:主节点,负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等,跟踪哪些节点是集群的一部分,并决定哪些分片分配给相关的节点 ,维护集群状态。主节点并不需要涉及到文档级别的变更和搜索等操作。只有在法定数量的节点接受集群状态更新时,才将更新视为成功。法定数量是从集群里符合主节点条件的节点中精心选出的一部分节点的数量。
//节点可以作为主节点
node.master: true
DataNode:储存数据的节点
//默认是数据节点
node.data: true
Coordinate node:协调节点
如果仅担任协调节点,将上两个配置设为false。一个节点只作为接收请求、转发请求到其他节点、汇总各个节点返回数据等功能的节点。就叫协调节点。小规模集群,不需严格区分。中大规模集群(十个以上节点),应考虑单独的角色充当。特别并发查询量大,查询的合并量大,可以增加独立的协调节点。角色分开的好处是分工分开,不互影响。如不会因协调角色负载过高而影响数据节点的能力。
Ingest node: 预处理节点,在索引数据之前可以先对数据做预处理操作,所有节点其实默认都是支持 Ingest 操作的,也可以专门将某个节点配置为 Ingest 节点。
(2)选举
选举时间点:
-
集群启动初始化
-
集群的master崩溃
选举过程:

activeMaster:其他节点认为的master节点,如果activeMaster列表不为空,优先从activeMaster选,如果有多个节点具有master资格,选择nodeId最小的节点。
masterCandidates:有资格成为master的节点,如果activeMaster为空,判断masterCandidates列表成员数量是否达到minimumMasterNodes,达到了比较集群状态版本编号clusterStateVersion,再比较id,让拥有最近集群状态的节点成为mater
#指为完成选举所需要的master-eligible节点数量;防止集群脑裂,在生产环境需要配置;
discovery.zen.ping.minimum_master_nodes
集群选举出master后,master节点回合集群其他节点定期发送ping,master节点发现其它节点宕机,master会将其它节点移除出集群,当其它节点发现master宕机,则会尝试发起选举
//master向其它节点ping确认是否存活的时间范围,该值默认为1s
discovery.zen.fd.ping_interval
//等待ping回复的时间,默认为30s
discovery.zen.fd.ping_timeout
//ping失败超时次数,超过该次数则认定宕机,默认值为3
discovery.zen.fd.ping_retries
通常,我们建议集群设置三个符合主节点条件的节点,这样如果其中的一个节点失败,其他两个节点仍然可以安全地形成法定数量,并继续提供服务。如果一个集群少于三个符合主节点条件的节点,那它将无法安全地容忍其中任何一个节点发生故障。相反,如果一个集群中符合主节点条件的节点远多于三个,则节点选举和集群状态更新可能需要更长的时间。
演进
在ES7.0中,重新设计了集群协调子系统
- 移除了
minimum_master_nodes 设置,让 Elasticsearch 自己选择可以形成法定数量的节点。
随着节点的添加或删除,Elasticsearch 会自动更新集群的选举配置,以维护最佳的容错级别.选举配置是一组符合主节点条件的节点,在做出决策时,它们具有投票权。
注意点:
- 建议在集群中设置少量和固定数量的符合master资格的节点,并且仅通过添加和删除不符合master资格的节点来上下扩展集群
- 删除符合master资格的节点时,不要同时删除太多节点,例如,如果目前有 7 个符合主资格的节点,并且您希望将其减少到 3 个,则不可能简单地同时停止四个节点:这样做只会留下三个节点,这还不到投票配置的一半,集群通常将不可用。
- 投票配置删除列表,
// Add node to voting configuration exclusions list and wait for the system// to auto-reconfigure the node out of the voting configuration up to the// default timeout of 30 seconds
POST /_cluster/voting_config_exclusions/node_name
// Add node to voting configuration exclusions list and wait for
// auto-reconfiguration up to one minute
POST /_cluster/voting_config_exclusions/node_name?timeout=1m
//查看当前集群投票配置排除列表
GET /_cluster/state?filter_path=metadata.cluster_coordination.voting_config_exclusions
// Wait for all the nodes with voting configuration exclusions to be removed from
// the cluster and then remove all the exclusions, allowing any node to return to
// the voting configuration in the future.
DELETE /_cluster/voting_config_exclusions
// Immediately remove all the voting configuration exclusions, allowing any node
// to return to the voting configuration in the future.
DELETE /_cluster/voting_config_exclusions?wait_for_removal=false
投票配置排除 API 最有助于将双节点缩小到一个节点集群,也可以同时使用它删除多个符合主资格的节点。通常,在群集上执行某些维护时会添加排除,维护完成后应清理排除。在正常操作中,集群不应有投票配置排除。
集群引导
从版本 7.0 开始,如果要启动一个全新的集群,并在多台主机上都有节点,则必须指定该集群在初次选举中应使用的一组符合主节点条件的节点作为选举配置。这被称为集群引导,只在第一次形成集群时需要。帮助进行选举一个主节点.
//指定满足node.master:true配置的节点
cluster.initial_master_nodes:
- master-a
- master-b
- master-c
如果完全使用默认配置启动新安装的 Elasticsearch 节点,它们会自动查找在同一主机中运行的其他节点,并在几秒钟内形成一个集群。在多台主机上都有节点的分布式环境中,该机制可能存在风险,各节点可能无法及时发现彼此,进而可能形成两个或多个独立的集群。如果没有设置 initial_master_nodes,则在启动全新节点时会尝试发现现有的集群。如果节点找不到可以加入的集群,则会定期记录一条警告消息,指明
master not discovered yet, this node has not previously joined a bootstrapped (v7+) cluster,and [cluster.initial_master_nodes] is empty on this node
No master block
对于一个可以正常充分运作的集群来说,必须拥有一个活着的主节点和正常数量(discovery.zen.minimum_master_nodes个)活跃的备选主节点。discovery.zen.no_master_block设置了没有主节点时限制的操作。它又两个可选参数:
但discovery.zen.no_master_block 这个参数对于节点相关的api是无效的,如节点信息(node info)、节点统计信息(node stats)这些api不会阻止。
版本7.0
